6.5 Parallel query architecture
|
| < Day Day Up > |
|
When a query is executed in parallel, the process that executed the parallel query is called the query coordinator (QC). The QC is a server shadow process of the session running the parallel query. The main function of the QC is to parse the query and partition the work between the slaves. During the parse operation both serial and parallel plans are prepared based on the degree of parallelism defined. The QC then attempts to obtain the number of parallel slaves it wants to run the query. During these attempts, if it is unable to find sufficient slaves, the QC decides to run the query serially. It is the function of the optimizer to use the parallel option only if there are sufficient resources available.
If sufficient resources are available, and the QC is able to get the required number of slaves, the QC sends instructions to the parallel query slaves (PQS). The coordination between the QC and PQS is done by a mechanism of process queues. Process queues are also used for communication between two or more PQS processes and this is handled using queue references.
Queue references are a representation of a link between two process queues. They are always organized in pairs, one for the process at each end of the link. Each queue reference has three message buffers, which are used to communicate between the processes. Every parallel operation is given a unique serial number. All the processes involved as a sanity check on incoming messages use this serial number, as all messages carry this number.
PQS, which is a background process, does most of the work for a parallel query. PQS are allocated in slave sets, which act as either producers or consumers. Determination of number of slave sets to be used is based on the complex nature of the query. For a simple query such as SELECT * FROM PRODUCT, only one slave set may be used, just to scan the table. This set of slaves acts as producers. However, if the query has a more complex nature, such as a multitable join or has a sort or group by operation, then probably more than one slave set would be used, and, in this scenario the slaves act in both the producer and consumer roles. When acting as producers, slaves are making data available to the next step (using the table queues). When acting as consumers, slaves are taking data from a previous table queue and performing operations on it.
Only when there is a need for multiple slave sets (e.g., where statements have ORDER BY or GROUP BY conditions, or statements that have multitable joins) does the consumer come into operation.
This parallelization process is dependent on the current data conditions such as volume, distribution, indexes, etc. Consequently, when data changes, if a more optimal execution plan or parallelization plan becomes available, Oracle will automatically adapt to the new situation.
Passing of data back and forth between the various processes is done using table queues (TQ). TQ is an abstract communication mechanism, which allows child data flow operations to send rows to its parents. Once the QC receives the results back it passes them over to the user that made the original request.
Figure 6.2 represents basic parallel query architecture. The slave set processes (P0 and P1) read data from disk, and, using the queue references and process queues, pass it to the P3 and P2 for sort and merge operation (if the query has GROUP BY or ORDER BY clause). Then it again passes through the queue reference layer to the TQ before returning data back to the QC process. The QC then presents the results back to the client program.
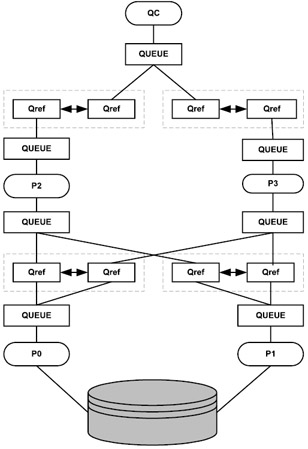
Figure 6.2: Parallel processing architecture.
Parallel query slaves bypass the buffer cache and perform a direct I/O to read data from disk. This makes the parallel query operation much faster and also avoids flooding the buffer cache. The data is retrieved directly into the PGA by the PQS process.
Beyond the parallel execution of the statement, in-between processes (e.g., sorting, ordering, joining, etc.) could also be executed in parallel. This kind of operation is called intra-operation parallelism and inter- operation parallelism.
-
Intra-operation parallelism is the parallelization of an individual operation, where the same operation is performed on smaller sets of rows by parallel execution servers.
-
Inter-operation parallelism happens when two operations run concurrently on different sets of parallel execution servers with data flowing from one operation into the other.
Let us expand the previous query (SELECT * FROM PRODUCT) with an additional clause of ORDER BY operation.
SELECT * FROM PRODUCT ORDER BY PRODUCT_NAME;
If this query were executed in a regular non-parallel mode, it would perform a full table scan against the PRODUCT table, followed by a sorting of the retrieved rows by PRODUCT_NAME. On the other hand, if the column PRODUCT_NAME does not have an index associated with it and if the degree of parallelism is set to four, i.e., to execute this query in four parallel operations, then each of the two operations (scan and sort) is performed concurrently using its set of parallel execution servers.
Figure 6.3 represents a pictorial view of the earlier query executed in parallel. The query is parallelized at two stages, the scan phase and the sort phase of the operation, with degree of parallelism of four. However, if you look at the combined execution, it is divided into eight parallel execution servers. This is because it is an inter-operation parallelism where a parent and child operator can be performed at the same time.
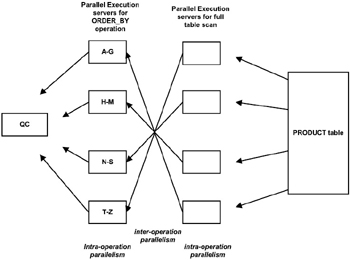
Figure 6.3: Intra- and inter-operation parallel processing.
It should be noted from Figure 6.3 that the two parallel execution tiers are related to each other in the sense that all the parallel execution servers involved in the scan operation send rows to the appropriate parallel execution server performing the sort operation. For example, if a row scanned by a parallel execution server contains a value of the PRODUCT_NAME column between A and G, that row gets sent to the first ORDER BY parallel execution server. When the scan operation is complete, the sorting processes can return the sorted results to QC, which then returns the complete query results to the user.
6.5.1 Parallel query initialization parameters
PARALLEL_MIN_SERVERS
This parameter specifies the minimum number of parallel execu tion processes for the instance. The value of 0 indicates that parallel execuion processes will not be created. If a value greater than 0 is defined, then Oracle creates the parallel execution processes at instance startup.
PARALLEL_MAX_SERVERS
This parameter specifies the maximum number of parallel execution processes and parallel recovery processes for an instance. By defining a max value, Oracle will not start too many execution processes. Processes are only added on an as-needed basis.
Careful attention should be given to setting this value. If the value is set too high, this could cause degraded performance, especially when sufficient resources are not available to support this behavior.
However, if this parameter is set to a big number, for example 255, Oracle will limit the effective (real) maximum number of processes, taking into account the number of processors on the machine and the number of threads per processor.
For every process, one chunk of PGA memory is allocated. If a process is loaded in memory during instance startup because the PARALLEL_MIN_SERVERS initialization parameter was set to a value > zero, the chunk remains allocated until instance shutdown. This chunk of memory allocation is given the attribute of ''permanent.'' Conversely, there are ''temporary'' processes and ''temporary'' chunks. For example, if the original values for PARALLEL_MIN_SERVERS and PARALLEL_MAX_SERVERS were set to 10 and 40 respectively, then these values defined in the initialization parameter file would cause the creation of 10 permanent processes and permanent chunks. Now, if the user process requested query parallelism by issuing a command to ALTER this minimum value to 20, this will cause Oracle to dynamically start additional processes to satisfy the user request for parallel execution, namely 10 temporary processes and 10 temporary chunks based on the user request. However, if the user subsequently makes another request to alter the parameter to a value that is greater than the initial definition of PARALLEL_MAX_SERVERS, the command will return an error.
Conversely, if the user sets PARALLEL_MIN_SERVERS to zero (i.e., below the level defined in the parameter file), this change will make all processes and chunks (that are of permanent status) temporary.
PARALLEL_MIN_PERCENT
This parameter is specified in relation to the PARALLEL_MIN_SERVERS and PARALLEL_MAX_SERVERS parameters defined above. This helps specify the minimum percentage of parallel execution processes required for parallel execution. This parameter determines whether the SQL will be executed if all the slaves requested are available.
PARALLEL_ADAPTIVE_MULTI_USER
This parameter enables the adaptive algorithm and, helps improve performance in environments that use parallel executions. The algorithm automatically reduces the requested degree of parallelism based on the system load at query startup time. The effective degree of parallelism is based on the default degree of parallelism, or the degree from the table or hints, divided by a reduction factor.
Having PARALLEL_ADAPTIVE_MULTI_USER set to TRUE causes the degree of parallelism to be calculated as
PARALLEL_THREADS_PER_CPU * CPU_COUNT * (a reduction factor)
The purpose of this parameter is to allow as many users as possible to concurrently run queries in parallel, taking into account the number of CPUs on the machine. As more parallel queries are issued, the number of slaves allocated to each will be reduced, thus preventing parallel queries from being forced to run serially or failing with the error:
ORA-12827 insufficient parallel query slaves available.
PARALLEL_AUTOMATIC_TUNING
This parameter determines the default values for the parameters that control parallel execution. When this parameter has been defined, it is required that the table definitions carry the clause PARALLEL. This helps Oracle to tune the parallel operations automatically.
When PARALLEL_AUTOMATIC_TUNING = TRUE, Oracle attempts to compute a reasonable default for processes which takes into account the additional resources required for parallel execution of SQL statements. The number of parallel processes will be set to the larger of:
-
What is set in the parameter file (init<SID>.ora), or
-
The larger of:
PARALLEL_MAX_SERVERS * 1.2
or
PARALLEL_MAX_SERVERS ) number of background processes ) (CPU_COUNT * 4)
Under most situations the value from the second formula under option 2 is almost always higher compared to the first formula. The background processes include the number of background processes such as PMON/ SMON/LGWR, etc., active in an Oracle instance. The value of this normally would be 11 for a single instance configuration and 15 for a RAC configuration. The additional background processes in a RAC environment are LMS, LMON, LMD, and DIAG. CPU_COUNT defaults the actual number of CPUs on the system. When PARALLEL_AUTOMATIC_TUNING is TRUE, the PARALLEL_MAX_SERVERS is also influenced by the setting of the PARALLEL_ADAPTIVE_MUTLI_USER parameter.
PARALLEL_MAX_SERVERS = CPU_COUNT*2*5
PARALLEL_ADAPTIVE_MULTI_USER defaults to TRUE when PARALEL_AUTOMATIC_TUNING is set to TRUE.
| Note | When setting the PARALLEL_AUTOMATIC_TUNING to TRUE, caution should be taken in sizing the LARGE_POOL_SIZE parameter. If the LARGE_POOL_SIZE parameter value is set low, the ''ORA-04031: unable to allocate %s bytes of shared memory'' error. |
| Oracle 10g | New Feature: This parameter is deprecated in Oracle Version 10g. Oracle now provides the required defaults for the parallel execution initialization parameters, which are adequate and tuned for most situations. |
PARALLEL_THREADS_PER_CPU
This parameter specifies the default degree of parallelism for the instance and determines the parallel adaptive and load-balancing algorithm. It describes the number of parallel execution threads that a CPU can handle during parallel execution.
By setting this value, the parallel execution option is not enabled. This parameter just indicates that such an option is possible. Parallel execution can be enabled by defining the PARALLEL clause at the table level or by adding a PARALLEL hint to the SQL statement.
This parameter is operating-system dependent and the default value of two is adequate in most cases. On systems that are I/O bound, increasing this value could help improve performance.
PARALLEL_EXECUTION_MESSAGE_SIZE
The default value for this parameter is 2148 bytes when PARALLEL_AUTOMATIC_TUNING is set to FALSE. While the default value of 2148 bytes is sufficient for most applications, increasing this value to 4096 bytes helps in increased performance.
6.5.2 Parallel query using hints
So far we have looked at parallelism in a natural way, not truly natural in the sense of being automatic, but by defining parameters for the entire instance (globally) across all SQL statements. Under this option and based on the statistics collected, the optimizer will determine whether parallel execution would be beneficial.
There is yet another method of using hints to inform the optimizer to behave in a certain way. For example, in the query below, a hint is used requesting a parallel execution:
SELECT /*)PARALLEL (PRODUCT 4) ORDERED*/ * FROM PRODUCT WHERE PRODUCT_ID =: PRODUCT_ID GROUP BY PRODUCT
PARALLEL (PRODUCT 4) ORDERED*/ tells the optimizer to scan the PRODUCT table using four execution servers and to use a similar parallel approach to ORDER the result set. There are various kinds of hints that could help the parallel execution behavior such as:
-
PARALLEL
-
NOPARALLEL
-
PQ_DISTRIBUTE
-
PARALLEL_INDEX
-
NOPARALLEL_INDEX
PARALLEL
The PARALLEL hint specifies the desired number of concurrent servers that can be used for parallel operation. The hint applies to the SELECT, INSERT, UPDATE, and DELETE portions of a statement, as well as to the table scan portion. When using this hint, the number of servers that can be used is twice the value in the PARALLEL hint clause, if sorting or grouping operations also take place.
In queries that join multiple tables and when aliases are used, the hint should use the table alias. The hint can take two values, separated by commas after the table name. The first value specifies the degree of parallelism for the given table and the second value specifies how the table is to be split among the RAC instances. If no value is specified, the default value is used, which is the value specified in the initialization parameter for the degree of paral lelism (DOP). It would be beneficial to give an example of a query like this:
SELECT /*)PARALLEL (EM 4) ORDERED*/ EMP_ID, EMP_NAME, DEPT_NAME FROM EMPLOYEE_MASTER EM, DEPARTMENT_MASTER DM WHERE EM.EMP_DEPT_ID = DM.DEPT_ID;
NOPARALLEL
The NOPARALLEL hint overrides a PARALLEL specification in the table clause. For example:
SELECT /*) NOPARALLEL PRODUCT */ * FROM PRODUCT
PQ_DISTRIBUTE
The PQ_DISTRIBUTE hint improves the performance of parallel join operations. The improvement in performance comes from specifying how rows of joined tables should be distributed among producer and consumer query servers. Using this hint overrides decisions the optimizer would normally make.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 174