11.2 The Process for Profiling Complex Data Rules
|
|
11.2 The Process for Profiling Complex Data Rules
Figure 11.1 shows the process model for profiling data rules over sets of business objects. It is substantially the same as in the case of single-object data rules. The complexity of these rules and the semantic nature of them makes them not amenable to discovery. There is no step for the discovery of complex data rules.
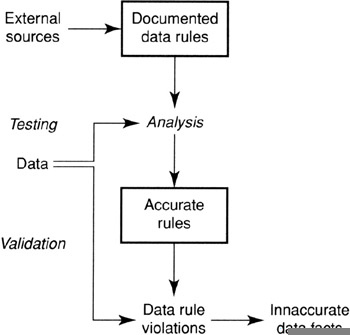
Figure 11.1: Process for profiling complex data rules.
Gathering Data
You can use the same sources you did with simple data rules. However, there are some differences in these rules, described in the sections that follow.
Source Code Scavenging
These types of rules are rarely scavenged from source code. Most rules embedded in code are rules that can be applied to a single transaction. Rarely does source code perform checks that involve extensive checking of an entire database before it allows a transaction to execute.
Some of these rules require that a period of time elapse before all data is present to process the rule. These types of rules cannot be executed on a transaction basis but must be executed whenever it is thought that the collection is complete. This means that if you intend to look for rules in source code, look for programs that run against the database at the end of a week, month, quarter, or some time interval.
Database-Stored Procedures
Complex data rules are almost never embedded in database procedure logic. Database-stored procedure logic generally involves only the data of a single transaction or only one instance of a business object. Data rules over sets of business objects normally do not fit this model.
Business Procedures
Business procedures will also generally be lacking because they concern themselves mostly with processing a single transaction. Sometimes they come into play when considering objects that have a characteristic that cannot invade the space of another object. This is discussed later.
Speculation
The most fruitful source of rules is again speculation: sitting down with the business analysts and subject matter experts and building data rules that should hold true over a collection of data.
Testing Data Rules
Data rules are crafted and then executed against the data to find violations. This is not anything new. What is new is that you are looking at sets of business objects and not individual objects. This requires that the data you use to test against must contain all relevant data. Taking samples may result in violations that are not true violations. In addition, extracting the data for data profiling at the wrong time can also result in the data being incomplete relative to the grouping function. For example, if the grouping function is MONTHLY, you cannot take the data for only part of a month; you have to wait for the month to end and get it all.
Validation of Output Data
As before, the results need to be examined by the same team of analysts and business experts to determine if the data rule is correct and to determine the meaning of violations. Accepted data rules need to be recorded in the data profiling repository. Data violations need to be converted to data issues if they warrant it.
|
|
EAN: 2147483647
Pages: 133