| The Network Address Translation (NAT) mechanism deals generally with the translation of IP addresses. It represents an effective way to encounter the exhaustion of free IP addresses (Version 4) in view of the explosive growth of the Internet. However, transition to IP Version 6 with its much larger address space progresses only slowly, because it was found extremely difficult to convert a decentralized network like the global Internet to a new protocol at one shot. Exactly this is where NAT comes in useful: For example, it allows all users in a local area network to access the Internet and its services, even though there is only one single official IP address available, and only private IP addresses (according to RFC 1918 [RMKG + 96]) are used within the local area network. A router accessible to the network, used by the users to connect to the global Internet, handles the required address mapping. The NAT implementation in Linux 2.4 consists of two parts: connection tracking, and the actual NAT. Chapter 20 described how the connection-tracking mechanism is implemented. 21.1.1 Important Terminology One of the most important technical terms in the NAT area is the so-called session flow. A session flow is a set of IP packets, exchanged between two instances and forming a unit in that they are treated equally by a NAT router. Such a session flow is directed to the direction the first packet was sent. For this reason, we speak of original and reverse directions in the following discussion. One good example is a telnet session: The corresponding TCP connection is initiated by the terminal computer, so the original direction of the relevant session flow points from the terminal to the server. TCP/UDP-based session flows can be described uniquely by an {IP source address, source port, IP destination address, destination port} tuple. Similarly, an ICMP session flow can be identified by an {IP source address, IP destination address, ICMP type, ICMP ID} tuple. [SrHo99] describes three characteristic requirements that should be met by all NAT variants: The following sections explain each of these requirements and what they mean. 21.1.2 Transparent Address Allocation Because we can use NAT to connect networks with different address spaces, these addresses from the respective address spaces have to be allocated among them. This allocation can be either static or dynamic. If we use static allocation, the allocations are maintained during the entire operation of a NAT router. Static allocations simplify the address translation, because no state information about specific session flows has to be maintained. In dynamic allocation, the allocation is specified at the time that a session flow is opened. This allocation remains valid until the session is terminated. In some cases, the allocation rule can be extended beyond the IP addresses to include the transport protocol ports. (See Section 21.1.6.) In any event, address allocation should be transparent: The mechanisms should be hidden from the applications in end systems. 21.1.3 Transparent Routing We use the term "transparent routing" in the following discussion to distinguish the routing functionality of a NAT router from the functionality of a normal router. Transparent routing differs from normal routing in that packets are forwarded between two different address spaces by changing the address information in IP packets and routing to match these modified addresses. Transparent routing can be divided into three phases: address binding, address translation, and releasing of the address binding. Address binding: This phase permanently binds two addresses from the two address spaces to be bound. This should not be confused with the address allocation mentioned above the address allocation only determines valid bindings. These bindings will then actually exist only after the address binding. In connections with static address allocation, address binding is also static, but dynamic binding occurs at the beginning of a session flow and is released as soon as this session ends. If we want to map internal network addresses to global, external addresses, then we should bind each additional session flow originating from the same end system to the same address. Address translation: Once an address has been bound, each IP packet of that session flow has to be manipulated. This manipulation can be limited to the IP addresses, but it could also extend to TCP/UDP ports. (See Section 21.1.6.) Notice that the checksum in the IP header, or in the UDP/TCP header, has to be recomputed. Releasing address binding: An address binding has to be released as soon as the last associated session flow ends, if we use dynamic binding, to ensure that the external address can be reused. In contrast, the binding is maintained if we use static binding.
21.1.4 Correct Handling of ICMP Packets ICMP error messages normally require special handling (except for ICMP Redirect messages), because the payload (PDU) of these messages includes the header of the IP packet that caused the error. To achieve total transparency, this inner packet header has to be properly manipulated. 21.1.5 Differences from Masquerading in Linux 2.2 A simple NAT implementation, called "masquerading," had been an integral part of the Linux kernel (Linux 2.0 and 2.2). Later, the NAT functionality was moved to an external module in the course of converting to the netfilter architecture. The NAT support was heavily extended, so that now masquerading represents only a special case of the general address-translation functionality. In contrast to the old masquerading, we now have a way to map more than one public IP address to the internal network. In addition, we can map a public IP address to several internal computers to implement load sharing. The problems of the old masquerading included a close involvement of the packet-filter code, which meant extremely complex rule sets in firewall computers. This problem becomes clear from looking at the different hooks for "IP chains" (see Section 19.2): In the input chain, a packet arriving from the outside appears to be intended for the firewall itself; in the forward chain, the previously unmasked packet is not recognized, because its destination address has changed; and, finally, in the output chain, the packet appears to originate from the firewall itself. In Linux 2.4, the NAT functionality was divided into two main parts: connection tracking, and actual translation. The connection-tracking module manages connections in the transport and application layers; the NAT module actually translates addresses. Both modules can be loaded into the Linux kernel at runtime, to strongly improve maintainability. 21.1.6 NAT Variants We will be using the sample topology shown in Figure 21-1 in the following discussion to better understand the different NAT flavors and their main differences. The local class-C network with two end systems, A and B, uses the private address space 192.168.1.0?92.168.1.255; it connects to the Internet over a NAT router. This NAT router has the internal network address 192.168.1.254 and a reserve of global addresses, which can be mapped to the internal addresses (it could also consist of one single address?99.10.42.1 in this example). A server with the address 100.1.1.1 is the communication partner of end systems A and B in this example. Figure 21-1. Example of a network using NAT. 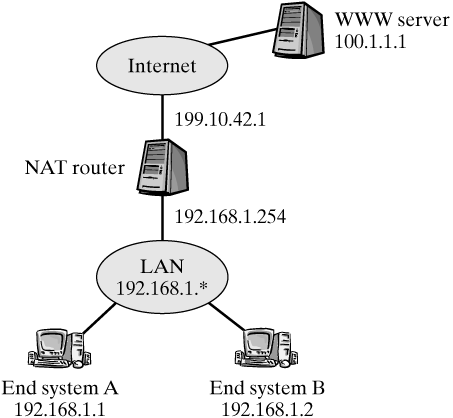
Traditional NAT: Traditional NAT is generally used (1) to connect a local area network using private addresses, as specified in RFC 1918, to an external network and (2) to allow the internal end systems to access the external network transparently. Traditional NAT is unidirectional: An address can be bound in one direction only (normally, when a session flow is established from the internal network towards the external network). In addition, you can translate either the source address (source NAT) or the destination address (destination NAT) of a session flow, but never both addresses at the same time. Basic NAT: This NAT variant is used to map internal IP address to one or several external IP addresses. To understand it better, let's assume that there is a (dynamic) allocation between the end system A (internal address 192.168.1.1) and a global address from the address space reserved for NAT (e.g., 199.10.42.1 in the sample network of Figure 21-1). Let's further assume that a WWW browser in end system A establishes a TCP connection from its port 1200 to port 80 in the WWW server 100.1.1.1. The NAT router binds the internal address 192.168.1.1 to the global address 199.10.42.1 for this session flow. However, this binding is valid for this single session flow only, and a new binding (to the same address) has to be done for each additional, secondary session flow. Network Address and Port Translation (NAPT): This NAT variant represents an extension of Basic NAT. NAPT can translate IP addresses and additionally TCP or UDP port numbers. It is used to map various session flows from different internal end systems to one global IP address. (If only one single global address is available, then this corresponds to the "masquerading" of Linux 2.2.) This means that, in our above example, we could establish a TCP connection from port 1200 of end system B to the same port 80 of the same server by translating port number 1200 (e.g., into 1201) in addition to the IP address. In this case, we would obtain the following bindings: Bidirectional NAT and Twice NAT: These two NAT variants are listed here only for the sake of completeness. In contrast to traditional NAT, bidirectional NAT lets you bind addresses during the establishment of session flows in both directions. Twice NAT removes the limitation of traditional NAT that we can transform either only the destination address or only the source address, but never both.
21.1.7 Problems One general problem in address translation is application-layer protocols, where applications exchange address information. One good example is the File Transfer Protocol (FTP see [Stev94a]). If an FTP client accesses an FTP server, then TCP first establishes a control connection to exchange FTP commands, such as GET or PUT. Now, if it wants to obtain data from the server, the client uses the PORT command to send an IP address and a port number. The client opens this port passively (see Chapter 27) and waits for the data connection, which is established by the server to the address it obtained earlier, to transmit payload. The problems arising in the above case are similar to those known from packet filters. (See Section 19.1.2.) One major problem is that, if there is a NAT router somewhere between the client and the server, this router maps the client's source IP address transparently to another address, whereas the client sends its internal address in the PORT command, and this address is invalid from the server's view. To ensure that the PORT command can operate correctly, the NAT router has to also translate the address transported in the PORT command; it has to be able to intervene in the FTP protocol on the application layer. Another major problem occurs in NAPT and relates to IP packet fragmenting. When IP packets are fragmented, only the first fragment contains the transport-protocol header with the port numbers of the source and the destination; but NAPT relies on this information when mapping addresses, so this means that the other fragments of the same packet cannot be handled properly. Consequently, we have to ensure that fragmented packets are reassembled before an attempt is made to translate addresses. |
 199.10.42.1:1200
199.10.42.1:1200