Normalization
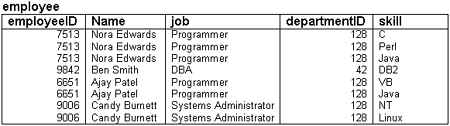
| Normalization is a process we can use to remove design flaws from a database. In normalization, we describe a number of normal forms, which are sets of rules describing what we should and should not do in our table structures. The normalization process consists of breaking tables into smaller tables that form a better design. To follow the normalization process, we take our database design through the different forms in order. Generally, each form subsumes the one below it. For example, for a database schema to be in second normal form, it must also be in first normal form. For a schema to be in third normal form, it must be in second normal form and so on. At each stage, we add more rules that the schema must satisfy . First Normal FormThe first normal form, sometimes called 1NF, states that each attribute or column value must be atomic. That is, each attribute must contain a single value, not a set of values or another database row. Consider the table shown in Figure 3.4. Figure 3.4. This schema design is not in first normal form because it contains sets of values in the skill column. This is an unnormalized version of the employee table we looked at earlier. As you can see, it has one extra column, called skill, which lists the skills of each employee. Each value in this column contains a set of values ”that is, rather than containing an atomic value such as Java , it contains a list of values such as C , Perl , Java . This violates the rules of first normal form. To put this schema in first normal form, we need to turn the values in the skill column into atomic values. There are a couple of ways we can do this. The first, and perhaps most obvious, way is shown in Figure 3.5. Figure 3.5. All values are now atomic. Here we have made one row per skill. This schema is now in first normal form. Obviously, this arrangement is far from ideal because we have a great deal of redundancy ”for each skill-employee combination, we store all the employee details. A better solution, and the right way to put this data into first normal form, is shown in Figure 3.6. Figure 3.6. We solve the same problem the right way by creating a second table. In this example, we have split the skills off to form a separate table that only links employee ids and individual skills. This gets rid of the redundancy problem. You might ask how we would know to arrive at the second solution. There are two answers. One is experience. The second is that if we take the schema in Figure 3.5 and continue with the normalization process, we will end up with the schema in Figure 3.6. The benefit of experience allows us to look ahead and just go straight to this design, but it is perfectly valid to continue with the process. Second Normal FormAfter we have a schema in first normal form, we can move to the higher forms, which are slightly harder to understand. A schema is said to be in second normal form (also called 2NF) if all attributes that are not part of the primary key are fully functionally dependent on the primary key, and the schema is already in first normal form. What does this mean? It means that each non-key attribute must be functionally dependent on all parts of the key. That is, if the primary key is made up of multiple columns , every other attribute in the table must be dependent on the combination of these columns . Let's look at an example to try to make things clearer. Look at Figure 3.5. This is the schema that has one line in the employee table per skill. This table is in first normal form, but it is not in second normal form. Why not? What is the primary key for this table? We know that the primary key must uniquely identify a single row in a table. In this case, the only way we can do this is by using the combination of the employeeID and the skill. With the skills set up in this way, the employeeID is not enough to uniquely identify a row ”for example, the employeeID 7513 identifies three rows. However, the combination of employeeID and skill will identify a single row, so we use these two together as our primary key. This gives us the following schema:
but we also have
In other words, we can determine the name, job, and departmentID from the employeeID alone. This means that these attributes are partially functionally dependent on the primary key, rather than fully functionally dependent on the primary key. That is, you can determine these attributes from a part of the primary key without needing the whole primary key. Hence, this schema is not in second normal form. The next question is, "How can we put it into second normal form?" We need to decompose the table into tables in which all the non-key attributes are fully functionally dependent on the key. It is fairly obvious that we can achieve this by breaking the table into two tables, to wit:
This is the schema that we had back in Figure 3.6. As already discussed, this schema is in first normal form because the values are all atomic. It is also in second normal form because each non-key attribute is now functionally dependent on all parts of the keys. Third Normal FormYou may sometimes hear the saying "Normalization is about the key, the whole key, and nothing but the key." Second normal form tells us that attributes must depend on the whole key. Third normal form tells us that attributes must depend on nothing but the key. Formally , for a schema to be in third normal form (3NF), we must remove all transitive dependencies, and the schema must already be in second normal form. Okay, so what's a transitive dependency? Look back at Figure 3.3. This has the following schema:
This schema contains the following functional dependencies:
The primary key is employeeID, and all the attributes are fully functionally dependent on it ”this is easy to see because there is only one attribute in the primary key! However, we can see that we have
and
Note also that the attribute departmentID is not a key. This relationship means that the functional dependency employeeID To get to third normal form, we need to remove this transitive dependency. As with the previous normal forms, to convert to third normal form we decompose this table into multiple tables. Again, in this case, it is pretty obvious what we should do. We convert the schema to two tables, employee and department, like this:
This brings us back to the schema for employee that we had in Figure 3.2 to begin with. It is in third normal form. Another way of describing third normal form is to say that formally, if a schema is in third normal form, then for every functional dependency in every table, either
or
The second part doesn't come up terribly often! In most cases, all the functional dependencies will be covered by the first rule. Boyce-Codd Normal FormThe final normal form we will consider ” briefly ”is Boyce-Codd normal form, sometimes called BCNF. This is a variation on third normal form. We looked at two rules previously. For a relation to be in BCNF, it must be in third normal form and come under the first of the two rules. That is, all the functional dependencies must have a superkey on the left side. This is most frequently the case without our having to take any extra steps, as in this example. If we have a dependency that breaks this rule, we must again decompose as we did to get into 1NF, 2NF, and 3NF. Higher Normal FormsThere are higher normal forms (fourth, fifth, and so on), but these are more useful for academic pursuits than practical database design. 3NF (or BCNF) is sufficient to avoid the data redundancy problems you will encounter. |


 name, job, departmentID
name, job, departmentID EAN: 2147483647
Pages: 261