Defensive Programming
Defensive programming is the art of writing code that functions properly under adverse conditions. In the context of the Web, an adverse condition could be many different things: for example, a user with a very old browser, or an embedded object or frame that gets stuck while loading. Coding defensively involves an awareness of the situations in which something can go awry. Some of the most common possibilities you should try to accommodate include
-
Users with JavaScript turned off
-
Users with cookies turned off
-
Embedded Java applets that throw an exception
-
Frames or embedded objects that load incorrectly or incompletely
-
Older browsers that do not support modern JavaScript objects or methods
-
Older browsers with incomplete JavaScript implementations ”for example, those that do not support a specific feature such as the push() , pop() , and related methods in the Array object of versions of Internet Explorer prior to 5.5
-
Browsers with known errors, such as early Netscape browsers with incorrectly functioning Date objects
-
Users with text-based or aural browsers
-
Users on non-Windows platforms
-
Malicious users attempting to abuse a service or resource through your scripts
-
Users who enter typos or other invalid data into form fields or dialog boxes, such as entering letters in a field requiring numbers
The key to defensive programming is flexibility. You should strive to accommodate as many different possible client configurations and actions as you can. From a coding standpoint, this means you should include HTML (such as << noscript >>s) and browser sensing code that permit graceful degradation of functionality across a variety of platforms. From a testing standpoint, this means you should always run a script in as many different browsers and versions and on as many different platforms as possible before placing it live on your site.
In addition to accommodating the general issues just described, you should also consider the specific things that might go wrong with your script. If you are not sure when a particular language feature you are using was added to JavaScript, it is always a good idea to check a reference, such as Appendix B of this book, to make sure it is well supported. If you are utilizing dynamic page manipulation techniques or trying to access embedded objects, you might consider whether you have appropriate code in place to prevent execution of your scripts while the document is still loading. If you have linked external .js libraries, you might include a flag in the form of a global variable in each library that can be checked to ensure that the script has properly loaded.
The following sections outline a variety of specific techniques you can use for defensive programming. While no single set of ideas or approaches is a panacea, applying the following principles to your scripts can dramatically reduce the number of errors your clients encounter. Additionally, they can help you solve those errors that are encountered in a more timely fashion, as well as future proof your scripts against new browsers and behaviors.
However, at the end of the day, the efficacy of defensive programming comes down to the skill, experience, and attention to detail of the individual developer. If you can think of a way for the user to break your script or to cause some sort of malfunction, this is usually a good sign that more defensive techniques are required.
Error Handlers
Internet Explorer 3+ and Netscape 3+ provide primitive error-handling capabilities through the nonstandard onerror handler of the Window object. By setting this event handler, you can augment or replace the default action associated with runtime errors on the page. For example, you can replace or suppress the error messages shown in Netscape 3 and Internet Explorer (with debugging turned on) and the output to the JavaScript Console in Netscape 4+. The values to which window.onerror can be set and the effects of doing so are outlined in Table 23-3.
| Value of window.onerror | Effect |
|---|---|
| Null | Suppresses reporting of runtime errors in Netscape 3+. |
| A function | The function is executed whenever a runtime error occurs. If the function returns true , then the normal reporting of runtime errors is suppressed. If it returns false the error is reported in the browser as usual. |
| Note | The onerror handler is also available for objects other than Window in many browsers, most notably the << img >> and << object >> elements. |
For example, to suppress error messages in older browsers you might use
function doNothing() { return true; } window.onerror = doNothing; window.noSuchProperty() // throw a runtime error Since modern browsers don t typically display script errors unless users specifically configure them to do so, the utility of the return value is limited.
The truly useful feature of onerror handlers is that they are automatically passed three values by the browser. The first argument is a string containing an error message describing the error that occurred. The second is a string containing the URL of the page that generated the error, which might be different from the current page if, for example, the document has frames. The third parameter is a numeric value indicating the line number at which the error occurred.
| Note | Early versions of Netscape 6 did not pass these values to onerror handlers. |
You can use these parameters to create custom error messages, such as
function reportError(message, url, lineNumber) { if (message && url && lineNumber) alert("An error occurred at "+ url + ", line " + lineNumber + "\nThe error is: " + message); return true; } window.onerror = reportError; // assign error handler window.noSuchProperty(); // throw an error the result of which in Internet Explorer might be
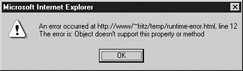
There are two important issues regarding use of the onerror handler. The first is that this handler fires only as the result of runtime errors; syntax errors do not trigger the onerror handler and in general cannot be suppressed. The second is that support for this handler is spotty under some versions of Internet Explorer. While Internet Explorer 4, 5.5, and 6 appear to have complete support, some versions of Internet Explorer 5.0 might have problems.
Automatic Error Reporting
An interesting use for this feature is to add automatic error reporting to your site. You might trap errors and send the information to a new browser window, which automatically submits the data to a CGI or which loads a page that can be used to do so. We illustrate the concept with the following code. Suppose you have a CGI script submitError.cgi on your server that accepts error data and automatically notifies the webmaster or logs the information for future review. You might then write the following page, which retrieves data from the document that opened it and allows the user to include more information about what happened . This file is named errorReport.html in our example:
<<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">> <<html xmlns="http://www.w3.org/1999/xhtml">> <<head>> <<title>>Error Submission<</title>> <<meta http-equiv="content-type" content="text/html; charset=ISO-8859-1" />> <<script type="text/javascript">> <<!-- /* fillValues() is invoked when the page loads and retrieves error data from the offending document */ function fillValues() { if (window.opener && !window.opener.closed && window.opener.lastErrorURL) { document.errorForm.url.value = window.opener.lastErrorURL; document.errorForm.line.value = window.opener.lastErrorLine; document.errorForm.message.value = window.opener.lastErrorMessage; document.errorForm.userAgent.value = navigator.userAgent; } } //-->> <</script>> <</head>> <<body onload="fillalues();">> <<h2>>An error occurred<</h2>> Please help us track down errors on our site by describing in more detail what you were doing when the error occurred. Submitting this form helps us improve the quality of our site, especially for users with your browser. <<form id="errorForm" name="errorForm" action="/cgi-bin/submitError.cgi">> The following information will be submitted:<<br />> URL: <<input type="text" name="url" id="url" size="80" />><<br />> Line: <<input type="text" name="line" id="line" size="4" />><<br />> Error: <<input type="text" name="message" id="message" size="80" />><<br />> Your browser: <<input type="text" name="usergent" id="usergent" size="60" />> <<br />> Additional Comments:<<br />> <<textarea name="comments" cols="40" rows="5">><</textarea>><<br />> <<input type="submit" value="Submit to webmaster" />> <</form>> <</body>> <</html>> The other part of the script is placed in each of the pages on your site and provides the information that fillValues() requires. It does so by setting a handler for onerror that stores the error data and opens errorReport.html automatically when a runtime error occurs:
var lastErrorMessage, lastErrorURL, lastErrorLine; // variables to store error data function reportError(message, url, lineNumber) { if (message && url && lineNumber) { lastErrorMessage = message; lastErrorURL = url; lastErrorLine = lineNumber; window.open("errorReport.html"); } return true; } window.onerror = reportError; When errorReport.html is opened as a result of an error, it retrieves the relevant data from the window that opened it (the window with the error) and presents the data to the user in a form. Figure 23-9 shows the window opened as the result of the following runtime error:
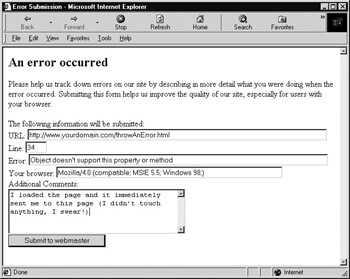
Figure 23-9: Automatic error reporting with the onerror handler
window.noSuchMethod();
The first four form values are automatically filled in by fillValues() , and the << textarea >> shows a hypothetical description entered by the user. Of course, the presentation of this page needs some work (especially under Netscape 4), but the concept is solid.
Exceptions
An exception is a generalization of the concept of an error to include any unexpected condition encountered during execution. While errors are usually associated with some unrecoverable condition, exceptions can be generated in more benign problematic situations and are not usually fatal. JavaScript 1.4+ and JScript 5.0+ support exception handling as the result of their movement toward ECMAScript conformance.
When an exception is generated, it is said to be thrown (or, in some cases, raised ). The browser may throw exceptions in response to various tasks , such as incorrect dom manipulation, but exceptions can also be thrown by the programmer or even an embedded Java applet. Handling an exception is known as catching an exception. Exceptions are often explicitly caught by the programmer when performing operations that he or she knows could be problematic. Exceptions that are uncaught are usually presented to the user as runtime errors.
The Error Object
When an exception is thrown, information about the exception is stored in an Error object. The structure of this object varies from browser to browser, but its most interesting properties and their support are described in Table 23-4.
| Property | IE5? | IE5.5+? | Mozilla/NS6+? | ECMA? | Description |
|---|---|---|---|---|---|
| Description | Yes | Yes | No | No | String describing the nature of the exception. |
| fileName | No | No | Yes | No | String indicating the URL of the document that threw the exception. |
| LineNumber | No | No | Yes | No | Numeric value indicating the line number of the statement that generated the exception. |
| message | No | Yes | Yes | Yes | String describing the nature of the exception. |
| name | No | Yes | Yes | Yes | String indicating the type of the exception. ECMAScript values for this property are EvalError, RangeError, ReferenceError, SyntaxError, TypeError, and URIError. |
| number | Yes | Yes | No | No | Number indicating the Microsoft- specific error number of the exception. This value can deviate wildly from documentation and from version to version. |
| stack | No | No | Yes | No | String containing the call stack at the point the exception occurred. |
The Error() constructor can be used to create an exception of a particular type. The syntax is
var variableName = new Error( message );
where message is a string indicating the message property that the exception should have. Unfortunately, support for the argument to the Error() constructor in Internet Explorer 5 and some early versions of 5.5 is particularly bad, so you might have to set the message property manually, such as
var myException = new Error("Invalid data entry"); myException.message = "Invalid data entry"; You can also create instances of the specific ECMAScript exceptions given in the name row of Table 23-4. For example, to create a syntax error exception, you might write
var myException = new SyntaxError("The syntax of the statement was invalid"); However, in order to keep user-created exceptions separate from those generated by the interpreter, it is generally a good idea to stick with Error objects unless you have a specific reason to do otherwise .
try, catch, and throw
Exceptions are caught using the try/catch construct. The syntax is
try {
statements that might generate an exception
} catch ( theException ) {
statements to execute when an exception is caught
} finally {
statements to execute unconditionally
}
If a statement in the try block throws an exception, the rest of the block is skipped and the catch block is immediately executed. The Error object of the exception that was thrown is placed in the argument to the catch block ( theException in this case, but any identifier will do). The theException instance is accessible only inside the catch block and should not be a previously declared identifier. The finally block is executed whenever the try or catch block finishes and is used in other languages to perform clean-up work associated with the statements that were tried. However, because JavaScript performs garbage collection, the finally block isn t generally very useful.
Note that the try block must be followed by exactly one catch or one finally (or one of both), so using try by itself or attempting to use multiple catch blocks will result in a syntax error. However, it is perfectly legal to have nested try/catch constructs, as in the following:
try { // some statements to try try { // some statements to try that might throw a different exception } catch( theException ) { // perform exception handling for the inner try } } catch ( theException ) { // perform exception handling for the outer try } Creating an instance of an Error does not cause the exception to be thrown. You must explicitly throw it using the throw keyword. For example, with the following,
var myException = new Error("Couldn't handle the data"); throw myException; the result in Mozilla s JavaScript Console is
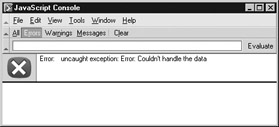
In Internet Explorer with debugging turned on, a similar error is reported.
| Note | You can throw any value you like, including primitive strings or numbers, but creating and then throwing an Error instance is the preferable strategy. |
To illustrate the basic use of exceptions, consider the computation of a numeric value as a function of two arguments (mathematically inclined readers will recognize this as an identity for sine(a + b)). Using previously discussed defensive programming techniques, we could explicitly type-check or convert the arguments to numeric values in order to ensure a valid computation. We choose to perform type checking here using exceptions (and assuming , for clarity, that the browser has already been determined to support JavaScript exceptions):
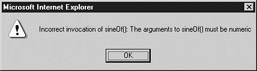
function throwMyException(message) { var myException = new Error(message); throw myException; } function sineOf(a, b) { var result; try { if (typeof(a) != "number" typeof(b) != "number") throwMyException("The arguments to sineOf() must be numeric"); if (!isFinite(a) !isFinite(b)) throwMyException("The arguments to sineOf() must be finite"); result = Math.sin(a) * Math.cos(b) + Math.cos(a) * Math.sin(b); if (isNaN(result)) throwMyException("The result of the computation was not a number"); return result; } catch (theException) { alert("Incorrect invocation of sineOf(): " + theException.message); } } Invoking this function correctly, for example,
var myValue = sineOf(1, .5);
returns the correct value; but an incorrect invocation,
var myValue = sineOf(1, ".5");
results in an exception, in this case:
Exceptions in the Real World
Exceptions are the method of choice for notification of and recovery from problematic conditions, but the reality is that they are not well supported even in many modern Web browsers. To accommodate the non-ECMAScript Error properties of Internet Explorer 5. x and Netscape 6, you will probably have to do some sort of browser detection in order to extract useful information. While it might be useful to have simple exception handling, such as
try { // do something IE or Netscape specific } catch ( theException ) { } that is designed to mask the possible failure of an attempt to access proprietary browser features, the real application of exceptions at the current moment is to Java applets and the DOM.
By enclosing potentially dangerous code such as LiveConnect calls to applets and the invocation of DOM methods in try/catch constructs, you can bring some of the robustness of more mature languages to JavaScript. However, using exception handling in typical day-to-day scripting tasks is probably still a few years in the future. For the time being, JavaScript s exception handling features are best used in situations where some guarantee can be made about client capabilities ”for example, by applying concepts from the following two sections. Use them if you can guarantee that your users browsers support them; otherwise, they re best avoided.
Capability and Browser Detection
We ve seen some examples of capability and browser detection throughout the book, but there remain a few relevant issues to discuss. To clarify terminology in preparation for this discussion, we define capability detection as probing for support for a specific object, property, or method in the user s browser. For example, checking for document.all or document.getElementById would constitute capability detection. We define browser detection as determining which browser, version, and platform is currently in use. For example, parsing the navigator.userAgent would constitute browser detection.
Often, capability detection is used to infer browser information. For example, we might probe for document. layers and infer from its presence that the bro`wser is Netscape 4. x . The other direction holds as well: often capability assumptions are made based upon browser detection. For example, the presence of MSIE 6.0 and Windows in the userAgent string might be used to infer the ability to use JavaScript s exception handling features.
When you step back and think about it, conclusions drawn from capability or browser detection can easily turn out to be false. In the case of capability detection, recall from Chapter 17 that the presence of navigator.plugins in no way guarantees that a script can probe for support for a particular plug-in. Internet Explorer does not support plug-in probing, but defines navigator.plugins[] anyway as a synonym for document.embeds[] . Drawing conclusions from browser detection can be equally as dangerous. Although Opera has the capability to masquerade as Mozilla or Internet Explorer (by changing its userAgent string), both Mozilla and Internet Explorer implement a host of features not found in Opera.
While it is clear that there are some serious issues here that warrant consideration, it is not clear exactly what to make of them. Instead of coming out in favor of one technique over another, we list some of the pros and cons of each technique and suggest that a combination of both capability and browser detection is appropriate for most applications.
The advantages of capability detection include
-
You are free from writing tedious case-by-case code for various browser version and platform combinations.
-
Users with third-party browsers or otherwise alternative browsers (such as text browsers) will be able to take advantage of functionality that they would otherwise be prevented from using because of an unrecognized userAgent (or related) string. Capability detection is forward safe in the sense that new browsers emerging in the market will be supported without changing your code, so long as they support the capabilities you utilize.
Disadvantages of capability detection include
-
The appearance of a browser to support a particular capability in no way guarantees that the capability functions the way you think it does. For example, consider that navigator.plugins[ ] in Internet Explorer is available but does not provide any data.
-
The support of one particular capability does not necessarily imply support for related capabilities. For example, it is entirely possible to support document.getElementById() but not support Style objects. The task of verifying each capability you intend to use can be rather tedious.
The advantage of browser detection includes
-
Once you have determined the user s browser correctly, you can infer support for various features with relative confidence, without having to explicitly detect each capability you intend to use.
The disadvantages of browser detection include
-
Support for various features often varies widely across platforms, even in the same version of the browser (for example, DHTML Behaviors are not supported in Internet Explorer across platforms as the Mac OS does not implement them).
-
You must write case-by-case code for each browser or class of browsers that you intend to support. As new versions and browsers continue to hit the market, this prospect looks less and less attractive.
-
Users with third-party browsers may be locked out of functionality their browsers support simply by virtue of an unrecognized userAgent .
-
Browser detection is not necessarily forward safe. That is, if a new version of a browser or an entirely new browser enters the market, you will in all likelihood be required to modify your scripts to accommodate the new userAgent .
-
There is no guarantee that a valid userAgent string will be transmitted.
-
There is no guarantee that the userAgent value is not falsified.
The advent of the DOM offers hope for a simplification of these issues. At the time of this edition s publication (2004), more than 75 percent of users have browsers that support most if not all commonly used DOM0 and DOM1 features (Internet Explorer 6+, Netscape 6+, and Mozilla 1+). While this number will increase, there s no guarantee that your users will be average. Additionally, if your site must be maximally compatible with your user base (e.g., you re running an e-commerce site), you have no choice but to do some sort of capability or browser detection to accommodate old browsers.
We offer the following guidelines to help you make your decisions:
-
Standard features (such as DOM0 and DOM1) are probably best detected using capabilities. This follows from the assumption that support for standards is relatively useless unless the entire standard is implemented. Additionally, it permits users with third-party standards-supporting browsers the use of such features without the browser vendor having to control the market or have their userAgent recognized.
-
Support for proprietary features is probably best determined with browser detection. This follows from the fact that such features are often difficult to capability-detect properly and from the fact that you can fairly easily determine which versions and platforms of a browser support the features in question.
These guidelines are not meant to be the final word in capability versus browser detection. Careful consideration of your project requirements and prospective user must factor into the equation in a very significant way. Whatever your choice, it is important to bear in mind that there is another tool you can add to your defensive programming arsenal for accomplishing the same task.
Code Hiding
Browsers are supposed to ignore the contents of << script >> tags with language or type attributes that they do not recognize. We can use this to our advantage by including a cascade of << script >>s in the document, each targeting a particular language version. The << script >> tags found earlier in the markup target browsers with limited capabilities, while those found later in sequence can target increasingly specific, more modern browsers.
The key idea is that there are two kinds of code hiding going on at the same time. By enclosing later scripts with advanced functionality in elements with appropriate language attributes (for example, JavaScript1.5 ), their code is hidden from more primitive browsers because these scripts are simply ignored. At the same time, the more primitive code can be hidden from more advanced browsers by replacing the old definitions with new ones found in later tags.
To illustrate the concept more clearly, suppose we wanted to use some DOM code in the page when the DOM is supported, but also want to degrade gracefully to more primitive non-standard DHTML functionality when such support is absent. We might use the following code, which redefines a writePage() function to include advanced functionality, depending upon which version of the language the browser supports:
<<script language="JavaScript">> <<!-- function writePage() { // code to output primitive HTML and JavaScript for older browsers } //-->> <</script>> <<script language="JavaScript1.3">> <<! function writePage() { // code to output more advanced HTML and JavaScript that utilizes the DOM} } // -->> <</script>> <<script language="JavaScript">> <<!-- // actually write out the page according to which writePage is defined writePage(); //-->> <</script>> Because more modern browsers will parse the second << script >>, the original definition of writePage() is hidden. Similarly, the second << script >> will not be processed by older browsers, because they do not recognize its language attribute.
| Note | While the language attribute is considered non-standard, you can see that it is much more flexible than the standard type attribute and thus the attribute continues to be used widely. |
If you keep in mind the guidelines for the language attributes given in Table 23-5, you can use this technique to design surprisingly powerful cascades (as will be demonstrated momentarily).
| language Attribute | Supported By |
|---|---|
| JScript | All scriptable versions of Internet Explorer and Opera 5+ |
| JavaScript | All scriptable versions of Internet Explorer, Opera, and Netscape |
| JavaScript1.1 | Internet Explorer 4+, Opera 3+, Mozilla, and Netscape 3+ |
| JavaScript1.2 | Internet Explorer 4+, Opera 3+, Mozilla, and Netscape 4+ |
| JavaScript1.3 | Internet Explorer 5+, Opera 4+, Mozilla, and Netscape 4.06+ |
| JavaScript1.5 | Opera 5+, Mozilla, and Netscape 6+ |
| Note | Opera 3 parses any << script >> with its language attribute beginning with JavaScript. |
To glimpse the power that the language attribute affords us, suppose that you wanted to include separate code for ancient browsers, Netscape 4, Mozilla, and Internet Explorer 4+. You could do so with the following:
<<script language="JScript">> <<!-- // set a flag so we can differentiate between Netscape and IE later on var isIE = true; //-->> <</script>> <<script language="JavaScript">> <<!-- function myFunction() { // code to do something for ancient browsers } //-->> <</script>> <<script language="JavaScript1.2">> <<!-- if (window.isIE) { function myFunction() { // code to do something specific for Internet Explorer 4+ } } else { function myFunction() { // code to do something specific for Netscape 4 } } //-->> <</script>> <<script language="JavaScript1.5">> <<!-- function myFunction() { // code to do something specific for Mozilla and Opera 5+ } //-->> <</script>> <<noscript>> <<strong>>Error:<</strong>>JavaScript not supported <</noscript>> We ve managed to define a cross-browser function, myFunction() , for four different browsers using only the language attribute and a little ingenuity! Combined with some simple browser detection, this technique can be very powerful indeed.
| Note | Always remember the language attribute is deprecated under HTML 4, so don t expect your pages to validate as strict HTML 4 or XHTML when using this trick. The upside is that all modern browsers continue to support the attribute even though it is no longer officially a part of the language. |
Remember that it is always good style to include << noscript >>s for older browsers or browsers in which JavaScript has been disabled. We provided a very basic example of << noscript >> here, but if we followed very defensive programming styles, each piece of code in this book should properly have been followed by a << noscript >> indicating that JavaScript is required or giving alternative functionality for the page, or indicating that a significant error has occurred. We omitted such << noscript >>s in most cases for the sake of brevity and clarity, but we would always include them in a document that was live on the Web. See Chapter 1 for a quick << noscript >> refresher. We now turn our attention toward general practices that are considered good coding style.
EAN: 2147483647
Pages: 209