Application Domain Isolation and Process Lifetimes
|
| At first glance, it might seem unnecessary to build a complex infrastructure just to make sure that a process doesn't crash in the face of exceptional conditions. After all, it would seem easier to simply write your managed code such that it handled all exceptions properly. In fact, this is the path the CLR team started down when it first began the work to make sure that managed code could work well in environments requiring long process lifetimes. However, it was quickly determined that writing large bodies of code to be reliable in the face of all exceptions is impractical. As it turns out, the CLR's model for executing managed code could, in theory, cause exceptions to be thrown on virtually any line of code that is executed. This situation is primarily caused by the fact that memory can be allocated, and other runtime operations can occur, in places where you wouldn't expect. For example, memory must be allocated any time Microsoft intermediate language (MSIL) code needs to be jit-compiled or a value type needs to be boxed. The following code snippet simply inserts an integer into a hash table: hashtable.Add("Entry1", 5);However, because the signature of HashTable.Add specifies that the second parameter is of type Object, the CLR must create a reference type by boxing the value "5" before adding it to the hash table. The act of creating a new reference type requires memory to be allocated from the garbage collector's heap. If memory is not available, the addition of the value 5 into the hash table would throw an OutOfMemoryException. Also, consider the following example that saves the value of an operating system handle after using PInvoke to call Win32's CreateSemaphore API: IntPtr semHandle = CreateSemaphore(...); In this case, if the call to CreateSemaphore were to succeed but an exception were to be thrown before the value of the handle could be stored in the local variable, that handle would be leaked. Resource leaks such as these can add up over time to undermine the stability of the process. Furthermore, conditions such as low memory can prevent the CLR from being able to run all cleanup code that you might have defined in finally blocks, finalizers, and so on. The failure to run such code can also result in resource leaks over time. It's also worth noting that even if it were practical for all of the Microsoft .NET Framework assemblies and the assemblies you write as part of your extensible application to handle all exceptional conditions, you'd never be able to guarantee that the add-ins you host are written with these conditions in mind. So the need for a mechanism by which the host can protect the process from corruption is required. The first two releases of the CLR (in .NET Framework 1.0 and .NET Framework 1.1) didn't have the explicit requirement to provide a platform on which you could guarantee long process lifetimes mainly because there weren't any CLR hosts at the time that needed this form of reliability model. The primary CLR host at the time was Microsoft ASP.NET. High availability is definitely a requirement in Web server environments, but the means to achieve that reliability have been quite different. Historically, at least on the Microsoft platform, Web servers have used multiple processes to load balance large numbers of incoming requests. If the demand were high, more processes would be created to service the requests. In times of low demand, some processes either sat idle or were explicitly killed. This method of achieving scalability works well with Web applications because each request, or connection, is stateless; that is, has no affinity to a particular process. So subsequent requests in the same user session can be safely redirected to a different process. Furthermore, if a given process were to hang or fail because of some exceptional condition, the process could be safely killed without corrupting application state. To the end user, a failure of this sort generally shows up as a "try again later" error message. Upon seeing an error like this, a user typically refreshes the browser, in which case the request gets sent to a different process and succeeds. Although achieving scalability and reliability through process recycling works well in Web server scenarios, it doesn't work in some scenarios, such as those involving database servers where there is a large amount of per-process state that makes the cost of starting a new process each time a failure occurs prohibitive. Just as the ASP.NET host drove the process recycling model used in the first two releases of the CLR, Microsoft SQL Server 2005 has driven the .NET Framework 2.0 design in which long-lived processes are a requirement. As described, the CLR's strategy for protecting the integrity of a process is to always contain failures to an application domain and to allow that domain to be unloaded from the process without leaking resources. Let's get into more detail now by looking at the specific techniques the CLR uses to make sure that failures can always be isolated to an application domain. Failure EscalationGiven that failures caused by resource exhaustion or other exceptional conditions can occur at virtually any time, hosts requiring long process lifetimes must have a strategy for dealing with such failures in such a way as to protect the integrity of the process. In general, it's best to assume that the add-ins running in your host haven't been written to handle all exceptions properly. A conservative approach to dealing with failures is more likely to result in a stable process over time. The host expresses its approach to handling failures through the escalation policy I described in the chapter introduction. In this section, I describe escalation policy as it fits into the CLR's overall reliability model. Later in the chapter, I discuss the specific CLR hosting interfaces used to express your escalation policy. In .NET Framework 2.0, all unhandled exceptions are allowed to "bubble up" all the way to the surface, thereby affecting the entire process. Specifically, an exception that goes unhandled will terminate the process. Clearly, this end result isn't acceptable when process recycling is too expensive. Note
CLR hosts can use escalation policy to specify how these types of failures should be handled and what action the CLR should take when certain operations take longer to terminate than desired. For example, a thread might not ever abort if the finalizer for an object running on that thread enters an infinite loop, thereby causing the thread to hang. The specific failures that can be customized through escalation policy are as follows:
Given these failures, a host can choose to take any of a number of actions. The specific actions that can be taken are the following:
In addition to specifying which actions to take in the face of certain failures, escalation policy also enables a host to specify timeouts for certain operations and to indicate which actions should occur when those timeouts are reached. This capability is especially useful to terminate code that appears to be hung, such as code in an infinite loop or code waiting on a sychronization primitive that has been abandoned. A host can use escalation policy to specify a timeout for thread abort (including an abort in a critical region of code), application domain unload, process exit, and the amount of time that finalizers are allowed to run. Finally, escalation policy can be used to force any of the operations for which timeouts can be specified to take a certain action unconditionally. For example, a host can specify that a thread abort in a critical region of code should always be escalated to an application domain unload. Now that I've covered the basic concepts involved in escalation policy, let's look at a specific example to see how a host might use those concepts to specify a policy aimed at keeping the process alive in the face of resource failures or other exceptional conditions. Figure 11-1 is a graphical representation of an escalation policy similar to the one used in the SQL Server 2005 host. Figure 11-1. Escalation policy is the host's expression of how failures in a process should be handled.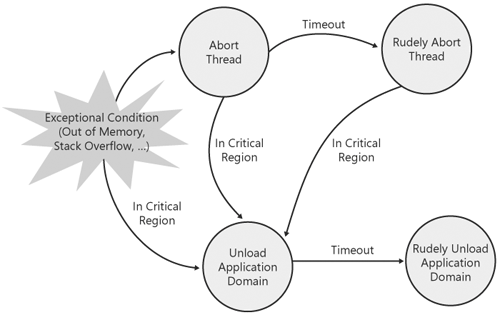 The key aspects of this policy are as follows:
Critical Finalization, SafeHandles, and Constrained Execution RegionsOne of the key pieces of infrastructure needed to ensure that application domains can be unloaded without leaking resources is the capability to guarantee that any native handles held by managed code will be closed properly. Several classes in the .NET Framework (not to mention those written by third parties, including those you might have written yourself) logically act as a wrapper around a native resource. For example, the file-related classes in the System.IO namespace hold native file handles, and the classes in System.Net maintain native handles that represent open network sockets. Traditionally, these native handles have been closed using a combination of the Dispose design pattern and object finalizers. However, as I've described, the CLR does not guarantee that finalizers will be run when rudely unloading an application domain. If a class that holds a native resource requires a finalizer to run to free the handle, that handle will be leaked when an application domain is rudely unloaded. For this reason, the CLR has introduced some new infrastructure in .NET Framework 2.0 that can be used to guarantee that native handles such as these will always be released, regardless of how the application domain is terminated. The concepts of critical finalization, safe handles, and constrained execution regions work together to ensure that native handles can always be released. Simply put, a critical finalizer is a finalizer that the CLR will always run. Furthermore, a critical finalizer is always guaranteed to complete. Any type that derives from System.Runtime.ConstrainedExecution.CriticalFinalizer-Object receives the benefits of critical finalization. One such type is System.Runtime.Interop-Services.SafeHandle (and its derivatives). A SafeHandle is a wrapper around a native handle that relies on critical finalization to ensure that the native handle will always be freed. All of the classes in the .NET Framework that hold native handles have been rewritten in version 2.0 to use SafeHandles to wrap those handles. The handles held by those classes will always be freed. What is it about a critical finalizer that enables the CLR to make the guarantee that it will always be run and that it will always complete? The answer lies in the concept known as a constrained execution region (CER). A CER is a block of code in which the CLR guarantees that exceptions such as OutOfMemoryException or StackOverflowException are never thrown because of a lack of resources. Given this guarantee, you can be sure that the code in the CER will always complete (assuming it handles normal application exceptions, that is). To guarantee that resource failures will never occur in a CER, the CLR must do two things:
When preparing a CER, the CLR moves the allocation of all resources, such as memory, to a point just before the type containing the CER is created. For example, all code in a CER is jit-compiled before the CER is entered, thereby ensuring that enough memory exists to create the native code needed to execute the methods in the CER. If the creation of a type in a CER succeeds, you can guarantee it will run without failing because of a lack of resources. Note that preparing a type isn't just a matter of looking at the resource needs of the type; it also requires preparing all types referenced in the CER (recursively) as well. Also, preparing a CER ensures it will run only if the code in the CER doesn't allocate additional memory by creating new reference types, boxing value types, and so on. So code in a CER is restricted from performing any operations that can allocate memory. In .NET Framework 2.0, there is no mechanism in the CLR to enforce that code in a CER follows these restrictions. However, there likely will be in future releases. For now, the primary way to make sure that code in a CER doesn't allocate additional resources is by code review. Given this understanding of CERs, step back and see how this all relates to safe handles. Safe handles guarantee the release of the native handles they wrap because all code in an instance of SafeHandle runs in a CER. If there are enough resources available to create an instance of SafeHandle, there will be enough resources available to run it. In short, the CLR moves the allocation of all resources required for a critical finalizer up to the point where the object containing the finalizer is created, rather than waiting to allocate the resources at the point the finalizer must run. Given that critical finalizers are guaranteed always to run, why not just make all finalizers critical? Or even better, why invent a new separate notion of a "critical" finalizer at all, and simply guarantee that all finalizers will complete successfully? Although this might seem tempting on the surface, there are two primary reasons why this wouldn't be practical. The first is performance: preparing a type (and its dependencies) takes time. Furthermore, the CLR might jitcompile code that is never even executed. The second reason that critical finalization can't become the default behavior is because of the restrictions placed on code running in a CER. The inability to cause memory to be allocated dramatically limits what can be done in a CER. Imagine writing a program that never used new, for example. One final aspect of critical finalization worth noting is that critical finalizers are always run after normal finalizers. To understand the motivation for this ordering, consider the scenario of the FileStream class in System.IO. Before .NET Framework 2.0, FileStream's finalizer had two key tasks: it flushed an internal buffer containing data destined for the file and closed the file handle. In .NET Framework 2.0, FileStream encapsulates the file handle using a SafeHandle, thus uses critical finalization to ensure the handle is always closed. In addition, FileStream maintains its existing finalizer that flushes the internal buffer. For FileStream to finalize properly, the CLR must run the normal finalizer first to flush the buffer before running the critical finalizer, which closes the file handle. The ordering of finalizers in this way is done specifically for this purpose. |

|
EAN: N/A
Pages: 119