Not All Commands on All UNIX Variants
| A variety of commands are covered in this chapter, including:
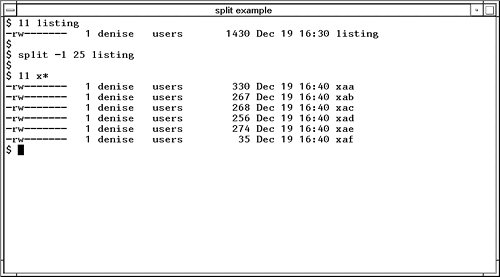
I cover many useful and enjoyable commands in this chapter. All the commands, however, are not available on all UNIX variants. If a specific command is not available on your system, then you probably have a similar command or can combine more than one command to achieve the desired result. splitSome files are just too long. The file listing we earlier looked at may be more easily managed if split into multiple files. We can use the split command to make listing into files 25 lines long, as shown in Figure 23-1: Figure 23-1. split Command Note that the split command produced several files from listing , called xaa, xab , and so on. The -l option is used to specify the number of lines in files produced by split . Here is a summary of the split command: split - Split a file into multiple files.
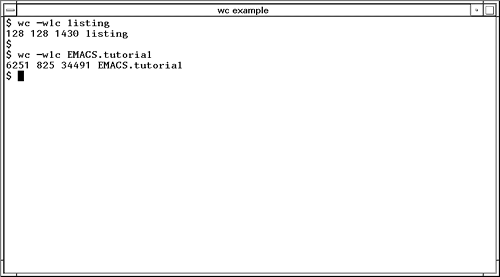
wcWe know that we have split listing into separate files of 25 lines each, but how many lines were in listing originally? How about the number of words in listing ? Those of us who get paid by the word for some of the articles we write often want to know. How about the number of characters in a file? The wc command can produce a word, line, and character count for you. Figure 23-2 shows issuing the wc command with the -wlc options, which produce a count of words with the -w option, lines with the -l option, and characters with the -c option. Figure 23-2. wc Command Notice that the number of words and lines produced by wc is the same for the file listing . The reason is that each line contains exactly one word. When we display the words, lines, and characters with the wc command for the text file EMACS.tutorial , we can see that the number of words is 6251 , the number of lines is 825 , and the number of characters is 34491 . In a text file, in this case a tutorial, you would expect many more words than lines. Here is a summary of the wc command: wc - Produce a count of words, lines, and characters.
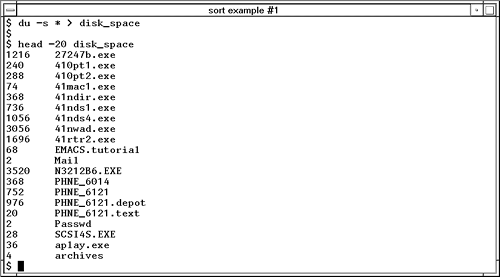
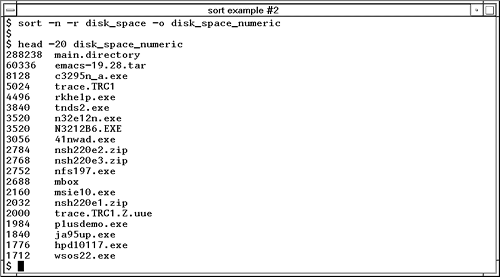
sortSometimes the contents of files are not sorted in the way you would like. You can use the sort command to sort files with a variety of options. You may find as you use your UNIX system more and more that your system administrator is riding you about the amount of disk space you are consuming. You can monitor the amount of disk space you are consuming with the du command. Figure 23-3 shows creating a file called disk_space that lists the amount of disk space consumed by files and directories and shows the first 20 lines of the file: Figure 23-3. sort Command Example #1 Notice that the result is sorted alphabetically. In many cases, this is what you want. If the file were not sorted alphabetically , you could use the sort command to do so. In this case, we don't care as much about seeing entries in alphabetical order as we do in numeric order, that is, the files and directories that are consuming the most space. Figure 23-4 shows sorting the file disk_space numerically with the -n option and reversing the order of the sort with the -r option so that the biggest numbers appear first. We then specify the output file name with the -o option. Figure 23-4. sort Command Example #2 What if the items being sorted had many more fields than our two-column disk usage example? Let's go back to the passwd.test file for a more complex sort. Let's cat passwd.test so we can again see its contents: Now let's use sort to determine which users are in the same group . Fields are separated in passwd.test by a colon (:). The fourth field is the group to which a user belongs. For instance, bin is in group 1, daemon in group 2 , and so on. To sort by group, we would have to specify three options to the sort command. The first is to specify the delimiter (or field separator) of colon (:) using the -t option. Next we would have to specify the field on which we wish to sort with the -k option. Finally, we want a numeric sort, so use the -n option. The following example shows a numeric sort of the passwd.test file by the fourth field: # sort -t: -k4 -n passwd.test halt:*:7:0:halt:/sbin:/sbin/halt operator:*:11:0:operator:/root: root:PgYQCkVH65hyQ:0:0:root:/root:/bin/bash sync:*:5:0:sync:/sbin:/bin/sync bin:*:1:1:bin:/bin: daemon:*:2:2:daemon:/sbin: adm:*:3:4:adm:/var/adm: lp:*:4:7:lp:/var/spool/lpd: shutdown:*:6:11:shutdown:/sbin:/sbin/shutdown mail:*:8:12:mail:/var/spool/mail: news:*:9:13:news:/var/spool/news: uucp:*:10:14:uucp:/var/spool/uucp: man:*:15:15:Manuals Owner:/: gopher:*:13:30:gopher:/usr/lib/gopher-data: ftp:*:14:50:FTP User:/home/ftp: col:Wh0yzfAV2qm2Y:100:100:Caldera OpenLinux User:/home/col:/bin/bash games:*:12:100:games:/usr/games: nobody:*:65534:65534:Nobody:/:/bin/false The following is a summary of the sort command. sort - Sort lines of files (alphabetically by default).
cmp, diff, and commA fact of life is that as you go about editing files, you may occasionally lose track of what changes you have made to which files. You may then need to make comparisons of files. Let's take a look at three such commands, cmp, diff , and comm , and see how they compare files. Let's assume that we have modified a script called llsum . The unmodified version of llsum was saved as llsum.orig . Using the head command, we can view the first 20 lines of llsum and then the first 20 lines of llsum.orig : # head -20 llsum # #!/bin/sh # Displays a truncated long listing (ll) and # displays size statistics # of the files in the listing. ll $* \ awk ' BEGIN { x=i=0; printf "%-25s%-10s%8s%8s\n",\ "FILENAME","OWNER","SIZE","TYPE" } ~ /^[-dlps]/ {# line format for normal files printf "%-25s%-10s%8d",,, x = x + i++ } ~ /^-/ { printf "%8s\n","file" } # standard file types ~ /^d/ { printf "%8s\n","dir" } ~ /^l/ { printf "%8s\n","link" } ~ /^p/ { printf "%8s\n","pipe" } ~ /^s/ { printf "%8s\n","socket" } ~ /^[bc]/ { # line format for device files printf "%-25s%-10s%8s%8s\n",,,"","dev" } # # head -20 llsum.orig # #!/bin/sh # Displays a truncated long listing (ll) and # displays size statistics # of the files in the listing. ll $* \ awk ' BEGIN { x=i=0; printf "%-16s%-10s%8s%8s\n",\ "FILENAME","OWNER","SIZE","TYPE" } ~ /^[-dlps]/ {# line format for normal files printf "%-16s%-10s%8d",,, x = x + i++ } ~ /^-/ { printf "%8s\n","file" } # standard file types ~ /^d/ { printf "%8s\n","dir" } ~ /^l/ { printf "%8s\n","link" } ~ /^p/ { printf "%8s\n","pipe" } ~ /^s/ { printf "%8s\n","socket" } ~ /^[bc]/ { # line format for device files printf "%-16s%-10s%8s%8s\n",,,"","dev" } I'm not sure what changes I made to llsum.orig to improve it, so we can first use cmp to see whether indeed differences exist between the files. $ $ cmp llsum llsum.orig llsum llsum.orig differ: char 154, line 6 $ cmp does not report back much information, only that character 154 in the file at line 6 is different in the two files. There may indeed be other differences, but this is all we know about so far. To get information about all of the differences in the two files, we could use the -l option to cmp : $ cmp -l llsum llsum.orig 154 62 61 155 65 66 306 62 61 307 65 66 675 62 61 676 65 66 This is not all that useful an output, however. W want to see not only the position of the differences, but also the differences themselves . Now we can use diff to describe all the differences in the two files: $ diff llsum llsum.orig 6c6 < awk ' BEGIN { x=i=0; printf "%-25s%-10s%8s%8s\n",\ --- > awk ' BEGIN { x=i=0; printf "%-16s%-10s%8s%8s\n",\ 9c9 < printf "%-25s%-10s%8d",,, --- > printf "%-16s%-10s%8d",,, 19c19 < printf "%-25s%-10s%8s%8s\n",,,"","dev" --- > printf "%-16s%-10s%8s%8s\n",,,"","dev" $ We now know that lines 6, 9 , and 25 are different in the two files and these lines are also listed for us. From this listing, we can see that the number 16 in llsum.orig was changed to 25 in the newer llsum file, and this accounts for all of the differences in the two files. The "less than" sign (<) precedes lines from the first file, in this case llsum . The "greater than" sign (>) precedes lines from the second file, in this case llsum.orig . I made this change, starting the second group of information from character 16 to character 25 , because I wanted the second group of information, produced by llsum, to start at column 25 . The second group of information is the owner, as shown in the following example: $ llsum FILENAME OWNER SIZE TYPE README denise 810 file backup_files denise 3408 file biography denise 427 file cshtest denise 1024 dir gkill denise 1855 file gkill.out denise 191 file hostck denise 924 file ifstat denise 1422 file ifstat.int denise 2147 file ifstat.out denise 723 file introdos denise 54018 file introux denise 52476 file letter denise 23552 file letter.auto denise 69632 file letter.auto.recover denise 71680 file letter.backup denise 23552 file letter.lck denise 57 file letter.recover denise 69632 file llsum denise 1267 file llsum.orig denise 1267 file llsum.out denise 1657 file llsum.tomd.out denise 1356 file psg denise 670 file psg.int denise 802 file psg.out denise 122 file sam_adduser denise 1010 file tdolan denise 1024 dir trash denise 4554 file trash.out denise 329 file typescript denise 2017 file The files listed occupy 393605 bytes (0.3754 Mbytes) Average file size is 13120 bytes $ When we run llsum.orig , clearly the second group of information, which is the owner , starts at column 16 and not column 32: $ llsum.orig FILENAME OWNER SIZE TYPE README denise 810 file backup_files denise 3408 file biography denise 427 file cshtest denise 1024 dir gkill denise 1855 file gkill.out denise 191 file hostck denise 924 file ifstat denise 1422 file ifstat.int denise 2147 file ifstat.out denise 723 file introdos denise 54018 file introux denise 52476 file letter denise 23552 file letter.auto denise 69632 file letter.auto.rec denise 71680 file letter.backup denise 23552 file letter.lck denise 57 file letter.recover denise 69632 file llsum denise 1267 file llsum.orig denise 1267 file llsum.out denise 1657 file llsum.tomd.out denise 1356 file psg denise 670 file psg.int denise 802 file psg.out denise 122 file sam_adduser denise 1010 file tdolan denise 1024 dir trash denise 4554 file trash.out denise 329 file typescript denise 3894 file The files listed occupy 395482 bytes (0.3772 Mbytes) Average file size is 13182 bytes script done on Mon Dec 11 12:59:18 $ We can compare two sorted files using comm and see the lines that are unique to each file, as well as the lines found in both files. When we compare two files with comm , the lines that are unique to the first file appear in the first column, the lines unique to the second file appear in the second column, and the lines contained in both files appear in the third column. Let's go back to the /etc/passwd file to illustrate this comparison. We'll compare two /etc/passwd files, the active /etc/passwd file in use and an old /etc/passwd file from a backup: # comm /etc/passwd /etc/passwd.backup root:PgYQCkVH65hyQ:0:0:root:/root:/bin/bash bin:*:1:1:bin:/bin: daemon:*:2:2:daemon:/sbin: adm:*:3:4:adm:/var/adm: lp:*:4:7:lp:/var/spool/lpd: sync:*:5:0:sync:/sbin:/bin/sync shutdown:*:6:11:shutdown:/sbin:/sbin/shutdown halt:*:7:0:halt:/sbin:/sbin/halt mail:*:8:12:mail:/var/spool/mail: news:*:9:13:news:/var/spool/news: uucp:*:10:14:uucp:/var/spool/uucp: operator1:*:12:0:operator:/root: operator:*:11:0:operator:/root: games:*:12:100:games:/usr/games: gopher:*:13:30:gopher:/usr/lib/gopher-data: ftp:*:14:50:FTP User:/home/ftp: man:*:15:15:Manuals Owner:/: nobody:*:65534:65534:Nobody:/:/bin/false col:Wh0yzfAV2qm2Y:100:100:Caldera OpenLinux User:/home/col:/bin/bash You can see from this output that the user games appears only in the active /etc/passwd file, the user operator1 appears only in the /etc/passwd.backup file, and all of the other entries appear in both files. The following is a summary of the cmp and diff commands. cmp - Compare the contents of two files. The byte position and line number of the first difference between the two files is returned.
diff - Compares two files and reports differing lines.
dircmpWhy stop at comparing files? You will probably have many directories in your user area as well. dircmp compares two directories and produces information about the contents of directories. To begin with let's perform a long listing of two directories: $ ls -l krsort.dir.old total 168 -rwxr-xr-x 1 denise users 34592 Oct 31 11:27 krsort -rwxr-xr-x 1 denise users 3234 Oct 31 11:27 krsort.c -rwxr-xr-x 1 denise users 32756 Oct 31 11:27 krsort.dos -rw-r--r-- 1 denise users 9922 Oct 31 11:27 krsort.q -rwxr-xr-x 1 denise users 3085 Oct 31 11:27 krsortorig.c $ $ ls -l krsort.dir.new total 168 -rwxr-xr-x 1 denise users 34592 Oct 31 15:17 krsort -rwxr-xr-x 1 denise users 32756 Oct 31 15:17 krsort.dos -rw-r--r-- 1 denise users 9922 Oct 31 15:17 krsort.q -rwxr-xr-x 1 denise users 3234 Oct 31 15:17 krsort.test.c -rwxr-xr-x 1 denise users 3085 Oct 31 15:17 krsortorig.c $ From this listing, you can see clearly that one file is unique to each directory. krsort.c appears in only the krsort.dir.old directory, and krsort.test.c appears in only the krsort.dir.new directory. Let's now use dircmp to inform us of the differences in these two directories: $ dircmp krsort.dir.old krsort.dir.new krsort.dir.old only and krsort.dir.new only Page 1 ./krsort.c ./krsort.test.c Comparison of krsort.dir.old krsort.dir.new Page 1 directory . same ./krsort same ./krsort.dos same ./krsort.q same ./krsortorig.c $ This is a useful output. First, the files that appear in only one directory are listed. Then the files common to both directories are listed. The following is a summary of the dircmp command. dircmp - Compare directories.
cutThere are times when you have an output that has too many fields in it. When we issued the llsum command earlier, it produced four fields: FILENAME, OWNER, SIZE , and TYPE . What if we want to take this output and look at just the FILENAME and SIZE . We could modify the llsum script, or we could use the cut command to eliminate the OWNER and TYPE fields with the following commands: $ llsum cut -c 1-25,37-43 FILENAME SIZE README 810 backup_files 3408 biography 427 cshtest 1024 gkill 1855 gkill.out 191 hostck 924 ifstat 1422 ifstat.int 2147 ifstat.out 723 introdos 54018 introux 52476 letter 23552 letter.auto 69632 letter.auto.recover 71680 letter.backup 23552 letter.lck 57 letter.recover 69632 llsum 1267 llsum.orig 1267 llsum.out 1657 llsum.tomd.out 1356 psg 670 psg.int 802 psg.out 122 sam_adduser 1010 tdolan 1024 trash 4554 trash.out 329 typescript 74 The files listed occupy 3 (0.373 Average file size is 1305 $
$ ./llsum grep -v "bytes" cut -c 1-25,37-43 FILENAME SIZE README 810 backup_files 3408 biography 427 cshtest 1024 gkill 1855 gkill.out 191 hostck 924 ifstat 1422 ifstat.int 2147 ifstat.out 723 introdos 54018 introux 52476 letter 23552 letter.auto 69632 letter.auto.recover 71680 letter.backup 23552 letter.lck 57 letter.recover 69632 llsum 1267 llsum.orig 1267 llsum.out 1657 llsum.tomd.out 1356 psg 670 psg.int 802 psg.out 122 sam_adduser 1010 tdolan 1024 trash 4554 trash.out 329 typescript 1242 $ llsum grep -v "bytes" cut -c 1-25,37-4_3 > llsum.out $ The following is a summary of the cut command, with some of the more commonly used options. cut - Extract specified fields from each line.
paste and joinFiles can be merged together in a variety of ways. If you want to merge files on a line-by-line basis, you can use the paste command. The first line in the second file is pasted to the end of the first line in the first file, and so on. Let's use the cut command just covered and extract only the permissions field, or characters 1 through 10 , to get only the permissions for files. We'll then save these in the file ll.out : $ ls -al cut -c 1-10 total 798 drwxrwxrwx drwxrwxrwx -rwxrwxrwx -rwxrwxrwx -rwxrwxrwx drwxr-xr-x -rwxrwxrwx -rw-r--r-- -rwxrwxrwx -rwxrwxrwx -rwxr-xr-x -rw-r--r-- -rw-r--r-- -rwxrwxrwx -rw-r--r-- -rw-r--r-- -rw-r--r-- -rw-r--r-- -rw-rw-rw- -rw-r--r-- -rw-r--r-- -rwxrwxrwx -rwxr-xr-x -rw-r--r-- -rw-r--r-- -rwxrwxrwx -rwxr-xr-x -rw-r--r-- -rwxrwxrwx drwxr-xr-x -rwxrwxrwx -rw-r--r-- -rw-r--r-- $ ls -al cut -c 1-10 > ll.out $ We can now use the paste command to paste the permissions saved in the ll.out file to the other file- related information in the llsum.out file: $ paste llsum.out ll.out FILENAME SIZE total 792 README 810 -rwxrwxrwx backup_files 3408 -rwxrwxrwx biography 427 -rwxrwxrwx cshtest 1024 drwxr-xr-x gkill 1855 -rwxrwxrwx gkill.out 191 -rw-r--r-- hostck 924 -rwxrwxrwx ifstat 1422 -rwxrwxrwx ifstat.int 2147 -rwxr-xr-x ifstat.out 723 -rw-r--r-- introdos 54018 -rw-r--r-- introux 52476 -rwxrwxrwx letter 23552 -rw-r--r-- letter.auto 69632 -rw-r--r-- letter.auto.recover 71680 -rw-r--r-- letter.backup 23552 -rw-r--r-- letter.lck 57 -rw-rw-rw- letter.recover 69632 -rw-r--r-- ll.out 1057 -rw-r--r-- llsum 1267 -rwxrwxrwx llsum.orig 1267 -rwxr-xr-x llsum.out 1657 -rw-r--r-- llsum.tomd.out 1356 -rw-r--r-- psg 670 -rwxrwxrwx psg.int 802 -rwxr-xr-x psg.out 122 -rw-r--r-- sam_adduser 1010 -rwxrwxrwx tdolan 1024 drwxr-xr-x trash 4554 -rwxrwxrwx trash.out 329 -rw-r--r-- typescript 679 -rw-r--r-- $ This has produced a list that includes FILENAME and SIZE from llsum.out and permissions from ll.out . If both files have the same first field, you can use the join command to merge the two files: The following is a summary of the paste and join commands, with some of the more commonly used options: paste - Merge lines of files.
join - Combine two presorted files that have a common key field.
trtr translates characters. tr is ideal for such tasks as changing case. For instance, what if you want to translate all lowercase characters to upper case? The following example shows listing files that have the suffix "zip" and then translates these files into uppercase: $ ls -al *.zip file1.zip file2.zip file3.zip file4.zip file5.zip file6.zip file7.zip $ ls -al *.zip tr "[:lower:]" "[:upper:]" FILE1.ZIP FILE2.ZIP FILE3.ZIP FILE4.ZIP FILE5.ZIP FILE6.ZIP FILE7.ZIP $ We use brackets in this case because we are translating a class of characters. The following is a summary of the tr command, with some of the more commonly used options. tr - Translate characters.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
EAN: 2147483647
Pages: 301