Chapter 17: Incident Response
I used to ride motorcycles and have many family members who still ride. When I first started riding , one of my uncles told me, There are two types of motorcycle riders: those who have hit the ground, and those who will. That statement translates to security administrators. There are two types of security administrators: those who have had a security incident, and those who will.
No matter how hard you plan and prepare, sooner or later there will be a security incident that you will need to respond to. Even if you follow every best practice that has been recommended in this series, you will not be 100-percent protected. As a result, it is fitting that the final chapter in this book examines what to do when everything else you have put in place to prevent a security incident has failed, and you must now address and recover from the security incident.
Building an Incident Response Plan
As we have established, no matter what you do to try to prevent an incident from occurring, you cannot guarantee that one will not occur. As a result, you have to plan for how you will handle a security incident when it happens. Incident response is like a fire drill for network security. You have fire drills so that, in the event of an actual fire, you have a methodical and structured method of evacuating the building, and at least in theory, everyone knows what that method is. You do this because if you don t, with the smoke and fire there is a much greater likelihood that confusion could result in a catastrophe.
Incident response is no different. During an actual security incident, emotions are going to be running so high that there is a much greater likelihood of confusion, and that is the last thing you need in an already stressful situation. The more confused and ill prepared you are in dealing with an incident, the greater the potential for damage as a result of the incident. Therefore, you want to plan in advance for your incident response so that when an incident occurs, you will have a methodical and structured method of addressing it.
A number of aspects of incident response must be performed, including the following tasks :
-
Assembling a computer incident response team (CIRT)
-
Developing an incident response plan
-
Discovering incidents
-
Handling incidents
-
Reporting incidents
-
Recovering from an incident
Assembling a Computer Incident Response Team (CIRT)
One of the most effective tasks you can undertake as part of your incident response policy is to build a CIRT. It is important to understand that a CIRT does not exist solely to deal with incidents after they have occurred. In fact, a well-developed CIRT should actually exist to attempt to prevent an incident from occurring in addition to being able to address an incident after it has occurred. A CIRT exists primarily to confront security incidents that might occur, are occurring, or have occurred. The objective is to prevent an incident from becoming a crisis, and the sooner a CIRT can react , the greater the success rate at accomplishing this objective.
The overriding mission of a CIRT is to provide the guidance and direction required for a company to effectively prepare for and respond to any security incidents that may occur on the network. Because these incidents include such different things as viruses, worms, intrusions, and unauthorized system access, a good CIRT comprises many different specialties. Simply put, a CIRT needs to be able to handle a myriad of different types of incidents and must do so with skill and expertise regarding the subject.
Forming a CIRT
A CIRT can be built in a couple different ways, depending on the needs of the company. One method is to establish a static group of people as members of the CIRT. These folks are sometimes referred to as core team members . The benefit of this method is that you always have a defined group that is responsible for incident response. The drawback of this method is that it can be very costly, so much so that it is cost prohibitive in many environments.
Another method is to define a dynamic group of people to address a specific issue or to deal with a specific incident. These folks are sometimes referred to as support team members . This is a much more common method of operating because it reduces the overhead of maintaining a dedicated incident response staff. You simply grab the people who are best suited for a problem and give them the authority and direction to handle it. For example, if you have a new worm that has to be addressed, you might identify who in the IT department is going to be responsible for dealing with the issue at that time and direct them to respond to the incident. The drawback of this method, however, is that because the components of the CIRT may change depending on the incident, it can take longer to mount an effective response.
One of the most effective methods of building a CIRT is to apply components from both of the previous methods in building a kind of hybrid CIRT. You will have certain individuals who are part of the core membership of the CIRT. They are always components of the CIRT and are available to respond to any incident that may occur. Then, when a specific incident arises, they may identify individuals with specific skills who need to be brought in to respond to the incident. In this manner, you really get the best of both worlds in that you have a dedicated group that can quickly respond to any incident while remaining cost effective because a mechanism is provided to augment the CIRT as the situation requires. This is the method I recommend and will detail in the rest of this chapter.
CIRT Membership
Once you have identified the need for a CIRT, the next step is to identify who needs to be a member of the CIRT and what their responsibilities are. A number of roles are identified within the CIRT, including whether these people are core members or are support members who are brought in as the situation requires.
This list is not exhaustive. In addition to the CIRT members we will identify, you may periodically involve team members from outside of your organization. For example, law enforcement, vendors , business partners , and consultants could all be necessary CIRT members in the appropriate circumstances.
CIRT Team Leader This person is a core member of the CIRT and is primarily responsible for managing all the other members of the CIRT in respect to their CIRT responsibilities. The team leader is responsible for determining the relative threat any incident has and mobilizing the proper resources and personnel to address the incident.
Security Staff The security staff includes both information and physical security personnel. These people are core team members and are primarily responsible for handling any issues related to the direct contact of your systems as a result of the incident. For example, if there was a physical breach of security, the physical security staff would be the people responsible for responding to the incident. Your security staff is frequently the group that interacts with law enforcement and may even consist of retired or off-duty police officers.
Forensics Staff Your forensics staff is composed of core team members and is primarily responsible for determining what has happened as a result of the incident. The primary objective of the forensics staff is to investigate the incident in such a manner as to be able to provide evidence and establish facts that can be used for the prosecution of any crimes as a result of the incident.
IT Staff Your IT staff can be either core or support team members, depending on the circumstances. For example, you might have members of your IT staff who are involved in all incidents that may occur, or you might have members of your IT staff who only get involved when an incident occurs that affects them. Because of the cost of maintaining permanent roles in the CIRT, I recommend the latter approach as part of the hybrid method described earlier. Identify who in the IT staff the CIRT should involve for any given incident type and have those personnel provide the required level of support that the CIRT needs.
Risk Manager The risk manager is a core team member who is primarily responsible for identifying and assessing the level of risk an incident has. As previously mentioned in Chapter 2, this can typically be done by assigning a threat rating to your network resources. The risk manager can then evaluate any incidents and determine the level of risk associated with an incident so that the CIRT team leader can determine the appropriate response.
Disaster Recovery Disaster recovery is composed of support team members who are primarily responsible for coordinating incident response in regard to recovering from incidents that have resulted in a catastrophic failure on the same level that a disaster would have. For example, if you have a system that is responsible for all your business continuity (for example, SAP or PeopleSoft) and it is compromised to the point that it is rendered inoperable, this is an incident on the same level as a natural disaster, rendering the system inoperable. In these circumstances, disaster recovery can work to get the company back up and operational through the use of previously defined mechanisms, such as an offsite failover location.
Legal Staff Your company s legal staff is composed of support team members who are primarily responsible for addressing and advising the CIRT in regard to legal advice and issues. The legal staff ensures that any evidence collected during the incident response is usable in the event that the company decides to take legal action. The legal staff is also responsible for providing legal advice to address any liabilities in the event that the incident affects customers, vendors, or the general public.
| |
Under some circumstances, failure to notify law enforcement can be a crime in itself (child pornography, specifically ). Your legal staff can advise you of these situations.
| |
Human Resources Human resources personnel are support team members who are primarily responsible for addressing any personnel issues related to an incident. Unfortunately, many incidents do not involve external threats but rather internal employees. Human resources provides the necessary advice on how to properly handle any situation that involves employees to ensure that the company does not violate any employment laws.
Public Relations Public relations, particularly in regard to security and security incidents, can have a large impact on the damage an incident causes. One need only look at Microsoft for an example of that. Microsoft has regularly and routinely been taken to task in the media due to the perception that Microsoft is weak on security. This has had the result of causing many people to dismiss Microsoft products as not capable of operating in a secure environment. For example, many folks still will not acknowledge that Microsoft ISA Server is a genuine firewall. Public relations includes support team members who are responsible for providing advice and guidance on how best to handle that most delicate of security issues ”the public perception. Public relations is also critical in helping to address stockholder concerns related to a security incident.
Financial Auditor Financial auditors are support team members who are responsible for assigning a monetary value to the cost of an incident. This is a critical requirement for most insurance companies as well as being necessary if you decide to press charges under the National Information Infrastructure Protection Act.
Defining the CIRT Charter and Responsibilities
Now that we have defined what a CIRT is and who should be a member of the CIRT, the next step is to define the role and responsibilities of the CIRT. For a CIRT to be effective, it must have a clearly defined charter or mission statement. The charter should define not only the philosophy, policies, and practices that will shape the role of the CIRT, but also the goals and the level of authority the CIRT has within an organization. Like so many other things, for a CIRT to be effective, it must have management support and recognition, and the CIRT charter should be an embodiment of that support.
As mentioned previously, the objective of a CIRT is ultimately to prevent an incident. If this cannot occur, however, the CIRT has the responsibility of defining the pre-established response to an incident, thus minimizing the potential impact and keeping the incident from reaching crisis proportions .
| |
You can see an example of why you need an effective CIRT by examining what happened with SCO and the MyDoom/Norvarg worm on February 1, 2004. The MyDoom/Norvarg worm carried a payload that launched a denial of service (DoS) against www.sco.com. Although it can be difficult to combat a DoS, you can undertake steps to mitigate it. One method is to engage filtering at your upstream neighbor routers where they have the bandwidth capacity to handle the traffic load. Another option is to increase the bandwidth capacity of the network connections to deal with the increased load. A third option, in the event that the DoS is so significant that nothing can effectively be done to prevent it, would be to change the DNS records of, in this case, www.sco.com to 127.0.0.1 or remove the www.sco.com DNS entry so that at the very least the traffic does not affect the Internet in general. It is during a scenario such as this that you need a CIRT to examine the consequences and determine the most effective course of action that allows the company to respond accordingly and quickly. Can you afford the cost of increasing your bandwidth? Does your upstream provider have the capacity to attempt to filter the attack? Your CIRT can manage the options and determine the most efficient and effective course of action. Ultimately, in this case, SCO removed the DNS entry, thereby addressing the incident in a manner that was appropriate for them.
| |
In addition to the broad responsibilities of preventing and handling incident response, the CIRT has some specific responsibilities. These include the following:
-
Development and maintenance of an incident response program and the related documentation, including the integration of lessons learned from any incidents that may occur.
-
Defining and classifying incidents.
-
Determining the necessary tools and technologies to be used for detecting incidents, such as intrusion detection software and hardware.
-
Determining which incidents should be investigated and to what degree the investigation should be undertaken. This includes determining whether law enforcement should be involved and what forensics work is necessary to investigate the incident.
-
Securing the network in response to an incident.
-
Conducting follow-up interviews and reviews to provide after-action reports that can be used to prevent subsequent incidents.
-
Promoting incident awareness throughout the organization as a preventative measure.
| |
Be advised that while the CIRT should determine whether law enforcement needs to be involved and what degree of investigation should be taken, bringing in any external authorities should only be performed after consulting with management. The corporate officers are who may or may not be liable as a result of a security incident. Accordingly, you should obtain explicit instructions from management to involve legal authorities based on the CIRT recommendation. Conversely, you should document if the CIRT has recommended to involve the legal authorities and management made the executive decision not to. (Remember, in some cases, it is not management's call. If you find kiddie porn on the company server, you are breaking the law if you don't report it. But that doesn't mean you shouldn't engage management and be a good corporate citizen also.)
| |
Planning for Incident Response
This first step of planning for incident response is to determine what the organization s incident response needs are. Once you have done that, the next step is to build the policies and procedures that will be used in the event of an actual incident. Finally, a critical step of planning for incident response is to practice what needs to be done to effectively minimize the impact an incident will have on the organization.
Determining the Organization s Incident Response Needs
The easiest method of determining what services, applications, and devices need to have an incident response plan is to perform an assessment of the resources that need to be protected. This rather simple statement is an incredibly complex process, however. This is due to the fact that it is virtually impossible for a CIRT to be able to identify every resource that needs to be addressed.
You can approach this issue in a couple of ways to make it a more practical undertaking. One method is to distribute questionnaires to the relevant individuals and groups and get them to identify what their needs are. The drawback of this method is that these questionnaires are frequently not returned or are not returned in a timely fashion.
Another option, and the more successful method, is to personally approach the relevant individuals and groups to discuss what their needs are. There are a number of benefits to this approach. The most important benefit of this approach is that it allows you to establish and maintain the personal contacts that can be critical to leverage in the event of an incident. In addition, people are generally more open to discussing things and usually provide more information when they are given an opportunity not only to answer but also to ask questions regarding the process. It allows them to feel more involved, and the more involved someone is in a process, the more they care about the success of that process. Another benefit is that it gets exposure to the computer incident response team, providing an excellent avenue for marketing the value of the CIRT throughout the organization.
In performing the assessment, you should at a minimum involve the following individuals to better ensure that you have properly defined all the critical resources that need an incident response plan and the type of incident response plan that is required:
-
Department managers You need to talk to the department managers of all the departments in an organization to ensure that you identify all the resources that they use and can assign a threat level to each of them.
-
IT staff One of the best groups for identifying resources that need an incident response plan is the IT staff. This is due to the fact that the IT staff, by and large, already knows and is responsible for most of the critical technology resources in the organization.
-
Helpdesk staff The helpdesk staff is a critical group for identifying the high-risk resources in an organization. This is due to the fact that any time there is a problem with any technology resource, it is a virtual certainty that the helpdesk will be called about it. This allows the helpdesk to quickly be able to determine what is and is not important within an organization.
-
HR staff So many critical resources are components of an organization s HR resources that speaking with the HR staff is a critical component of identifying what resources require an incident response policy and the degree of policy necessary.
-
Risk management Because risk management is responsible for determining the level of risk associated with resources within the organization, it is an important group to meet with to help identify what resources require an incident response policy and the degree of detail that policy requires.
-
Users Although it is impractical to meet with all the users in an organization, it can be worthwhile to identify specific users or user groups to meet with to discuss what resources they believe need to be protected.
Building an Incident Response Policy
Like in other aspects of hardening your network infrastructure, it is necessary to design written incident response policies that provide the guidance necessary to define how to respond to an incident. The reason for this is simple: It is much easier to react to an incident when you have defined how to react, as opposed to trying to make it up in the midst of an already stressful situation. Your incident response policy contains those definitions.
RFC2350, located at ftp://ftp.rfc-editor.org/in-notes/rfc2350.txt, is the definitive best-practices standard on how to handle incident response and, in particular, how to build your incident response policies. RFC2350 details the necessity of your incident response policy documenting the types of incidents as well as the level of support that will be provided for these incidents. I recommend that you take this a step further and generate a unique incident response policy for each type of incident you identify. This is because each incident may require a different level of response, and maintaining this information in separate documents will make it much easier to determine what the appropriate response for any given incident is. Another item you should ensure your incident response policy contains is an explanation of who the CIRT routinely interacts with and the degree of cooperation that the various groups in your organization will have. This is not to define whether cooperation should occur as much as it is to reduce the chance of misunderstandings or duplication of efforts between groups. Finally, your incident response policy should detail the level of communication and disclosure that will occur as well as the appropriate mechanisms for communication and disclosure. This is to ensure that only the information the organization wants to be disclosed is disclosed and that it is done so in the appropriate manner, such as through the use of press releases.
The best way to approach an incident response policy is in the same manner you would a security policy. In fact, an incident response policy is really just a very specific security policy, and like a security policy there are sections that every incident response policy should contain, including the following:
-
Overview
-
Incident identification
-
Incident classification
-
Incident response process flow
-
Communications
-
Reporting
-
Definitions
-
Revision History
Overview The overview section should contain a brief explanation of what the incident policy addresses. This section could also include background information regarding the technology or resources the incident response policy will address. Details of how to handle the incident are left for further explanation in the other sections. This section is where you briefly explain what the incident response policy will address and what the objectives of the policy are.
Incident Identification The incident identification section is where you explicitly define the incidents that the policy covers. In addition to identifying the incidents, you need to define the types of incidents. For example, computer fraud and computer abuse are two different types of incidents that require a different kind of response.
It is also a good idea to provide examples of the incidents in the incident identification section. This will not only help people better understand what incidents the policy applies to, but it can also help to identify where you are missing or overlooking security incidents that need to be addressed with a policy.
The incident identification section is used to determine what needs to be documented in the other sections of the policy.
| |
One of the biggest differences between a security policy and an incident response policy is how they are written. Security policies are often passive documents that prescribe how systems should be used and what should be put in place to prevent something from occurring. On the other hand, incident response policies are action oriented. They focus on what to do, how to do it, when to do it, and who to notify.
| |
Incident Classification Because not all incidents require the same level of response, you need to define an incident classification system. The incident classification section is where you will define the degree of urgency and priority that incidents addressed by the incident response policy will be handled with.
Incident Response Process Flow The incident response process flow section is where the feet hit the pavement. This section concerns itself with what to do when an incident has been identified and classified . This section is where you document what to do for the incident the policy addresses. For example, if the policy addresses a compromise of your external firewall, this section should detail the steps to be followed in addressing the incident, including stating whether it is acceptable to disconnect the firewall from the network, thus terminating all Internet connectivity, or whether the firewall must be kept operational while the incident is being addressed. In addition to defining whether business continuity must be maintained , this section should also define what is required to restore business continuity after an incident. For example, your policy may dictate that before a compromised system can be brought back online and put into operation, it must be completely scrubbed and rebuilt from scratch.
A formal incident response process flow system will be discussed in more detail in the Handling Incidents section later in this chapter.
Communications The communications section is where you document who to contact regarding an incident and how to contact them. The communications section should also detail the escalation path to be used for the incident so that the appropriate people can be notified at the appropriate time.
Reporting The reporting section is where you document the kind of data that will be collected, how the data will be reported, and who the data will be reported to. This section is also where you define how much information will be released to the customers/partners/general public and who is responsible for doing so.
Definitions The definitions section is where you define any terms or concepts you used in the incident response policy to ensure that everyone understands what was meant . You should also use this section to clarify any acronyms used in the policy.
Revision History The revision history section is where you track all updates and changes made to the incident response policy. You need to document not only the current date and version of the incident response policy, but also a brief explanation of the changes made to the incident response policy and who made those changes.
Practicing for an Incident
The last step of planning for incident response is to practice for an incident to occur. The reason for this is simple: If you have undertaken the hardening steps in this book, the likelihood of you having an incident is going to be greatly reduced. If you don t periodically review what needs to be done in the event of an incident, you just might be caught with your proverbial pants down. In addition, the more you practice, the more natural it will be to react to an incident. Incident response will become second nature, and instead of spending time thinking about what you need to do in the middle of an incident, you will find yourself falling back on your practice and simply doing what needs to be done without spending a lot of time thinking about it.
The best way to practice is to simulate going through an incident. Have the CIRT respond as if an actual incident is occurring and go through the processes and procedures that you have documented as part of your incident response plan. In addition to making sure that everyone knows what they need to do, this will also show you where your incident response plan fails so that you can fix it before a real incident occurs.
Discovering Incidents
Discovering incidents is a critical part of incident response. After all, how can you respond to an incident if you don t know that an incident exists? Incident discovery really entails two separate processes. The first process is discovering incidents before they occur in your environment. The second process is discovering incidents after they occur in your environment. Each process has its own unique characteristics.
Discovering Incidents Before They Occur
Because the best incident response is to prevent an incident from becoming a crisis, the best way to discover incidents is before they occur in your environment. The best method for doing this is to monitor different vendors and organizations websites for incident reports. Table 17-1 details some common websites to monitor on a regular basis.
| Organization | Website |
|---|---|
| CERT Advisories | http://www.cert.org/advisories/ |
| SecurityFocus | http://www.securityfocus.com |
| Microsoft | http://www.microsoft.com/security/ |
| Cisco | http://www.cisco.com/security/ |
| Check Point | http://www.checkpoint.com/securitycenter/index.html |
| Red Hat | https ://www.redhat.com/solutions/security/ |
| Symantec Anti-Virus | http://www.sarc.com/ |
| Network Associates | http://www.nai.com/us/security/vil.htm |
In addition to checking vendor websites, you should subscribe to a number of mailing lists for incident notification, as detailed in Table 17-2.
| Organization | Subscription Website |
|---|---|
| NT Bugtraq | http://www.ntbugtraq.com/ |
| Buqtraq | http://www.securityfocus.com/archive |
| Full Disclosure | http://lists.netsys.com/mailman/listinfo/full-disclosure (Be advised that Full Disclosure is an unmoderated mailing list and frequently becomes filled with religious wars between Linux advocates and pretty much everyone else.) |
| SecurityFocus Incidents | http://www.securityfocus.com/archive |
| CERT Advisory Mailing List | http://www.cert.org/contact_cert/certmaillist.html |
Discovering Incidents in Your Environment
Discovering incidents in your environment can be a much trickier proposition than monitoring websites and mailing lists for vendor advisories. This is due to the fact that in many cases you don t know exactly what to look for. There are a few things that you can do to help with this, however.
Event Monitoring
Virtually all your network devices support some kind of event-logging functionality. Most support some form of syslog notification. This is important because most incidents are precipitated by some kind of event. If you monitor your event logs for these events, they can tip you off that there might be an incident happening or about to happen.
One of the biggest problems with event monitoring is the sheer volume of events. This makes it an almost impossible task to try to review your event logs. To help with this, you can use products that filter through your event logs and alert you whenever an event you have stipulated is logged. One of the products you can use to help you isolate events is Kiwi Syslog Daemon from Kiwi Enterprises (http://www.kiwisyslog.com/). Although a freeware version is available, the retail version supports configuring e-mail notification when certain administrator-configured events are logged. Another product that scales much better in large enterprises is NetIQ VigilEnt Log Analyzer (http://www. netiq .com/products/vlm/default.asp). In addition to robust alerting capabilities, VigilEnt Log Analyzer also supports very robust log archival and reporting functionality. Event monitoring has been covered in more detail in Chapter 10.
Helpdesk Ticket Tracking One of the most underestimated methods of recognizing that an incident might be occurring in your environment is monitoring the helpdesk tickets being generated. No matter how well you try to monitor your environment, one group of people will monitor your network better than you ”your end users. Your end users will almost always notice a problem with something that they use before you do. In many cases, they will call the helpdesk to report the problem. You can use this information to your advantage to try to stay on top of potential issues in your environment.
Intrusion Detection Systems Intrusion detection systems can also inform you of potential incidents by identifying any unusual traffic patterns and notifying you when they detect one. For example, many worms have a distinct signature of what their network traffic looks like. Your intrusion detection system can be loaded with that signature and be configured to alert you in the event that the traffic pattern is identified. Intrusion detection is covered in more detail in Chapter 4.
Bandwidth Monitoring Applications
A somewhat unusual event-identification system is conventional bandwidth monitoring. Many of today s worms will cause a significant increase in network traffic as they attempt to spread. If you have a bandwidth-monitoring application running on your network, it can help to identify unusual traffic spikes that could indicate that an incident is occurring. One of the better freeware products you can use to monitor your bandwidth is the Multi Router Traffic Grapher (MRTG), which can be obtained at http://people.ee.ethz.ch/~oetiker/webtools/mrtg/. In addition, BMC Software, Inc., makes two very good network-monitoring applications. PATROL DashBoard is a report-driven web-based GUI similar to MRTG. PATROL Visualis takes monitoring a step further, providing a 3D graphical topology display that can show you real-time bandwidth on a per-link basis. The benefit of this type of system is that you can actually see what network segments are being inundated with traffic so that you can isolate where the incident might be occurring. Both PATROL DashBoard and PATROL Visualis can be obtained at http://www.bmc.com/products/products_services_detail/0,,0_0_0_22,00.html.
Change Monitoring
Another method you can use to determine if an incident is occurring on your network is the use of change-monitoring applications and processes. In the case of many Cisco devices, you can actually monitor for changes by using syslog because Cisco will generate a syslog message any time that the configuration is changed. In addition, Tripwire makes a product known as Tripwire for Network Devices (http://www.tripwire.com/products/network_devices/) that can also monitor your network devices for configuration changes. For the servers in your environment, you can use another Tripwire product, Tripwire for Servers (http://www.tripwire.com/products/servers/).
Handling Incidents
Incident handling is the most important part of any incident response plan. Incident handling is where you put all the planning, preparation, and practice into effect and attempt to minimize the impact an incident has on your environment. Figure 17-1 details a process flow for implementing an incident response plan.
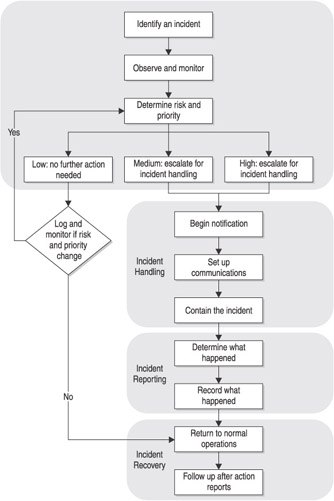
Figure 17-1: Incident response process flow
There are four phases to handling incidents. The first phase is incident discovery. The second phase is incident handling. The third phase is incident reporting, and the final phase is incident recovery.
Incident Discovery
The entrance into the incident response flow is the discovery of an incident. Although the actual discovery methods have been previously discussed, from the perspective of the incident response flow, incident discovery is the process of determining what needs to be done once the incident has been identified.
Once a potential incident has been identified, you must observe and monitor the situation so that you can assess what is happening based on the available information. The important thing at this phase is to determine whether this is a real incident that needs to be addressed. This will prevent the CIRT from having to jump through hoops for a false alarm. At the same time, you need to make sure that what you are observing is the actual problem and not merely a symptom of the problem or simply a ruse that is designed to divert attention from the real problem.
After you have established that this is indeed an incident that requires a response, you need to define the urgency and priority of the incident. This will allow you to coordinate the appropriate resources for the problem at hand. For example, if the incident is deemed a low-risk, low-priority incident that is mitigated by existing protection mechanisms, the decision might be made to do nothing further for the incident and to merely monitor the systems to ensure that it does not become a bigger issue. An example of a low-risk, low-priority incident might be one that does not result in any data loss or data compromise or an incident that affects an extremely small percentage of your environment. Medium-risk, medium-priority issues may require action, but they do not require any special efforts to begin the incident-handling process. An example of a medium-risk, medium-priority incident might be an exploit that affects a web browser and has the potential to grant privilege escalation. Although the exploit needs to be addressed, the likelihood of occurrence is relatively low (a user must visit a website that exploits the flaw) and can be addressed through routine change-control and patching procedures. On the other hand, high-risk, high-priority incidents may require the CIRT to stop whatever it is that they are doing and to focus exclusively on the incident at hand. An example of a high-risk, high-priority incident might be a worm that has begun infecting your internal resources and must be addressed immediately to prevent subsequent damage.
Incident Handling
Incident handling is the actual doing phase of the incident response flow. During the incident-handling phase, you want to identify and notify the appropriate resources and undertake the necessary steps to contain the incident.
Begin Notification
The first step of incident handling is to notify the appropriate individuals in the organization and identify the CIRT that will need to contain the incident. This is the phase in which the relevant on-call personnel should be notified. During the notification phase, the CIRT team leader will ensure that the previously defined processes and procedures for addressing the incident begin being put into action. The CIRT team leader should also decide if the incident meets the requirements for involving legal authorities or if it meets requirements to make notifying the legal authorities mandatory. It is important at this phase that the CIRT team leader has the necessary authority to carry out the response that has been identified.
Set Up Communications
Because the CIRT members may span multiple sites and physical locations, or they may be running here and there trying to respond to the incident, it is important to establish a method of communication so that all the CIRT members can communicate their status, actions, and responses. This is also critical in ensuring that there is no duplication of effort or, even worse , that people start unintentionally undoing things that other CIRT members did. You also need to establish communications with management so that you can keep them apprised of the situation, and you might need to notify public relations so that they can begin drafting a public response as required.
Contain the Incident
Incident containment is simply the process of limiting the scope of an incident as much as you can. Incident containment will often require the application of vendor patches to address security holes that contributed to the incident. This type of containment is best applied before the security hole has been exploited in your environment as a preventative measure. If you cannot do this, however, remember that patching a compromised system can still leave a back door in place and operational. Although a patch can address the security hole, it often does not address the results of the security hole. In many cases, incident containment will also require the disconnecting of systems from the network or the Internet to prevent the spread of the incident and to make it easier to recover systems. You have to weigh this against the need to catch an intruder, however. If the incident in question is a new worm, it probably isn t worth the effort to try to catch who you got the worm from; instead, you want to isolate the infected systems and remove the worm. However, if the incident is someone attempting to gain access to your internal database of customer financial records, you will probably need to weigh very carefully whether it is more important to contain the incident right now, or if the incident can be allowed to proceed a little longer in an attempt to determine who is responsible.
Incident Reporting
After you have successfully contained the incident, the next phase is to prepare to report the incident to the necessary organizations. In some cases, that will be law enforcement. In other cases, it will be internal management resources, and in yet other cases, it might be an ISP.
| |
The National Infrastructure Protection Center (NIPC) maintains an excellent incident-reporting form in both online and PDF format that provides a good example of the kind of information you need to gather and be prepared to present when reporting an incident. This form can be accessed at http://www.nipc.gov/incident/incident.htm. Some common elements to include in your incident response form are listed here:
-
Point of contact information.
-
Date and time of the incident.
-
Whether the affected system is business critical.
-
Nature of the problem. (Was it an intrusion, a website defacement, a worm, and so on?)
-
Suspected method of intrusion/attack. (Did it use a trap door or Trojan horse, or was there a vulnerability that was exploited? If so, what was the vulnerability?)
-
Suspected perpetrators or motivation for the attack.
-
Whether any spoofing appears to have been used.
-
The apparent source of the incident.
-
What systems (hardware and software) were affected.
-
Whether there was a loss in data, and the level of sensitivity of the data loss.
-
What actions have been taken to mitigate/resolve the incident.
| |
Determine What Happened The first step of incident reporting is to determine exactly what happened, why it happened, and how it happened, and then to identify the steps necessary to prevent it from happening in the future. It may be necessary to involve an internal or external forensics team to assist in trying to determine what occurred. It is important at this step to remember that there is no magic in computing. Computers and networks do exactly what they are programmed to do every time. Even when systems crash, they are doing so because they were programmed to do so. In determining what happened, do not leave things to chance, guesswork, or gut feelings. Although those are all potentially valuable in helping to determine what happened, you need to deal in facts at this stage of the game. In addition to figuring out what happened, you also need to identify who was or is still involved in the incident. This might be an internal or an external person or group.
Record What Happened Next, you should document everything about the incident. No detail is too small, especially if there is any possibility that there might be litigation or criminal prosecution as a result of the incident. A critical component of recording what happened is maintaining a verifiable chain of custody. The chain of custody is simply the ability to ensure that at no time has any evidence been tampered with. To establish a chain of custody, you must be able to prove the following:
-
No information has been added, changed, or deleted.
-
A complete copy was made.
-
A reliable copy process was used.
-
All media was secured.
You can obtain more detailed information about chain of custody and the federal rules on evidence at http://www. usdoj .gov/criminal/ cybercrime /usamarch2001_4.htm or by speaking with your legal department and ensuring that they help to develop your chain of custody process.
In addition to simply documenting the incident, it may also be necessary that you make a backup of all the damaged/tampered with systems so that they can be submitted for legal purposes.
Incident Recovery
The last step is to recover from an incident. Incident recovery is typically the most important step of all of incident response as far as management is concerned . The sooner that an incident has been addressed, the sooner the company can get back to business. This desire often puts an incredible strain on the CIRT that might influence the team to perhaps not spend as much time investigating the incident or containing the incident before they attempt to bring the resources back online. At all costs, this desire must be resisted, and you need to make sure you follow all the steps of the incident response flow to ensure that you have effectively addressed the incident and have not done anything that could ultimately harm the company in a desire to get things running again.
In addition to simply restoring the operation of systems, recovering from an incident also includes ensuring that all the vulnerabilities and points of penetration used to exploit the systems have been properly patched or corrected. You should ensure that you did not go through all these efforts just to have the incident repeat itself again in the future.
Unfortunately, often the only way to recover from an incident is to wipe the system out and reinstall. This is particularly critical if you even suspect that the incident may have enabled an intruder to install any kind of software (such as a Trojan horse or key logger) on the system. Although it may be easier to say, But we found the Trojan so everything must be OK, the truth of the matter is that you have to approach it from the perspective of If they did this, there is no way to know what else they might have done. You need to be prepared to accept this consequence as a result of a security incident.
The last thing to do after you have returned to normal operations is to have a formal review process and perform an after-action report on the incident. The goal is twofold: First, you want to understand everything that conspired to cause the incident to occur so that you can make sure you addressed any of the issues to ensure that this never happens again. Second, you want to review how the CIRT performed and how well the incident response policies and procedures worked in containing and recovering from the incident. This will help you identify areas that need to be changed or improved to ensure a more effective process the next time an incident occurs ”because there will be a next time.
EAN: N/A
Pages: 125