Chapter 4: LDAP: Some Practical Details
|
| < Day Day Up > |
|
Combining the knowledge gained from Chapters 2 and 3, we now have a fairly complete grasp of LDAP basics. Chapter 2 treated LDAP from the protocol point of view. Chapter 3 showed the four models that provide the basis of LDAP. We learned that the LDAP database contains a large number of objects stored in the form of entries. Each object is constructed of attributes. Each attribute has a name and one or more values. The objects are organized in the database in a hierarchical structure that builds a tree, much like a directory on a file system. LDAP offers a number of functions to facilitate access to these objects. There are also control structures to mediate who can access and manipulate the data.
In this chapter, we take a more practical approach. We revisit the search function and explain how to construct filters with the help of some examples. We then have a brief look at the directory schema and provide some practical examples. We also learn how the theoretical objectIDs and matching rules fit into the definitions that are in the configuration files. We learn more about the LDIF format and understand its importance for importing a directory. Finally, as promised in Chapter 2, we will have a closer look at LDAP URLs, further examine the differences between LDAPv2 and LDAPv3, and conclude with a short discussion of what is going on with the development of LDAP. I will also describe the workgroups active at the time of this writing.
Search Revisited
In the preceding chapters, we have seen the search function in action a number of times. Before initiating a search, you specify several parameters. Let us take a look at an example. Look at Exhibit 1. We want to know name of the users working in Europe. First, we define the search base, i.e., the location in the tree from which the search should begin.
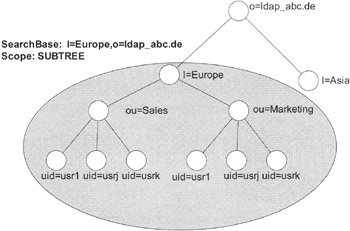
Exhibit 1: Example of Search, Scope Set to SUBTREE
BaseDN: l=Europe, ou=ldap_abc.de
Next, we have to specify how deeply we wish to search. This specifies the scope parameter, as explained in Chapter 3. The three possibilities are:
-
subtree: Searches the whole subtree, including the search base, as shown in Exhibit 1
-
onelevel: Searches one level below the search base, thus excluding the search base from the search scope
-
base: Limits the search to the search base
In Exhibit 1, it is clear that "subtree" means the whole subtree, beginning at the search base. Exhibit 2 shows the "onelevel" search scope. Note that the search base itself is excluded from the search. You can verify this by searching with the filter:
objectclass=*
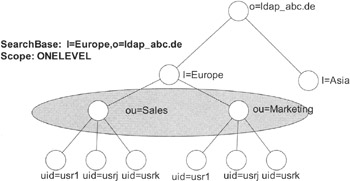
Exhibit 2: Example of Search, Scope Set to ONELEVEL
Note that the exact name of the constant used for the scope depends on the API you are using. In the C API, the constants are called:
-
LDAP_SCOPE_SUBTREE
-
LDAP_SCOPE_ONELEVEL
-
LDAP_SCOPE_BASE
To complete the picture, see Exhibit 3, which shows an example of "search" with the scope set to "base," i.e., the search is executed only in the immediate search base.
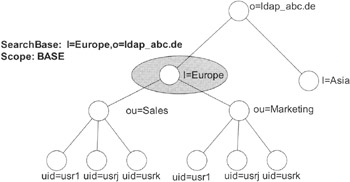
Exhibit 3: Example of Search, Scope Set to BASE
The most important thing in the search is the filter. The filter defines what you want to know, perhaps which objects belong to a certain objectclass, the list of persons with surnames beginning with "A," and so on.
Query Filters
Now, finally, we will have a closer look at how to construct a query filter. If you would like more information about filters, you can look at RFC 2254, "The String Representation of LDAP Search Filters." This RFC supersedes RFC 1960, "A String Representation of LDAP Search Filters" describing LDAP (v2) filters. The difference between the two RFCs is that LDAP (v3) adds the extended match filter. In LDAP (v2) you could not search in the distinguished name. The extensible match makes this possible and allows the user to define different behaviors in comparisons. We will discuss this aspect in greater detail later.
Exhibit 4 lists the filter definitions that can be used in an LDAP search. The following sections give a brief example of each filter listed in Exhibit 4.
| Name | Operator |
|---|---|
| equalityMatch | = |
| substring | = |
| greaterOrEqual | >= |
| lessOrEqual | <= |
| present | =* |
| approxMatch | =~ |
| Boolean Operators: | |
| and | & |
| or | | |
| not | ! |
| LDAP (v3) | |
| extensibleMatch: | |
| NAME? | "attr [":dn"] [":" matchingrule] ": = " value |
| NAME? | [":dn"] ":" matchingrule ": = " value |
Exhibit 4: LDAP Search Filters
equalityMatch
This is the simplest form of the filter. It tests for exact equality between the string searched and the attribute value.
(sn=Parker) (mail=Mparker@ldap_abc.com)
Substring
Evaluates to "true" if the attribute value contains the query string:
-
(sn = Pa*): Matches every sn beginning with "Pa," e.g., Parker, Paul
-
(sn = *man): Matches every sn ending with "man," e.g., Woodman, Goldman
-
(sn = s*n): Matches every sn beginning with "s" and ending with "n," e.g., Simon
-
(sn = *str*): Matches every sn containing "str," e.g., Astrid
greaterOrEqual, lessOrEqual
The greaterOrEqual filter matches every attribute value that is greater than or equal to the query string, and the lessOrEqual filter matches every attribute value that is less than or equal to the query string. The ordering depends on the syntax of the attribute you are comparing. For example, integer attributes are ordered numerically. ASCII values are ordered lexicographically. Attributes with caseIgnoreString syntax and attributes with caseSensitiveSyntax are ordered in a different way. Attributes that cannot be ordered, such as binary data, cannot be searched with this operator.
Present
This is a simple filter type, testing only for the presence of the requested attribute. For example,
fax=*
reports entries that have a value for the attribute "fax."
approxMatch
The approxMatch filter is a question of implementation. It returns true if the attribute values "sounds like" the search string. This is clearly dependent on the language used. For example,
(sn=~ Parker)
returns true if the attribute value of sn "sounds like" Parker, the meaning of which depends on the particular implementation.
Boolean Operators: And, Or, Not
Finally, we have the Boolean operators. These operators are used in combination with all of the operators described in this section so far. The notation, however, is somewhat cumbersome and not recommended for the end user. The syntax used is called "prefix notation." Those who recall the postfix notation of the first pocket calculators (namely Hewlett-Packard) will remember it. With prefix notation, the operator precedes the operands.
Examples
The following examples illustrate the use of the Boolean operators alone and in combination:
-
(! (sn = A*)): Matches every entry with an sn that does not begin with A
-
(& (sn = A*) (1 = NewYork)): Matches every entry with an sn beginning with A and living in New York
-
(| (1 = New York) (1 = Washington)): Matches every entry with location New York or location Washington
-
(& (1 = California) (! (1 = San Francisco))): Matches every entry with location California, excluding San Francisco
Using these Boolean operators, it is possible to build whatever logical construction you want.
extensibleMatch
Do you remember that it was not possible to search in the distinguished name in LDAP (v2)? Now, in LDAP (v3) with this search filter you can. You express your wish to search in the distinguished name in this way:
(l:dn :=San Francisco)
With this command, the search would include all entries containing the distinct name "San Francisco" in the location field.
However, this filter can do much more. The user can also specify which matching rule the query should use. For example, suppose you wanted to use the caseExactString match to look up a common name. The common name (cn) normally uses caseIgnoreString, so Carter and carter and CARTER are all the same thing. You could specify
(sn:caseExactString:=Carter)
to distinguish "Carter" from the other possibilities.
In Backus Naur form (BNF) (see Chapter 3, Exhibit 4), the syntax definition for the extensible match statement would be as follows::
attr [":dn"] [":" matchingrule] ":=" value | [":dn"] ":" matching- rule ":=" value
with the following:
-
attr: Attribute name
-
matchingRule: Matching rule to be applied. In this case, the object identifier (OID) is used. See "Information Model" in Chapter 3 for details. You could use the human-readable aliases as well, for example "caseExactString." You will find the values appropriate for your server in its configuration files.
-
value: Value to be used for the query
The square brackets indicate that the enclosed expression is optional. The logical operator "|" means OR. If you omit the attribute name, you have to express the matching rule your query will use.
To finish this section, let us review several examples copied from RFC 2254, "The String Representation of LDAP Search Filters":
-
(sn:dn:2.4.6.8.10: = Barney Rubble): Illustrates the use of the ":dn" notation to indicate that (1) matching rule "2.4.6.8.10" should be used when making comparisons and (2) the attributes of an entry's distinguished name should be considered part of the entry when evaluating the match.
-
(o:dn: = Ace Industry): Denotes an equality match, except that DN components should be considered part of the entry when doing the match.
-
(:dn:2.4.6.8.10: = Dino): A filter that should be applied to any attribute supporting the given matching rule (because the attribute has been left off). Attributes supporting the matching rule contained in the DN should also be considered in the search.
The filter mechanism itself uses a handful of characters for its own purpose. The "*" character is used in substring matches; left and right parentheses are used for grouping; the backslash character is used for "escaping" characters; and the NULL string is reserved. If you need to use these characters as part of the search value, they have to be "escaped" using their hexadecimal values. Exhibit 5 lists the values and shows the associated escape sequences.
| Character | ASCII Value | Escape Sequence |
|---|---|---|
| * | 0 × 2a | \2A |
| ( | 0 × 28 | \28 |
| ) | 0 × 29 | \29 |
| \ | 0 × 5c | \5C |
| NUL | 0 × 00 | \00 |
Exhibit 5: Characters with Their ASCII Values and Escape Sequences
The following are other useful examples from RFC 2254:
-
First we try to use opening (\28) and closing parentheses in the "cn" attribute. The phrase "Parens R Us (for all your parenthetical needs)" would result in:
(o=Parens R Us \28for all your parenthetical needs\29)
-
Next, we try to use the star character in cn, preventing it from being interpreted as a wild card. cn = * would result in:
(cn=*\2A*)
-
The backslash used in a Win32 filename is encoded as \5c, therefore filename = C:\MyFile would be written as:
(filename=C:\5cMyFile)
-
Now we want to write a four-byte word bin = hex value 0004 as follows:
(bin=\00\00\00\04)
-
The last example shows how to assign to "sn" a numer of non-ASCII characters, such as:
(sn=Lu\c4\8di\c4\87)
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 149
- Challenging the Unpredictable: Changeable Order Management Systems
- Enterprise Application Integration: New Solutions for a Solved Problem or a Challenging Research Field?
- Context Management of ERP Processes in Virtual Communities
- Distributed Data Warehouse for Geo-spatial Services
- Healthcare Information: From Administrative to Practice Databases