Byte Ordering
| [ LiB ] |
Before I delve into the socket theory, I want to discuss a nasty aspect of network programming byte ordering . Almost everyone I know grumbles when this topic is mentioned.
A long, long time ago in a galaxy not so far away, computers had small amounts of memory and small data busses . The size of the data bus in a computer is typically called the word size . For example, some of the first computers had a bus size of 4 bits, and thus their word sizes were 4 bits.
NOTE
This is an inside joke in the com puter world: Groups of 4-bit data are referred to as nibbles , which fits into the whole bit and byte theme.
Obviously, there was only so much a 4-bit CPU could do, so larger machines were invented that used 8-bit data. These machines became the standard for awhile, and the 8-bit data size became the standard atomic data structure, which meant that the smallest single piece of data you could store was 8 bits, also called a byte.
I don't want to dive too far into a discussion of binary math, so I'll briefly cover only what you need to know.
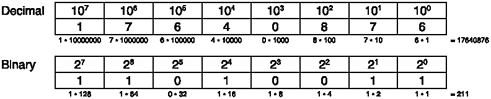
In any number system, the digit furthest to the right has the least significance ( assuming the number is written left to right). In decimal, the digit furthest to the right is the ones column, the next is the tens column, then the hundreds, and so on. The same goes for binary, except the columns are ones, twos , and fours, each doubling the value of the previous as shown in Figure 2.1.
Figure 2.1. The juxtaposition of columns contrasts the arrangement of the digits of base 10 and base 2 numbers .
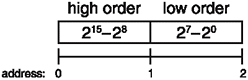
So when you increase the size of the data from 8 to 16 bits, you would naturally assume that the new 8 bits, representing the higher-order bits of the number, would appear to the left of the lower-order bits, as shown in Figure 2.2.
Figure 2.2. A mathematical representation of a 16-bit number in a computer.
Unfortunately, things aren't that simple. When computers started switching over to 16 bits, people realized that they had a heck of a lot of code still running on 8-bit systems; the chip designers thought it would be a great idea to have a 16-bit processor and also be able to run 8-bit code. Backward compatibility is a wonderful thing, after all.
Well, due to the limitations of computer architectures, 16-bit processors also needed their memory aligned to 16-bit boundaries and stored in 16-bit areas of memory, even if the data was just 8 bits. Therefore, if you put an 8-bit piece of data into memory (without clever byte manipulations, of course), the compiler converts it to 16 bits and stores it aligned on a 16-bit boundary. Looking back at Figure 2.2 may help you picture this concept. In Figure 2.2, the data is being stored at address 0, but the actual data is placed at address 1, and a value of 0 is placed at address 0.
So, imagine what would happen if later on you wanted to retrieve that 8-bit value by using a pointer. You would load up address 0 and treat that as a byte and load that. But... oops! The data is actually at byte 1!
You could certainly have the processor auto-translate addresses, but that would make the processor much more complicated, and more complicated processors are slower and more expensive.
So, the solution that most chipmakers adopted was swapping the byte ordering, as shown in Figure 2.3. That way, both 8-bit and 16-bit programs know where their data is. The data in Figure 2.2 is said to be stored in big-endian format, and the data in Figure 2.3 is called little-endian .
Figure 2.3. Compare Figures 2.2 and 2.3 to see how the byte order was swapped.
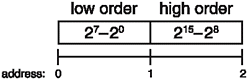
Unfortunately, this made a huge mess for us all, because some chips use little-endian, and some chips use big-endian. When these computers attempt to communicate with each other with data larger than a byte, problems ensue.
NOTE
The big-little-endian reference is actually an inside joke from the classic novel Gulliver's Travels , by Jonathan Swift (which is a scathing political commentary , not a children's tale, but that's a story for another day). In the book, two clans constantly argue over which side of a hard-boiled egg should be eaten firstthe little end or the big end. They are called, respectively, the little-endians and the big-endians. You learn something new every day.
Obviously, this is a huge problem for networking, since there must be a standard byte ordering for data over a network. Therefore, when the Internet was first created, the creators decided to use big-endian for the network byte order . Everything in every packet header is supposed to be in big-endian, the proper mathematical ordering. How the data is organized outside of the protocol headers is really up to you and how you design your Application layer protocols, but it is usually recommended that you keep data in big-endian for consistency's sake.
Now, the important question is this: How do I convert data from my host byte order (which may or may not be big-endian, depending on the system) to the network byte order? The Sockets API was nice enough to include four functions for just this purpose:
// host to network long: unsigned long htonl( unsinged long ); // network to host long: unsigned long ntohl( unsigned long ); // host to network short: unsigned short htons( unsigned short ); // network to host short: unsigned short ntohs( unsigned short );
Now that we've got that out of the way, on to the beef!
| [ LiB ] |
EAN: 2147483647
Pages: 147