6.4 Other Issues for Content Providers
| only for RuBoard - do not distribute or recompile |
6.4 Other Issues for Content Providers
As a content provider, you may have concerns regarding how caches deal with your site content. In particular, many people worry about dynamic responses, advertisements, and accurate access count statistics. While each of these usually result in uncachable content, some methods are worse than others. In this section, I talk about some of the tradeoffs and what you can do to minimize the wait times for users.
6.4.1 What About Dynamic Responses?
Dynamic responses are generally cache-unfriendly . This doesn't mean that dynamic content is bad. It does mean that caches cannot help to improve users' wait times for dynamic pages.
As a webmaster, this is a tradeoff you must carefully consider. How important is the dynamic aspect of your content? Is it worth making people wait for it? Is it worth losing some viewers /customers because the wait is too long? You might say that your customers won't have to wait because you can build a really big server with really fast hardware. However, your big, fast server does nothing to alleviate wide-area network congestion. Neither can it reduce network round-trip delays, nor make someone's dial-up connection faster. You'll have to decide on a balance between dynamic content and cachability .
6.4.2 What About Advertisements?
Advertisements, ad images in particular, are not necessarily at odds with web caching. It really depends on how the system is set up. A number of reasonable approaches are possible. For the following discussion, consider a typical web page with advertisements. Most likely, there are two or more ad images on the page, and the actual ad images change with each request.
One approach is to use fixed URLs in a static HTML page. The URLs for the ad images remain the same but return a different image each time. You can do this with a CGI script that opens a random image file and writes it to the server. For this to work properly, the image response must be uncachable. Otherwise, users of a shared cache will probably see the same advertisement whenever they access that page. Another reason to have the image uncachable is so it can be counted at the origin server. Then the server knows exactly how many times a particular ad image was downloaded. Assuming that only humans download the images, this also corresponds to the number of views of the advertisement. The content provider can then charge the advertiser based on how many people saw the ad. This technique is good in that it gives accurate view counts, but it's bad in that it makes people wait too long for images to download and wastes bandwidth by repeatedly transmitting the same images.
An improvement on the previous approach is to turn the ad image URL into a CGI script that returns an HTTP redirect message. The redirect can point to a static image URL. For example, the embedded URL might be http://www.host.com/cgi-bin/ad. When requested , the server returns an HTTP 302 redirect:
HTTP/1.1 302 Moved Temporarily Location: /ad-images/ad1234.gif
When requested again, the redirect message has a different Location URL for a different ad image. This technique allows the actual images to be cachable because the dynamic aspects are handled by the redirect message, which is uncachable by default. It's better for the redirect message to be uncachable because it is probably about an order of magnitude smaller than the ad image. The origin server still gets an accurate view count because the CGI script is executed for every view. Also note that the HTML file can be static and cachable . Unfortunately, the CGI script and redirect message do add some latency to the overall page display time because the browser must make two HTTP requests for each image.
A third option is to make the HTML page dynamic and uncachable, while leaving the images static and cachable. Each time the HTML page is requested, links and URLs for advertisements are inserted on the fly. This approach is not a huge loss, because only 15% of all web requests are for HTML pages. Once again, this technique allows the origin server to accurately count views.
Note that each of the techniques that give origin servers accurate view counts rely on some aspect of the page to be uncachable. It could be the images themselves , the underlying HTML document, or the redirect messages. The best solution is the one which minimizes both network delays and bytes transferred. In other words, if you have a single small ad image in a large HTML file, it is better for the image to be uncachable.
6.4.3 Getting Accurate Access Counts
What can you do if you want to be cache-friendly but still want accurate access counts? One common approach is to insert a tiny, invisible, uncachable image in the HTML page that you want to count. Every time someone requests the page, even if they got it from a cache, they should also request the image. Since the image is very small and invisible, people should never realize it is there. When you insert the image in the HTML page, be sure to specify the image dimensions so the browser can render the area quickly. For example:
<IMG SRC="/images/counter.gif" WIDTH="1" HEIGHT="1">
Of course, one drawback is that not everyone who views the HTML file also requests the image. Some people (usually those with low-speed connections) disable the browser option to automatically load images. Also, not everyone uses graphical browsers; Lynx users will not get counted.
You might want to use the <OBJECT> tag instead of <IMG> . Both can be used to place images in an HTML document. However, browsers won't display the broken image icon when you use OBJECT and the file can't be loaded. The syntax is:
<OBJECT DATA="/images/counter.png" WIDTH="1" HEIGHT="1" TYPE="image/png">
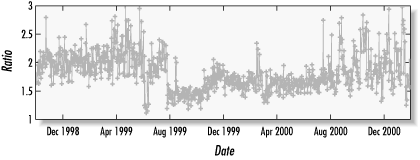
For my own web site, I added both cachable and uncachable (invisible) images to the top-level page. By counting the number of requests for both types, I can approximate the ratio of requests for cachable and uncachable objects. If I want to know how many people actually requested my pages, I simply multiply my server's count by the ratio. For my site, the ratio varies daily from anywhere between 1.5 and 2.5, as shown in Figure 6-1.
Figure 6-1. Ratio of uncachable-to-cachable requests
Finally, I want to mention hit metering. Some members of the IETF's HTTP working group spent a lot of time on a proposed standard for hit metering. This work has been published as RFC2227. Hit metering has two components : limiting and reporting, both of which are optional.
The standard provides mechanisms for limiting how many times a response can be used as a cache hit until it must be revalidated with the origin server. For example, a server can say, "You may give out 20 cache hits for this document, but then you must contact me again after that." Alone, this is a simple scheme; things become complicated, however, with cache hierarchies (see Chapter 7). If the server gives a cache permission for 20 hits, it must share those hits with its neighbor caches. In other words, the first cache must delegate its hits down to lower-level caches in the hierarchy.
Hit metering also provides features for reporting cache hits back to origin servers. The next time the cache requests a metered resource, it uses the Meter header to report how many hits were given out. A cache has a number of reasons to re-request the resource from the origin server, including:
-
It ran out of hits according to limits specified by the origin server.
-
The response has become stale and the cache needs to revalidate it.
-
A client generated a no-cache request, probably by clicking on the Reload button.
If none of those occur before the cache wants to remove the object, the cache is supposed to issue a HEAD request to report the hits to the origin server.
Hit reporting also becomes a little complicated with cache hierarchies. Lower layers of the tree are supposed to report their hits to the upper layers. The upper layers aggregate all the counts before reporting to the origin server.
While hit metering seems promising , the biggest problem at this time seems to be that no one is interested in implementing and using it. A chicken-and-egg situation exists, because neither origin server nor proxy cache developers seem to be willing to implement it unless the other does as well. Perhaps most importantly, though, the folks who operate origin servers are not demanding that their vendors implement hit metering.
| only for RuBoard - do not distribute or recompile |