Session Bean Features
The first set of WebLogic Server-specific features is related to session bean components and their management by the container.
Stateful Session EJB Cache Management
Stateful session bean instances are created by WebLogic Server as they are needed to service client requests. Between requests these instances reside in a bean-specific cache in the active state, ready for the next request. The size of the cache is limited by the max-beans-in-cache element in the weblogic-ejb-jar.xml deployment descriptor file. As long as your application never requires more than max-beans-in-cache instances of the SFSB at any given time to service all concurrent clients , there is no contention for the cache and performance is optimal. If you limit the number of beans in the cache, WebLogic Server may be forced to manage the cache in a fairly active manner using the following rules:
-
If the cache is full, bean instances that are not being used at that moment for client requests are subject to passivation. Setting the idle-timeout-seconds has no effect on this rule because the server must make room for additional instances.
-
If the cache is full and all instances are currently pinned in the cache fulfilling client requests, WebLogic Server throws a CacheFullException . It will not block and wait for an instance to become available for passivation. Note that this condition is unlikely to occur if the max-beans-in-cache setting is higher than the maximum number of execute threads because the number of simultaneous client requests is normally limited by the number of threads.
-
Passivation logic is controlled by the cache-type and idle-timeout- seconds elements in the descriptor. The default setting for cache-type , not recently used (NRU), passivates beans only when the number of active beans approaches the max-beans-in-cache setting. It will not passivate based solely on time using the idle-timeout-seconds setting. An alternative cache-type value, least recently used (LRU), passivates based on both the maximum cache size and the time-out setting. While the LRU setting can be a convenient way of enforcing idle time-outs on the resources the objects encapsulate, it requires the container to keep track of the bean s access time and maintain an ordered list that gets updated after each bean access. Unless you have a good reason to need idle time-outs strictly enforced, most applications should retain the default NRU algorithm and passivate only on memory pressure.
-
Passivated instances that are unused for idle-timeout-seconds are subject to removal from disk storage during cache maintenance.
-
If idle-timeout-seconds is set to zero, beans are simply removed when chosen for passivation and are never passivated to disk storage. This can be a useful option to avoid passivating old instances representing lost clients or transactions that were completed long before. Of course, this can also cause long-running clients to lose their sessions if the max-beans-in-cache is not properly tuned .
Recall that passivation of beans refers to the serialization of nontransient data in the bean to disk storage to release the memory used by the bean. The next request for the passivated bean will require activation, the reverse process, where bean attributes are read from the disk store and the active bean instance is recreated in memory. Needless to say, passivation and activation cycles are extremely expensive. You should monitor the amount of passivation activity occurring in your system using the WebLogic Console and tune the max-beans-in-cache setting to reduce or eliminate this activity to achieve high performance.
| Best Practice | Avoid excessive passivation of stateful session beans by setting max-beans-in-cache high enough to meet the instance requirements for the expected maximum concurrent user count. |
Your application should always call remove() to delete the active bean instance from the cache when a client is through using the instance. Failure to call remove() leaves the bean instance in the active state and consumes one slot in the cache, requiring eventual passivation by WebLogic Server during cache management to make room for additional client beans.
| Best Practice | Always call remove() on a stateful session bean after you are done using it to delete it from the bean cache. |
The idle-timeout-seconds setting is obviously very important in cache management. The bean is subject to passivation once the time-out expires , assuming the LRU algorithm is being used, and may be removed from storage completely after the time-out period passes again. The default time-out value, 600 seconds, may be too short if users are likely to pause between requests for a longer period of time. If you are using SFSBs with a Web application, it might make sense to set this time-out value equal to the HttpSession time-out value for your Web application, for example, to be more consistent. Otherwise, review your business requirements and set the idle-timeout-seconds to the lowest value possible that still meets your application s requirements.
| Best Practice | Stateful session beans used to store session state for Web applications should have their idle-timeout-seconds set equal to the HttpSession time-out value. For non-Web clients, set the idle-timeout-seconds to the lowest value possible while still meeting your business requirements for the application. |
In-Memory Replication for Stateful Session EJBs
Stateful session bean components are used to encapsulate client-specific data and processes that must maintain state across multiple method invocations. These invocations may be separated by periods as short as milliseconds or as long as hours, subject to time-out settings. State that is maintained across multiple invocations would be lost if the SFSB was deployed to a single server instance that failed or became unavailable to the client. Fortunately, WebLogic Server provides failover for stateful session beans deployed in a cluster, just as it does for HttpSession data through the use of in-memory replication.
Figure 6.2 illustrates the basic in-memory replication scenario and shows communication paths before and after the failure of Server2. In this example, Client155 was using the SFSB155 component hosted on Server2 as the primary copy of the bean. When that server failed, Client155 was automatically redirected to the backup copy of the SFSB155 component hosted on the other server. This failover logic is provided by the replica-aware stub object used by the client for all communication with the bean. The stub acts as a proxy for the bean in much the same way the Web server plug-in acts as a proxy for Web applications and provides failover in the presentation tier .
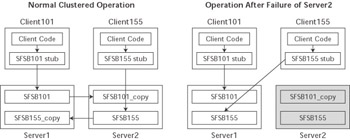
Figure 6.2: The replica-aware stub provides SFSB failover.
Changes made to the primary copy of an SFSB component are copied to the replicated version on the backup server at the end of a committed transaction involving the SFSB component. Note that modified SFSB data may be lost if either server fails during the post-commit transfer of data to the backup server because the replication is done outside the scope of the transaction.
Although we generally recommend storing session data in the HttpSession and using HttpSession replication alone when possible, you might consider using SFSB replication to store business data or the intermediate results of a multistep process under some conditions. Figure 6.3 illustrates the Web application replication scenario using an HttpSession to store the replica-aware stub object and a replicated SFSB component to store the business data.
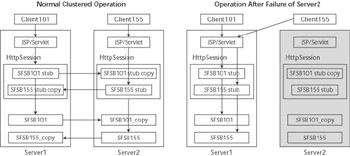
Figure 6.3: Replicated HttpSession and SFSB component.
Note that both the Web application and EJB components are located on the same machine. Failure of that machine will cause the Web server plug-in to fail over to servlets and JSPs on the specific secondary machine saved in the cookie sent to the browser. How can you be sure that the backup copy of the SFSB data will be located on the same machine as the backup copy of the HttpSession data, as illustrated in Figure 6.3? Just as WebLogic Server always prefers to communicate with EJB components located in the same application as the Web application components, it normally configures the failover copies of both the HttpSession data and the replicated SFSB data on the same backup server.
Unfortunately, the collocation of both kinds of backup data is not guaranteed to occur in all conditions. If the HttpSession secondary and the SFSB secondary are located on different machines, you can easily get into a situation where a single client request involves calling from one WebLogic Server cluster member to another to process the request. Performance will suffer if this scenario occurs, and the large number of cross-server messages and the threads consumed by these messages also expose your application to a potential deadlock condition discussed in Chapter 12.
| Warning | Be careful when storing SFSB references in the HttpSession because in-memory replication doesn t guarantee collocation of secondary objects and may lead to excessive server-to-server calls in the same cluster after a primary server failure. Not only will this kill your performance, but it also will expose your application to potential deadlock situations. |
Recognize that SFSB replication is more costly in terms of memory and performance than HttpSession replication because there is no simple way for the container to determine which portions of the bean have changed. While HttpSession replication relies on setAttribute() calls to determine the data that must be sent to the backup server, SFSB replication requires before and after images of the SFSB to determine changes requiring replication at the end of the transaction. For efficiency, the server keeps the after image from the last transaction to use as the before image for the next; this means that you have two copies of the bean in memory in the primary server and one in the secondary server.
Why would you use replicated SFSB components when HttpSession replication fills essentially the same role? Web applications should probably stick with HttpSession replication to maximize performance and avoid introducing additional complexity, but not all applications are Web applications. Replicated SFSB components allow non-Web applications to maintain state between method invocations in a fully clustered fashion as well.
Configuring SFSB components for in-memory replication requires a replication- type element in the descriptor for the stateless session bean in weblogic-ejb-jar.xml :
<stateful-session-clustering> ... <replication-type>InMemory</replication-type> </stateful-session-clustering>
EAN: 2147483647
Pages: 125
- Structures, Processes and Relational Mechanisms for IT Governance
- Integration Strategies and Tactics for Information Technology Governance
- An Emerging Strategy for E-Business IT Governance
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- Measuring ROI in E-Commerce Applications: Analysis to Action