Executing Action Commands
| ADO.NET (as I'll discuss in depth in Chapter 8, "Getting Started with ADO.NET," and beyond) uses an entirely different approach to handling changes to the database. In earlier data access interfaces like DAO, RDO, and ADOc, the action commands were automatically generated based on the SELECT statement used to fetch the rowset. Microsoft found this to be too inflexible to deal with the myriad data sources and ways to return rows. In contrast, ADO.NET leaves creation of the action commands up to you. That is, when it comes time to make changes to the database, your application (or one of the tools like SQL Server Management Studio, SQL Express Manager, or the Server Explorer in Visual Studio) needs to construct one of three types of T-SQL statements:
The first two of these T-SQL statements use a specific syntax that specifies the database table and the columns to add or change. The syntax in the UPDATE and DELETE statements should use a WHERE clause that tells SQL Server how to locate the row(s) to change or remove (without that WHERE clause, all rows would be changed or removed). Yes, there are a variety of ways to construct action commands, and the Visual Studio wizards (like the DataAdapter Configuration wizard [DACW]) or CommandBuilder can do it for you. You need to understand the mechanics of these action commands to understand the code being generated and to know how to modify it to better address your situation. That's because the code generated by the CommandBuilder and the DACW (which uses the CommandBuilder) is, shall I say, "challenged." While I might use the Visual Studiogenerated code for simple operations, it breaks down once the SELECT query gets too complex. I discuss these issues in depth in Chapter 6, "Building Data Sources, DataSets and TableAdapters." Let's take a quick look at each of these T-SQL action commands to see what they do and how you can control their behavior. Inserting New RowsThe T-SQL INSERT statement is used to add one or more rows to an existing table. However, before you run off and start writing routines that generate INSERT statements en masse, make sure you check out SQL Server's ability to import data for you. These "bulk" techniques are dramatically faster than any INSERT scheme you can create. Even if the data has to be munged before it's committed to production tables, it's still faster to upload it to a SQL Server work table (or a #Temp table) and run server-side code to move it to your "real" tables. In the process of executing the INSERT statement to add the new row, SQL Server performs the following tasks:
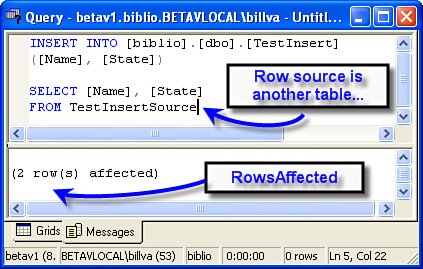
Sure, it's possible to code an INSERT statement to add several rows at a time. For example, to "import" rows from another table, you could build an INSERT statement, as shown in Figure 2.74. Figure 2.74. Adding rows to a table from another table. In this example, the target table (TestInsert) is defined to include an IDENTITY column. This means I don't (shouldn't) have to specify the IDENTITY column value in the INSERT statement. Handling NULL and DEFAULT ValuesWhen you need to add a new row but the value for a specific column is unknown (as in "DateOfDeath" or "FinalVoteCount"), you should provide NULL as the value to be inserted into a specific column. In order for this to work, you must define the table to accept NULL for the column or don't include the column in the column list in the INSERT statement. You can define default values in T-SQL, and these can be assigned to specific table columns. The rule is, if a default is defined for a column and no value is passed in the INSERT statement, the default value is used. If you pass a NULL as the column value in the INSERT, NULL is usednot the defined default.
Don't use the INSERT command to move data from one data source to anotherat least limit the number of rows added to a few dozen rows. ADO.NET provides a bulk copy interface (BCP) to do this more efficiently. If the INSERT statement succeeds, SQL Server returns the number of rows affected. In the example in Figure 2.74, two rows were added to the TestInsert table. This value is passed back to ADO.NET, and if you set up an argument to capture it, you can inspect this value. This can be very handy when you want to know if the INSERT did what you asked/expected it to do. ADO.NET also expects this behavior. When I discuss the DataAdapter Update method in Chapter 12, "Managing Updates," I'll show that ADO.NET uses the rows affected value to determine if the INSERT, UPDATE, or DELETE operation succeeded. In this case, ADO.NET always expects a rows affected value of 1.
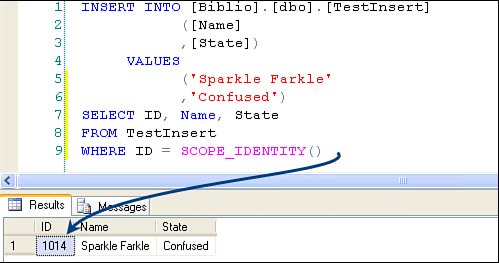
The rows affected value is returned to ADO.NET after each action statement in the batch. Capturing the New Identity ValueMany of the tables I work with use Identity values or GUIDs as the primary key. When I add a new row, it's important to know the new SQL Servergenerated value, so I can manage parent/child relationships in the client. Retrieving the new value can be done in a variety of ways:
The Visual Studio 2003 DataAdapter Configuration Wizard generates an INSERT statement that can include an additional SELECT statement directly after the INSERT that uses the @@IDENTITY global variable. After I suggested that Microsoft change this to SCOPE_IDENTITY(), they did so. Visual Studio 2005 now does it right. When I get to Chapter 12, I'll show you how to create client-side Identity values to manage parent/child relationships before and after ADO.NET executes the DataAdapter Update method. Inserting Data with SELECT INTOI've found that it's often handy to insert data into a table using SELECT INTO syntax. Suppose you need a temporary table that contains information you expect to use in subsequent queries. If you use SELECT INTO, you can create a permanent or temporary (#Temp) table on-the-fly. This could not be much easier. Write normal T-SQL SELECT, but add the INTO <tablename> before the FROM clause, as shown in Figure 2.78. Figure 2.78. Using SELECT INTO to populate a #Temp table.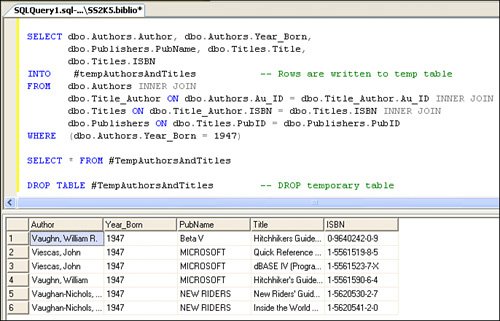 If you prefix the target table name with "#", the new table is created in TempDB. Yes, you'll have to drop this table yourself once you're done with it because #Temp tables live for the life of the connection and are not visible to other connectionsnot even other connections your application opens. Figure 2.79. Using SELECT INTO to insert new rows into a temporary table.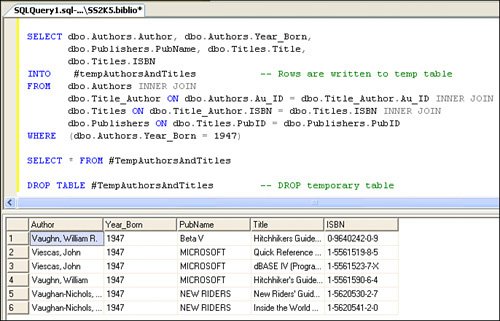 Using Temporary (#Temp) Tables#Temp tables can be very handy when trying to persist a set of rows like a notepad. These tables are stored automatically on a connection-by-connection basis in TempDB. When the connection is dropped, any residual tables are dropped. TempDB is re-created each time the system boots (it's copied from the model database), so there can never be anything left over from a previous existence. A few points to remember:
Figure 2.80. Changing the initial size of TempDB.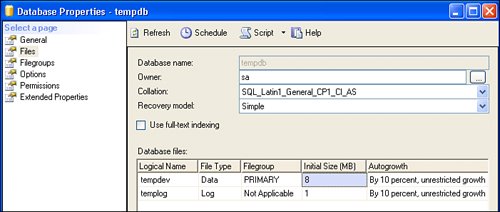 You can use #Temp tables like any other table. This means you can include a #Temp table in a JOIN to improve query performance in situations where a connected application makes a number of similar queries. Updating RowsYes, I expect that at some time or another, you're going to want to add, change, or delete the data in your databaseunless it's on CD. This section walks you through the process of making those changes using T-SQL. Sure, the Visual Studio wizards will help build UPDATE, INSERT, and DELETE statements for you, but as I discuss in Chapter 12, you'll quickly outgrow the approach they use. Changing SQL Server data is not that hard to do if you remember three basic tips:
When it comes time to change your database, most of the work involves finding the row that needs changing, setting the new column values, and dealing with concurrency issues. If your UPDATE statement does not have a WHERE clause that identifies a single row, more than one row can (and probably will) be changed. As you'll see in Chapter 12, ADO.NET expects you to write UPDATE commands that address rows individually, so updates are done one row at a time. Visual Studio and ADO.NET can generate appropriate T-SQL UPDATE statements for youalthough as your application grows in sophistication, you probably won't want them to do so. The other major aspect of updating involves concurrency, which I discuss next, and how ADO.NET handles concurrency, which I discuss in Chapter 12. Your T-SQL UPDATE should not attempt to update the row's primary key. If you think about it, when you change the primary key (the value[s] that define the "uniqueness" of a row), you're really dropping an existing row and replacing it with another. If you keep this in mind, your code can be a lot simpler and ADO.NET won't be as petulant. The T-SQL UPDATE statement is used to change one or more rows to an existing table. In the process of changing the row, SQL Server performs the following tasks for each row addressed by the WHERE clause:
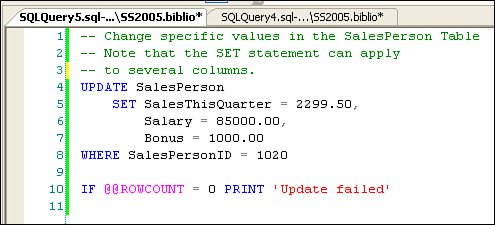
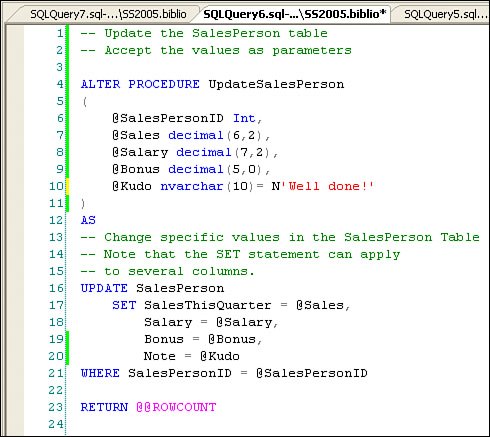
Understanding the TSQL UPDATE SET ClauseThe UPDATE statement's SET clause contains a set of values to replace values in the specified columns. The values can also contain an expression based on the current contents of the row, as when the new value is to be computed relative to the existing value"CurrentSales + 2.50". The example shown in Figure 2.81 illustrates using an UPDATE statement to set the SalesPerson table's Bonus column for all salespeople whose sales are within 10% of the top sales amount. Sure, this UPDATE T-SQL operation could have been written in a number of different ways, so it's a great idea to click on the "Include Client Statistics" in SQL Server Management Studio as you build the T-SQL to see which is most efficient, given the table indexes. Figure 2.81. Using the UPDATE statement to change a specific column in many rows.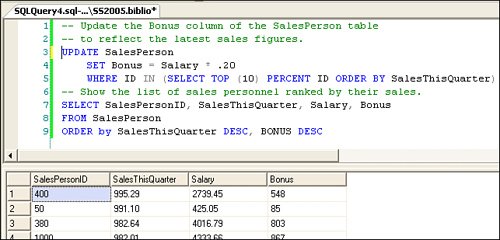 Note that the SET statement is used (in this case) to apply a value to a specific column. It's not unusual to use SET against several columns in a single UPDATE operation, as when your code is updating a row with more current information. Of course, executing any UPDATE statement assumes that the current User associated with the connection has rights to make changes to the specific table and columns being changed. Imagine (if you will) a SalesPerson table that contains data your User has rights to see but not change. For example, while the User might be able to execute a SELECT against the SalesPerson table, the account might not have rights to alter any but the Bonus columnand then only because specific update rights have been granted to that User account. Assuming your User has sufficient rights, a more typical UPDATE statement might reference several columns in a single operation, as shown in Figure 2.82. Figure 2.82. Using the UPDATE SET operator to change the values of several columns. But no, this approach doesn't make much sense, as it requires you to recode the T-SQL for each change you want to make. In most cases, you'll want to create a parameter-based query to accept the values to SET, as well as the criteria to choose the row(s) to UPDATEit's rarely a good idea to hard-code assigned values in an UPDATE statement. Parameter-Based UpdatesParameter-based UPDATES are designed to permit your code to pass in values to be used with the SET statement. These can be implemented in your code by:
All of these approaches are discussed in the context of Visual Studio and ADO.NET in Chapter 6 and again in Chapter 8, as they involve using ADO.NET or Visual Studio to generate the code. Let's take a look at a simple stored procedure that inserts the parameter values into the UPDATE statement at runtime (see Figure 2.83). Figure 2.83. A stored procedure used to perform an UPDATE using parameters. To test this procedure, I need to build a "test harness". A test harness is simply a program used to exercise the procedure. It can be written with Visual Studio and a SQL script, and executed with SQLCor, as in this case, I use SQL Server Management Studio. This T-SQL script (shown in Figure 2.84) sets up a local variable to capture the stored procedure RETURN value. Figure 2.84. Testing the update stored procedure.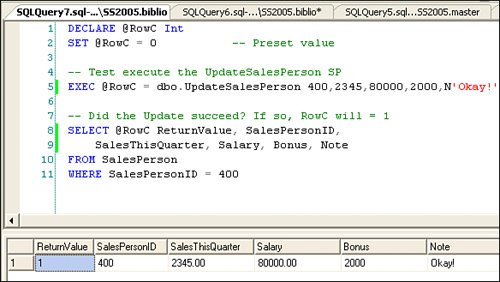 Since we're working with Visual Studio, we can also test this (or any) stored procedure using the Server Explorer. Sure, you can also use Visual Studio to create, edit, and step through the stored procedures. Later in this chapter, I'll show you howsee "Introducing Stored Procedures." Strongly Typed Data ColumnsWhen you assign a value to a table column, SQL Server makes sure that the data is correctly "typed." That is, the source data (the information you're trying to apply to the column) is the right size and "shape." For example, if you define a column as tinyint, acceptable values are numbers[25] between 0 and 255. If you provide a value higher (or lower) than the datatype permits, SQL Server will throw an exception. Each datatype has its own constraints, be it a range of values (including the ability to hold negative numbers), precision and scale, or length. Datatypes also determine how the data is stored, as in Boolean, binary, text, string, floating point, or Unicode/ANSI designations.
If you take a closer look at the example shown in Figure 2.85 and change the second stored procedure parameter to "234567", the code throws a runtime exception because the column (and parameter) are defined as decimal(6,2). In this case, the datatype is set to permit decimal values no longer than six digitstwo of which are after the decimal point. This means a value of 1234.56 is acceptable, but 12345.67 is not. Figure 2.85. Type-checking data.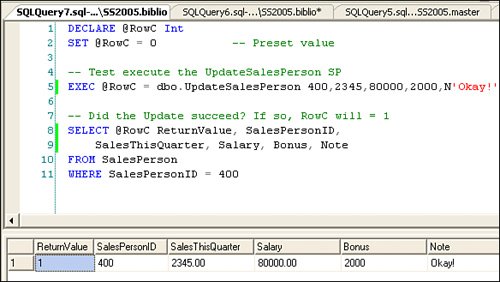 Datatypes and data validity constraints raise an interesting issue: Should your T-SQL code provide datatype filtering to prevent exceptions, should filtering be done by your own code as the data is captured, or should you code server-side Rules and Constraints to ensure that inbound data is correctly formatted? In any case, your application or server-side code needs to deal with this issue one way or anothereither by filtering inbound data at the source or on the server, or by writing exception handlers to clean up the mess caused by a data exception. I like to code our front-end applications to ensure that data values are captured correctly as the data is entered. This ensures that corrupted data does not enter the system in the first place. Generally, the person entering the data is the "source," so they should know the correct value. It's up to your application to make sure they know how to pass that value to your program. If they're entering the data incorrectly, it's as much your fault as it is theirs. Your program should make the acceptable values and constraints of the data being entered perfectly clear. IMHO If users are entering data incorrectly, it's as much your fault as it is theirs. ADO.NET, the .NET Framework, the languages, and Visual Studio all have mechanisms to help you make sure data values meet the datatype criteria. The mechanism they use is called "strongly typed" data. When you build strongly typed DataSets, DataTables, and other ADO.NET data structures, additional code is added to your project to ensure that only correctly formatted data is captured. This code is added automatically to your project in the form of classes that define each data column in great detail. While it's not necessary to use strongly typed data classes, some developers think that they can help code execution performance (they do) and type safety (they do). Type safety simply means that the generated code that manages your data does not permit invalid data to be moved into your ADO.NET DataRow. Dealing with StringsWhen working with strings, your code needs to deal with several other factors:
Dealing with Decimal and Floating Point NumbersWhen you need to store numerical money or scientific data in the database, you must choose an appropriate datatype to floating the values on either side of the decimal point. The column datatype specifies how much and the precision of the data to be stored so your code will have to deal with inbound data to ensure it meets these criteria. If you have to store money values, keep in mind that some currencies have very low exchange rates. This means that if you have to store a money value in Venezuelan bolivars or Japanese yen, your money type might have to be capable of handling much larger values when compared to euros or U.S. dollars. For example, $10,000 can be exchanged for about 21,446,000 bolivars. This means in order to save this value, your column needs at least three more digits of scale. However, when you consider that you might be asked to store a value of 2.50 bolivars, your column will need to be able to store $ 0.001165 or round off to the penny. Dealing with BLOBsBinary large objects (BLOBs) are simply data that won't (until now) fit in a conventional varbinary or varchar column, like pictures of your Aunt Tillie on her Harley or those contracts you save with your customer data. In SQL Server 2000, if you had a picture or text string that was longer than about 8,000 bytes, you had to store it in a TEXT or IMAGE datatype. In this case, ADO and ADO.NET had to perform a number of tricks to get the data in and out of the database. In SQL Server 2005, BLOB data can now be stored in "ordinary" varchar, nvarchar, varbinary, and XML columns, and ADO.NET does not have to perform as much magic behind the scenes. In SQL Server 2005, Microsoft has made a number of changes to help manage "large" and super-large data elements easier. First, they added varchar(max) and nvarchar(max), which accept variable-length character and Unicode values as large as 2GB (which means about two billion ANSI characters and about a billion Unicode characters). This means you might not need to use the TEXT datatype at all to store long text strings (like entire documents). But if you choose to store BLOBs in the database, that's just the beginning of your problems. To start with, getting a BLOB saved or retrieved from the database is far slowerup to six times slower than reading or writing a file containing the same information. Sure, SQL Server 2005 handles BLOBs faster than ever, but it's still slower than simply saving the data to a file and recording the path to the file in the database. When you save a BLOB to the database and you don't plan ahead, you'll end up backing up the BLOB data along with all of the other data, thus slowing down the backup/restore process. Sure, you can save BLOBs to tables on different database segments and back these up separately, but that's a bit tough for those shops without an experienced DBA. The question is, why back up the BLOBs at all if they are static pictures or documents? Yes, if the data is constantly changing, it's a great idea to keep backups and archives. However, if the data is RO, there is no reason at all to keep more than a single backup. Once you fetch a BLOB into your application, it's addressed via a DataRow column. Can you point Microsoft Word or PowerPoint or a picture editor at this column? Hardly. Generally, you'll find it's a lot easier (and faster) to save the BLOB to a file and point the external application at this file. The application (like Word) can save the file (to disk) using the normal Save clicks, and your application can persist this file to the database. But again I ask, why? Why not simply store the file path in the database and keep the files on normal disk directories? RO files can also be shipped with the application on RO media like CDs or DVDs. Designing in ConcurrencyThe next big challenge you'll have to think about as you add, change, and delete rows is concurrency. That is, what has happened to the data since your application last read it? Concurrency is a complex subject, and Microsoft spends quite a bit of time discussing it in its documentation and training materials.
If traffic engineers thought about highway intersections the way that programmers think about data collisions, they would spend all of their time worrying about where to place the ambulances instead of how to time the traffic lights and design the intersections to avoid collisions in the first place. In a single-user application, you'll have very little need to add code to deal with concurrency. However, if you even suspect that your application will have to scale to support two or more users accessing the same data, you'll need to add code to deal with concurrency contingencies:
As you update your data, Visual Studio can help manage the low-level operations to detect if a collision has occurred. In addition, changes in Visual Studio 2005 make it easier to autogenerate appropriate code for many of the techniques I use to detect collisions. Let's discuss techniques you can use to address some of the issues I just brought up. How Can Your Code Determine Whether the Row Is There to Update?Your T-SQL UPDATE statement's WHERE clause should specifically address the row(s) to change. This is usually implemented by referring to a specific primary key value directly, as shown in Figure 2.82, or via parameter, as shown in Figure 2.83. Sure, your WHERE clause can refer to several columns, if that helps further narrow the focus of the UPDATE. If this WHERE clause returns no rows, that's a pretty good indication that the row is not present to update. No, it does not help to execute a SELECT before executing the UPDATE to determine whether the row is presentunless these are bound into a single atomic transaction. That's because by the time your code returns to post the UPDATE, the row might have been deleted. In the past, I had to add code to check for duplicates before adding new rows. That's no longer needed with SQL Server as if you define a unique primary key for the table. This is done (as I've said before) by selecting one or more columns that, when taken together, provide a unique way to identify the row. If a unique PK is defined, as you add a new row, SQL Server won't permit you to add a row with the same PK values. This means your table can never contain duplicatesunless you do something really dumb. If the row you're trying to change is not found, you have to ask yourself why. What happened to it? As often as not, your own application deleted it in another operation. If not that, then the next most likely reason is that the row was deleted by another user or by the DBA performing maintenance. In any case, you need to decide on a fall-back planwhat to do when the row to be updated is not found at all. One approach is to change the UPDATE into an INSERT, but this might be dangerous. You really need to know why the row was removed. How to Tell Whether the Row Has Changed Since It Was Last Read?Once your UPDATE statement's WHERE clause has picked the row to change, you need to determine whether the row has changed since it was last read. The easiest way is to use the row's rowversion column valueassuming your row has a rowversion column. A rowversion (or timestamp[26]) column is simply a SQL Servermanaged counter that's automatically incremented as rows are added or changed. When you initially fetch the row, your SELECT should return the current rowversion column value. This way, when it's time to execute the UPDATE, you can compare the server-side rowversion value with the value initially fetched. This test is fast and relatively foolproofit also does not require you to compare other column values against server-side data values that might not have any bearing on your operation. Figure 2.86 illustrates how to set up an UPDATE statement and test harness to use the Timestamp column value to determine whether a concurrency collision has occurred.
Figure 2.86. Testing for a concurrency collision using the TimeStamp (rowversion) column value.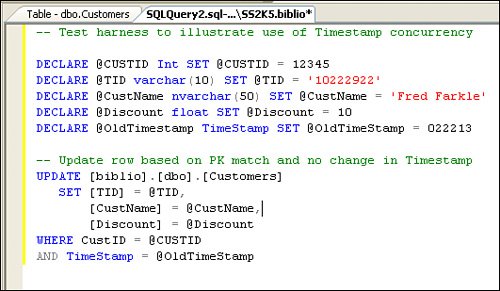 Okay, suppose you permit other users to change the data row while your application is making changes. If you can't use the rowversion or timestamp column, you might need to test for changes in specific columns to determine whether a concurrency collision has occurred. In this case, you'll need to compare pertinent columns against the server-side data. |
EAN: 2147483647
Pages: 227
- Getting Faster to Get Better Why You Need Both Lean and Six Sigma
- Success Story #1 Lockheed Martin Creating a New Legacy
- Seeing Services Through Your Customers Eyes-Becoming a customer-centered organization
- The Value in Conquering Complexity
- Success Story #4 Stanford Hospital and Clinics At the forefront of the quality revolution