Interactive Data Mining
|
| < Day Day Up > |
|
Interactive data mining is a process whereby the user can guide the knowledge discovery. It is achieved by dynamically presenting the results of the data mining process and incorporating interactive capabilities within the presentation environment. This allows the user to interact with the underlying mining process. Through such interaction the user is able to guide the mining process and steer the discovery process to areas of user interest.
The iterative knowledge discovery process is illustrated in Figure 29. This process is controlled by user specification of data sources, tools, and associated parameters. The process includes data collection (possibly from multiple heterogenous sources), preprocessing (which massages the data into a form required for analysis), analysis (mining), presentation, and finally interpretation by the user. This widely accepted model of the knowledge discovery process shows each stage as being independent, with the interaction between stages constrained to the piping of the output of one stage to the input of the next stage. Depending upon the extent to which the results satisfy the user's goals, the user may refine the specification of tools and parameters and "re-cook" the results. This "re-cooking" or iteration of the knowledge discovery process or portions thereof can be a time expensive exercise, with the stages of collection, preprocessing and analysis requiring many hours of work for large or complex data sets.
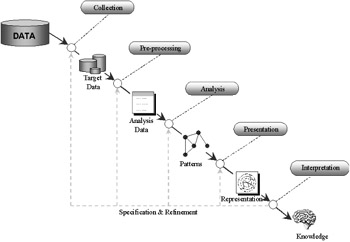
Figure 29: Knowledge discovery process
Some researchers report that the initial specification of the collection and preprocessing stages can take up to 60% of the processing time. However because the user has a high degree of control over these processes and can specify exactly what is required, refinement is typically unnecessary. The analysis or mining stage, however, is generally batch oriented, so the user has no control over the process. User refinement and "re-cooking" generally occur at the analysis stage, with the user tweaking the mining algorithm's parameters in an attempt to produce results of greater interest. It is this lack of user control within the analysis process that is rectified by incorporating interactive capabilities within the mining process.
Involving the user in the mining process requires an interface whereby the user can see and guide the mining. In this way, the coupling between the analysis and presentation stages is strengthened by providing real-time streaming of analysis results to the presentation tool for user interpretation and by all owing the subsequent guidance of the mining algorithm through user interaction with the presentation.
Figure 30 shows the changes to the process. The change results in the merging of the analysis and presentation stages, although current research is focused on maintaining stage independence and increasing the coupling through the specification of a generic set of interface methods that capture the required interactive functionality. This technology will provide flexibility by allowing the user to select the presentation technique that best suits their current needs. Examples of this technology are the FIDO project currently being undertaken at Flinders University (Roddick & Ceglar, 2001) and the KESO project at the University of Helsinki (Wrobel et al., 1996).
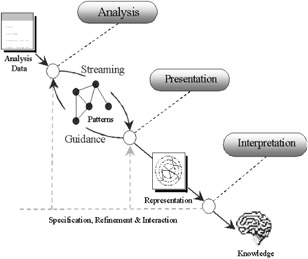
Figure 30: Guided knowledge discovery process
Increased coupling between the analysis and presentation stages is illustrated in Figures 31 and 32, which differentiate between a batch and interactive mining run. The four images comprising these figures represent data mining runs as a tree structure with each level implying a point in time. The time interval is not constant but indicates a point at which the mining algorithm reaches a stage where intermediate results may be produced. The production of intermediate results is algorithm dependent; however, most exploratory mining algorithms, for example, A priori and K-means, involve multiple iterations over the dataset, which provide natural processing stages. Where the algorithm requires only a single pass, techniques such as sampling can be used to provide intermediate results. Within Figures 32 and 33, the nodes within each tree level indicate the discovered information at that point in time; the blue nodes represent intermediate results and the red nodes represent terminal results.
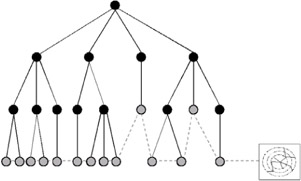
Figure 31: Batch data mining run
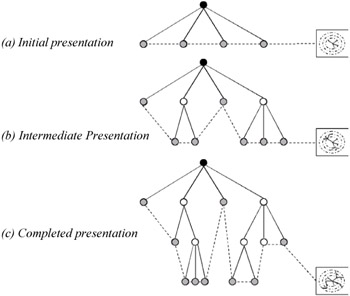
Figure 32: Interactive data mining run
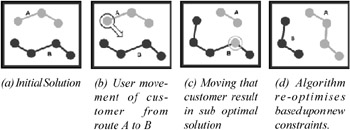
Figure 33: Repercussions of user movement of customer from route A to B (Rabejij, 2001)
Figure 31 presents a regular batch mining run where the terminal results are presented only at completion. If refinement is required, the entire mining run must be repeated. Figure 32 illustrates the guidance of the knowledge discovery process through interactive mining. These three diagrams show the production or update of the presentation at different stages during the analysis process, thus providing the user with insight into the process.
The initial presentation (Figure 32a) is generated based upon the available intermediate results. The user is then able to interact with this presentation to guide further processing, represented in Figure 32b by the green-coloured nodes that indicate the user's interest in these intermediate results. Further processing is then constrained to the intermediate results indicated by these nodes. Figure 32c illustrates the completed state of the exploration process, within which can be seen the inclusion of further guidance.
Comparing Figure 31 and Figure 32c highlights the advantages of interactive data mining. In particular the terminal result set is smaller, with less intermediate results being processed. This reduces mining time and produces less cluttered presentations. In addition the incorporation of subjective as well as objective measures of interest within guided knowledge discovery ensures that this smaller, more quickly produced result set will be of greater interest to the user. It is therefore also likely that less refinement and reprocessing will be required, further reducing mining time.
Other techniques used to reduce mining time, particularly in the case of association mining, are cache-based and constraint-based mining. Cache-based mining or dynamic mining involves the storage of the results of frequently requested queries for fast retrieval of mining over common sets (Nag, Deshpande & DeWitt, 1999; Raghavan & Hafez, 2000). Constraint-based mining includes techniques such as subset mining and the prior specification of constraints. Subset mining involves the mining of a subset of the data, the rules of which are then verified against the whole set (Toivonen, 1996). However, this method is probabilistic and may not discover some rules of interest. Prior constraint techniques involve the specification of Boolean expressions to constrain the mining process (Srikant, Vu & Agrawal, 1997). However it is often the case in explorative tasks that the user does not know beforehand what is of interest; only through the presentation of options can the user focus on what is of greater interest. Although these methods may reduce mining time, they do not preempt guided discovery through interaction and are not associated with the benefits it offers.
The granularity and types of interaction possible are dependent upon both the presentation type and mining task. The user may manipulate the mining process either in terms of its focus, its parameters or its constituent dataset by interacting with the associated real-time presentation. Figure 32 is indicative of an exclusion form of interaction whereby the user eliminates a node from further processing. A more advanced technique is that of priority interaction, whereby the user selects the nodes of interest, which are processed first and hence presented first. This doesn't exclude the further processing of the other nodes; it simply puts off this processing until the prioritised work has been completed. This ensures that eventually all elements will be processed, so all possibly interesting results are discovered while arranging for those of most interest (as specified by the user) to be processed first (Wrobel, Wettschereck, Verkamo, Siebes, Mannila, Kwakkel & Klosgen, 1996).
Although some researchers have investigated interaction in the context of data mining, most such systems actually incorporate forms of interactive views (Chu & Wong, 1998; Klemettinen et al., 1997; Ribarsky et al., 1999; Wills, 1998; Xiao & Dunham, 2001) or are iterative but allow refinement through graphical interaction (Kim, Kwon & Cook, 2000). The following subsections discuss those published works providing interactive capabilities in the fields of clustering and association mining.
Interactive Clustering
The Mitsubishi Electronic Research Laboratory (MERL) located at Cambridge University has investigated the use of interact on in explorative analysis to solve optimisation problems in the fields of vehicle routing (Anderson et al., 2000) and network partitioning (Lesh, Marks & Patrignani, 2000). This study centres on the human guided simple search (HuGSS) paradigm, which improves the effectiveness of a relatively simple search algorithm by allowing users to steer the search process interactively. The interactive capabilities provided by this system include the ability to escape local minima via manual editing and to focus searches into areas of promise.
An application to which the HuGSS paradigm has been applied is that of vehicle routing with time windows. This study involves the optimisation of goods delivery to a group of customers with the fewest trucks, while minimising the distance travelled by each truck. The system uses either a greedy or steep-descent clustering algorithm to determine the number of trucks and the routes they should take. The user specifies the number of steps in a search invocation. This effectively controls the number of automated allocation moves the computer can make before presenting a set of intermediate results to the user. Users have the opportunity to insert guidance primitives for the next invocation of automated allocation.
In this example, the user guides the route allocation process and escapes local minima by manually assigning customers to routes, in effect changing the cluster to which the item belongs. This automatically invokes a route optimisation algorithm on the affected routes only, ensuring that under these new constraints the systems still provides the best possible solution, as illustrated in Figure 33. The user can additionally change a customer's priority, which affects when the customer is considered for movement by the algorithm and changes the algorithm's associated objective measures and mode before invocating another sequence of automated route allocations. Figure 34 shows a snapshot of the completed routing allocation.
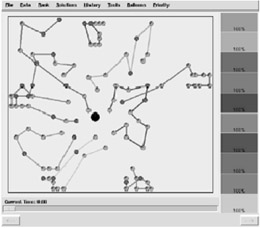
Figure 34: Routing interface snapshot (Anderson, Anderson, Lesh, Marks, Perlin, Ratajczak & Ryall, 2000)
The MERL group has also applied the HuGSS paradigm to the area of k-way network partitioning that required the development of a different set of presentation techniques to visualise the relevant aspects. This consequently led to the development of a new set of interaction mappings that effectively provide the same types of interactive guidance as the route discovery application (Lesh, Marks, & Patrignani, 2000). Other works (Nascimento & Eades, 2001) allows the user to interactively change cluster's number and size; however, the crucial element in MERL's research is the ability to guide the cluster membership of particular items. This research by MERL is the most significant published work in the field to date.
Interactive Association Mining
Research undertaken by Brin and Page (1998) at Stanford University appears to be the only piece of research that satisfies our criteria for guided association mining. Their work, which is known as dynamic data mining (DDM), attempts to produce more interesting rules by foregoing traditional support-based algorithms (that use a single deterministic run) and instead use a method that continuously explores more of the search space. This is accomplished through the incorporation of a user-defined measure of interest, Weight, which can be redefined dynamically, and a heuristic, Heavy Edge Property, which guides the exploration process.
Rather than the mining process being a single deterministic run (producing a well-defined set of item sets and rules), DDM invokes a process that continually generates improving item sets, based upon the dynamic item set counting algorithm (DIC) (Brin, Motwani, Ullman & Tsur, 1997). This allows the DDM to take advantage of intermediate counts to form an estimate of an item set's occurrence or weight, which results in the presentation of intermediate results to the user. The user is then able to dynamically adjust individual item weights, in effect prioritising them. User interaction is indirect and textual, with refinement occurring through an associated text box within which the user can adjust global mining parameters and individual item weights via a simple language.
This research provides a means of prioritising the mining of particular items and in effect allows the user to insert a subjective measure of interestingness into the algorithm. The technique will produce a more interesting and smaller set of results than traditional batch processing methods.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 174