STRUCTURED PARALLEL PROGRAMMING
Parallel programming exploits multiple computational resources in a coordinated effort to solve large and hard problems. In all but the really trivial cases, the classical problems of algorithm decomposition, load distribution, load balancing, and communication minimization have to be solved. Dealing directly with the degree of complexity given by communication management, concurrent behavior and architecture characteristics lead to programs that are error prone, difficult to debug and understand, and usually need complex performance tuning when ported to different architectures. The restricted approach to parallel programming takes into account these software engineering issues (Skillicorn & Talia, 1998). Restricted languages impose expressive constraints to the parallelism allowed in programs, which has to be defined using a given formalism. Requiring the explicit description of the parallel structure of programs leads to enhanced programmability, to higher semantics clearness, and to easier correctness verification. Compilation tools can take advantage of the explicit structure, resulting in more efficient compilation and automatic optimization of code. Porting sequential applications to parallel can proceed by progressive characterization of independent blocks of operations in the algorithm. They are moved to separate modules or code sections, which become the basic components of a high-level description. Prototype development and refinement is thus much faster than it is with low-level programming languages. The SkIE programming environment (Vanneschi, 1998b) belongs to this line of research. There is, of course, not enough space here to describe in full detail all the characteristics of the programming environment, which builds on a research track about structured parallel programming, so we will only outline its essential aspects and the development path that we are following. SkIE aims at easing parallel software engineering and sequential software reuse by facilitating code integration from several different host languages. The parallel aspects of programs are specified using a skeleton-based high-level language, which is the subject of the next section. The key point is that parallelism is essentially expressed in a declarative way, while the sequential operations are coded using standard sequential languages. This approach preserves useful sequential software tools and eases sequential software conversion and reuse, while keeping all the advantages of a structured parallel approach. Parallel compilation is performed in a two-phase fashion, with global optimizations and performance tuning at the application level performed by the parallel environment, and local optimizations introduced by sequential compilers. The low-level support of parallel computation is based on industry standards like MPI, to ensure the best portability across different architectures.
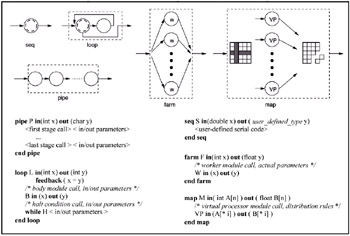
The Skeleton Model in SkIESkIE-CL, the programming language of the SkIE environment, is a coordination language based on parallel skeletons. The parallel skeleton model, originally conceived by Cole (1989), uses a set of compositional building blocks to express the structure of parallel code. Skeleton models have been subsequently exploited in the design of structured parallel programming environment; see for instance the work of Au et al. (1996), or that of Serot, Ginhac, Chapuis and Derutin (2001). A coordination language allows the integration of separately developed software fragments and applications to create bigger ones. In SkIE-CL, this approach is applied to the sequential portion of algorithms, and it is combined with the structured description of parallelism given by skeletons. As shown in Danelutto (2001), skeletons are close to parallel design patterns, as both provide solutions to common problems in term of architectural schemes. Some of the main differences are that skeletons are more rigidly defined and paired with specific implementation solutions (usually called templates), while design patterns are more like recipes of solutions to be detailed. As a result, skeleton programming languages are more declarative in style, while existing languages based on design patterns provide a number of generic classes and objects to be instantiated and completed, thus requiring at least partial knowledge of the underlying software architecture. A program written in SkIE-CL integrates blocks of sequential code written in several conventional languages (C and C++, various Fortran dialects, and Java) to form parallel programs. The skeletons are defined as language constructs that provide the parallel patterns to compose the sequential blocks. The basic parallel patterns are quite simple because skeletons, and SkIE skeletons in particular, can be nested inside each other to build structures of higher complexity. The interfaces between different modules are given by two in and out lists of data structures for each module. These defined interfaces are the only mean of interaction among different modules. Each parallel module specifies the actual data that are passed to the contained modules, and the language support handles all the details of communication, synchronization and concurrency management. This is especially important in the general case, when modules receive a stream of data structures and have to perform their computation over all the data. The general intended semantics of the SkIE skeletons is that the overall computation is performed in a data-flow style, each module beginning its work as soon as its input is available, and starting a new computation as soon as new input data arrives. SkIE skeletons are represented in Figure 1, both as basic parallel communication schemes and as simple code fragments in the SkIE syntax. The in/out interfaces of some of the examples are instantiated to basic type definitions to show how the various skeletons use their parameters. Lists of parameters of C-like, user-defined types are allowed in the general case. The simplest skeleton is the seq, whose purpose is to contain the definition and the interfaces of a fragment of serial code. Almost obviously, the seq is the only skeleton that cannot contain other skeletons. In Figure 1, we identify a seq module with a sequential process communicating with other ones by means of channels. We explicitly note that the graphical representation abstracts from the actual implementation of the skeleton on a particular hardware. Viewing sequential blocks and interfaces as processes and channels is a useful concept to intuitively understand the behavior of the parallel program, but doesn't constrain the program implementation devised by the compiler.
SkIE provides with skeletons that model the two basic classes of parallel computations, namely, task parallel computations and data parallel computations. We talk about task parallelism and streams of tasks when a series of input elements or independent computation results flow from one module to a different one. The data-parallel skeletons rely instead on explicit decomposition and composition rules to split the computation of a large data structure into an organized set of sub-computations, and to compose the results back into a new structure. We call computational grain the size of the tasks we distribute to other processors for parallel computation. A small grain can lead to excessive overhead. In the case of the farm and other stream-parallel skeletons, packing a number of tasks together for communication optimizes the grain, enhancing the computation/communication ratio. The pipe skeleton defines the basic pattern of pipeline functional evaluation over a stream of tasks. Given a set of modules (of arbitrary internal complexity), their pipeline composition evaluates a functional composition f(g(h (inputi))). The f,g,h functions over different elements of the input are evaluated in parallel in an assembly-line fashion. A nested module defines each function. A stage of the pipe sends its results to the next one as soon as it finishes its computation. The general syntax of the pipe construct is shown in Figure 1. This general form obeys the constraint that the output of a stage (the out parameters of the module for that stage of the pipe) is the input of the following stage. The farm skeleton expresses a load-balanced replication of a functional module W, each copy separately performing the same computation over different tasks of the input stream. The type of the in and out parameters of the contained worker module must be the same farm ones. The execution order is assumed to be irrelevant; incoming tasks are accepted as soon as a worker module is free of computation. The implementation of the farm skeleton in SkIE can also exploit other compile and run-time optimizations, like buffered communications and computation grain tuning. The loop skeleton defines cyclic, eventually interleaved dataflow computations. The nested body module repeatedly computes all the tasks that enter the loop. A feedback declaration defines the mapping among the in and out parameters when tasks are sent to the loop entry point. Interleaving of different computation is supported and is dealt with by the language support. Tasks leave the loop as soon as they satisfy the condition evaluated by the sequential module halt. In Figure 1, we show the while-like variant of loop, the do-until and for versions differing only in the way the halt condition is evaluated. The map skeleton performs data parallel computations over multidimensional arrays. SkIE defines a specific syntax (which we don't describe here) to express a set of useful decomposition rules for the input structure, also including several kinds of stencils. The data structure is thus decomposed and distributed to a set of virtual processors (VP) modules, in a way that allows them to compute independently. The output of the VPs is then recomposed to a new structure, which is the output of the map. In the example, we show the syntax for distributing an array of integers one element per VP, and then collecting back an array of the same size. For the sake of conciseness, we skip the formal description of the other data-parallel skeletons (reduce and comp).
Memory HierarchiesAll modern computers employ a memory hierarchy to optimize the average memory access time. Programming models usually hide all the details of memory hierarchy, and intuitive understanding of program complexity relies on a uniform memory access cost. Real experience and theoretical results show that several common computational tasks have very different costs if we take into account external memory references, and very large constant terms suddenly creep in as soon as the data size exceeds the size of a memory level. When data structures do not fit in main memory, the oblivious resort to virtual memory can cause severe latency and bandwidth degradation, especially for random access patterns, because of the huge speed gap among main and mass memory. External memory-aware computation models, algorithms, and data structures have been designed to overcome the problem, appropriately exploiting core memory and the I/O blocking factor to amortize the secondary memory accesses. A deep survey of the topic can be found in Vitter (2001). The issue is clearly relevant for database and DM applications, which manage both input and working data structures of huge size. On the other hand, computational models and algorithms for parallel I/O exploitation have been developed too, in the effort to solve larger and larger problems. All these solutions can be quite complex, having to match the algorithm structure to the constraints of efficient utilization of different levels of memory. In some cases, there is already a data management layer that can integrate these results in a black-box fashion, as it happens with relational DBMS and GIS databases (Freitas & Lavington, 1998). In the general case, new interfaces have been studied also to simplify the implementation of external memory algorithms, and to exploit parallel I/O resources. Both the black-box approach and the generic one can be useful for high-performance DM. Efficient, tight integration with database, data warehouse, and data transport management services highly enhances flexibility and efficiency of the DM tools, because they can easily benefit from any improvements of the underlying software levels. On the other hand, new (parallel) DM applications often need to directly manage huge data structures, and we want to exploit the same advanced techniques with the minimum programming effort.
Skeletons and External ObjectsIn this section, we outline the reasons that led us to the addition of an external objects (EO) abstraction to a high-level parallel language. The skeleton programming approach allows us to express parallel programs in a simple, portable way. Parallel applications need, however, to interface to hardware and software resources, and ideally, we want this part of the program to enjoy the same degree of portability. But usually access to databases, file systems, and other kinds of software services from within sequential code is done differently, depending on the sequential language and the operating system. We explore the option of developing an object-like interface used from within parallel applications to access generalized external services. With external services, we denote a wide range of different resources, and software layers, like shared memory and out-of-core data structures, sequential and parallel file systems, DBMS and data warehouse systems with SQL interface, and CORBA software components. These can be usefully exploited regardless of the configuration details of the parallel program. Support for object-oriented external libraries is already available or easily added to different sequential languages. The parallel language recognizes parallel external objects as fully qualified types. The support of the language can accomplish set-up and management tasks, such as locating or setting up servers and communication channels. The sequential host languages can interact with the object support code as external libraries with a fixed interface, and, of course, object-oriented languages like C++ and Java can develop more complex functionalities by encapsulating the SkIE external objects into user-defined ones. The definition of internally parallel objects is a responsibility that remains in the hands of the language developer. It is a complex task, and it is subject to the constraints that the implementation is portable and does not conflict with the parallel language support. More complex objects with an explicitly parallel behavior can be defined in terms of the basic ones, to ease parallel programming design. A first experiment in adding external objects to the pre-existing SkIE language has looked at distributed data structures in virtually shared memory (Carletti & Coppola, 2002). The results were evaluated with the application to the parallel C4.5 classifier described in this chapter. The long-term goal of the design is to develop objects that manage huge distributed data structures by exploiting available shared memory or parallel file systems, and using the best in-core and out-of-core methods according to problem size and memory space. The management algorithms for this kind of task can become quite involved, having to deal with multiple levels of external memories and problems of caching, prefetching, and concurrent semantics. It is, of course, a complex and not yet portable design; however, expressing parallel DM algorithms in such a level of detail makes them complex and nonportable as well, and the effort made is not easily reused. On the other hand, we want to exploit this way the well-established standards we already mentioned, like CORBA components and SQL databases, in order to enhance the integration of the high-performance core of DM application with existing software and data support layers. As portability is needed with respect to both the hardware architecture and the software layer that manages the data, we can profitably use object-oriented interfaces to hide the complexity of data retrieval.
| |||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||

EAN: 2147483647
Pages: 194
- Static PE-CE Routing Command Reference
- Configuring L2TPv3 Tunnels for Layer 2 VPN
- Virtual Private LAN Service (VPLS)
- Case Study 2: Implementing Multi-VRF CE, VRF Selection Using Source IP Address, VRF Selection Using Policy-Based Routing, NAT and HSRP Support in MPLS VPN, and Multicast VPN Support over Multi-VRF CE
- Case Study 4: Implementing Layer 3 VPNs over Layer 2 VPN Topologies and Providing L2 VPN Redundancy