Chapter 4: Using XML
|
|
Even though we've looked at how to build XML documents, we haven't done anything with them. Building XML documents in an editor is one thing. Building them dynamically or accessing them programmatically is something else entirely. We have to now take our knowledge of XML and transport it into our applications. Fortunately, we don't have to do it all on our own. There are some tools and standards available that get us about half the way there.
The other half we will have to design and develop, but we're not ready to get into that just yet. In this chapter, we will just get familiar with the existing techniques and standards for working with XML. This is the next step in understanding XML enough to use it in meaningful way: through creating and consuming Web services.
Working with XML
There are several approaches to working with XML. Some developers might take the brute force approach of "It's just ASCII text. I'll parse it myself." No matter how confident you might be, taking on that task is much more than you are bargaining for! If that wasn't obvious as you read Chapter 3, you might want to look through it one more time.
-
ASCII is an acronym for American Standard Code for Information Interchange. This is a 255-character decimal-based system for defining character data. The establishment of this standard was critical to getting computers to communicate with each other. Without every system agreeing on how a character is defined, standards based on character patterns, like XML, would be pointless.
As nice as it would be, I'm afraid this is not a "one size fits all" opportunity or decision. Certainly you will want to avoid some techniques, like building your own programmatic interface into an XML document. Not only can the logic to access XML data be very complex, but others have also already done the work for you. Why reinvent the wheel?
The industry has established two different standards to make it easier to work with XML: the Document Object Model (DOM) and the Simple API for XML (SAX). The DOM has been developed through the W3C, and participants in the XML-DEV mailing list (hosted by OASIS) developed the SAX specification.
These standards in and of themselves would provide little assistance other than direction if not for the vendors that have developed objects and libraries supporting these standards. That is because the DOM and SAX are both merely methodologies for accessing XML data. They are not parsers, but approaches on how to contain and thus interact with the data once it is parsed. Fortunately, the vendors have taken the effort to provide parsers that utilize these standards. That translates into free logic that you can use, which makes your job much easier.
DOM
The Document Object Model is an application programming interface (API) designed as a platform-independent approach to working with HTML and XML. The type of work the DOM formally facilitates is often misunderstood. You would not use the DOM to actually create XML code. Rather, it is an API for accessing and manipulating existing code. This manipulation can result in a new document, but it consists of, or is a copy of, XML code that previously existed. The actual creation of XML code is something the working group chose to leave out, because the construction of elements may have no relationship to the DOM itself. The specification has left it to the implementations themselves to develop their own creation factory and bundle it with the DOM specification. We will discuss these creation techniques later when we start building and consuming Web services in Chapter 6.
The history of the DOM is rather interesting in that it originates from work with JavaScript and Java. While working to find a way to make the languages more usable across various browsers, the working group at the W3C ended up being influenced by HTML and XML authors to broaden the original vision. The resulting efforts of that group became the first DOM specification (now known as Level 1). A revision to the DOM specification, DOM Level 2, was completed in November 2000.
To achieve platform and implementation independence, the DOM defines a logical container to the data. This container takes the shape of a hierarchical tree structure. This logical model is both a familiar concept to developers and a sound model that maintains the hierarchical nature of elements in an XML document. Figure 4-1 shows what the DOM tree structure of the following code might look like:
<customer> <firstname>John</firstname> <lastname>Smith</lastname> <birthday>071671</birthday> <address> <street>41 Mason</street> <city>Somerville</city> <state>MA</state> <zip>02144</zip> </address> </customer>
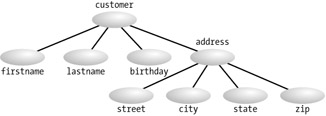
Figure 4-1: A graphical view of the DOM representation of XML
Understanding this data structure is critical to working with the DOM. I will refer to this model constantly when we start looking at the code for traversing data, identifying specific nodes, modifying data, or anything that has to do with the XML data.
| Note | The DOM tree structure should not be misinterpreted to be a binary tree. A binary tree is similar, but allows only up to two child nodes off of any node of the tree, whereas the DOM tree allows an unlimited number of child nodes. |
-
A node refers to one element in the tree structure. The nodes in Figure 4-1 are represented as circles. A parent node is a node that has other nodes extending from it. These nodes are considered child nodes because of their dependency on the parent. A parent may have many children, but a child may have only one parent. In Figure 4-1, the street element is a child node of the address element in the DOM structure.
The DOM is merely a logical representation, and it places no demand on the physical data structures behind the applications and tools that may support it. That means the actual data of a DOM application may live in any form, but it must be accessible via the interfaces defined by the specification. This allows us to care nothing about a DOM implementation beyond its performance and reliability (assuming of course that it conforms with the standards it has defined).
Also, the DOM has no support for generating XML constructs in any other object model. This means the DOM will never actually generate an XML document; it will merely support the data it is given and the interfaces it supports. The tools that implement the DOM will of course have their own mechanisms for generating nodes and then turn to the DOM standard for integrating it into a document.
Finally, the DOM does not in any way compete with any of the other object models for middleware such as COM (Component Object Model) or CORBA (Common Object Request Broker Architecture.) The "object" referred to in DOM simply refers to logical data, not physical software like with the other models.
My objective is to provide you with a sufficient understanding of the DOM to simply use the API, not implement it. If that is your objective, I suggest you look at books dedicated to the DOM as well as digging into the specification itself. If you do look up the specification directly on the W3C, you should be aware of the variations between versions.
Any reference to the core specification refers to the base DOM standard, which must be implemented for correct compliance. Other specifications are also considered part of the DOM (views, events, html, and others), but they are not required for compliance. These other specifications extend upon DOM, usually in specific markup languages or scenarios, and so do not always apply. Here we will be concerned with only the core specification.
| Note | My look at the DOM standard is based on the Level 2 Recommendation submitted by the W3C in November 2000. The parsers we will later use support this version. |
The DOM is usually implemented through the parsers provided by software vendors (like MSXML by Microsoft and XML4J by IBM). These implementations of the DOM actually extend far beyond the core specification to provide additional functionality such as network communication and file-level access to documents. Usually, vendors have their own specific purposes in mind for the DOM and are simply making it more robust. It is actually misleading to call these tools in their entirety a DOM, but rather the DOM is one component of the entire parser. We will talk about the DOM specifically in this section, but we will get into the specifics of different implementations when we start building Web services in Chapters 6 and 7.
The DOM will be the main interface into our XML data, so understanding the specifics of its components will be important for following the examples later in the book. These components are all mapped to interfaces, not classes. This means we aren't concerned with the logic making it happen and can simply rely on routines that manipulate the data as we want. Since the DOM is intended to be a language-independent API, no pretenses are made concerning the actual implementation. The DOM simply defines how an implementation will look to an external application and this interaction occurs through interfaces.
Node Interfaces
The DOM model is defined by a series of interfaces exposed through a document structure. Think of these interfaces as a set of instructions on how to access and manipulate the data in an XML document. Two different sets of logical interfaces are actually defined. The primary set is the object-oriented approach. In this approach, a series of interfaces is inherited from base interfaces, which makes it quite extensible. However, a performance cost is associated with this approach because casts or query interface calls (in their respective environments) are required for their use. That is why a second set of interfaces was established that is node-centric. In this simplified approach, the DOM treats everything as a node, and so everything is done through that interface. We will look at the DOM through this approach, since it provides all the functionality we need for our Web services and every aspect maps to the original object-oriented interface.
| Caution | The W3C considers this simplified interface to be extra functionality and so should not be assumed complete in its scope or completeness. That said, this node-based interface is simpler to use and can be used to accomplish most tasks you need in working with XML and especially when just parsing XML. Both of these approaches are part of the DOM core implementation, so any DOM-compliant parser exposes both. |
In this "everything is a node" approach, all the interfaces are implemented through the actual node interface. In the node are a series of types, attributes, and methods that allow you to access and manipulate the DOM. Since this is the key interface into the DOM using this approach, let's take a look at the IDL, or interface definition, for the node in Listing 4-1.
Listing 4-1: DOM node IDL
interface Node { // NodeType const unsigned short ELEMENT_NODE = 1; const unsigned short ATTRIBUTE_NODE = 2; const unsigned short TEXT_NODE = 3; const unsigned short CDATA_SECTION_NODE = 4; const unsigned short ENTITY_REFERENCE_NODE = 5; const unsigned short ENTITY_NODE = 6; const unsigned short PROCESSING_INSTRUCTION_NODE = 7; const unsigned short COMMENT_NODE = 8; const unsigned short DOCUMENT_NODE = 9; const unsigned short DOCUMENT_TYPE_NODE = 10; const unsigned short DOCUMENT_FRAGMENT_NODE = 11; const unsigned short NOTATION_NODE = 12; readonly attribute DOMString nodeName; attribute DOMString nodeValue; // raises(DOMException) on setting // raises(DOMException) on retrieval readonly attribute unsigned short nodeType; readonly attribute Node parentNode; readonly attribute NodeList childNodes; readonly attribute Node firstChild; readonly attribute Node lastChild; readonly attribute Node previousSibling; readonly attribute Node nextSibling; readonly attribute NamedNodeMap attributes; // Modified in DOM Level 2: readonly attribute Document ownerDocument; Node insertBefore(in Node newChild, in Node refChild) raises(DOMException); Node replaceChild(in Node newChild, in Node oldChild) raises(DOMException); Node removeChild(in Node oldChild) raises(DOMException); Node appendChild(in Node newChild) raises(DOMException); boolean hasChildNodes(); Node cloneNode(in boolean deep); // Modified in DOM Level 2: void normalize(); // Introduced in DOM Level 2: boolean isSupported(in DOMString feature, in DOMString version); // Introduced in DOM Level 2: readonly attribute DOMString namespaceURI; // Introduced in DOM Level 2: attribute DOMString prefix; // raises(DOMException) on setting // Introduced in DOM Level 2: readonly attribute DOMString localName; // Introduced in DOM Level 2: boolean hasAttributes(); };
Types
You can think of the DOM as a series of interrelated containers that hold your data. These containers may be physically present in the document, like an element, or they may be logical representations of your data, like a text node. (I'll explain each of these shortly.) Regardless of its nature, in this node-based interface to the DOM, each container is treated as a node, and each node has a type that defines and declares what it represents.
We are going to look at all the various node types, or types, that exist in the DOM. When you are working with the DOM, it is important for you to understand these relationships so that you can know what data you are referencing or modifying. There can be a subtle difference between changing the name of an element and changing the text value in it. This look at types will help you to understand that difference.
The headings at the top of each definition are the names of each available node type. Node types are actually defined by integers from 1 through 200, and these constants declare the types currently in use in the specification. More types will probably be added in future revisions, but these are all the valid types available in the DOM Level 2 recommendation.
These types provide the interface for how to view and declare the various nodes in our model. If you are that interested in working with the object-oriented interface, each of these node types actually represents the original interface itself. For example, the Document_Node type is actually a Document interface. Thus, anything you can do with the Document you can do with the Document_Node interface.
Where appropriate, I have added some code samples to help relate these types to actual XML data. These nodes all have strictly defined relationships in the document and with each other that mimic their ancestors. Diagrams for each type illustrate the relationships they have with each other. This can be a quick reference when you start trying to work with a piece of data and have trouble locating it in the DOM tree.
| Note | If you are having difficulty remembering what each of these types is, please refer back to the section in Chapter 3 on XML structures. |
Document_Node
The document node is the root of any DOM. The DOM can work only with valid XML data, which means that a root element must always be present. That would then be the document node. As the root, the document node obviously has no legal parent nodes. In this example, grills is the document node.
<grills> <manufacturer>Vermont Castings <model>VC-200</model> <model>VC-400</model> </manufacturer> <manufacturer>Fire Magic <model>Regal II</model> </manufacturer> </grills>
There can be only one Document_Node in a valid XML document. The relationships between the Document_Node entity and others are shown in Figure 4-2.
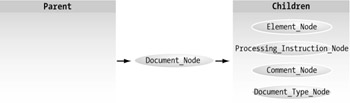
Figure 4-2: Document_Node relationships
Document_Fragment_Node
A document fragment is a subset of a valid XML document. This portion is still considered a valid document, if isolated, because it has a root node. You reference this root node when actually loading the document fragment. For example, take the following XML document:
<calendar> <event> <concert> <artist>U2</artist> <city>Boston</city> <hall>FleetCenter</hall> </concert> <date>060501</date> </event> </calendar>
Once you are working with this document, you may want to work with just the concert element, which is a valid subset. This method is often used to work with a portion of a document, perhaps to move, transform, or remove it. The Document_Fragment_Node relationships are shown in Figure 4-3.
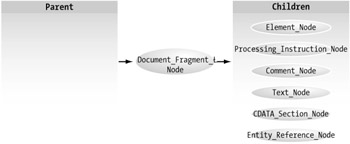
Figure 4-3: Document_Fragment_Node relationships
Document_Type_Node
The document type is an element that is actually an attribute of the document node. It is intended as an interface to the entities defined in the document. It is not editable and is generally used only for identifying DTD (Document Type Definition) references. Unfortunately, this uneditable aspect of the document type keeps you from being able to programmatically add a reference to an existing document. Chapter 6 explains why this is such a shortcoming. The following document contains an external DTD reference that defines itself for parsers:
<?xml version="1.0" encoding=" UTF-8"?> <!DOCTYPE myData SYSTEM "http://www.fundamentalwebservices.com/interface/grills.dtd"> <grills> ... </grills>
Here you see the document type node defined by the !DOCTYPE tag. Notice how the node actually precedes the root node of the document itself. However, in the DOM, it is in a child node of the document node. The reason for this "abnormal" structure in the text representation is likely to facilitate easy reference for when the document is parsed and validated (using the referenced DTD). Figure 4-4 shows the relationships for Document_Type_Node.

Figure 4-4: Document_Type_Node relationships
Entity_Node
As you might expect, the entity node defines entities. These entities may be parsed or unparsed, and the entity node, along with all descendents, is handled as read only in the DOM. The entity node is more of a logical container, and so pinpointing an entity node in code is not as meaningful as in other types. The relationships for the Entity_Node are shown in Figure 4-5.
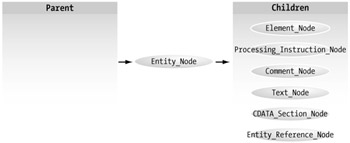
Figure 4-5: Entity_Node relationships
Entity_Reference_Node
Entity reference nodes reference entities external to the XML document currently loaded. Processors may retrieve these entities during load, which means that no entity references will exist. Like the document reference node, these nodes are not editable in the DOM. Figure 4-6 illustrates the legal relationships for this type.
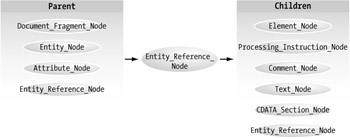
Figure 4-6: Entity_Reference_Node relationships
Element_Node
The element node will obviously be the most frequently used node. Every element outside of the root node is in an Element_Node. This concept may be easier to understand by looking at all the relationships the element node has with other types. (See Figure 4-7.)
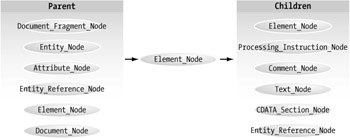
Figure 4-7: Element_Node relationships
Attribute_Node
Every attribute of an element is exposed through an attribute node. Notice in Figure 4-8 that the attribute has no parent nodes. This might seem confusing if you don't recognize that your document tree is a logical model only. Even though attributes relate to an element, they are not treated as child nodes of the elements because there would then be no distinction between an element's attributes and its child elements. You will see the need for this distinction when you start looking at the methods of the DOM.

Figure 4-8: Attribute_Node relationships
Processing_Instruction_Node
This node serves as a container for instructions meant specifically for the processor. Unlike other, seemingly similar nodes, this one potentially holds meaningful information to the parser and is not simply passing it along to the DOM. The following code is an example of a processing instruction node:
<?AcmeParser Filter(123)?>
The first word in a processing instruction is referred to as the target, which is the parsing application at which the instruction is directed. It should then know how to handle the information passed to it. From Figure 4-9, you can see that this node can be the child of several types, but can have no children.
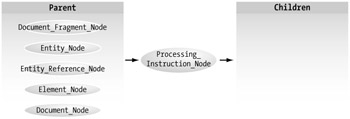
Figure 4-9: Processing_Instruction_Node relationships
Comment_Node
This node contains comments included in the XML document currently loaded. Unlike other nodes distinguished by start and end tags, comments in the XML document would merely be in "<!--" and "-->" delimiters. Like the processing instruction, the comment node can have no children. (See Figure 4-10.)
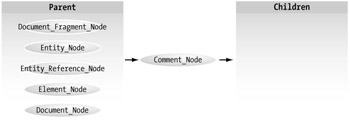
Figure 4-10: Comment_Node relationships
Text_Node
The text node contains the textual data value of an element or attribute node. This data cannot contain any markup data. Although it is possible to create multiple text nodes in an element, all text is normalized by rule into one node whenever the data is loaded into the DOM. The only reason to create multiple instances of the text node is as a temporary tactic for management of the data in an element inside the DOM (containing lines of text in separate nodes, for instance). The relationships for a text node are shown in Figure 4-11.
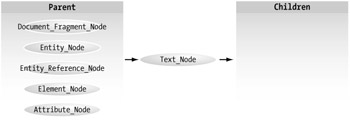
Figure 4-11: Text_Node relationships
CDATA_Section_Node
Like other CDATA sections, this node is used to escape blocks of text that may be misconstrued as actual code in a markup document. The legal relationships for a CDATA section node are shown in Figure 4-12.
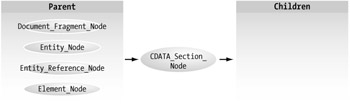
Figure 4-12: CDATA_Section_Node relationships
Notation_Node
This node is used for containing notations in a DTD. Just like comments with the XML data itself, it only has use to a human viewer. The following code is an example of a notation:
<!NOTATION gif SYSTEM "viewgif.exe">
Unlike other nodes, the notation node has no legal relationships with other nodes. (See Figure 4-13.)

Figure 4-13: Notation_Node relationships
Attributes
Every node type has three attributes called nodeName, nodeValue, and attributes. However, they are used differently and sometimes ignored based on the type in question. For instance, the element and attribute nodes use nodeName to define tag content in XML, but text, comment, and document nodes essentially ignore it. The nodeValue attribute applies only to the attribute, CDATA section, comment, processing instruction, and text types.
The attributes attribute can be a little confusing. First, it is actually an attribute that declares attributes for the node. Second, attributes applies only to element node types. This attributes property will contain all the information that allows us to navigate the DOM tree of our data. This is quite a large collection of data that applies only to elements. Thus, the specification is seeking to minimize the overhead impact on other types that would never utilize this information. Defining the relationships among elements through their own properties has made navigating and manipulating the DOM tree much easier. For example, if you want to know what the parent of the current node is, you can reference that property instead of traversing up the tree and then identifying the node.
| Caution | Don't confuse the attributes, or properties, of elements in the DOM with the attributes that the elements may have defined in the XML document. These attribute properties exist only with the DOM structure and are not related to any attributes that may be defined by the data writer. |
This attributes property contains an interface to something called a NamedNodeMap, which is part of the DOM specification used to define a collection of nodes. In this case, it contains information specific to the current element type. Let's take a look at each of the attribute values in the element node type.
childNodes
This is a listing of all the child elements of the current element. These child elements are exposed through a NodeList. The NodeList is simply another interface that abstracts an ordered list of nodes; similar to how a structured array could contain the nodes. They are accessible through a 0-based index system. Thus, the second child of the current node would be found through the following pseudocode:
currentnode.childNodes(1)
| Note | I am using pseudocode in this section in the hope of communicating basic concepts to developers of various languages.You will need to transcribe this logic to your own language and DOM or SAX implementation, because the syntax and even object and method names can vary. |
Earlier I talked about how attributes are not treated logically as child elements of the element to which they relate. If it wasn't clear, this is why that is the case. If you retrieve a list of child nodes that are composed of both attributes and elements, you would then have to qualify each node as an element or attribute. Figure 4-14 should help you to see how these two scenarios would differ in efficiency.
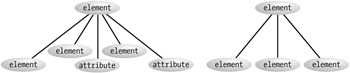
Figure 4-14: Elements versus elements and attributes as child nodes
firstChild
This property returns with the first child element of the current element. Because elements are sequenced in the DOM according to the order in which they were loaded, it would not be appropriate to assume that the firstChild is always the same element in different instances of the same schema. This is usually used more as an immediate, quick reference to the current DOM only.
lastChild
This property returns the last child element of the current element. Like the firstChild attribute, it is unwise to build a dependence upon this property outside of tightly controlled XML documents, even of the same schema.
localName
This property returns the local part of the qualified name for the current node. Any types other than attributes and elements will return a null value.
namespaceURI
This property contains the namespace reference for the current node. This value will be null if not declared in the XML document and that is acceptable.
nextSibling
This property directs you to the next node at the current level. If no additional nodes are present, it returns null. The sequence of nodes is determined by the childNodes property upon loading of the DOM. Just like the firstChild and lastChild nodes, this property depends upon the sequence of elements as they were loaded into the DOM.
ownerDocument
This is a read-only property that associates the current node with the document object of the current DOM. This associates the node with the root node of the entire document.
parentNode
This property returns the parent element of the current node. Only one parent can exist per node, so, given a single instance of a node, this is pretty much fool-proof and should not vary from load to load of the same document structure.
| Note | By a single instance of a node, I am referring to the same node definition in the same location. Certainly the same node can exist in more than one area. City can be a node in a mailing address element and billing address element, as seen in the following code. These would be different instances of the same element.
<shippingData> <mailingAddress> ... <city></city> <!--Instance 1--> </mailingAddress> <billingAddress> ... <city></city> <!--Instance 2--> </billingAddress> </shippingData> |
prefix
This attribute contains the namespace prefix of the current node. It returns null if it is unspecified. Changing this value is sometimes allowed, but this does have consequences on other properties of certain types. We will not be doing this, but be sure to look into it further if you ever attempt it.
previousSibling
This returns the previous node in the list. The behavior is the same as that of nextSibling, and if no previous nodes are present, it returns null.
Methods
Now that we have covered all the properties of the node interface, it is time to start working with the DOM. Although some tasks can be accomplished by referencing attributes (as we just saw), their capabilities are limited. After all, if you try to work with the property of a node that doesn't exist, you are going to run into problems. The additional functionality needed to have more robust control of your XML data will be attained through the methods exposed by the interface.
appendChild
This method adds a child node to the current node. If a node of the same name already exists, it is removed, and then the new node is added. Therefore, if you append a child node, make changes to its properties, and append it again, your work is lost! Because you are appending, it is simply adding the node to the end of the node list, making it the last child node in any sequence. The pseudocode for appending a child node looks like this:
{sourceNode}.appendChild ({newChildNode}) As you can see by the code, you are passing in a node as a parameter, which means that you aren't actually creating a node, but are simply taking a node and appending it to the current node. This allows for the migration of an existing node from one area to another in, or even across, DOMs. Remember, this node can also represent a collection of nodes if it is a document fragment type.
cloneNode
This takes a node and makes an existing copy of it. This is just like using the copy routine in an application. The duplicate node does not exist in the current tree and does not have a parent. However, it copies any attributes and copies child nodes if you specify it through the parameter. In the case of child nodes, the resulting node ends up as a document fragment type, as shown here:
{clonedNode}={originalNode}.cloneNode([boolean]) hasAttributes
This method tells you whether the current node has any attributes. There are no parameters, and it simply returns a true or false. This is a great method added in the Level 2 specification that will help you to avoid the errors that occur if you simply go looking for attributes that are not there. Usage of the hasAttribute method is shown here:
[boolean]={currentNode}.hasAttributes hasChildNodes
Similar to hasAttributes, this is a great mechanism for finding out if the current node has any child nodes without having to traverse the tree. The syntax for this method can be seen here:
[boolean]={currentNode}.hasChildNodes insertBefore
This method allows you to add a node previous to the specific node listed. While you may not care about the exact order, this is a convenient method for adding a node to a level without having to use the appendChild method. Navigating the DOM is tedious and costly, so being able to manipulate data in one command is a good thing.
Again, this method does not create a node for you, so you pass in the node to insert as well as the node before which you wish to insert it. If the referenced node does not exist, this method simply adds the node to the end of the list of current nodes. Shown next is the usage for insertBefore:
{insertedNode}=node}.insertBefore({nodeToInsert},{existingNode}) isSupported
You use the isSupported feature to discover whether an implementation has implemented a specific feature. This is not something you are likely to use in your code (unless you are working with various parsers), but you could use it ahead of time to verify an implementation or troubleshoot unexpected results from the processor. This method returns a simple true or false and takes two parameters, specifying the feature in question and the version of support you are looking for. The syntax for isSupported is shown here:
[boolean]=node.isSupported({feature},{version}) normalize
This method collects all text nodes in the element and its subtree into a single child node. This helps to not only aggregate adjacent text nodes, but also eliminate empty ones. The syntax is very simple, as seen here:
{currentNode}.normalize removeChild
The removeChild method allows you to completely remove a child node from the current node. The return on this call is actually the node you deleted, so this is more of a cut function than a straight deletion. The following code shows the syntax for removeChild.
{removedNode}={parentNode}.removeChild({nodeToRemove}) replaceChild
When you want to swap one node for another in the DOM tree, use this method. Just like the removeChild call, this method returns the original node, so no deletion of nodes actually occurs during this process. The syntax for replaceChild is given here:
{oldChild}=node.replaceChild({newChild},{oldChild}) DOMException
DOMException is not a method call, but, as you might suspect, is an exception that is raised by the DOM. This happens most frequently when you attempt a method call with invalid parameters or upon inappropriate nodes. Most DOM implementations you work with take advantage of the defined constants for DOMException, so I will not go over them here. (Codes are self-explanatory.)
Usage
Now that I have covered all the details of the DOM structure, let's see its usage in actual code. For the sake of accommodating various backgrounds and DOM implementations, I will continue to use pseudocode in these examples. Don't worry; we'll be looking at actual code when we build and consume Web services in Chapter 6 through 8!
Let's start with a scenario in which you add a few nodes to a DOM. The tree is loaded with the following XML data:
<sampleRequest> <date>2001-07-01</date> <customer>ACME <contact>John Smith</contact> <phone>6175552323</phone> </customer> <part> <partNumber>B89451</partNumber> <quantity>1</quantity> <dateRequired>2001-07-14</dateRequired> </part> </sampleRequest>
You want to add the appropriate data to an approval section so that this request for a sample product can be fulfilled. Based on the business requirements, you know that the following schema defines the approval element:
<xsd:element name=" approval"> <xsd:complexType> <xsd:all> <xsd:element ref=" firstName"/> <xsd:element ref=" lastName"/> <xsd:element ref=" position"/> <xsd:element ref=" loanPeriod"/> <xsd:element ref=" datePromised"/> </xsd:all> </xsd:complexType> </xsd:element> <xsd:element name=" datePromised" type=" xsd:timeInstant"/> <xsd:element name=" firstName" type=" xsd:string"/> <xsd:element name=" lastName" type=" xsd:string"/> <xsd:element name=" loanPeriod" type=" xsd:timeDuration"/> <xsd:element name=" position"> <xsd:simpleType> <xsd:restriction base=" xsd:string"> <xsd:enumeration value=" District Manager"/> <xsd:enumeration value=" Regional Manager"/> <xsd:enumeration value=" Chief Financial Officer"/> </xsd:restriction> </xsd:simpleType> </xsd:element>
You can see from this schema that the approval element has five child elements that are all required, and one has a defined set of valid values. There are actually a few different scenarios you could deal with in this situation. One is where this additional data is provided to you in a separate XML document. This makes the process fairly simple. The other case, which is much more likely, is one in which you have the data in some other format. It could be from a database, a user interface, or application-defined constants. In this scenario, we have to get the data into XML.
Remember that the DOM does not facilitate the creation of XML. You can move nodes, change the value of nodes, and delete nodes; you just cannot create them. Most implementations expose a method for creating nodes, but those are customizations of the DOM specification. When appropriate, you can eliminate the wholesale generation of XML code by designing your application to utilize templates. This would be a valueless document that merely has the structure defined. In this sample request scenario, the template might look like this:
<?xml version="1.0" encoding=" UTF-8"?> <approval> <firstName/> <lastName/> <position/> <loanPeriod/> <datePromised/> </approval>
This provides all the structure that you need to contain all the data you need to incorporate your approval data. This is also an easy way to adhere to a specific schema. When you take this approach, it is best to declare everything in your template and delete the optional nodes that you won't use for that particular document.
The only other method for getting this data into an XML format involves actually building the code in your applications, and that is both tedious and less efficient. I will walk through the process for handling this scenario and solution, because receiving the data in XML would be elementary in comparison.
You could add your template to the final XML document and then modify it, or you could modify an instance of the template and then add it to your document. I choose the later because the memory consumption is less if you efficiently load and unload your documents.
This example contains two defined data sources. The first, sampleRequestDoc, references the sample request itself, and approvalSegment is the reference to the template. First make a copy of the template, as shown here:
templateNode=approvalSegment.childnodes(1).cloneNode(True)
Notice that, in the cloning, we are grabbing the second child node of the template. This is because the first node is a processor instruction node containing the XML header, as shown here:
<?xml version="1.0" encoding=" UTF-8"?>
You'll want to define your node reference of the template at this level for two reasons. First, doing it here keeps you from having to step into the DOM an additional level every time you manipulate the data. For example, this method allows you to reference the position element with the code:
approvalSegment.childNodes(2).nodeTypedValue
Referencing the document at a higher level would require the following:
approvalSegment.childNodes(1).childNodes(2).nodeTypedValue
Second, referencing a document at the document level limits the level of access you have to the data. For instance, you cannot append a child to the approvalSegment node even if you drill down to the element level, because the initial reference is to a document node.
Next, you need to set the appropriate values for your approvalSegment, as shown here:
templateNode.childNodes(0).nodeValue = "Bill" templateNode.childNodes(1).nodeValue = "Boxx" templateNode.childNodes(2).nodeValue = "District Manager" templateNode.childNodes(3).nodeValue = "P1M" templateNode.childNodes(4).nodeValue = "1999-05-31T13:20:00.000-05:00"
| Caution | The nodeValue property is a read-only property for an element node type in the DOM. However, every modern implementation I have seen has supported this through some means. For instance, the Microsoft parser uses the method nodeTypeValue to differentiate it from the nodeValue method in the DOM.You could not change any element values at all if the implementation held strictly to the specification. |
Finally, we will append it to the existing sample request document, as shown here:
docRoot =sampleRequestDoc.childnodes(1) docRoot.appendChild templateNode
Again, we are building a reference to the sample request at the second child node because the appendChild method is not valid on a document node type. Based on these changes, the completed XML document should now look like this:
<?xml version="1.0"?> <sampleRequest> <date>2001-07-01</date> <customer>ACME <contact>John Smith</contact> <phone>6175552323</phone> </customer> <part> <partNumber>B89451</partNumber> <quantity>1</quantity> <dateRequired>2001-07-14</dateRequired> </part> <approval> <firstName>Bill</firstName> <lastName>Boxx</lastName> <position>District Manager</position> <loanPeriod>P1M</loanPeriod> <datePromised>1999-05-31T13:20:00.000-05:00</datePromised> </approval> </sampleRequest>
Depending on the DOM implementation you are using, you may have some additional information referencing schemas and namespaces. This listing should be the lowest common denominator among all implementations.
As you can see, your access is a little restricted through the DOM. It is very much an all-or-nothing approach because you load entire documents into memory to work with them. Once you parse the document, you can certainly clone just the element or document segment you want to work with, but the loading of the document must occur first. There are several scenarios in which this would be a very inefficient use of your resources. A method for specific access to just one element, or an occurrence of an element, would be much more effective. This was the thinking behind the development of SAX.
SAX
Like the DOM, SAX allows you to access XML data in a document. However, the implementation is very different, and that difference can be either a benefit or a hindrance depending on what you are trying to accomplish.
SAX was created by a collection of developers who recognized the need for another API when working with XML data. These developers collaborated through the XML-DEV mailing list coordinated by David Megginson. (Anyone can join this mailing list, and the list archives are maintained at the site http://www.lists.ic.ac.uk/hypermail/xml-dev/.) Work on the initial specification proposal started in December 1997 and took only one month to complete. SAX 1.0 was actually established by the community in another five months. The culture and common interests of the development community allowed the discussion group to avoid much of the bureaucracy that occurs in large, formalized organizations. You can find the specification, as well as implementations, at Megginson's site: http://www.megginson.com/SAX.
The SAX specification is developed with Java in mind (the original spec was even named SAX-J) and is actually designed to work on top of existing Java parsers. This is different from the DOM, because parsers are typically built on top of it. Without a technology-agnostic approach to the specification, changes to the original design or intent have to be made to accommodate other languages. This results in implementations varying far more from vendor to vendor than DOM implementations. For the most part, vendors have tried to stay true to the original vision. Compromises have been made only to circumvent technical obstacles.
| Note | My discussion of SAX is based on the SAX2 specification released in May 2000. The parsers we will be working with later support this version. |
I've talked quite a bit about XML data in terms of a tree structure when discussing the DOM. The SAX model is different in that it is event driven. This means that SAX reports events to the parser based on what it finds while reading the document. The largest impact of this model is that the entire document is not directly loaded into memory. (See Figure 4-15.) For this reason, SAX is considered a lightweight parser of XML. This actually affords the developer the opportunity to load it into memory through a different model. Accomplishing this specific task using the DOM would be a two-step process, because it imposes its own model. So the main distinctions of SAX over the DOM are the ability to parse documents larger than available system memory and more efficient loading of XML into a custom model. This may or may not translate into a benefit depending on what you are trying to do.
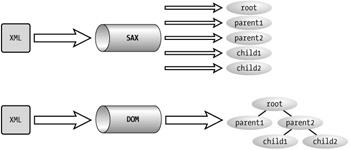
Figure 4-15: Graphical representation of the DOM and SAX APIs
Because SAX does less, it actually gives you less. The main limitation is the synchronous processing nature of parsers utilizing SAX. You are reading one node at a time once. When an XML document is loaded into the DOM, you can potentially have several processes referencing the data simultaneously. There is no dynamic referencing of an element in the document because you don't have it in memory and potentially never do. This also means that using SAX to reference the last node requires reading the entire document synchronously. The law of averages says that, in a given task of looking for one specific node, you should have to parse only half the document. Sometimes it will be the last node, but sometimes it should also be the first node.
The other limitation comes from the lack of a defined model. Obviously, if you aren't loading it, you have no defined data structure for containing the data. Inexperienced programmers could very well access nodes and load their values into variables without any relationships, making for very messy algorithms.
So you can see why different scenarios will require either the DOM or SAX for efficient access of your XML data. This means there is room for both the DOM and SAX to exist in a parser implementation.
Now that I have covered the background of SAX and why it is needed, let's take a look at the specifics.
Events
The basis for the SAX API is event handling. To SAX, every element triggers an event of some kind. The start of an element triggers one event, an attribute another, a text value another, the end of an element another, and so on. Table 4-1 lists each of the events supported in SAX along with a brief description.
| EVENT | DESCRIPTION |
|---|---|
| startDocument | Notification of the beginning of a document |
| endDocument | Notification of the completion of a document |
| startElement | Notification of the beginning of an element |
| endElement | Notification of the completion of an element |
| characters | Notification of character data |
| ignorableWhitespace | Notification of whitespace in an element |
| processingInstruction | Notification of processing instructions |
| setDocumentLocator | Notification of the origin for document events |
| skippedEntity | Notification of a skipped entity |
| startPrefixMapping | Notification of the beginning of scope on a namespace mapping |
| endPrefixMapping | Notification of the end of scope on a namespace mapping |
When reading a document, SAX views the XML as a series of events. As an example, look at the following XML data:
<hotelAvailability> <date>2001-08-05</date> <hotel> <chain>Milton</chain> <distance>5</distance> <bedSize>King</bedSize> <cost>120</cost> <nonsmoking>Yes</nonsmoking> </hotel> </hotelAvailability>
If we parse this using SAX, our events would trigger the following calls in order (indentions are only for readability):
startDocument startElement ("hotelAvailability ") startElement ("date") characters ("2001-08-05") endElement ("date") startElement ("hotel") startElement ("chain") characters("Milton") endElement ("chain") startElement ("distance") characters ("5") endElement ("distance") startElement ("bedSize") characters ("king") endElement ("bedSize") startElement ("cost") characters ("120") endElement ("cost") startElement ("nonsmoking") characters ("Yes") endElement ("nonsmoking") endElement ("hotel") endElement ("hotelAvailability") endDocument Of course, while you are parsing this information, you can choose to capture it in some model, but that is not part of the SAX specification. It is simply notifying you of the appropriate information as it parses.
The way you capture these events is by utilizing an event handler. This is basically a routine that is called by a given event. SAX exposes these events through the contentHandler interface. Put another way, the events in Table 4-1 are actually methods of the contentHandler interface.
| Note | The contentHandler interface replaced documentHandler with the release of SAX2. Although documentHandler is still supported for backward compatibility, contentHandler must be used if you want to support namespaces. |
To expose this interface, you must first implement the XMLReader interface. It is responsible for actually initiating a parse and registering the event handlers. As I mentioned earlier, SAX is designed as a synchronous process. XMLReader can utilize only one process thread, because an event handler must return before continuing to parse a document. In other words, a separate thread cannot continue parsing a document while an event handler is working.
Table 4-2 shows the methods of the XMLReader interface. Parse is obviously the most important method. The others can be helpful for querying features or utilizing other applications.
| METHOD | DESCRIPTION |
|---|---|
| parse | Parses an XML document |
| getContentHandler | Returns the content handler |
| setContentHandler | Registers a content handler |
| getDTDHandler | Returns the DTD handler |
| setDTDHandler | Registers a DTD event handler |
| getEntityResolver | Returns the entity resolver |
| setEntityResolver | Registers an entity resolver |
| getErrorHandler | Returns the error handler |
| setErrorHandler | Registers an error handler |
| getFeature | Returns the value of a feature |
| setFeature | Sets the state of a feature |
| getProperty | Returns the value of a property |
| setProperty | Sets the value of a property |
Usage
Like with any event-based system, you have to implement routines that "catch" the event as it occurs. If you are used to working with only procedure-based or function-based applications, this may be a bit of an adjustment. It isn't difficult; it's just another way of thinking about an application process.
The difference can probably be best explained through a football analogy in which the two teams line up on either side of the football: offense and defense. The offense is the proactive side, determining which play it runs based on the situation. The defense may try to anticipate, but ultimately reacts to what the offense does. For instance, if the offense runs the ball, everyone converges on the running back. If the quarterback drops back for a pass, some people chase after him, but others drop back, trying to break up the pass.
Writing a procedural application is like playing offense: you dictate the flow of the logic, being very proactive. Writing an event-based application is like playing defense: you anticipate things the application will do and write routines for what the application will do should those things actually occur. Like in football, the key is being prepared by knowing what to do for any given scenario.
Fortunately, the API has defined all the events that can occur, so, if you follow the specification, you shouldn't be surprised. The key for developers is to know what conditions of those events to look out for. If you look for a certain element, or a certain sequence of elements, you need to program those conditions into your event handlers. Let's walk through a scenario.
Say you have an application that needs to filter XML documents for hotel rooms that match some criteria. (Although there may be a more efficient means of doing this, let's say for the sake of argument that this is all you have to work with.) You collect several documents that have hotel rooms in the right city and in your price range, but you want to go one step further by qualifying rooms that are nonsmoking and have a king-sized bed. You will work with the same document structure you saw earlier in the hotel availability sample.
The first thing you need to do is load your XMLReader and start parsing. Look at this in pseudocode:
hotelHandler=XMLReader hotelHandler.contentHandler = myContentHandler hotelHandler.errorHandler = myErrorHandler hotelHandler.parse "c:\hotelDoc.xml"
Notice that we defined the error handler as well as the content handler. Although we can technically get away with not implementing the error handler, I recommend always implementing it if you have any hope for a reliable application.
The content handler is responsible for capturing all the legal events that occur during the parse. In this case, we are looking for two specific elements: bedSize and nonsmoking. Let's first look at generic event handlers for startElement and characters, as shown here:
event startElement(namespaceURI, localName, QName, Attributes)
This event passes along four pieces of information, three related to the name of the element and a fourth containing all the attributes. Without namespaces, only the local name is passed. With namespaces, both the URI and the local name are available. The QName, or qualified name (namespace prefix:local name) for an element, is available when namespace prefixes are used. The attributes are always available when present.
The problem with this scenario is that we are looking for the values of these elements and not just the tags themselves. This actually requires two events in SAX. That means we have to work with the characters event, as shown here:
event characters(string)
This is a very straightforward event collecting the value of the element. The actual form of the data being passed to the event may be an array of characters, depending on the language utilized, but I will treat it as a string for simplicity's sake.
Because these two events are entirely separate and unrelated, you have to coordinate the succession of events that produces a bedSize element with a specific value and a nonsmoking event with a specific value.
One way to accomplish this is to declare a global working variable for capturing your element name when the startElement event fires. This way the characters event can be aware of the activity in the startElement event. Remember that SAX parsing is synchronous, so you don't have to worry about multiple processes touching your variable and corrupting it.
Go ahead and add the logic to filter your hotel data. Declare your global variable as currElement. You also have two declared variables that you used to capture the smoking and bed preference from the end user: smokingSelection and bedSelection, as shown here:
event startElement(namespaceURI, localName, QName, Attributes) currElement=localName end event event characters(string) if currElement=" bedSize" then if string = bedSelection then ... else if currElement = "nonsmoking" then if string = smokingSelection then ... end event
By collecting the state of the startElement event, you can intelligently interpret the data in your elements, thus filtering your data. I'm sure you've noticed that I conveniently left out the logic to select the hotel once your condition was met. Because no data model is present in SAX, you have to build some mechanism for actually storing the data, in this case just the data you select. This may take the form of an array, a tree, or even a physical document. This is for you to decide, and it falls outside the scope of this book. I recommend getting a book on SAX2 for more ideas on this particular topic.
SAX Versus DOM
Both of these methods for accessing XML data can be effective in the right scenario. They can both ultimately accomplish the same tasks, but they go about them quite differently. This does not mean that one method is more accurate than the other. It is purely an issue of performance. Given a single task, one will probably accomplish it more quickly and efficiently than the other.
Although the quicker approach is often going to be better, the additional aspect of efficiency makes this tradeoff less clear. This metric depends on the resources available in your system and their efficiency, so making a blanket judgment can be quite difficult.
There are always exceptions, but SAX is generally better at referencing specific nodes out of a document or when you need to reference the nodes of a document only once. If you need to do more than that, you will likely benefit from loading the document into memory via the DOM.
Unfortunately, the decision of whether to use SAX or the DOM for an application may be out of your hands. If you use an existing parser to work with your XML data, you use whatever methods are being used behind the scenes. Don't assume that just because you are loading the XML into a DOM that it isn't using SAX to accomplish that task. The same goes for using SAX and thinking that it must not be using a DOM structure behind the scenes. If performance is that important an issue, it will serve you well to research the parsers you select. If the performance of your parsing is not an issue, then you may never have to concern yourself with the tradeoffs.
In general, Java parsers utilize SAX for parsing data, regardless of whether they are storing the data in a DOM structure. Microsoft's MSXML parser let's you choose the parsing method, but only the developers know how it actually works behind the covers. Typically, if you use Visual Basic, you utilize the DOM interface. This is simply because object-oriented languages are much more suited to support event-driven applications (hence, the wide support for SAX by the Java community). Although SAX and DOM can be used to do almost anything with your XML data, some things are better done with a slightly different approach. When you are working with the same data over and over and doing the exact same thing with it, writing an application may not be the most efficient approach. Instead of working with your data at a low level, why not just tweak the data through some high-level manipulations?
|
|
EAN: 2147483647
Pages: 77