6.3 Building the Business Case
|
|
6.3 Building the Business Case
It is helpful to separate the front-end project of assessing the quality of the data from the back end of implementing and monitoring remedies. The front end takes you through the remedy design phase of issues management.
Figure 6.1 shows the shape of the business case when this is done. An assessment project looks at data, develops facts, converts them to issues, assesses impacts, and designs remedies. One or more back-end projects are spawned to implement the remedies. They can be short-term patches to systems followed by more substantial overhauls, or they can be parallel projects to improve multiple systems.
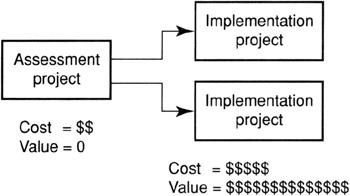
Figure 6.1: General model of business case.
A Data quality project can escalate into a cost of several millions of dollars. For example, an assessment project discovers many inaccurate data facts. This costs very little to find. In reviewing these with business analysts, they discover that many decision-making systems that feed off that data are corrupted, creating a serious potential problem. They also discover that the bad data is currently costing them a bundle.
Moving to the remedy phase, they work with the IT department staff to find solutions. The problem is multifaceted, with some of the blame going into improper data architecture. The application is old, using an obsolete data management technology.
A decision is made to scrap the existing application and database implementation and reengineer the entire application. Instead of building a new system, they decide to purchase a packaged application. This project escalates into a major migration of data and logic.
In parallel, the team determines that reengineering the entire data capture process is also in order. Bringing the application into the modern age entails defining Internet access to data as well an Internet data capture process. The jobs and responsibilities of many people change.
What started out as a small project mushroomed into a major initiative for the corporation. There were probably many other business drivers that pushed the decisions in this direction. However, data quality issues alone have the power to generate very large and costly projects.
The assessment project is all cost and no value. This is because value is only returned if changes are made. The business case for doing the assessment project is the difficult evidence of value to be recouped from problems caused by that source of data and speculation about recoupable value not visible. Its business case is very speculative at both ends. Not only is value potential poorly known but the costs are also poorly known. The length of time to complete the assessment will not be understood until the project is fully engaged.
The implementation projects achieve the potential value. The business case for the implementation projects is determined by the assessment project. If done properly, it will have a thorough analysis of potential value to be recouped. It will also be much easier to estimate the costs of the project.
The front-end assessment project is not only the basis for the business case for the back-end implementation projects but an indicator of what can be accomplished through more assessment projects. As the company becomes more successful with projects, it becomes easier and easier to support new assessment projects. The goal of a data quality assurance group is to build on success not only by finding many useful facts but also in following through on the implementation projects to be able to measure the value achieved for the corporation.
The Case for a Data Quality Assessment Project
The model of front-end versus back-end projects described previously is instructive to use in comparing the two project activity types of stand-alone assessment versus services-to-projects. The stand-alone assessment project starts by selecting a data source that is suspected of having sufficient data problems to speculate that large gains are likely from quality investigations and follow-through.
Companies have hundreds if not thousands of data sources. Those that are usually considered ripe candidates for data quality assessment are those that are important to the primary mission of the corporation, those that are older, or those that have visible evidence of problems with data. It should be apparent from previous discussions that this is not a very scientific way of selecting what to work on first. The largest problems may not yet have occurred or may have occurred but are not visibly connected to data quality. In addition, the probability that a database has errors may be offset by the fact that the database is of low importance to the corporation.
The quality assurance group should inventory all information systems and then rank them according to their contribution to the business, the potential for them to be the target of new business models, and their potential to create costly problems if they are not accurate. The goal should be to get the corporation's information systems to high levels of quality and maintain them there. The process should select the databases first that have the most need to be at a level of high data quality.
Figure 6.2 shows some of the factors that should be considered in selecting what to work on first. Each of the categories should be graded on a scale of 1 to 10, for example, and weights assigned for each factor. This would give the team a basis for relative prioritizing. The resulting chart could be presented to management to help justify the work to be done. This becomes the basis for the business case.
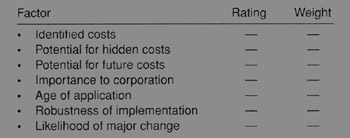
Figure 6.2: Project selection criteria.
Identified Costs
Identified costs include any problems, such as rework costs, that have already been identified. Quantification is very useful if possible.
Potential For Hidden Costs
These are the potential for costs that are not visible. Identified costs may be an indicator that more costs are there. For example, if you know that 5% of customer orders are returned, you can speculate that the number of mixed-up orders is higher and that some customers are just accepting the mistake and not going to the trouble of returning the merchandise. A chart that shows the potential for additional wrong orders and the impact they have on customer loyalty can easily suggest that the cost is much higher than the visible component.
Potential For Future Costs
This is acquired by speculation on what could happen if certain data elements contained inaccurate information. Assessment of legal liabilities, potential for costly manufacturing mistakes, and the like can identify areas where the risk of not knowing if your data is accurate is not worth it.
Importance To The Corporation
Data sources that serve the critical components of the corporation should be more important to study than others. Even if no visible problems exist, the risk of their being flawed and not knowing about it should carry some weight into the decision process. Conversely, the knowledge that the data is as clean as it can be carries some value.
Age Of Application
The age of data source applications should be considered. Older applications generally have a large change history. This tends to promote problems with quality. They also tend to have the most inaccurate or incomplete metadata. Age should not be the only factor used to prioritize work, but it should certainly be one factor.
Robustness Of Implementation
Applications that were built using modern DBMS technology, with data architecture tools, or with business rules accommodated in the design should be prioritized lower than applications built on obsolete technology and that gave little consideration to quality factors. The characterization should take into consideration whether quality promotion features such as referential constraints were used, not just that they were available.
Likelihood Of Major Change
The probability of a data source being the target of a business change is very important. Anticipating unintended uses can cause you to target a quality review and find and fix problems before they block your attempt to reengineer the business process they are a part of. Connecting data sources to projects that are in the planning phase is one way to do this.
The stand-alone project is all cost with no value. The justification is usually the expectation that value-generating issues will be found. This is why hard evidence of costs already being incurred has such large weight in these decisions. Because most of the costs are hidden at this stage, often one of less importance is selected.
The cost of conducting the assessment should also be estimated. Assessment projects involve a great deal of analytical activity regarding data. The factors that will influence the cost are the volume of data, the difficulty in extracting the data for analysis, the breadth of the data (number of attributes and relations), and the quality of the known metadata. Some sources can be profiled with very little effort, and others can take weeks or months to gather the data and metadata to even start the process.
Generally, the cost of conducting the assessment is not a critical factor. The value potential determined by the first part of the business case will drive the approval of the project, not the cost of doing the project. The primary difficulty in getting approval of assessment-only projects is that they are all cost without hard facts promising value.
The Case for Providing Services to Another Project
All active corporations execute several projects concurrently that are based on changing their business model or practices and that involve reengineering, reusing, or repurposing existing data. Examples of these types of projects are application migration from legacy to packaged applications, data warehousing construction, data mart construction, information portal construction, application consolidation due to mergers and acquisitions, application consolidation for eliminating disparate data sources, CRM projects, application integration projects joining Internet applications to legacy data sources, and on and on.
All of these projects have an existing data source or sources that are about to receive new life. These projects have the worst record of success of any class of corporate ventures ever attempted. They are plagued by budget over-runs, missed schedules, and cancellations.
It is recognized that a major reason for the difficulties in executing these projects is the poor quality of the data and the metadata of the original data sources. It is also becoming increasingly recognized that discovering and correcting the metadata and discovering the data accuracy problems as the first step in these projects hugely reduces the risk of failure and shortens the time to completion while increasing the quality of the outcome.
It only makes sense that working from accurate and complete metadata will lead to better results than working with inaccurate and incomplete metadata. It also makes sense that knowing the quality of the data will lead to corrective actions that are necessary for the project to complete, as well as to meet its objectives.
The analytical approach to accomplishing this first step includes the same activities that are performed in a stand-alone data quality assessment project. It requires the same skills and produces the same outputs: accurate metadata, and facts about inaccurate data and issues. If the data quality assurance group performed this first step for these projects or with the project team, the business case becomes a no-brainer.
The justification of the project is not just that quality improvements will lead to value. It adds the justification that it will shorten the time to complete the project and reduce the cost of completion. The Standish Group has estimated that performing data profiling at the beginning of a project can reduce the total project cost by 35%. This is a very conservative estimate. However, it is more than sufficient to offset all costs of the assessment activity.
This means that performing a quality assessment on data sources that are the subject of a project is free: it returns more dollars and time to the project than it takes away. It is very different from the business case for stand-alone assessment projects in that it does not need to wait for remedy implementation to return its expense.
The story does not end there. The quality assessment also makes decisions within the project better. The project team may decide that improving the quality of the data source is a requirement for proceeding, thus spinning off a renovation project that will enable the larger project to succeed. It may identify changes to the design of the project that are necessary for success: changes to target system database design or packaged application customization parameters. The project team can decide to cancel a project early if the data assessment reveals that the data source cannot satisfy the project requirements in terms of either content or quality.
Additional benefits are the reduction in the potential for mistakes being made in the data flow processes for data between the original source and the target. It essentially prevents accurate data from being turned into inaccurate data.
It may also provide issues that can eliminate data inaccuracies in the source systems that are not directly needed by the project but that were discovered in the process. These inaccuracies may impact other projects using the same data, thus improving their quality. It significantly reduces the risk of failure of such projects while having the potential for several beneficial side effects.
Figure 6.3 shows this business case. The business case is just the opposite of that for stand-alone assessment. The cost is zero (actually negative), the value returned for the assessment project is high, and the value of implementation activities that result just add more value. The ability to estimate the cost and time of subsequent implementation activities improves.
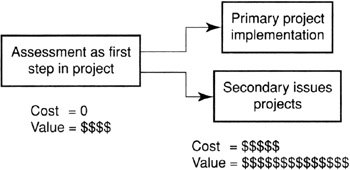
Figure 6.3: The business case for project services.
Because of the unique business value for these activities, the data quality assurance department should include this as their primary function. Instead of avoiding data that is the subject of major project, they should join with the projects and add value to them. The data sources involved in these projects are most likely the ones with the highest ratings for importance to the corporation and are most likely to have the highest rating for potential future problems.
The Case for Teach and Preach
Teach-and-preach activities involve educating information specialists in the principles of data quality and in the best practices for achieving better quality. The costs of such a program are relatively low. The potential return is obviously very high. The value is intuitive; it cannot be estimated or proven.
This is no different than wanting accountants to understand auditing or manufacturing staff to understand quality inspection techniques. Information specialists come to the corporation with poor data quality education and skills. It only makes sense that investing in their education is worth much more than the cost.
The outcome of continuous data quality education for information specialists will be better system designs and implementations, better awareness of quality issues (which leads to more exposure of problems), and better cooperation with data quality assurance staff and activities through higher appreciation of their value.
The Case for the Corporation
Spending money on improving data and information quality is always a trade-off decision for corporations. Data quality initiatives do not generally open up new markets, deliver new or improved products, or increase the number of customers. Competing with projects that promise these types of outcomes is always difficult.
There are three fundamental approaches to deciding whether to invest in data quality improvements and to what intensity the activities ought to be pursued. These approaches are described in the sections that follow.
Decisions Based On Hard Facts
This type of decision requires defensible estimates of cost and value before funding is made. Demanding this for data quality initiatives will almost always result in no funding. Everyone knows that the value is there. It is just impossible to determine what it is before you spend the money.
Many corporate decisions are based on hard facts. For example, consider buying a software package that will reduce disk requirements for large databases by 40%. You can trial the software and see if it gets a reduction of 40%, plus or minus 5%, on samples of your data. If it does, you can take the worst case of 35%, compute the reduction in disk drives required, price the cost of the drives, and determine the total value. Compare this with the cost of the software package, and the business case is done.
Data quality initiatives do not work this way. Too often management wants a hard-fact case presented to them for data quality spending. Sometimes this is possible because of egregious examples of waste due to bad data. However, it is not a method that selects projects with the highest potential value. Even though this may grossly understate the potential for value, it may provide sufficient justification for getting started.
The negative about this is that one project gets funded and, when the specific case is corrected, the problem is considered solved. Providing hard-fact business cases can undermine attempts to justify other projects later. Management may expect all data quality funding to be based on hard facts because of the success of a single initiative. This leads down a very bad path.
Decisions Based On Probable Value
Corporations often spend money on initiatives that promise returns that cannot or have not been estimated. Opening outlets in new cities, changing the design of a popular product, and spending money on expensive advertising campaigns are all examples of approving spending without hard facts about returns.
This is where data quality belongs. Those asking for funding need to exploit this approach as much as possible. Hard facts should be used to indicate the presence of value to be gotten, not the magnitude of the value. Management needs to be educated on the potential for finding value. Information about gains realized in early efforts or from other corporations are useful in establishing the case that unmanaged information systems generate inefficiencies by nature. The probability of coming up with a dry well is very low.
There is a lot of valuable information around about data quality. For example, most corporations could recoup 15% or more of operating profit if they could eliminate all data quality problems. Also, for example, the lack of understanding of metadata and quality of data can cost a project 35% or more of the total project budget. The argument is that if your corporation has not been paying attention to data quality, this type of return can be expected.
Decisions Based On Intuition
Corporations also base decisions on intuition. Some of this is following fads. This is why some major vendors who push new ideas advertise on the Super Bowl. The logic that says that managing the quality of data will make the corporation more efficient, more effective, and more profitable makes sense.
Executives should be made aware of the growing groundswell of interest in this area. It is not happening for no reason; corporations who adopt data quality initiatives become more successful than those who do not. Although this cannot be proven, it should be obvious.
Most large initiatives in IT are not created through hard facts or through credible estimates of probable value. They are created through intuition.
An example is the movement to relational database systems in the early 1980s. The systems were unreliable, incompatible with prior systems, and showed very slow and unpredictable performance. They used much more disk space than other data storage subsystems. Whereas mature, previous-generation systems were benchmarking 400+ transactions per second, the relational systems could barely squeak out 20 transactions per second (at least on robust benchmarks, not the trumped-up benchmarks of some vendors).
There were virtually no hard facts to justify relational databases. There were no computations of probable value. There was only the vision that the software and the hardware they ran on would get better and that the productivity improvements for application development and the ease of satisfying new requirements from the data would be realized. Companies all over the planet rushed to relational technology only because of the vision.
Data quality is not a glamorous or exciting topic. It is not central to what a company does. It deals in negatives, not positives. It is difficult to get management's attention, and even more difficult to get its funding.
The best argument you can use is the one that says that placing your company in a position to rapidly respond to new business models can only be done by having and maintaining highly accurate data and highly accurate metadata for your corporate information systems. Failure to do that puts a serious impediment in the way of making any significant business model changes.
Data quality advocates should avoid being put into a position of conducting limited value-demonstration projects and in doing only projects that require hard facts. Far too much value is left on the table when this is done. They should try to get religion in the corporation and have a full-function mission established that performs stand-alone assessments, services to projects, and teach-and-preach functions across the entire corporate information system landscape. They need to be accepted as a normal cost of doing business, in that the penalty for not doing so is much higher.
|
|
EAN: 2147483647
Pages: 133