Cancelling IO Requests
[Previous] [Next]
Just as happens with people in real life, programs sometimes change their mind about the I/O requests they've asked you to perform for them. We're not talking about simple fickleness here. Applications might issue requests that will take a long time to complete and then terminate, leaving the request outstanding. Such an occurrence is especially likely in the WDM world, where the insertion of new hardware might require us to stall requests while the Configuration Manager rebalances resources or where you might be told at any moment to power down your device.
To cancel a request in kernel mode, the creator of the IRP calls IoCancelIrp. The operating system automatically calls IoCancelIrp for every IRP that belongs to a thread that's terminating with requests still outstanding. A user-mode application can call CancelIo to cancel all outstanding asynchronous operations issued by a given thread on a file handle. IoCancelIrp would like to simply complete the IRP it's given with STATUS_CANCELLED, but there's a hitch: it doesn't know where you have salted away pointers to the IRP, and it doesn't know for sure whether you're currently processing the IRP. So it relies on a cancel routine you provide to do most of the work of cancelling an IRP.
It turns out that a call to IoCancelIrp is more of a suggestion than a mandate. It would be nice if every IRP that something tried to cancel really got completed with STATUS_CANCELLED. But it's okay if a driver wants to go ahead and finish the IRP normally if that can be done relatively quickly. You should provide a way to cancel I/O requests that might spend significant time waiting in a queue between a dispatch routine and a StartIo routine. How long is significant is a matter for your own sound judgment; my advice is to err on the side of providing for cancellation because it's not that hard to do and makes your driver fit better into the operating system.

The explanation of how to put cancellation logic into your driver is unusually intricate, even for kernel-mode programming. You might want to simply cut to the chase and read the code samples without worrying overmuch about how they work.
If It Weren't for Multitasking…
There's an intricate synchronization problem associated with cancelling IRPs. Before I explain the problem and the solution, I want to describe the way cancellation would work in a world where there was no multitasking and no concern with multiprocessor computers. In that Utopia, several pieces of the I/O Manager would fit together with your StartIo routine and with a cancel routine you'd provide, as follows:
- When you call IoStartPacket, you specify the address of a cancel routine that gets saved in the IRP. When you call IoStartNextPacket (from your DPC routine), you specify TRUE for the Boolean argument that indicates that you're going to use the standard cancellation mechanism. Before IoStartPacket or IoStartNextPacket calls your StartIo routine, it sets the CurrentIrp field of your device object to point to the IRP it's about to send. IoStartNextPacket sets CurrentIrp to NULL if there are no more requests in the queue.
- One of the first things your StartIo routine does is set the cancel routine pointer in the IRP to NULL.
- IoCancelIrp unconditionally sets the Cancel flag in the IRP. Then it checks to see whether the IRP specifies a cancel routine. In between the time you call IoStartPacket and the time your StartIo routine gets control, the cancel routine pointer in the IRP will be non-NULL. In this case, IoCancelIrp calls your cancel routine. You remove the IRP from the queue where it currently resides—this is the DeviceQueue member of the device object—and complete the IRP with STATUS_CANCELLED. After StartIo starts processing the IRP, however, the cancel routine pointer will be NULL and IoCancelIrp won't do anything more.
Synchronizing Cancellation
Unfortunately for us as programmers, we write code for a multiprocessing, multitasking environment in which effects can sometimes appear to precede causes. There are at least three race conditions in the logic I just described. Figure 5-10 illustrates these race conditions, and I'll explain them here:
- Suppose IoCancelIrp gets as far as setting the Cancel flag and then (on another CPU) IoStartNextPacket dequeues the IRP and sends it to StartIo. Since IoCancelIrp will soon send the same IRP to your cancel routine, your StartIo routine shouldn't do anything else with it.
- It's possible for two actors (your cancel routine and IoStartNextPacket) to both try, more or less simultaneously, to remove the same IRP from the request queue. That obviously won't work.
- It's possible for StartIo to get past the test for the Cancel flag, the one that you're going to put in because of the first race, and for IoCancelIrp to sneak in to test the cancel routine pointer before StartIo can manage to nullify that pointer. Now you've got a cancel routine that will complete a request that something (probably your DPC routine) will also try to complete. Oops!
The standard way of preventing these races relies on a systemwide spin lock called the cancel spin lock. A thread that wants to cancel an IRP acquires the spin lock once inside IoCancelIrp and releases it inside the driver cancel routine. A thread that wants to start an IRP acquires and releases the spin lock twice: once just before calling StartIo and again inside StartIo. The code in your driver will be as follows:
VOID StartIo(PDEVICE_OBJECT fdo, PIRP Irp) { KIRQL oldirql; IoAcquireCancelSpinLock(&oldirql); if (Irp != fdo->CurrentIrp || Irp->Cancel) { IoReleaseCancelSpinLock(oldirql); return; } else { IoSetCancelRoutine(Irp, NULL); IoReleaseCancelSpinLock(oldirql); } ... } VOID OnCancel(PDEVICE_OBJECT fdo, PIRP Irp) { if (fdo->CurrentIrp == Irp) { IoReleaseCancelSpinLock(Irp->CancelIrql); IoStartNextPacket(fdo, TRUE); } else { KeRemoveEntryDeviceQueue(&fdo->DeviceQueue, &Irp->Tail.Overlay.DeviceQueueEntry); IoReleaseCancelSpinLock(Irp->CancelIrql); } CompleteRequest(Irp, STATUS_CANCELLED, 0); } |
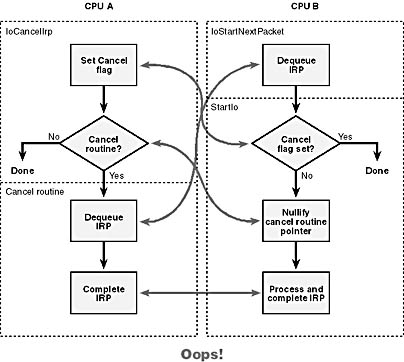
Figure 5-10. Race conditions during IRP cancellation.
Avoiding the Global Cancel Spin LockMicrosoft has identified the global cancel spin lock as a significant bottleneck in multiple CPU systems. You can see why it would be so. Every driver is potentially acquiring and releasing this lock several times for each IRP it processes, and no work can occur on a CPU while it's waiting for the lock. Microsoft Windows 2000 now implements IoSetCancelRoutine as an atomic (that is, interlocked) exchange operation, and IoCancelIrp follows a precise sequence that allows some drivers to avoid using the global cancel spin lock altogether. Ervin Peretz's article "The Windows Driver Model Simplifies Management of Device Driver I/O Requests" (Microsoft Systems Journal, January 1999), explains a way to support cancellation without using the cancel spin lock. I built on his ideas when I crafted the DEVQUEUE object described in the next chapter, "Plug and Play."
Notwithstanding that it's a bad idea to rely on the global cancel spin lock if you can avoid it, sometimes you can't avoid it. Namely, when you're using the standard model for IRP processing. That's why I'm explaining the whole gory mess in this chapter. Plus, it's good for your character.
Behind the scenes, the system routines that are calling your code will be doing something like the following. (This is not a copy of the actual Windows 2000 source code!)
VOID IoStartPacket(PDEVICE_OBJECT device, PIRP Irp, PULONG key, PDRIVER_CANCEL cancel) { KIRQL oldirql; IoAcquireCancelSpinLock(&oldirql); IoSetCancelRoutine(Irp, cancel); device->CurrentIrp = Irp; IoReleaseCancelSpinLock(oldirql); device->DriverObject->DriverStartIo(device, Irp); } VOID IoStartNextPacket(PDEVICE_OBJECT device, BOOLEAN cancancel) { KIRQL oldirql; if (cancancel) IoAcquireCancelSpinLock(&oldirql); PKDEVICE_QUEUE_ENTRY p = KeRemoveDeviceQueue(&device->DeviceQueue)); PIRP Irp = CONTAINING_RECORD(p, IRP, Tail.Overlay.DeviceQueueEntry); device->CurrentIrp = Irp; if (cancancel) IoReleaseCancelSpinLock(oldirql); device->DriverObject->DriverStartIo(device, Irp); } BOOLEAN IoCancelIrp(PIRP Irp) { IoAcquireCancelSpinLock(&Irp->CancelIrql); Irp->Cancel = TRUE; PDRIVER_CANCEL cancel = IoSetCancelRoutine(Irp, NULL); if (cancel) { (*cancel)(device, Irp); return TRUE; } IoReleaseCancelSpinLock(&Irp->CancelIrql); return FALSE; } |
It should be obvious that the real system routines do more than these sketches suggest. For example, IoStartNextPacket will be testing the return value from the KeRemoveDeviceQueue pointer to see whether it's NULL before just uncritically developing the IRP pointer with CONTAINING_RECORD. I've also left out the IoStartNextPacketByKey routine, a sister routine to IoStartNextPacket that selects a request based on a sorting key.
To prove that this code works, we need to consider three cases. Figure 5-11 will help you follow this discussion. We're going to assume that code running on CPU A of a multi-CPU computer wants to cancel a particular IRP and that code running on CPU B wants to start it. Since only two activities are going on with respect to this IRP simultaneously, we don't need to worry about what might happen if there were more than two CPUs.
Case 1: CPU A Gets the Spin Lock First
Suppose that CPU A gets past point 1 by acquiring the spin lock. It sets the Cancel flag and then tests to see whether there's a CancelRoutine for this IRP. The answer is Yes because the code that would nullify the pointer can't run yet without getting past the two acquisitions of the spin lock. So CPU A calls the cancel routine, dequeues the IRP, and then releases the spin lock. CPU B is now able to acquire the spin lock at point 2 and proceeds to remove an IRP from the queue. But this isn't the same IRP—it's whatever IRP was next in the queue. So CPU A will complete the IRP with STATUS_CANCELLED while CPU B goes ahead and initiates the next queued request.
Case 2: CPU B Gets the Spin Lock Just Before CPU A Tries
Now suppose that CPU B manages to get past point 2 and owns the spin lock just before CPU A tries to acquire the lock. CPU B will dequeue the IRP and set the device object's CurrentIrp to point to this IRP. Then it releases the spin lock (briefly) while it calls StartIo. In the meantime, CPU A grabs the spin lock at 1, which will keep CPU B from advancing past 3. CPU A sets the Cancel flag and calls the cancel routine. The cancel routine sees that this is the current IRP, so it releases the spin lock. CPU B is now free to advance past point 3 inside the StartIo routine. It will see that the Cancel flag is set in this IRP, so it will release the lock and just return. At this exact point, the device is idle. CPU A continues executing the cancel routine, however, which calls IoStartNextPacket and then completes the cancelled request.
It's very important not to call IoStartNextPacket while still owning the cancel spin lock because, as you can see by looking at the sketch of that function, it will acquire the lock on its own behalf. If we made the call to IoStartNextPacket while owning the lock, our CPU would deadlock because spin locks can't be recursively acquired.
The code in StartIo also guards against another subtle race condition. You might have wondered why StartIo tests the CurrentIrp field before testing the Cancel flag. (It's part of the C language specification, by the way, that a Boolean operation be evaluated left-to-right with a short circuit when the result is known. If the first part of the if test—Irp != CurrentIrp—is TRUE, the generated code won't go on to evaluate the second part: Irp->Cancel.) Suppose that CPU A manages to completely finish completing this IRP before CPU B makes it to point 3. Something on CPU A would call IoFreeIrp to release the IRP's storage. CPU B's Irp pointer would then become stale, and it would be unsafe to dereference the pointer.
Take another look at the previous code for IoStartNextPacket, and notice that it alters the device object's CurrentIrp pointer under the umbrella of the cancel spin lock. Our cancel routine calls IoStartNextPacket before it completes the IRP. Therefore, it's certain that one of the following two situations will occur: either CPU B's StartIo will get the spin lock before CPU A's IoStartNextPacket, in which case the IRP pointer is safe and the Cancel flag will be found set, or CPU B's StartIo will get the spin lock after CPU A's IoStartNextPacket, in which case the Irp variable won't be equal to CurrentIrp anymore—IoStartNextPacket changed it—and CPU B won't dereference the pointer.
The close reasoning of the preceding two paragraphs illustrates that, if you don't want to call IoStartNextPacket (or IoStartNextPacketByKey) from the cancel routine, you must be sure to set CurrentIrp to NULL while owning the cancel spin lock.
Whew! No wonder we cut and paste sample code so much!
Case 3: CPU B Gets the Spin Lock Twice
The third and last case to consider is the one in which CPU B manages to get all the way past point 3 and therefore owns the spin lock inside StartIo before CPU A ever tries to acquire the spin lock at point 1. In this case, StartIo will nullify the CancelRoutine pointer in the IRP before releasing the spin lock. CPU A could get as far as setting the Cancel flag in the IRP, but it will never call the cancel routine because the pointer is now NULL. Mind you, CPU B now goes ahead and processes the IRP to completion even though the Cancel flag is set, but this will be okay if it can be done rapidly.
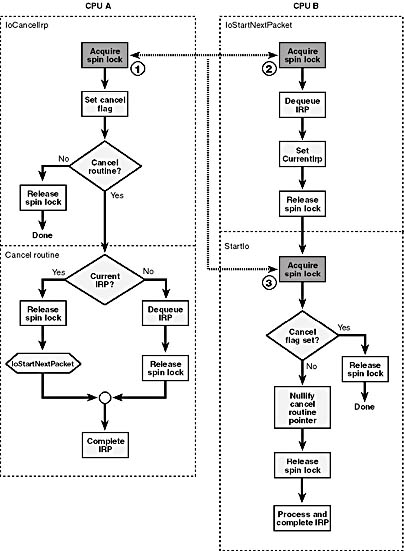
Figure 5-11. Using the cancel spin lock to guard cancellation logic.
Closely allied to the subject of IRP cancellation is the I/O request with the major function code IRP_MJ_CLEANUP. To explain how you should process this request, I need to give you a little additional background.
When applications and other drivers want to access your device, they first open a handle to the device. Applications call CreateFile to do this; drivers call ZwCreateFile. Internally, these functions create a kernel file object and send it to your driver in an IRP_MJ_CREATE request. When whatever opened the handle is done accessing your driver, it will call another function, such as CloseHandle or ZwClose. Internally, these functions send your driver an IRP_MJ_CLOSE request. Just before sending you the IRP_MJ_CLOSE, however, the I/O Manager sends you an IRP_MJ_CLEANUP so that you can cancel any IRPs that belong to the same file object but which are still sitting in one of your queues. From the perspective of your driver, the one thing all the requests have in common is that the stack location you receive points to the same file object in every instance.
Figure 5-12 illustrates your responsibility when you receive IRP_MJ_CLEANUP.
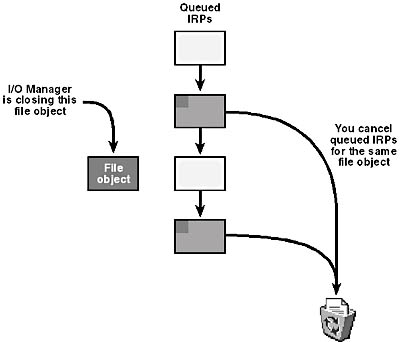
Figure 5-12. Driver responsibility for IRP_MJ_CLEANUP.
If you're using the standard model, your dispatch function might look something like this:
1 | NTSTATUS DispatchCleanup(PDEVICE_OBJECT fdo, PIRP Irp) { PDEVICE_EXTENSION pdx = (PDEVICE_EXTENSION) fdo->DeviceExtension; PIO_STACK_LOCATION stack = IoGetCurrentIrpStackLocation(Irp); PFILE_OBJECT fop = stack->FileObject; LIST_ENTRY cancellist; InitializeListHead(&cancellist); KIRQL oldirql; IoAcquireCancelSpinLock(&oldirql); KeAcquireSpinLockAtDpcLevel(&fdo->DeviceQueue.Lock); PLIST_ENTRY first = &fdo->DeviceQueue.DeviceListHead; PLIST_ENTRY next; for (next = first->Flink; next != first; ) { PIRP QueuedIrp = CONTAINING_RECORD(next, IRP, Tail.Overlay.ListEntry); PIO_STACK_LOCATION QueuedIrpStack = IoGetCurrentIrpStackLocation(QueuedIrp); PLIST_ENTRY current = next; next = next->Flink; if (QueuedIrpStack->FileObject != fop) continue; IoSetCancelRoutine(QueuedIrp, NULL); RemoveEntryList(current); InsertTailList(&cancellist, current); } KeReleaseSpinLockFromDpcLevel(&fdo->DeviceQueue.Lock); IoReleaseCancelSpinLock(oldirql); while (!IsListEmpty(&cancellist)) { next = RemoveHeadList(&cancellist); PIRP CancelIrp = CONTAINING_RECORD(next, IRP, Tail.Overlay.ListEntry); CompleteRequest(CancelIrp, STATUS_CANCELLED, 0); } return CompleteRequest(Irp, STATUS_SUCCESS, 0); } |
- We're going to look for queued IRPs that belong to the same file object as the one that this IRP_MJ_CLEANUP belongs to. The file object is mentioned in the stack location.
- Our strategy will be to pull the IRPs we're going to cancel off the main device queue while holding two spin locks. Since there might be more than one IRP, it's convenient to construct another (temporary) list of them, so we initialize a list head here.
- We need to hold two spin locks to safely extract IRPs from our queue. We acquire the global cancel spin lock to prevent interference by IoCancelIrp. We also acquire the spin lock associated with the device queue to prevent interference by ExInterlockedXxxList operations on the same queue.
- This loop allows us to examine each IRP that's on our device queue. We know that no one can be adding or removing IRPs from the queue because we own the spin lock that guards the queue. We can therefore use regular (noninterlocked) list primitives to access the list.
- When we find an IRP belonging to the same file object, we remove it from the device queue and add it to the temporary cancellist queue. We also nullify the cancel routine pointer to render the IRP noncancellable. Notice that we examine the stack for the queued IRP to see which file object the IRP belongs to. It would be a mistake to look at the queued IRP's opaque Tail.Overlay.OriginalFileObject field—the I/O Manager uses that field to tell it when to dereference a file object during IRP completion. It can sometimes be NULL, even when the IRP belongs to a particular file object. The stack location, on the other hand, should hold the right file object pointer if whatever created the IRP did its job properly.
- We release our spin locks at the end of the loop.
- This loop actually cancels the IRPs we selected during the first loop. At this point, we no longer hold any spin locks, and it will therefore be perfectly okay to call time-consuming and lock-grabbing routines like IoCompleteRequest.
- This final call to IoCompleteRequest pertains to the IRP_MJ_CLEANUP request itself, which we always succeed.
File ObjectsOrdinarily, just one driver (the function driver, in fact) in a device stack implements all three of the following requests: IRP_MJ_CREATE, IRP_MJ_CLOSE, and IRP_MJ_CLEANUP. The I/O Manager creates a file object (a regular kernel object) and passes it in the I/O stack to the dispatch routines for all three of these IRPs. Anything that sends an IRP to a device should have a pointer to the same file object and should insert that pointer into the I/O stack as well. The driver that handles these three IRPs acts as the "owner" of the file object in some sense, in that it's the driver that's entitled to use the FsContext and FsContext2 fields of the object. So, your DispatchCreate routine could put something into one of these context fields for use by other dispatch routines and for eventual cleanup by your DispatchClose routine.
The real point of the code I just showed you is the first loop, where we remove the IRPs we want to cancel from the device queue. Owning the device queue's spin lock guarantees the integrity of the queue itself. We also need to hold the global cancel spin lock. If we didn't hold it, something could call IoCancelIrp for the same IRP we're removing from the queue, and IoCancelIrp could go on to call our cancel routine. Our cancel routine would block while trying to dequeue the IRP. (Refer to the earlier example of a cancel routine in the "Synchronizing Cancellation" section.) As soon as we release the queue lock, our cancel routine would go on to incorrectly attempt to remove the IRP from the queue and complete it. Both of those steps would be incorrect because we're doing exactly the same two things in this dispatch routine. The solution is to prevent IoCancelIrp from even starting down this road by taking the global spin lock. By the time IoCancelIrp is able to proceed past its own acquisition of the global spin lock, the IRP will appear noncancellable.
You might notice that we acquire the global cancel spin lock first and then the device queue. Acquiring these locks in the other order might lead to a deadlock: our cancel routine and routines in the I/O Manager (such as IoStartPacket) acquire the global lock and then call KeXxxDeviceQueue routines that acquire the queue lock. We don't want there to be a situation in which we acquire the queue lock and then block, waiting for the global lock to be released by something that's waiting for the queue lock.
In an earlier sidebar, "Avoiding the Global Cancel Spin Lock," I mentioned that the global cancel spin lock is a significant system bottleneck. The fact that your IRP_MJ_CLEANUP routine needs to hold that spin lock long enough to examine the entire IRP queue only makes the bottleneck worse. Imagine every driver needing to claim this lock for every call to IoStartPacket, IoStartNextPacket, StartIo, and DispatchCleanup—even when no one is trying to perform the relatively unusual activity of actually cancelling an IRP! Furthermore, as the system becomes more sluggish, IRP queues will tend to build and cleanup dispatch routines will take longer to examine their queues, thereby increasing contention for the global cancel spin lock and slowing the system even further.
Because of the performance bottleneck, you really want to avoid using the global cancel spin lock if you can. Doing so requires you to manage your own IRP queues. How to do that will be one of the subjects of the next chapter.