5.1 Overview
| only for RuBoard - do not distribute or recompile |
5.1 Overview
Figure 5-1. Interception proxying schematic diagram
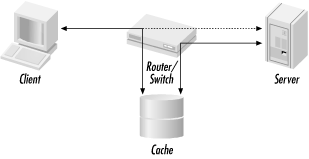
Figure 5-1 shows a logical diagram of a typical interception proxy setup. A client opens a TCP connection to the origin server. As the packet travels from the client towards the server, it passes through a router or a switch. Normally, the TCP/IP packets for the connection are sent to the origin server, as shown by the dashed line. With interception proxying, however, the router/switch diverts the TCP/IP packets to the cache.
Two techniques are used to deliver the packet to the cache. If the router/switch and cache are on the same subnet, the packet is simply sent to the cache's layer two (i.e., Ethernet) address. If the devices are on different subnets, then the original IP packet gets encapsulated inside another packet that is then routed to the cache. Both of these techniques preserve the destination IP address in the original IP packet, which is necessary because the cache pretends to be the origin server.
The interception cache's TCP stack is configured to accept "foreign" packets. In other words, the cache pretends to be the origin server. When the cache sends packets back to the client, the source IP address is that of the origin server. This tricks the client into thinking it's connected to the origin server.
At this point, an interception cache operates much like a standard proxy cache, with one important difference. The client believes it is connected to the origin server rather than a proxy cache, so its HTTP request is a little different. Unfortunately, this difference is enough to cause some interoperability problems. We'll talk more about this in Section 5.6.
You might wonder how the router or switch decides which packets to divert. How does it know that a particular TCP/IP packet is for an HTTP request? Strictly speaking, nothing in a TCP/IP header identifies a packet as HTTP (or as any other application-layer protocol, for that matter). However, convention dictates that HTTP servers usually run on port 80. This is the best indicator of an HTTP request, so when the device encounters a TCP packet with a source or destination port equal to 80, it assumes that the packet is part of an HTTP session. Indeed, probably 99.99% of all traffic on port 80 is HTTP, but there is no guarantee. Some non-HTTP applications are known to use port 80 because they assume firewalls would allow those packets through. Also, a small number of HTTP servers run on other ports (see Table A-9). Some devices may allow you to divert packets for these ports as well.
Note that interception caching works anywhere that HTTP traffic is found: close to clients , close to servers, and anywhere in between. Before interception, clients had to be configured to use caching proxies. This meant that most caches were located close to clients. Now, however, we can put a cache anywhere and divert traffic to it. Clients don't need to be told about the proxy. Interception makes it possible to put a cache, or surrogate, close to origin servers. Interception caches can also be located on backbone networks, although I and others feel this is a bad idea, for reasons I'll explain later in this chapter. Fortunately, it's not very common.
| only for RuBoard - do not distribute or recompile |