Communication Architecture
|
|
In the communication architecture, we define the service and consumer interfaces as well as the transport mechanism between these interfaces. In a macro view, you can think of the communication architecture as the protocol that the logical architecture can utilize. It defines the mechanism for two partners to communicate via a Web service-the intersection of two links in our chain analogy, as shown in Figure 2-6. This level is independent of where components reside, how many layers of participants are involved, and all the details of any specific implementation.
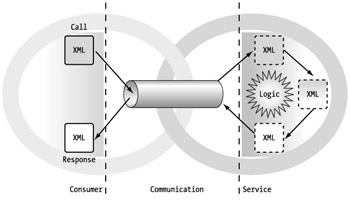
Figure 2-6: The communication architecture for a Web services call
-
The term logical refers to the conceptual view of a system versus the physical view. A logical view of an n-tier application would have a distinct separation between the presentation, business, and data layers even if they are physically contained on a single server.
The process is broken into three main components: the consumer, the communication, and the service. The consumer defines the entity utilizing the Web service, the communication defines how the consumer is interacting with the service, and the service defines the provider of the Web service. Each of these components is crucial for Web service execution. Furthermore, each of these three components must be implemented properly to qualify it as a Web service.
Remember that our definition of a Web service is any process that can be integrated into external systems through valid XML documents over Internet Protocols.
While this definition does not mention many specifics beyond the transport, it does demand enough structure to limit our options and focus industry efforts for building Web services. To confirm this, let's look again at our communication architecture, broken up into subcomponents with some of the technologies at our disposal for implementation (see Table 2-1).
| CONSUMER | TRANSPORT | SERVICE | |||
|---|---|---|---|---|---|
| REQUESTOR | PARSER | PROTOCOL | PAYLOAD | LISTENER | RESPONDER |
| Any logical process or entity that can initiate TCP/IP or UDP requests | DOM | TCP/IP | XML | ASP/JSP/ Java Servlets | Any logical process or entity |
| SAX | UDP | Any component that can receive TCP/IP or UDP requests | |||
While you could certainly justify a different arbitrary breakdown, this one works out nicely with each component containing two subcomponents representing the key functionality of each. Each subcomponent's column lists some options for implementing that functionality. Note that all of the technologies listed are readily available today through multiple tools on multiple platforms. Quite a few areas have unrestricted technology options available for implementation. While a number of tools are available to build this functionality, there will be more "out-of-the-box" choices in the future to help deploy Web services more quickly with more robust services. When we discuss the details of actual implementations, we'll confirm that Web services can be built and consumed with current technologies alone.
Now that we've gotten a high-level view, let's look at each of the components of this architecture in more detail.
The Transport Layer
We'll start by examining the transport mechanism because it is at the heart of making Web services possible. This mechanism facilitates the service interaction by getting the request to the Web service and returning the response to the consumer. Without this step, we would have a service of little value. The importance of standardizing the communication aspects of Web services can't be overstated. In fact, the industry advances in this area are what have produced the environment in which Web services can be conceived and utilized. Without consistent communication methods, every implementation with a new partner might require an entire infrastructure and set of services. This is counterproductive to the goal of interoperability, and specifically, interoperability over the Internet. Fortunately, that requirement of working via the Internet helps establish our baseline requirements, and all of our communication structure falls into place from there.
The transport can be broken up into two components: protocol and payload. The protocol defines how we actually communicate between the Web service and its clients. The payload is the data being transferred, and later we will look at how it is formatted and how we can work with it.
Transport Protocol
This discussion of the protocol for Web services refers to the Open Systems Interconnection (OSI) reference model, an industry-standard model developed by the International Organization for Standardization (ISO) for identifying the layers of a network application. The OSI reference model has seven layers:
-
Application
-
Presentation
-
Session
-
Transport
-
Network
-
Data link
-
Physical
Just as they are listed, you can think of these layers as being stacked from the physical layer up to the application layer. Not all layers are required for a functional network application, but if they exist, they can interact with each other. The communication for a Web service application simply specifies two layers in the OSI reference model: network and transport. However, the option selected in the transport layer inherently limits your options in the application layer as well.
The network layer for all Web services is the Internet Protocol (IP), the established standard for all communication over the Internet. By specifying IP, we are limiting our options in the transport layer to TCP (Transmission Control Protocol) and UDP. The only real differences between these two protocols are their reliability and performance. TCP is connection oriented, and UDP is connectionless. This means that TCP tries to ensure delivery at a cost to overall performance, while UDP focuses on the highest possible performance. While it might seem that TCP is the obvious choice for applications, UDP is much more effective for high-bandwidth applications in which the quality doesn't have to be perfect, such as voice. Still, TCP is much more widely used and has many more commercial applications established for working with it and developing on it (hence the common industry reference to TCP/IP when discussing the network of the Internet).
| Caution | While UDP does not guarantee delivery, many people expect it to have the same reliability as TCP/IP. Unfortunately this expectation can be deceiving, since applications built on UDP have a noticeable performance improvement. Do not be tempted into developing on UDP without understanding the repercussions and taking the time to build in extra error handling at the application level in case something goes wrong and your application doesn't work! |
Both TCP and UDP are stateless, high-efficiency, routable transport mechanisms that can be very effective when used correctly. Like many things, if you don't depend on them for more than what they are, they will work just fine. However, you can get more enhanced services through the application layer.
Your options in the application layer for Web services are predefined in the sense that they must be fully compliant with TCP/IP or UDP. These are often called the Internet application protocols and include, but are not limited to, HyperText Transfer Protocol (HTTP), secure HTTP (HTTPS), File Transfer Protocol (FTP), and Simple Mail Transfer Protocol (SMTP). All these applications represent port numbers over the IP layer. Port numbers then translate to a socket on the system that allows a client and server to establish a connection. Table 2-2 shows some of these port numbers.
| APPLICATION | PORT |
|---|---|
| FTP | 21 |
| SMTP | 25 |
| HTTP | 80 |
| HTTPS (Secure Sockets Layer, SSL) | 443 |
The applications listed are for TCP/IP, because UDP applications are typically not named and instead are just represented by their port number. For example, we would call an FTP application "a Port 21 application." This would probably change if UDP became as widely used commercially as TCP/IP. Your choice of the transport and application layers comes down to your application requirements. There are options that allow you to perform a multitude of services: simulate remote procedure calls; have a high-performance media service; or send secure, encrypted data to a server. We will take a hands-on look at some of these choices later.
| Note | Another alternative protocol for the Internet is Internet Control Message Protocol (ICMP), which is not discussed here because its use is reserved for TCP/IP to communicate connection errors to the system. |
Transport Payload
The data transferred during the communication of two systems is referred to as the payload. This is how we can send data to a Web service and receive responses. Again, the establishment of standards in this area was critical to enabling a consistent method for defining the data both syntactically and semantically. This means that we not only have a standard format to intelligently parse the data, but we know how to identify specific pieces to interpret or transform it. This allows us to work meaningfully with the data. Let's take a closer look at the enablers of our data component: format and definition.
Format-Speaking the Same Language
The importance of speaking the same language (that is, agreeing to a syntax) is critical to any kind of communication, including Web services. The easier it is to use the language, the quicker and more extensive adoption will be. The lack of a consistent language means that partners would spend more time translating.
If an English-speaking tourist travels to China, how long does it take that tourist to use a translation book to order a glass of water from a non-English-speaking waiter? The tourist has to look up the correct words and then try and pronounce the words correctly and use them in the correct context. While this may seem extreme for a computer application, it still shows how potentially costly and ineffective translating can be. It doesn't matter how fast you are at translating; it is far less productive than speaking the same language.
XML has provided the means for two or more systems to speak the same language. This flexible language describes data syntactically in an industry-accepted standard. While simple in concept, its importance and significance to Web services, and application integration in general, cannot be overstated. We will use XML in our Web services to format our payloads between the consumer and the service. By using a standard like XML, Web services can and will be able to take advantage of tools built for working with XML. Nearly every language, development environment, and service takes, or will take, advantage of XML in some way, and that translates very well to working with Web services.
Definition-Communicating the Same Meaning
Although we have a means for describing our payload, we also need a way of defining it. The semantics of our data will enable everyone "speaking our language" to understand our vocabulary. This means that others will not only be able to read our data, but also have the ability to know what the data is and work with it.
This issue is even evident in the same language. People in both the United States and England speak the same language, but does that mean they share the same understandings? In England, there is a mechanism for taking people vertically up a building's floors called a "lift." In the United States, lift is usually used as a verb and means to pick something up. Now, when someone from the United States hears lift for the very first time, does that person have any hope of understanding what the speaker means if the speaker is from England? Because they share enough commonality due to the fact they speak the same language, the person from England can either explain the concept in more common words, as I did earlier, or say the word elevator. The case is similar in data transfers when everyone talks the same language. It is always possible to "map" a new term to a previously understood term or terms. While our mind remembers to treat the words or phrases as synonyms in the future, an application has to make a record of the relationship in some data store for future reference.
| Note | It may seem like this idea of mapping words or phrases is the same as translating languages, but they are different processes. You cannot map two words or phrases if they are not synonymous in the language. Before and after the mapping, the context is the same, the usage is consistent, and the meaning doesn't change. |
A standard in this area also enables us to have a more efficient means for communicating the details of our Web services to partners and consumers. Fortunately, we again have some mechanisms in place to make this easy: the Document Type Definitions (DTDs) and XML Schema Definitions (XSDs). A service owner would provide one or the other to communicate the definition of any payload involved in calls and responses. We will talk about these two standards in much greater detail in Chapter 3.
The Web Service
The service contains all the components that make up the actual Web service interface. These components reside on the service owner's infrastructure and can be implemented in a variety of ways. The decisions of platform, technology, tools, and services supporting the service are at the owner's discretion. Furthermore, these decisions can be changed without impacting any existing consumers because the change takes advantage of the Internet's stateless nature. What does it mean to be stateless?
State is the act of remembering what is going on between the interactions of systems, or "calls." That may sound oversimplified, but that is pretty much it. Whenever you have an application or process that manages state, it monitors its users to know if they are logged on, if they are in the middle of doing something, what they might have done yesterday, and so on. The Internet is inherently a stateless environment. That means that every time you make a request to a Web site, the application inherently has no idea if you have ever been there before. Of course there are Web applications on which you can create accounts and that remember what you are doing, because information is being maintained by those sites on the application layer.
| Caution | Many HTTP servers come with standard and custom services for maintaining state, but there is usually a performance and/or scalability tradeoff. No method is foolproof, so be aware of the implications and risks for each and only use them when necessary. |
Any Web application maintaining any state is using some method to identify users (cookies, HTTP data, and so on) and then storing information about their activities (usually in a database) as their state. This state can then be referenced by the application during later requests by that user. This is how Web-based applications circumvent the stateless environment through which they are communicating. The browser certainly helps in the effort by managing cookies and keeping information in its cache. Any application that does this, though, has to gracefully handle any truncated processes, because the user at any moment can get disconnected or abandon a session, and the application will never be notified.
-
A session is an instance of a single user working with an application in a defined time period.
| Note | This is why all sessions on Web servers have a timeout property. Without it, the application would always be assuming the user is still connected and would continue maintaining old information. |
Two vital components are required for an application to function as a Web service: a listener and a responder. While these two components can be physically one entity, or distributed among numerous entities (see Figure 2-7), the functionality they provide is what is important for this discussion.
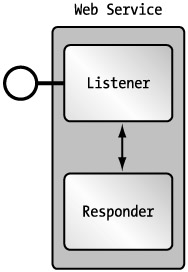
Figure 2-7: A functional view of a Web service
Listener: Waiting for the Call
The listener of a Web service is responsible for handling a Web services call from a consumer. The availability of this listener determines the availability of a Web service because it is essentially the interface. The process of handling a Web services call involves two steps.
The first step is capturing the incoming call. This capturing can manifest itself in many ways with a wide range of complexity. Possibilities for implementation range from having a script document hosted on a Web site to exposing an FTP directory.
The second step is the delivery of the payload package to the actual service logic. Although the listener could contain the actual logic of the Web service, this is not necessarily the best design. Separating the logic and the listener allows all listeners to be aggregated into one location or function, thus reducing the deployment time for each additional Web service. It also provides an extra layer on top of your logic, making it a more secure design.
You can think of this relationship between the listener and the service logic as being much the same as how a post office relates to the mailboxes on the street. The listener serves as the distribution center for the neighborhood (in our case, the service provider), and a process delivers the call to the actual address (in our case, the service).
Again, this functionality can be implemented through a wide range of technologies, but the key is that it is a persistent implementation. If you provide a Web service for your partners and customers, the expectation is that your service is as reliable as your Web site, if not more so. Thus, it is important that your actual implementation is persistent and efficient, and that all starts with your listener. We will look at some approaches for making your implementation persistent and efficient in actual code in Chapters 6 and 7.
Responder: Answering the Call
The responder of a Web service is responsible for providing a response to be returned to the calling consumer. It only provides a response because the listener owns the connection to the client. The response cannot be returned through another process because of the nature of the communication process. The consumer makes the request of the service and either waits for a response or expects no response from that service. Although only a UDP-based Web service could be truly asynchronous, you could simulate an asynchronous call via TCP/IP by providing a simple acknowledgement of the client call and releasing the connection. (This is essentially what happens inherently with SMTP.) You could then later send a response to the request at your convenience, not tying up your listener or the client (see Figure 2-8 for an example). This essentially turns a consumer into a service provider, since it requires a persistent listener on the consumer's side. This is a viable design, but these two steps should be considered two distinct Web services, since they are both acting as a client and a server.
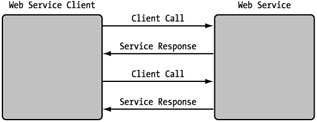
Figure 2-8: Asynchronous or delayed response Web service
-
Synchronous refers to the inline execution of a process or set of processes. No other processing can occur in an application during a synchronous call. Asynchronous refers to the execution of a process that does not restrict the application from other activity.
This dual Web services solution places much higher demands on your consumer. The challenge of this approach is that you are turning a client-server relationship into a server-client relationship, which means that you are establishing a client-server connection to the client that originally called you. Typically, the client that called you would actually be a server, so it should be capable of supporting the relationship. But does it have an active listener waiting for this response, which is essentially a request? Does the consumer have the logic to handle and process this delayed response? You need to consider these challenges to determine if this is a practical implementation for your Web service.
| Note | There is a misnomer about synchronous versus asynchronous calls that I will clarify for our discussion. There are very few asynchronous calls over the network. Client applications usually receive at least some notification that a packet has been delivered somewhere. What are thought to be asynchronous calls are actually asynchronous processes. This is accomplished by tying two synchronous calls together. The first one acts as a channel for the send process, the second as a channel for the significant response process. Again, we can relate this to mail delivery. If you were to send off for a rebate, is that synchronous or asynchronous? The sending of the rebate is synchronous because once you fill it out and place it in a mailbox, you know that it will be delivered. However, the entire process is asynchronous because you have no guarantee of getting the rebate. |
The response may or may not depend on the data payload submitted by the client. For instance, a Web service could simply respond with a confirmation that the call was received, or it may process the data and provide a custom response. When the response is simply a confirmation of receipt, the responder may be included in the listener component. But the more your response increases in complexity, the more beneficial it will be to separate these components. In fact, for enterprise-level Web services, you will likely have a responder that is logically separated from all of your Web service application logic to get the most reuse of that functionality.
Since the data in a response has to be encapsulated in a valid XML document, this component might have to build the response or at least transform it from another format. Then again, it could simply pass XML data straight through it. This starts to lead us to implementation designs, which we will discuss later.
Just like the listener, the responder platform and technology choices are independent of the consumer's. However, you may be tied to decisions made in this area for your listener. Assuming that performance is important for the service, you should stick with one set of technologies internally, since you have that luxury when there is single ownership.
The Web Service Consumer
Just as the name implies, the consumer is responsible for using the Web service and for initiating the interaction with the service, not vice versa. Every application or process that uses a Web service is considered a consumer. That means that for a chain of linked partners (as we saw in Figure 2-1), every partner except the last one (partner D) was a consumer. We will see in "Logical Architecture," later in this chapter, how this stacking of consumers can make our Web services extensible.
| Note | In this book the word consumer refers to the direct caller of the Web service. This might also be called the client since this could be classified as a client-server architecture. However, neither of these names is used in this book to describe the end user. The end user is the person or persons possibly using the service through an application and is likely to be a customer, or at least a client of the actual consumer. |
With our definition of a consumer, we have recognized another fundamental aspect of Web services: namely, that Web services are built exclusively for programmatic access by other applications. Table 2-1, earlier in this chapter, reinforces this by leaving out any mention of a presentation tier. There is no need for a presentation tier internal to our Web services architecture because the consumer calling it has complete control of the end user experience. Even though the presentation layer itself has no place in the Web service architecture, a Web service can provide presentation information, as we will see in Chapter 5.
The consumer of a Web service probably has the widest range of possibilities of all the components when it comes to functionality. The consumer may be responsible for the presentation to the end user brokering multiple Web services, or simply passing through a Web services call. This becomes more obvious when you realize that even different consumers of the same Web service may want to use a Web service in entirely different ways. One consumer may pass information straight through to a client, and another may want use the Web service behind the scenes, completely masking its existence. We will look at some of these possibilities in more detail when we start looking at code in the sample applications. Right now we will only concern ourselves with the functionality that is necessary to make the call to the Web service and "handle" its response.
With today's toolsets and services, that means developing a custom application, or at least expanding the functionality of an existing application. Keep in mind that the great thing about consumers in this architecture is that they are truly independent of the Web service. That means that the options of how to design it, what technology is chosen, and even which platform to use are entirely open and unaffected by those same choices made by the Web service owners. The consumer is completely independent and could be completely unknown to the service, so the details of its implementation and execution are of no consequence to it.
The consumer will consist, by nature, of two different logical, if not physical, parts: the caller and the parser (see Figure 2-9). I stress the logical separation of these two functions, because, just like the service's functional components, they are independent of each other.
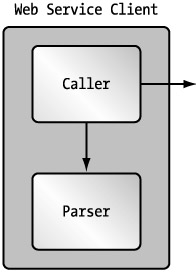
Figure 2-9: A functional view of a Web service client
Caller: Making the Request
The caller component is responsible for initiating the entire process of instantiating a Web service. It is responsible for building the payload for, and making the actual call to, the Web service. The nice thing about the caller is that it can be very generic in nature, so you can get a lot of reuse from a caller component. It can be so generic because of the communication structure we have defined. Regardless of what the consumer wants to do with a Web service, the communication with it is fairly consistent.
As we discussed with the service component, the call to the Web service is actually synchronous. Regardless, all the complexity of the caller lies in the intricacies and nuances of network communication. The steps involved are executed in the following order:
-
Build the payload.
-
Send the payload to the service.
-
Wait for the response from the service.
-
Pass the response to the parser.
More steps could be added to this process, but these are the minimal steps necessary to facilitate the Web service interaction by the consumer. We will look at this in more detail in Chapter 8 when we discuss consuming Web services.
Parser: Handling the Response
Since Web services respond to the consumer in an XML document format, most consumers have the ability to parse XML. This will almost always be necessary, but there are scenarios in which XML could be passed straight through, as we will see in the presentation models in Chapter 5. This functionality is so basic to Web service consumption that it is best isolated and accessed as a reusable object or component. This will keep you from having to incorporate that logic directly in each of your consumer implementations. While this could be done through custom logic, some standards have been defined to keep developers from having to design their own algorithms for parsing XML.
| Note | Although there is technically a difference between the two, I will treat the words object and component the same for the purpose of this discussion and will use them interchangeably. |
One of those standards is the Document Object Model (DOM). This model allows the loading of an XML document into a tree structure, referencing each of the elements as nodes. This is a good method for parsing XML when you want to work with an entire document. An alternative to the DOM is the Simple API for XML (SAX) standard, which allows for easy access to a single node in an XML document. We will look at both of these access technologies in much more detail in Chapter 4.
Just like the Web service itself, the technology and platform choices made for the consumer are independent of any other entity. You will not be diminishing your capabilities to access true Web services by any choices you make.
| Caution | I have mentioned several times how the technology choices made at each level have no impact on the other components in a Web service application. While these choices will not prevent you from using any Web service, there may be advances or more robust services in some vendor implementations of XML or Web services that may make the deployment and consumption of Web services easier. The issue to be aware of is a vendor's customization of Web services that actually makes the communication, service, or consumer proprietary. This may be a tradeoff you are willing to make, but you need to be aware of the decision you are making. |
The parser component of a Web service consumer can have the most variation on a per implementation basis because the utilization of a Web service has unlimited possibilities. This becomes more obvious when you realize that even different consumers of the same Web service may want to use it in entirely different ways. One consumer may pass information straight through to a client, and another may want to use the Web service behind the scenes, completely masking its existence. We will look at some of these possibilities in more detail when we start looking at code in the sample applications.
Now that we have a good understanding of how clients communicate with Web services, let's take a look at the actual makeup of a Web service.
|
|
EAN: 2147483647
Pages: 77