MDA with AndroMDA
|
| Compared to the slick commercial MDA products, AndroMDA offers a nuts-and-bolts approach to practicing MDA. It provides no form of visual development environment, instead initiating the entire MDA process using an Ant build file. It may seem strange that a tool proclaiming to support MDA should have no means of visually building a PIM. This is in stark contrast to products like OptimalJ that offer a complete integrated MDA development environment with support for building the initial model through to editing, deploying, and debugging the generated application. In this regard, OptimalJ rates as a complete MDA implementation. Due to the wide scope of the MDA domain, the MDA standard states MDA can be practiced using a federated collection of tools, each supporting a specific aspect of the process. For example, a tool may focus on support for mapping from PIM to PSM, while another generates code from the PSM. MDA makes this approach possible by ensuring models are shareable between tools. AndroMDA relies on a suitable modeling tool to first generate the PIM from which it can start the code generation process. AndroMDA generates a working application with the template engine Velocity and the attribute-oriented programming product XDoclet.
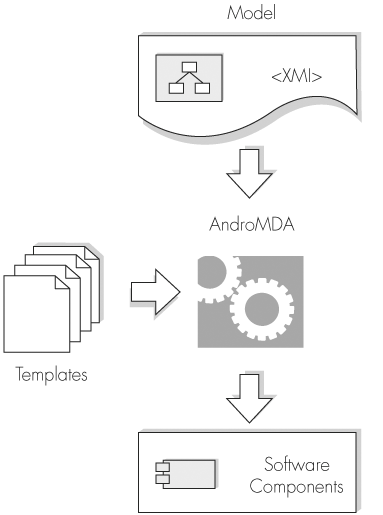
Chapter 6 covers both Velocity and XDoclet. Figure 8-2 provides an overview of MDA with AndroMDA. Figure 8-2. Code generation with AndroMDA. Moving from PIM to working application with AndroMDA involves a number of steps:
Note Notice in Figure 8-2 that AndroMDA foregoes the mapping to a PSM and instead goes directly to the implementation model. This direct transformation from PIM to code is a valid MDA approach and complies with the MDA standard. Commercial MDA tools such as OptimalJ support the generation of a PSM. Generating a PSM allows the architect to further refine the PSM and so gives greater control over the application generated. AndroMDA users must rely on the pluggable MDA cartridges to produce suitable output. However, refinement of the model is possible under AndroMDA by modifying the templates used by the relevant MDA cartridges. The steps outlined introduce several new MDA concepts, such as marks and cartridges, which warrant further explanation. Model Interchange with XMIAndroMDA uses the XMI specification for importing models built with a modeling tool. XMI is another OMG standard that, along with standards such as UML and MOF, has been bundled under the MDA umbrella. Unfortunately, while XMI is a standard for model interchange, like ice cream, it comes in many different flavors. In practice, these different flavors, or dialects, virtually negate the benefits of the XMI standard, because different dialects raise compatibility issues between modeling tools. This situation is at odds with the MDA concept of sharing models between tools. Due to this confusion over the XMI format, you may find you cannot use your favorite modeling tool for generating a model that can be imported into AndroMDA. To avoid this problem, you can use a modeling tool the AndroMDA team states is compliant with an XMI dialect AndroMDA expects. One such product that has close ties with AndroMDA is Poseidon from Gentleware, a commercial spinoff from the open source modeling tool ArgoUML. A community edition of this product is available from the Gentleware Web site at http://www.gentleware.com. The community edition offers a good feature set and supports the exporting of models as XMI. An AndroMDA plug-in has been developed for Poseidon that integrates the two products and enables AndroMDA to access a Poseidon model in its native format. Full details of this plug-in are available from the Gentleware and AndroMDA sites. If Poseidon is not to your liking, MagicDraw from No Magic is also recommended. A community edition of MagicDraw is obtainable from http://www.magicdraw.com. PIM MarksDespite the richness of information conveyable by a UML model, tools that perform the mapping between PIM and PSM often require some direction as to how a mapping should be performed. The MDA standard provides several guidelines for the mapping process, one of which is the use of marks. Marks identify those elements within a PIM that must be transformed with a predetermined set of transformation rules. The marks themselves can be from a variety of UML-compliant sources, including:
The use of stereotypes is one of the more common approaches to marking the PIM, and this is the method used by AndroMDA. Stereotypes, a concept from the UML, are a means of extending the UML. They enable model elements to be embellished with additional values, constraints, and if required, a new graphical representation. Essentially, they serve as metaclasses within the UML. Declaring a model element to be of a particular stereotype causes the element to take on the full list of characteristics associated with the stereotype. The UML notation has the name of the stereotype enclosed within guillemets, or chevrons. Perhaps the stereotype with which most people are familiar is the <<interface>> stereotype. Although Java supports the use of interfaces through a reserved keyword, other languages do not, and the UML relies on a specialized form of the class type to represent elements with this behavior. The <<interface>> stereotype expresses the constraint that all methods of the class are abstract. The stereotype further allows UML tools to render classes of this type using a circle for the notation instead of the classic rectangle. The <<interface>> stereotype is already well used by the code generation facilities of most modeling tools. Such tools know how to generate Java interfaces from elements expressing this stereotype instead of generating Java classes. We can declare stereotypes for our models as we wish and have the MDA tool map them accordingly. Figure 8-3, drawn using MagicDraw, depicts a simple class diagram showing stereotypes known to AndroMDA. Table 8-1 summarizes the stereotypes used in the example model. These stereotypes are used during code generation to direct output. Figure 8-3. PIM with AndroMDA-compliant stereotype marks.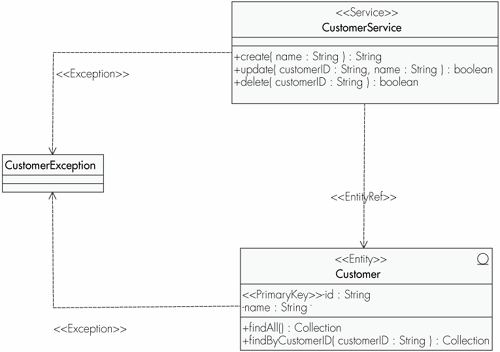
The PIM shown in Figure 8-3 has a stereotype for each class. Adding the stereotype <<Service>> to CustomerService marks the class as being a provider of some form of business service. In a PIM, we are unconcerned with how the customer service is represented in the final system. Likely, implementation options include a Web Service, an enterprise bean, or even an RMI object. A stereotype of <<Entity>>, as shown on the Customer class, indicates some form of domain model object, which requires persistence. Again, how this persistence is implemented is the concern of the transformation process. The modeler defers the decision as to whether technologies such as entity beans, JDO, or an O/R mapping product like Hibernate will be used. Although this model is supposed to be platform-neutral, admittedly the operation findByCustomerID() has distinct EJB architecture overtones. Not only the classes but also the associations and operations in the diagram have been marked. The dependency association between CustomerService and Customer carries a stereotype of <<EntityRef>>. Likewise, the attribute id has been stereotyped with <<PrimaryKey>>. All of this metainformation is used by AndroMDA to determine the architecture of the application generated. Next, we examine how AndroMDA transforms model elements into code based on their stereotype. MDA CartridgesAndroMDA code generation is driven by stereotypes. Stereotyped elements in a PIM are mapped to code using pluggable code generation cartridges, with cartridges existing to specify the transformation rules for each AndroMDA stereotype. We saw a similar approach used with Middlegen, albeit without the use of stereotypes. Middlegen allows different persistence mechanisms to be supported with plug-ins. Our example used the Hibernate plug-in to generate Hibernate configuration files based on metadata retrieved from the database. Other Middlegen plug-ins exist for entity beans and JDO. Middlegen delegates the task of generating code to its plug-ins. Middlegen itself takes responsibility for interrogating the database for the necessary metadata, supplying this information to all plug-ins configured from the Ant build file.
Middlegen is covered in Chapter 7. AndroMDA plays a similar role to Middlegen, except AndroMDA obtains its metadata from a UML model instead of the database. An AndroMDA cartridge is similar to a Middlegen plug-in insofar as they both generate code from metadata. Four cartridges come complete with the AndroMDA distribution:
The AndroMDA core searches the classpath to locate any installed cartridges. Model elements that have a known AndroMDA stereotype are passed to each cartridge discovered on the classpath. Cartridges are configured under the <andromda> Ant task. This task points AndroMDA at a PIM and specifies those cartridges used for generating the application. Listing 8-1 shows a section taken from an Ant build file of a build configuration using the andromda-struts cartridge. Listing 8-1. AndroMDA Build File<andromda basedir="." modelURL="${model}.xmi" lastModifiedCheck="true" typeMappings="${andromda}/src/xml/TypeMapping.xml"> <userProperty name="foreignKeySuffix" value="_FK" /> <outlet cartridge="java" outlet="value-objects" dir="${gen.dir}" /> <outlet cartridge="hibernate" outlet="entities" dir="${gen.dir}" /> <outlet cartridge="hibernate" outlet="entity-impls" dir="${impl.dir}" /> <outlet cartridge="hibernate" outlet="session-beans" dir="${gen.dir}" /> <outlet cartridge="hibernate" outlet="session-impls" dir="${impl.dir}" /> </andromda> The nested element <outlet> configures the location of all source generated by each cartridge's outlet. An outlet is essentially a template defined within the MDA cartridge. We look at the function of outlets in the next section. Each cartridge is referred to by its name, as specified using the cartridge attribute, with the outlet attribute identifying the outlet within the cartridge. The ability to direct generated source to different locations is important, as some generated classes are intended to be modified by the developer. This fits in with the code generation guideline of separating actively generated code from code maintained by hand. In the next section, we deconstruct the anatomy of an AndroMDA cartridge to determine how it generates code from a UML model. Anatomy of a CartridgeCartridges enable a stereotype to be married to a template. AndroMDA uses the Apache Velocity as its template engine, making the task of building a cartridge simple for anyone familiar with the Velocity Template Language (VTL).
For a summary of VTL commands, see Chapter 6. The MDA standard states a mapping may include templates, which it describes as parameterized models for specifying a particular transformation. Templates offer a very powerful mapping mechanism and enable entire design patterns to be generated from a single mark in the PIM. The secret to how a cartridge associates a stereotype with a Velocity template lies in the cartridge's deployment descriptor. Each AndroMDA cartridge must provide a deployment descriptor named andromda-cartridge.xml that resides under the META-INF directory in the jar file. Listing 8-2 shows the deployment descriptor for the andromda-hibernate cartridge. Listing 8-2. AndroMDA Hibernate Cartridge Deployment Descriptor <cartridge name="hibernate"> <property name="persistence" value="hibernate" /> <stereotype name="Entity" /> <stereotype name="Service" /> <outlet name="entities" /> <outlet name="entity-impls" /> <outlet name="session-beans" /> <outlet name="session-impls" /> <template stereotype="Entity" sheet="templates/HibernateEntity.vsl" outputPattern="{0}/{1}.java" outlet="entities" overWrite="true" /> <template stereotype="Entity" sheet="templates/HibernateEntityImpl.vsl" outputPattern="{0}/{1}Impl.java" outlet="entity-impls" overWrite="false" /> <template stereotype="Entity" sheet="templates/HibernateEntityFactory.vsl" outputPattern="{0}/{1}Factory.java" outlet="entities" overWrite="true" /> <template stereotype="Service" sheet="templates/HibernateSessionBean.vsl" outputPattern="{0}/{1}Bean.java" outlet="session-beans" overWrite="true" /> <template stereotype="Service" sheet="templates/HibernateSessionBeanImpl.vsl" outputPattern="{0}/{1}BeanImpl.java" outlet="session-impls" overWrite="false" /> </cartridge> The first clue to how the AndroMDA core triggers a cartridge is with the <stereotype> elements: <stereotype name="Entity" /> <stereotype name="Service" /> These two lines associate the cartridge with model elements bearing the stereotypes of <<Entity>> and <<Service>>. The cartridge generates code for model elements based on either of these two stereotypes using a template. AndroMDA allows multiple template types to be associated with a single stereotype, thus several templates can be used in generating the code for a single model element. The <template> element maps stereotypes to templates: <template stereotype="Entity" sheet="templates/HibernateEntity.vsl" outputPattern="{0}/{1}.java" outlet="entities" overWrite="true" /> The stereotype attribute declares the stereotype being mapped, while the sheet attribute points AndroMDA at the Velocity template for code generation. Templates are bundled as part of the cartridge jar file, and along with the deployment descriptor, are all that is required for a valid cartridge. The outlet attribute links the template to the <outlet> custom Ant task specified under the <andromda> task in the Ant build file. This setting informs the Velocity engine of the location of all output generated with the template. The overWrite attribute enables AndroMDA to differentiate between code that is actively generated and code that is modified by the developer. For classes where the developer adds business functionality, setting the overWrite attribute to false ensures modified code will not be overwritten each time AndroMDA is run. Cartridge TemplatesThe final part of a cartridge is the Velocity templates referenced in the deployment descriptor. These templates perform the mapping from the UML model to code. The AndroMDA core makes available information on model elements to the template. This information can then be rendered as required with the VTL. Table 8-2 lists the objects supplied by AndroMDA for use in the Velocity templates.
To appreciate how these objects can be used from within a template, an extract of a template from the andromda-java cartridge is shown in Listing 8-3. Listing 8-3. Cartridge Template Extract from ValueObject.vsl public class ${class.name} implements java.io.Serializable { #foreach ( $att in $class.attributes ) #set ($atttypename = $transform.findFullyQualifiedName($att.type)) private $atttypename ${att.name}; #end ... #foreach ( $att in $class.attributes ) #set ($atttypename = $transform.findFullyQualifiedName($att.type)) #if ( ($atttypename == "boolean") || ($atttypename == "java.lang.Boolean") ) /** #generateDocumentation ($att " ") * */ public $atttypename is${str.upperCaseFirstLetter(${att.name})}() { return this.${att.name}; } #else /** #generateDocumentation ($att " ") * */ public $atttypename get${str.upperCaseFirstLetter(${att.name})}() { return this.${att.name}; } #end public void set${str.upperCaseFirstLetter( ${att.name})}(${atttypename} newValue) { this.${att.name} = newValue; } #end } The template example in Listing 8-3 illustrates the use of AndroMDA scripting objects to define the attributes in a Java class, complete with getter and setter methods. The template illustrates how easily information can be pulled from the model and transformed with a Velocity template. By building your own cartridges or manipulating the cartridges AndroMDA supplies, all manner of transformations are possible from the model. Existing templates can be modified to meet your own coding standards, or you may add a template to the cartridge to generate unit tests for certain model elements. AndroMDA makes it easy to create cartridges that can be tailored to the needs of your project. This extensibility makes AndroMDA a powerful model-driven code generation framework. AndroMDA AppliedThe powerful and versatile code generation features of AndroMDA make it ideal for rapid development. As do most MDA-compliant tools, it has excellent potential for prototyping, since a nearly complete framework for the application can be generated very quickly. Furthermore, requirements changes can be readily reflected in the application by updating the model and regenerating. As is the case with most MDA tools, the downsides of the paradigm also apply to AndroMDA; specifically, difficulties can arise when working with legacy systems. Two questions are often asked concerning AndroMDA: Can the tool perform roundtrip engineering from source to model, and how does AndroMDA guard against overwriting handwritten code? Reverse Engineering the ModelYou cannot reverse-engineer from code back to the model. Although this feature is expected of any high-end modeling tools, the MDA-compliant tools take a different approach to model-driven development than do modeling tools like Together ControlCenter. Reverse engineering is a problem for MDA-compliant tools due to the difficulties inherent in transforming from a PSM to a PIM. To avoid the need to undertake this difficult mapping, MDA tools instead look to protect code modified by the developer, allowing the PIM to be changed and new code generated without overwriting any business logic added by the developer. This brings us to the next question: If we are updating the PIM and regenerating each time, how are the business rules implemented in the code preserved between build cycles? Managing Handwritten CodeNo matter how sophisticated the UML model, all MDA-generated applications of any real complexity will require further modification by a developer. Such modifications are required in order to add the all-important business rules to the application. It is therefore vital the MDA tool treats all handwritten code as sacrosanct and preserves the state of modified code between generation cycles. The methods of safeguarding handwritten code vary between MDA tools. High-end tools such as OptimalJ have the concept of guard blocks, areas of code that the developer must not modify. By using the OptimalJ development environment, the OptimalJ code editor ensures this rule is followed. Any code modified outside of these guarded areas is preserved. Tools like AndroMDA, which do not control the editing of Java source, must resort to other means. AndroMDA generates special implementation classes that are updated with application-specific behavior by the developer. When an AndroMDA build is next initiated, AndroMDA detects the presence of these classes and ensures they are not overwritten. The implementation classes typically extend generated classes. A change to the UML model, which results in a change to the superclass of an implementation class, should be flagged as an error by the compiler. Although this approach leaves the developer with work to do in the event of a domain model change, no handwritten code is lost. AndroMDA 3.0The information in this section applies to version 2.0 of AndroMDA. At the time of writing, Matthias and his team are hard at work on version 3.0. This new version looks to increase the sophistication of the transformation process and introduces several new features:
Developers are invited to look in on the progress of the new version at http://team.andromda.org. This site for version 3.0 looks very professional. If the quality of the site is backed up by the quality of the software, then the next version of AndroMDA will be worth waiting for. Keep your eye on the AndroMDA Web site for all breaking news. |
|
EAN: 2147483647
Pages: 159