Chapter 15: Debugging Distributed Systems
A distributed system is one where multiple processes on two or more machines cooperate with a common aim. One of the primary design goals of .NET was to make the design, development, and debugging of distributed systems significantly easier than it has been in the past. Both Web services and remoting were built with this goal in mind and have benefited from some of the hard lessons taught by technologies such as DCOM, COM+, RMI, and CORBA.
This chapter first looks at the type of problems that differentiate distributed applications from local applications and how to solve these problems. Then it examines how to set up and use remote debugging, and how to use the remote debugger to debug a distributed application that uses remoting. Finally, it covers an effective way of monitoring a distributed application.
Understanding Distributed Applications
This section takes a strategic look at the most common problems experienced by distributed applications. If you understand these problems before you start construction of your application, it's much easier to design your way around most of the problems. This can save you considerable debugging time, because debugging a distributed system can be significantly more complicated than debugging a local application. The idea driving this section is to give you sufficient information to design your distributed application properly.
Dealing with Failure
The defining difference between local and distributed applications is failure. This is because a remote method call has so many more ways of failing than a local method call. With a local method call, it normally just works. You simply don't expect it to fail, and the number of possible failures is very limited when both components are running on the same machine. When executing a remote method call, there are many possible failures, some of which appear in the following list:
-
There's a problem with Windows on the sending machine that prevents the request from reaching the network stack.
-
There's a problem with the network card on the sending machine.
-
There's a problem with one of the network cables ”the cable might be faulty, not plugged in properly, or even severed.
-
There's a problem with the network itself, such as a faulty network switch or router. Switch and router issues can cause network segmentation or even complete failure.
-
The receiving machine is either down or disconnected from the network for some reason.
-
There's a problem with the network card on the receiving machine.
-
There's a problem with Windows on the receiving machine that prevents the request from reaching the receiving component.
-
There's a problem with the receiving component. The component's process has terminated or hung in some way, or the thread that's supposed to process the request has terminated with a thread exception.
-
The receiving component is busy handling other requests , and therefore is unable to process the new request in a timely fashion.
-
The receiving component processes the request and issues a response, but the response is lost for any of the preceding reasons.
So when you make a method call or send a message to a remote component, there are many ways (some of them quite ingenious) in which that call can fail. One of the major issues in this context is distinguishing between partial failure and complete failure. When you send a message to a remote component and don't receive a reply, what happened ? Was the request lost and never received by the remote component? Or did the request reach the remote component, but the response was lost or never issued?
In the case of a lost request, this is called a complete failure. In the case of a lost response, this is called a partial failure. Distinguishing between these two types of failure is essential because if you don't know what failed, it's hard to figure out what to do about the failure. With a lost request, you can usually reissue the request without any adverse effects. With a lost response, reissuing the request may well have severe adverse effects. Figure 15-1 shows these two types of failure.
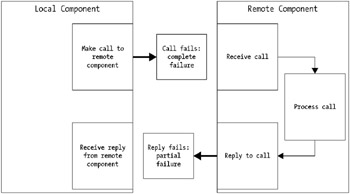
Figure 15-1: Partial failure versus complete failure
For instance, suppose you have an e-commerce Web site selling beanie babies. A customer decides to buy 2,000 beanie babies from your Web site and the Web page dutifully passes her purchase request to the remote server that processes credit cards. What happens if that server doesn't respond for 30 seconds or a minute? Has the credit card been validated and the purchase processed , but you just haven't received the purchase confirmation for some reason? Or has the purchase failed completely because the credit card server had a problem? How long should the Web page wait for a reply from the credit card server? And what should it tell the customer when no reply is forthcoming?
In order to deal with this type of situation, you need to design your distributed applications to cope with both complete and partial failures. You should have an explicit recovery strategy and you need to understand the benefits and drawbacks of each of the possible recovery strategies.
Using Distributed Transactions
The most common recovery strategy for dealing with failure in a distributed application is to use distributed transactions. You may well be familiar with transactions in a database environment. Most modern databases have the capability to roll back a sequence of database actions if a problem is encountered at some point during the sequence. In this context, a transaction says, "Something went wrong with what I was doing, so I'm going to reverse what I did and roll back to a safe situation." A distributed transaction involves communication between components to decide whether to complete the transaction in progress or to roll it back completely.
A distributed transaction therefore tries to eliminate the distinction between partial and complete failure by turning any partial failure into a complete failure. This enables you to repeat the request without worrying about adverse effects. The problem is that a distributed transaction can become very complex. It requires communication between multiple components asking, "Can I go forward? Are you ready to go forward? Please vote on going forward." All of these messages increase the complexity of the process. The more information going back and forth between the components, the more room there is for things to go wrong. Even with a sophisticated two-phase commit transaction, you still need to worry about some unlikely scenarios that can leave your application in an ambiguous state. Creating, and possibly aborting, distributed transactions gives you a significant overhead in complexity.
Using Compensatory Transactions
Another recovery strategy is to use compensatory transactions. When a sending component fails to receive a response to a request, it sends another request saying, in effect, "I haven't received your response to my original request, so please cancel that request if you've already acted upon it." This leverages the receiving component's knowledge of whether the failure of the original request was partial or complete. If the failure was partial, the receiving component reverses the request. If the failure was complete, the receiving component ignores the new request. In fact, in the case of a complete failure, the receiving component may not have received either request.
Compensatory transactions can also become quite complex if multiple components are involved in the transaction, although the complexity is typically less than that associated with distributed transactions. The major problem with compensatory transactions is that they rely on the ability to reverse a transaction. This isn't always possible or feasible . For instance, if the credit card has already been debited in the e-commerce scenario mentioned previously, reversing the credit card debit transparently can be difficult. You also need to cater for partial failure scenarios that can occur in the second compensating request. Just as with a two-phase commit, it's possible to come up with unlikely scenarios that leave your application in an ambiguous state.
Using Idempotent Transactions
Probably the best recovery strategy to use for many distributed applications is idempotent transactions. In an idempotent transaction, you simply keep on trying a request until a response to that request is received. Each request is given a unique identifier, and if the response to a request isn't received, the request is transmitted again and again until the response is received. Because the request has a unique identifier, the receiving component knows if that request has already been received and processed. If the request is new as far as the receiving component is concerned , it processes the request as normal and sends a response signifying success or failure. If the request is a duplicate of one that's already been received and processed successfully, the receiving component simply retransmits the original response to that request. If the request is a duplicate of one that failed during processing, it's reprocessed and the response is sent. In this manner, every duplicate request is filtered so that it isn't processed successfully more than once.
This is a brute force recovery strategy in that it doesn't use any clever transaction scheme or coordination between components. It simply keeps trying every request until a response (signifying either success or failure) has been received. As such, its very simplicity is a benefit. You don't need clever programming or clever developers, you just need to buy enough servers and network hardware to handle any increase in network traffic that might result from the retransmission of failed requests and responses. Nowadays, hardware is much cheaper than developers!
Swaying with the Earthquake
"Swaying with the earthquake" is a phrase that I first heard used by Ken Arnold, one of the original architects of both CORBA and Jini. It sums up very nicely the philosophy of not trying to build ultra -reliable components in a distributed system, because that can become very difficult and expensive. As you work toward that elusive 99.999% reliability (see Chapter 1 for a discussion on this), each extra decimal point of reliability becomes exponentially more expensive and introduces more external factors and bottlenecks. Instead of working toward a probably unattainable degree of reliability in a distributed application, it usually makes more sense to design your system so that it can function even when individual components fail. If you can design and construct your application so that it has no single point of failure, it doesn't matter so much when single components do fail. This relieves you of the tremendous burden of having to create ultra-reliable components. In effect, you design your application to continue functioning by rerouting itself around failed components.
It's similar to designing a building that needs to survive a major earthquake. Although your instinct might be to make the building as sturdy as possible, a better solution is to create a building that sways with the earthquake rather than trying to resist it. A building can survive a much bigger earthquake by swaying with the movement of the ground.
In the e-commerce scenario discussed previously, it might make more sense to have two or even three credit card components, so that if the first request fails, the Web page can direct the request to one of the other components. Your application still needs to understand and distinguish between partial and complete failure, but once again, it's much easier and cheaper to buy extra hardware and less reliable components than it is to create or find ultra-reliable components.
In a way, this mirrors the common approach of using redundant array of inexpensive disks (RAID) as a way of coping with the tendency of disk drives to fail at regular intervals. Instead of trying to cope with disk failure by purchasing ultra-reliable and therefore ultra-expensive drives , most companies have opted to construct hardware configurations where a good disk drive will immediately take the place of a disk drive that has failed. This approach is very effective because where a single disk may have a mean time between failures (MTBF) of 30,000 hours, the MTBF for a reasonable RAID configuration failing is something like 900 million hours. A similar approach applied to software components might be called redundant array of inexpensive components (RAIC).
Dealing with State
Almost every distributed system will store state somewhere, where state is defined as information held in one component that's needed at some point by another component. The most common storage of state is probably a database, but state is also often stored in business components and in a cache. Storing state has to be treated carefully in a distributed system because you need to understand how to keep the state consistent with reality on a continuous basis, how long the state has to be stored, and whether you need some sort of replication or backup of the state.
For example, imagine a component that acts as the cache for your trading system. This cache holds all of the current market prices, which together form the state of the market. You keep this cache because you don't want to make a lengthy interrogation of external price exchanges every time a new trader wants to look at the state of the market.
If the cache occasionally fails completely, say by going down, that doesn't worry you too much. As a last resort you can always go back to each of the price exchanges and thereby manage to reconstruct the cache. But you still need to worry about partial failure. How do you verify that the cached prices are all correct? How often should you verify that the cached prices reflect reality? How many traders can be serviced by a single cache? If a single cache isn't sufficient to service all of your traders in a timely fashion, how should you replicate the cache, and how can you verify that the replicated caches are identical to each other?
Caching strategies are well known to computer science, and if you want or need to use caches, you should certainly take the time to understand the problem that you're trying to solve and design your caching strategy properly.
Although caching generally stores information that you can reconstruct in the last resort, what happens if you store information that can't be reconstructed? For example, your application's database might hold information about all of the market trades made today by your users. In this case, you definitely need to think about questions such as "Is this component a single point of failure?" and about answers such as state replication. Be aware that replication can become very complex, especially when you start looking at everything that can go wrong and at possible recovery strategies.
Understanding Message Semantics
Chapter 1 has a short discussion on the problem of standardizing the meaning of each message passed between the components of a distributed application. The issue is that just because the different components can speak the same language (for example, XML), this doesn't mean that each component has an identical understanding of what each word in the language means. For example, two components that both see an XML attribute called Price many not agree on what that attribute represents. Is it net price or gross price ? Is it inclusive or exclusive of sales tax? An additional problem is that different XML documents may each have an attribute with the same name , but that attribute might represent a different entity within each document.
A common communication protocol such as XML just raises this problem of semantics to a higher level ”indeed a level where semantic differences may not be detected until quite late in the software development life cycle. XML can help components talk together more easily, while masking the issue of having a common understanding of what they're talking about.
This is summed up neatly in the old joke of two men walking down the road. One says to the other, "It's windy today, isn't it?" The second man replies, "No, it's Thursday." The first man comes back with, "Yes, I am too. Let's find a pub."
There's no easy answer to this problem. Careful documentation of every entity shared between components in a distributed application is essential, but even then, it's all too easy for misunderstandings to occur. If development of distributed applications was easy, everybody would be doing it and good developers wouldn't be so well paid.
Dealing with Leaky Abstractions
If you use a technology such as Web services, you can see that .NET cleverly tries to conceal the difference between a local call and a remote call. It creates a client proxy class under the hood and uses this proxy to present a convenient abstraction of the Web service and the remote call. When you make a method call to a Web service, it looks exactly as though you're calling a method on a local object. You can't even step through the client proxy code with the debugger unless you explicitly remove one of the proxy's attributes.
Unfortunately, this abstraction can sometimes leak. For instance, if you're accustomed to creating and calling local classes, and then you see the same idiom used for calling a Web service, you might expect that the Web service is an object, has a lifetime that you can control, and maintains state over its lifetime. Of course, this isn't true. A Web service is definitely not an object, it won't maintain state unless it's been explicitly developed that way, and its lifetime isn't under your control at all.
When you're debugging, you therefore need to see through the convenient abstractions that .NET offers and try to understand how the plumbing actually works. The abstractions are excellent for concealing much of the complexity of distributed programming, but don't get carried away and start to believe that the underlying mechanisms are as easy and neat as the .NET abstractions make them look.
EAN: 2147483647
Pages: 160