Section 10.4. Understanding the DOM: The Core API
10.4. Understanding the DOM: The Core APIThe DOM HTML API was created specifically to bring in the many implementations of BOM that existed across browsers. However, over the last several years, there's been a move away from using HTML (with all the proprietary extensions) and toward the XML-based XHTML. The DOM HTML API is still valid for XHTML, but another set of interfacesthe DOM Core APIhas gained popularity among current JavaScript developers. The W3C specifications for the DOM describe a document's elements as a collection of nodes, connected in a hierarchical tree-like structure. If you use Firefox as a browser, and you've opened up the DOM Inspector to look at the page objects, you'll probably have noticed that the page contents strongly resemble a tree. A web page with a head and body tags, the body with a header (H1), as well as DIV elements containing paragraphs, would have a structure somewhat like this: document -> HTML -> HEAD -> BODY -> H1 -> DIV -> P -> P The DOM provides a specification that allows you to access the nodes of this content tree by looking for all of the tags of a certain type or traversing the different levelsliterally walking the tree and exploring each node at each level. Not only can you read the nodes in the tree, but you can also create new nodes. 10.4.1. The DOM TreeTo better understand the document tree, consider a web page that has a head and body section, a page title, and a DIV element that itself contains an H1 header and two paragraphs. One of the paragraphs contains italicized text; the other has an imagenot an uncommon web page: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html> <head> <title>Document In</title> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> </head> <body> <div > <h1>Header</h1> <!-- paragraph one --> <p>To better understand the document tree, consider a web page that has a head and body section, has a page title, and contains a DIV element that itself contains an H1 header and two paragraphs. One of the paragraphs contains <i>italicized text</i>; the other has an image--not an uncommon web page.</p> <!-- paragraph two --> <p>Second paragraph with image. <img src="/books/4/327/1/html/2/dotty.gif" alt="dotty" /></p> </div> </body> </html> An element contained within another is considered a child node, other contained elements are siblings, and the containing element is the parent. Figure 10-1 provides a hierarchical description of this page, demonstrating the parent, child, and sibling relationships. Figure 10-1. Hierarchy of elements in a web page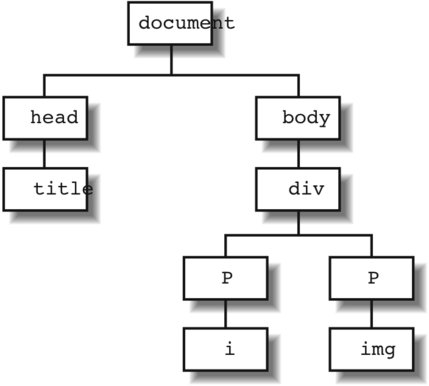 Information, such as the relationship each node has with the others, is accessible via each node's shared properties and methods, covered next. 10.4.2. Node Properties and MethodsRegardless of its type, each node in the document tree has one thing in common with all the others: each has all of the basic set of properties and methods of the Node object. The Node object's properties record the relationships associated with the DOM content tree, including those of sibling elements, child, and the parent. It also has properties that provide other information about the node, including type, name, and if applicable, value. The following list gives this object's properties.
You can see the XML influence in the Node properties, especially with regard to namespaces. However, when accessing XHTML elements as nodes within a browser, the namespace properties are typically null. Also note that some properties are valid for node objects that are considered elements, such as those wrapping page elements like HTML and DIV; some are valid only for Node objects that are not, such as those of text objects associated with paragraphs or whatever element. To better get a feel for this element/not element dichotomy, Example 10-4 is an application that accesses each Node object within a web page and pops up a dialog listing the node properties. The nodeType property provides the type of node as a numeric, and the nodeName is the actual object name currently being processed. If the node is not an element, its value is printed out with nodeValue; otherwise, this is null. In addition, if the Node object is an element, it will have a style property (inherited as part of the element, and covered in much more detail in Chapter 12). This sets the background color of the object currently being processed (using a random-color generator), so that you can get visual feedback as the page processing progresses. (It also outputs this background color information to the message, as a secondary feedback method.) Example 10-4. Accessing Node properties
In the application, when the nodeValue property is not null, the style property is seteven for nonvisual elements such as those associated with the META tag. However, when the nodeValue property has a value (even if it's only a blank), the style property is not set. Also note that elements containing text, such as a paragraph, actually contain a reference to a text node, which is what contains the text. In fact, you might be surprised at how many components go into this rather simple page.
There is another aspect of this application that might surprise you, and that's the difference in what is printed out per browser. Firefox prints out the CDATA contents of the script tag, while Opera does not. Internet Explorer does not create text objects for whitespace outside of a tag, while other browsers do. IE also prints out the doctype definition while other browsers do not. Navigator doesn't color the entire page when processing the HTML element, but it does print out CDATA section for the script, and so on. This one example demonstratesprobably more effectively than any other in the bookthe fact that subtle differences in implementing even the exact same specification can cause behavioral and visual variations among the different browsers.
One property of node, nodeType, is a numeric. Rather than search for a specific node type using values of 3 or 8, the DOM specifies a group of constants you can access on the node prototype representing each type. These constants are:
These constants are helpful in maintaining more readable code, not to mention not having to memorize the individual values. Unfortunately, their implementation is not universal. Internet Explorer and Opera, at a minimum, don't implement these constants. Luckily, you can extend the Node object using the JavaScript prototype, covered in detail in Chapter 11. One of the examples is adding these constants to Node. 10.4.3. Traversing the Tree with the NodeThe Node can be used to traverse a document's content, through its various parent, child, and sibling methods. Example 10-4 demonstrated this capability. The application uses the childNodes list to access a page element's children, and then uses recursion to traverse each child, in turn. The parent/child relationship isn't the only one that can be used to travel throughout a model; other properties can be used, including the sibling relationship. The following three examples illustrate a frameset (Example 10-5), an input HTML page (Example 10-6), and a page with JavaScript to walk through the document in the first frame (Example 10-7). The script prints out the objects found, at what level, and if they have any children themselves. By level, I mean how deeply nested the HTML element is within the page. Example 10-5 is the frameset page. I'm not using a frameset as a form of penance for not being fond of a perfectly good HTML construct. No, I'm using frames because I'll be printing to the document as I traverse it, and if I create new objects as I'm writing them out, I'll end up in a recursive loop that will never end. Example 10-5. Frameset page
Example 10-6 is the source page for the traversal. The frameset can be modified to use any page for the frame, and the JS will attempt to walk the tree. However, note that the function to process the tree is based on an onload event in the script page. If it loads before the source page, the results will not be as you expect. Example 10-6. Source page
Example 10-7 is the web page with the script. Like Example 10-4, it uses recursion, but before it digs deeper into the page nesting, the children nodes of the HTML element currently in the queue are accessed and printed out using the Node's relationship properties. Each child node is then processed in turn. Example 10-7. Script page
This example is a fairly simple approach to walking the tree. A variation could be to store each level in an array and then print each level out, in turn. You could also traverse each tree branch in turn and print out the parent-child trail before going on to each sibling element.
Other than its self-identification and navigation capabilities, the Node also has several methods that can be used to replace nodes or insert new nodes. These are used in association with document object methods that are used to create new elements. |

EAN: 2147483647
Pages: 151