1281-1284
Page 1281
on these systems. On true shared-disk systems, for example, it is possible to implement database systems that provide access to all data as long as at least one node is available.
Loosely coupled systems, however, present greater challenges in terms of system administration and application development, as compared to SMP systems. One of the primary requirements for a parallel database system is to hide these complexities, presenting a logical unified view to the users, enabling them to transparently exploit all available resources on a loosely coupled system.
Traditionally, two distinct approaches shared-nothing and shared-diskhave been used in the implementation of database systems on parallel hardware. Each approach, in its pure form, offers certain unique benefits and tradeoffs. This section provides a conceptual foundation for the central argument in this chapter: a hybrid architecture that combines the strengths of each approach is the most pragmatic real-world solution.
The Shared-Nothing Approach
In a pure shared-nothing architecture, database files are partitioned among the instances running on the nodes of a multi-computer system. As illustrated in Figure 56.1, each instance or node "owns" a subset of the data, and all access to this data is performed exclusively by the owning instance. In other words, a pure shared-nothing system uses a partitioned or restricted access scheme to divide the work among multiple processing nodes. Data ownership by nodes changes relatively infrequentlydatabase reorganization and node failure are the typical reasons for change in ownership.
Parallel execution in a shared-nothing system is directly based upon the data partitioning scheme. Each partition is accessed in parallel by a single process or thread, with no provision for intrapartition parallelism. Conceptually, it is useful to think of a pure shared-nothing system as being very similar to a distributed database. A transaction executing on a given node has to send messages to other nodes that own the data being accessed and coordinate the work done on the other nodes, to perform the required read/write activity. Such message passing is commonly known as function shipping.
In principle, this is a very reasonable approach on shared-nothing parallel hardware: The approach is simple and elegant. It employs a software architecture that directly maps to the hardware system and has the potential to provide scalable performance on loosely coupled systems. Function shipping is an efficient execution strategy and typically provides significant performance gains over the alternative data shipping approach. However, as you will see in further detail later, the real-world applicability of a pure shared-nothing database architecture is seriously limited by certain drawbacks inherent to this scheme.
First, the shared-nothing approach is not appropriate for use on shared-everything SMP hardware. The requirement to physically partition data in order to derive the benefits of parallelism is clearly an artificial requirement in a shared-everything SMP system, where every processor has direct, equal access to all the data. Second, the rigid partitioning-based parallel execution
Page 1282
strategy employed in the shared-nothing approach often leads to skewed resource utilization. The tight ownership model that prevents intrapartition parallel execution fails to utilize all available processing power in the presence of data or workload skew, delivering suboptimal use of available processing power.
Figure 56.1.
A shared-nothing
database system.
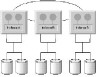
Third, the use of data partitioning as the exclusive basis for parallelism forces a trade-off between manageability and parallel execution performance, often introducing serious administrative complexities.
Finally, shared-nothing systems, due to their use of a rigid restricted access scheme, fail to fully exploit the potential for high fault-tolerance available in clustered systems.
The Shared-Disk Approach
This approach is based on the assumption that every processing node has equal access to all of the disks (data). In a pure shared-disk architecture, database files are logically shared among the nodes of a loosely coupled system with each instance having access to all the data. As illustrated in Figure 56.2, shared-disk access is accomplished either through direct hardware connectivity or by using an operating system abstraction layer that provides a single view of devices on all nodes. Therefore, a transaction running on any instance can directly read or modify any part of the database. Such systems require the use of interinstance communication to synchronize update activities performed from multiple instances.
Page 1283
Figure 56.2.
A shared-disk database
system.

Pure shared-disk is a good approach on clustered systems where equal and direct access to all disks is typically available from every node. A single node variant of the shared-disk scheme also ideally maps to SMP systems. Shared-disk has the potential to offer excellent resource utilization because there is no concept of data ownership and every processing node can participate in accessing all data. Further, this approach provides unmatched levels of fault tolerance, with all data remaining accessible even with a single surviving node. However, on shared-nothing hardware systems with local affinity between processing nodes and disks, the assumption of direct data access is not valid. Logical shared access can usually be accomplished, but the exclusive use of such a scheme can result in unneeded internode data shipping, incurring significant performance penalties.
What the Real World Needs
Over the years , there has been much religious debate among academic researchers and industry analysts on what the ideal parallel database architecture isshared-nothing or shared-disk. Although such debate still goes on, often producing interesting technical insights into the merits and drawbacks of either scheme, it's clear that no single scheme is without flaws. Given that, the authors believe that the most pragmatic real-world solution has to be a hybrid architecture that incorporates elements of each approach to provide the best of both worlds . Such an approach would provide the elegance and efficiency of pure shared-nothing systems, while avoiding their drawbacks in terms of resource utilization, manageability, and availability. At the same time, such a hybrid approach would also incorporate key attributes of pure shared-disk systems to deliver excellent resource utilization and fault tolerance.
Page 1284
Oracle Parallel Architecture: An Overview
The Oracle server was the first open relational database product to provide complete support for all parallel hardware architectures, with production availability on a variety of SMP systems for several years, and on loosely coupled cluster and MPP systems since 1990. The Oracle Parallel Server technology with its advanced parallel cache management facilities and the unique high performance, nonblocking concurrency mechanism is years ahead of any other commercial open systems product in performance, proven reliability, and unlimited scalability. Parallel query execution technology was introduced in Oracle release 7.1 to serve as the basis for enabling data- intensive decision support applications on cost-effective open systems. Parallel execution capabilities were designed as core internal facilities designed to achieve highly scalable performance on all parallel hardware architectures. The initial release provided support for parallel execution of most operations involved in query execution including table scans , sorts, joins, aggregations, and ordering. In addition, this release included parallel execution of data loads, index creation, and recovery operations. Each subsequent release of the Oracle7 server has added significant functional and performance improvements to this initial offering. This section provides an outline of Oracle's server architecture and an overview of the dynamic parallel query execution technology.
Oracle Parallel Server Technology
The Oracle Parallel Server technology is at the heart of Oracle's server implementation on loosely coupled clustered and MPP systems. As shown in Figure 56.3, the parallel server utilizes a robust, fault-tolerant shared data access scheme and Oracle's proven, scalable parallel cache management technology to provide unmatched levels of availability and scalable performance on parallel hardware systems. This section outlines key elements of this technology with specific emphasis on decision support applications. The Oracle Parallel Server utilizes a shared data access mechanism that enables multiple instances of the database server, with an instance on each node of the loosely coupled system, to transparently share a common set of database files. The shared data access is direct on clustered systems where there is physical connectivity of every disk device to all nodes. On shared-nothing and hybrid hardware systems, the shared access is enabled through an efficient operating system abstraction layer. As you will see later in further detail, Oracle's parallel architecture utilizes an intelligent mix of efficient local data access and transparent shared access on these systems to provide a superior combination of performance, resource utilization, and fault tolerance.
Each server instance utilizes a dedicated buffer cache, with the consistency of data updates across the multiple caches ensured by Oracle's parallel cache management technology. Oracle's proven, scalable parallel cache management technology represents the result of years of joint development efforts with leading parallel hardware system vendors . Key components of this technology include an efficient interinstance communication mechanism and a distributed lock manager (DLM) subsystem.
EAN: 2147483647
Pages: 391