Object-Oriented Data Model, Smart Service Layer, and Documents
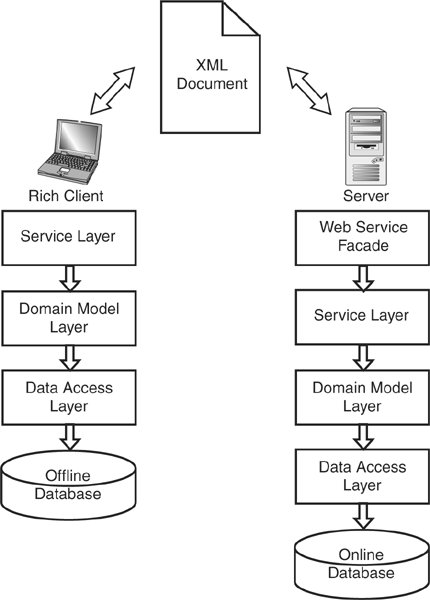
By Mats Helander Sometimes, during dark winter nights, I recall faintly what life was like in the days before the Domain Model. It is at times like those that I pour a little cognac into my hot chocolate and throw an extra log on the fire. The evolution of the architecture in my applications, finally leading up to the use of the Domain Model, followed a pattern some readers may feel familiar with. I'm going to outline this evolution quickly, as it helps put my current approach for using the Domain Model into context. In the BeginningI started out writing client-server applications where all the application code was stuffed into the client, which would talk directly to the database. When I started writing Web applications, they consisted of ASP pages with all the application code in them including the code for calling the database. Because the result of this type of application architecture is, without exception, a horrific mess whenever the application grows beyond the complexity of a "Hello World" example, I soon learned to factor out most of the code from the presentation layer and to put it in a Business Logic Layer (BLL) instead. Immediately, the applications became easier to develop, more maintainable, and as a bonus the BLL could be made reusable between different presentation layers. It should also be noted that in those days, it could make a big difference to the performance and scalability of a Web application to have the bulk of its code compiled in a component. The next step was to lift out all the code responsible for communicating with the database from the BLL and put it in a layer of its own, the Data Access Layer (DAL). I recall that I was slightly surprised to see that the DAL was often substantially larger than the BLLmeaning more of my application logic dealt with database communication than with actual business logic. At this time, I was almost at the point where the Domain Model would enter into the equation. The PL would talk to the BLL that would talk to the DAL that would talk to the database. However, all data from the database was passed around the application in the form of Recordsets, the in-memory representation of rows in the database (see Figure A-1). Figure A-1. Classic, pre-Domain Model layered application architecture Sometimes, working with the data in its relational form is just what you want, and in those cases the architecture described earlier still fits the bill nicely. But, as I was becoming aware of, relational data structures aren't always ideal for the business logic to work with. Object-Orientation and Relational Data StructuresFrom some work I had done with an object-oriented database from Computer Associates called Jasmine, I had come to understand that an object-oriented data structure was quite often a lot easier to work with when developing the business logic than the corresponding relational structure. Relationships between entities are simpler, for one thing. In the case of many-to-many relationships, this is especially so, because the relational data structure requires an additional table whereas no additional class is required in the object-oriented data structure. Collection properties are another case where an additional table is used in the relational model but no extra class is required in the object-oriented data structure. Furthermore, object-oriented data structures are type safe and support inheritance. The Domain Model and Object-Relational MappingThe problem was that OO databases weren't that common. Most projects I encountered still revolved around the relational database. This is where Object-Relational Mapping entered the picture. What Object-Relational Mapping does is to let you take an object-oriented data structure and map it to the tables in a relational database. The advantage is that you will be able to work with your object-oriented data structure as if working with an OO database like Jasmine, while in reality you're still using a relational database to store all your data. Furthermore, you can add business logic to the classes of the object-oriented data structure in the form of business methods. As you may have guessed, the object-oriented data structure with business methods that I'm talking about is that's rightthe Domain Model. By learning about Object-Relational Mapping I could finally take the step toward including the Domain Model in my application architecture. Inserted between the BLL and the DAL, the Domain Model Layer now allowed my business logic to work with an object-oriented data structure (see Figure A-2). Figure A-2. Updated, layered application architecture including Domain Model This meant that a BLL method that had previously been working with a Recordset containing a row from the Employees table would now instead work with an Employee Domain Model class. I gained type safety, and the code became shorter and easier to readnot to mention that I could navigate my data structure during development using Microsoft's IntelliSense feature! Ever since, I've been a devoted user of the Domain Model and I haven't looked backexcept during those cold, dark winter nights. As I mentioned, another advantage with the Domain Model is that it lets you distribute your business logic over the Domain Model classes. I've experimented a lot with where to put my business logic. I've shifted between putting most of it in the Business Logic Layer to putting most of it in the Domain Model Layer and back again. Service LayerI've also come to prefer the term Service Layer [Fowler PoEAA] to Business Logic Layer, as it better covers what I'm doing at times when most of my business logic is in the Domain Model Layer. When most of my business logic is in the Service Layer I see no reason to switch back to the term Business Logic Layer, though I sometimes refer to it as a "thick" Service Layer to distinguish it from a more conventionally thin Service Layer. These days I almost always put most of the business logic in a "thick" Service Layer. While some OO purists might argue that structure and behavior should be combined, every so often I find it practical to keep the business logic-related behavior in the Service Layer. The main reason for this is that in my experience, business rules governing the behavior of the Domain Model will usually change at a different pace, and at different times, from the rules governing the structure of the Domain Model. Another reason is that it easily lets you reuse the Domain Model under different sets of business rules. Normally, the only business methods I would put on the Domain Model objects themselves are ones that I believe are fundamental enough to be valid under any set of business rules and are probably going to change at the same time and pace as the structure of the Domain Model. With most of my business logic in the Service Layer, the application architecture is nicely prepared for the step into the world of SOA. But before we go there and take a look at how I would tackle Jimmy's example application, I'd just like to stress another particular benefit of this approach. Combining ThingsAs I mentioned earlier, the object-oriented data structure offered by the Domain Model isn't the perfect fit for every operation you'll want to perform. There are reasons why relational databases are still so popular and why many people prefer to use Object-Relational Mapping before going with an actual OO database. For many tasks, the relational data structure and the set-based operations offered by SQL are the perfect fit. In these cases, slapping methods onto the Domain Model objects that will actually be performing set-based operations directly on the relational data structures may not seem like a very natural way to go. In contrast, letting Service Layer methods that access the database directly (or via the DAL) co-exist side by side with methods that operate on the Domain Model is no stretch at all. Converting a Service Layer method from using one approach to the other is also easily accomplished. In short, I'm free to implement each Service Layer method as I see fit, bypassing the Domain Model Layer where it is not useful as well as taking full advantage of it where it is useful (which, in my experience, happens to be quite often). Jimmy's Application and SOAHaving said that, let's return to Jimmy's application and the brave new world of SOA. So far I have only really described what my application architecture looks like on the server, which may be enough for a Web application, but now we're going to deal with a Rich Client, and I'd like to focus on application servers as a variation to the rest of the book. In cases where a lot, if not all, of the business logic has been distributed over the Domain Model, a tempting approach is to try to export both data and behavior packaged together in this way to the Rich Client by giving it access to the Domain Model. With the architecture I'm using, where most of the behavior is found in the Service Layer, a more natural approach is to expose the behavior and the data separately. Concretely, the Service Layer is complemented with a Web Service façade (a type of the Remote Façade pattern [Fowler PoEAA]), which is just a thin layer for exposing the business logic methods in the Service Layer as Web Services. The Rich Client communicates with the server by calling the Web Services, exchanging XML documents containing serialized Domain Model objects. For our example application, this means that each time the Rich Client needs new information it will call a Web Service on the server that will return the information in the form of an XML document. To begin with, let's take the case of listing customers matching a filter. I would begin by creating a GetCustomersByFilter() Service Layer method implementing the actual filtering. The Service Layer method would take the filter arguments and return the matching Domain Model objects. Then I'd add a GetCustomersByFilter() Web Service exposing the Service Layer method to the Rich Client. The Web Service accepts the same filter arguments and passes them on in a call to the Service Layer method. The Domain Model objects returned by the Service Layer method would then be serialized to an XML document that would finally be returned by the Web Service. The Rich Client can then use the information in the XML document to display the list of customers to the user (see Figure A-3). Figure A-3. Rich Client Application Server layered application architecture including Domain Model It is completely up to the Rich Client application developers if they want to create a client-side Domain Model that they can fill with the data from the XML document. They may also decide to store the information for offline use. One way is to just save the XML documents to disk. Another is to persist the client-side Domain Models to an offline database on the client machine. Note that the eventual client-side Domain Model doesn't have to match the Domain Model on the server. Accordingly, if the client-side Domain Model is persisted to an offline database, the client-side database will presumably follow the design of the client-side Domain Model and thus doesn't have to look like the server-side database. Note One important difference regarding the schema of the server-side database and the client-side database is that if a server-side database table uses automatically increasing identity fields, the corresponding client-side database table normally shouldn't. Say that a new employee is created on the server. As a new row is inserted in the Employees table it is automatically given a value in its auto-increasing ID column. The employee is then serialized and sent to the client, which fills a client-side Domain Model with the data and stores it in the client-side database for offline use. The new row in the client-side Employees table should not be assigned with a new IDthe ID that was assigned to the employee in the server-side database should be used. This means that the properties for the ID columns may be different on the client and the server. The point here is that the developers of the Rich Client application are free to decide whether or not they want to use a Domain Model at all, and if they want one they are free to design it as they see fit. The communication between client and server is 100% document-oriented, and no assumptions about the Domain Models on either side are made by the other. For example, maybe the Rich Client calls Web Services of many different companies, all capable of returning lists of customers but all with slightly different fields in their XML documents. One way to deal with this would be to create a "superset" client-side Customer Domain Model object with properties for all the different fields that were returned from all the companies called. Next, we want the user of the Rich Client application to be able to look at the orders belonging to a particular customer. The unique ID of each customer was of course included in the XML document returned by the first Web Service, so we know the ID of the customer in which we're interested. What I have to do is to implement a Web Service that takes the ID of a customer and returns the orders for that customer. Again, I begin by creating a GetOrdersByCustomerID() Service Layer method that accepts the ID of a customer and returns the Domain Model Order objects belonging to the customer. I'll then proceed by adding a GetOrdersByCustomerID() Web Service that takes a customer ID, passes it along to the Service Layer method, and finally serializes the returned order objects into an XML document that can be returned by the Web Service. However, in this case, some extra attention has to be paid to the XML serialization. We want the XML document to include the total value for each order, but the Order Domain Model object doesn't contain any TotalValue property because the total value of an order is not stored in any field in the database. Rather, the total value is calculated whenever it is needed by adding the values of the order lines together. The value of each order line, in its turn, is calculated by multiplying the price that the purchased product had when it was bought by the number of items bought. Because the order lines aren't included in the XML document sent to the client, the client application can't calculate the total values for the orders, which means that the calculation has to be done on the server and the result has to be included in the XML document. The methods for calculating the value of an order line and the total value for an order are good examples of the type of method that many people would prefer to put on the OrderLine and Order Domain Model objects but that I prefer to put in the Service Layer. Service Layer DesignThis may be a good time to mention that I usually organize my Service Layer around the same entities that are used in the Domain Model, rather than by task, which is otherwise also popular. This means that if I have an Employee object in the Domain Model Layer, I'll have an EmployeeServices class in the Service Layer. For services that don't need any transaction control, I also usually implement the Service Layer methods as static methods so that they can be called without instantiating any object from the Service Layer classes. In the case at hand, I would thus place a static GetValue() method on the OrderLineServices Service Layer class and a static GetTotalValue() method on the OrderServices class. These methods will accept the objects they should work with as parameters. This means I won't be calling a method on the Order object itself in the following fashion: myOrder.GetTotalValue(); Instead I'll be calling a Service Layer method, like this: OrderServices.GetTotalValue(myOrder); It is this kind of procedural syntax that has some OO purists jumping in their seats, hollering, and throwing rotten fruit, but I think that the benefits that follow from separating the behavior from the structure of the Domain Model are well worth the slightly uglier syntax. Of course, the service methods don't have to be static, and sometimes they can't befor example, if they should initiate a declarative transactions or if you want to configure your SL classes using Dependency Injection (see Chapter 10, "Design Techniques to Embrace"). But when static methods will do, I usually make them static simply because that means less code (no need to waste a line of code instantiating a SL object every time I want to call a service). Because it makes for less code, I'll continue using static service methods in my examples. The point is that I don't really lose the opportunity for organizing my methods pretty much as nicely as if I had put them on the Domain Model classes. Because for every Domain Model class I have a corresponding Service Layer class, I'm able to partition my business logic in just the same way as if I had distributed it over the actual Domain Model. The benefit comes when the rules for GetTotalValue() start changing even though the underlying data structure doesn't changesuch as when suddenly a systemwide rule should be implemented stating that an order may not have a total value exceeding one million SEK. You can then just modify the relevant Service Layer methods without having to recompile or even touch your Domain Model Layer that can remain tested and trusted. Returning to the GetOrdersByCustomerID() Web Service, I just add a call to the Service Layer OrderServices.GetTotalValue() method to which I pass each order during the serialization routine and add a field to the XML document for holding the result. This provides us with a good example of how the Domain Model on the client, should the client application developer choose to implement one, can differ from the server-side Domain Model. The client-side Domain Model Order object might well include a property for the total value as presented in the XML documenta property that the server-side Domain Model Order object doesn't have. Following this approach, we may decide to include even more fields in our XML document with values that have been calculated by Service Layer methods. For instance, consider a system-wide rule specifying that a customer may not owe more than a certain amount of money. The precise amount is individual and calculated by some special Service Layer method. When designing the XML document to return from the GetCustomersByFilter() Web Service, you may want to include a field for the maximum amount each customer can owe, or at least a flag stating if the customer is over the limit. This goes to demonstrate that the documents offered by the server don't have to match the Domain Modelcommunication between client and server is entirely document-oriented. Looking at what we have at the moment, the user of the Rich Client application should be able to view filtered lists of customers and to view the list of orders belonging to each customer. Next, we want to let them check out the order lines belonging to a specific order. There's no news in how this is implemented: The client calls a Web Service with the ID of the order, the Web Service forwards the call to a Service Layer method and serializes the results to XML. By now, we know the drill for letting the client fetch data. What about letting the client submit data? Submitting DataLet's say we want the user to be able to update the status of an order from "Not inspected" to "Approved" or "Disapproved." At first glance it may seem like a straightforward request, but we're really opening a Pandora's Box of concurrency problems here as we move from read-only to read-write access. So let's begin by sticking with the first glance and not look any closer for a little while. How would we do it then? The first thing to do is to create an UpdateOrderStatus() Service Layer method and a corresponding Web Service. The methods should accept the ID of the order and the new order status as parameters and return a bool value telling you if the operation completed successfully. (We won't go into any advanced cross-platform exception handling hereeven though it's a whole bunch of fun!) So far, so good; the Service Layer method is easy enough to implement, and the Web Service is just a wrapper, forwarding the call to the Service Layer method. Now let's look at the problems we're going to run into. The problems arise if two users try to update the status of the same order at the same time. Say that user A fetches an order, notes that it is "Not inspected" and goes on to inspect it. Just a little later, user B fetches the same order, notes the same thing, and also decides to inspect it. User A then notes a small problem with the order, causing her to mark the order as "Disapproved" in her following call to the UpdateOrderStatus() Web Service. Just after user A has updated the status of the order, user B proceeds to call the same Web Service for updating the status of the same order. However, user B hasn't noticed the problem with the order and wants to mark the order as "Approved." Should user B be able to overwrite the status that A gave the order and that is now stored in the database? A standard answer would be "No, because user B didn't know about the changes user A had made." If user B had known about the change that user A made and still decided to override it, the answer would be "Yes" because then B could be trusted not to overwrite A's data by mistake. So the challenge becomes this: How do we keep track of what B, or any other client, "knows"? One approach is to keep track of the original values from the database for updates fields and then at the time when the modified data is saved to the database, check if the original values match those that are in the database now. If the values in the database have changed, the client didn't know about these changes and the client's data should be rejected. This approach is called optimistic concurrency. Let's look at a very simple way that optimistic concurrency could be implemented for the case at hand. To begin with, the client application has to be coded so that when the user changes the status of an order, the status that was originally returned from the database via the XML document is still kept around. Then the UpdateOrderStatus() Web Service and the Service Layer method with the same name have to be modified to accept an additional parameter for the original order status value. Thus, when the client calls the Web Service, three parameters are passed: the ID for the order, the new order status, and the original order status. Finally, the UpdateOrderStatus() Service Layer method should be updated to include a check if the current status for the order in the database matches that which was passed to the parameter for the original order status, executing the update only if the values match. This version of optimistic concurrency, matching the original values of updated fields with those in the database, will give good performance and scalability, but it can be a bit cumbersome to implement, at least in a Rich Client scenario. An alternative way of using optimistic concurrency is to add a versioning field to the tables in your database. Sometimes even strategies like optimistic concurrency won't work, so domain-specific solutions have to be applied in those cases. A normal theme is to use some sort of check-in/out system, where the user marks an object as "checked out" or "locked" when it is fetched for write access, preventing other users from updating it until she is done. Other, more sophisticated schemes include merging of concurrently updated data. The only way to decide on what strategy is appropriate in the particular case is to ask the domain specialistthat is, the person understanding the business implications of these decisionswhat behavior is desired. There's no general way to select a concurrency strategy. Even so, I'm guessing that the appropriate way to go in this case would be to use optimistic concurrency, with or without a versioning field. The point is that it is still up to somebody who knows what the expected behavior is for their business to decide. Perhaps the biggest problem with the approach we have used here is that we have asked the client to keep track of the original values for us. This is probably asking a bit too much of the client application developer, so a better alternative might be to store the original values on the server in a Session variable or a similar construct. How Fine-Grained?Another thing to consider is whether the service is too fine-grained. Rather than providing a separate Web Service for every field of an order that can be updated, could we, perhaps, implement a single UpdateOrder() Web Service instead? In this case, rather than providing a parameter for each updateable field, the Web Service could accept an XML document representing the updated order. That is, instead of this: [WebMethod]public bool UpdateOrder(int orderID, int orderStatus , DateTime orderDate, int customerID) you could use this: [WebMethod] public bool UpdateOrder(string xmlOrder) In this way the client both receives and submits data in the form of XML documents. This strictly document-oriented approach helps in keeping the Web Services API coarse-grained and avoiding overly "chatty" conversations between the client and the server (see Figure A-4). Figure A-4. Overview of full application architecture A Few Words About TransactionsFinally, a note on transactions. As I mentioned earlier, I usually make my Service Layer methods static whenever I don't need transactions, but in the case of a business application managing orders, I'm inclined to believe transactions will be part of the solution. This implies that, for example, the UpdateOrderStatus() method should be transactional. What this means is that instead of making this method static I turn it into an instance-level method and mark it with the [AutoComplete] .NET attribute. Because I'm also going to mark the whole class that the method belongs to with the [transaction] attribute and let it inherit from ServicedComponent, I decide to lift this method out of the OrderServices class and into a new class called OrderServicesTx, where "Tx" stands for "transactional." And that's it. All my UpdateOrderStatus() Web Service has to do now is to create an instance of the OrderServicesTx class and call the UpdateOrderStatus() on that object instead of calling the old static method on the OrderServices class. The execution of the OrderServicesTx.UpdateOrderStatus() will use distributed transactions that will be automatically committed if the method finished without exceptions and rolled back otherwise. The Service Layer is, in my opinion, the perfect place to enforce transaction control in your application. It is also a great place for putting your security checks, logging, and other similar aspects of your application. Note that all the methods in the Service Layer don't have to be organized around the entities from the Domain Model layer. Just because I'll have EmployeeServices, CustomerServices, and so on, that doesn't mean I won't also have LoggingServices and SecurityServices classes in my Service Layer as well. SummaryMy preferred style is to put most of the business logic in the Service Layer and let it operate on the object-oriented data structure represented by the Domain Model. The communication between client and server is completely document-oriented, and no attempt to export the Domain Model to the client or even to let the client access the server-side Domain Model (for example, via Remoting) is made. I hope I've been able to give some idea about how I use the Domain Layer and whyas well as how I would go about designing Jimmy's application. |



EAN: 2147483647
Pages: 179