XML and Three-Tier Web Architectures
XML can fit into many different places on a Web site. In this section, I'll discuss a Web site that uses XML wherever appropriate, and I'll show how XML is superior to other available technologies.
A modern Web site provides personalized information to its users. Gone are the days when a company could get away with having a dozen static HTML pages to serve up to its customers or potential customers. Those companies found that a customer would visit their site initially and, after discovering nothing new in a subsequent visit, never return. The customer assumed that nothing on the site ever changed.
Today's successful site provides useful information to users, so the users come back again and again. This return traffic allows you to provide your customers with new data whenever business reasons dictate. XML can help you provide a personalized view of that data in several different ways.
Let's examine a hypothetical site that uses modern three-tier Web architecture (shown in Figure 1-1) and XML together to provide great information.
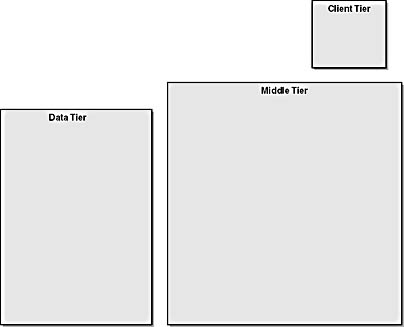
Figure 1-1. Three-tier Web architecture showing the data, middle, and client tiers.
To get the most out of the information in a modern Web site, we will employ a three-tier architecture. This is also called n-tier because there can be many different tiers between the two end points, depending on the task performed. Microsoft sometimes refers to this architecture as Windows Distributed interNet Architecture, or Windows DNA.
Data Tier
Data sources reside in the data tier. Notice that I did not say "databases." A database is one source of data, but there are others. In this example, we will use external sites and business partners as sources of data. When I say that data sources reside in the data tier, I don't necessarily mean that the data tier is a physical machine. It is a conceptual place where data sources are made available to processes running on another tier. Whether the data tier is a single machine, many machines, or a set of virtual HTTP connections to the Web is irrelevant to this discussion.
Client Tier
Next comes the client tier. In this example, we will rely strictly on thin clients—usually a Web browser. A thin client is called "thin" because most of the processing is done on the server and shipped to the browser for display purposes. Modern Web browsers have the ability to do more processing than they are usually called on to do; you will see that additional processing capability when you use XML to transfer data to the clients.
Middle Tier
Between the data tier and the client tier sits the middle tier. In the middle tier, business processes are applied to data from the data tier and the result is sent to the client tier. In other words, the middle tier is where the work gets done.
The most common component in the middle tier is a piece of software that responds to the client's requests to initiate a process. This software is called the HTTP server or, more commonly, the Web server. The Web server doesn't do much except receive requests and fire off middle-tier applications. These applications are written in many different computer languages and embody the business logic required to achieve a certain effect.
The example we will examine uses several server-side applications to connect to the data tier, retrieve raw data, process it according to some rules, and present it to the user.
Subscriber Profiles
When a Web browser makes a request, it sends a stream of data containing useful pieces of information to the Web server. The Web server can use this information to find out what brand of browser is making the request, what operating system it runs on, and what its display capabilities are. Some browsers can even report on the site that referred the user to our site.
On our data tier, we maintain a subscriber profile database. Figure 1-2 shows the structure of this database.
Notice that there are fields for name, e-mail address, and zip code, plus some time stamp fields that indicate when the person first visited our site and when his or her most recent visit was.
Another thing we can make use of is a cookie. We can send a cookie to a user's machine at any time. If the user accepts the cookie, the cookie stays on the user's system for a specified time period and is therefore considered a persistent object that allows us to turn a stateless protocol into a stateful protocol. Once we place a cookie on a person's machine, the machine returns it to our server whenever a request is made. For example, the VisitorID field shown in Figure 1-2 could correspond to a cookie value we place on the visitor's machine. When the server gives this cookie a new visitor, a new record is placed in the data tier database. The VisitorID then becomes a key we can use to store and retrieve subscriber information. Figure 1-3 demonstrates how these three tiers communicate.
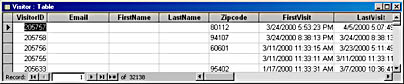
Figure 1-2. The subscriber profile database showing sample records, keyed by a unique VisitorID.
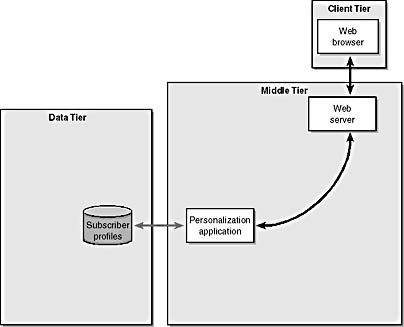
Figure 1-3. The Web server passes HTTP header information to a personalization application, which queries a database containing subscriber information. The VisitorID field is used to access the information for each particular user.
Now we can read the cookie and, by looking into the database, discover when the person last accessed the site. We use that information to determine what to do next. All this processing can be done without any help from the user.
SQL and XML
Structured Query Language (SQL) is a straightforward language designed to get information out of a relational database. Hundreds of thousands of programmers and database administrators use SQL. Every major relational database product supports SQL to some extent, which shows the power of standards: if an Oracle database programmer changes to a job where the database is now Microsoft SQL Server, that programmer carries an understanding of SQL to the new environment.
The open-system standards story ends there, however. Even though SQL is a standard way of sending query requests to almost any relational database, each database manufacturer has a different way of responding to that request. Responses come back in the form of a recordset, but the binary structure of this result set is different for each database.
Wouldn't it be nice to send an open standard request (SQL) to any database, and get back a standard response? (Might I suggest XML?) Several database manufacturers are working on a solution to this problem. Let's take a look at the Microsoft approach.
A Microsoft ADO (ActiveX Data Objects) Recordset object can persist a recordset as an XML stream with a fixed schema, or set of specifications. (I discuss schemas in more detail in Chapter 4.) Let's say you sent the following SQL query to an ADO-enabled database:
SELECT Name, Joke FROM Students |
The following document is an XML stream returned as the result of persisting a SQL query response using Microsoft Data Access Components (MDAC).
<xml xmlns:s='uuid:BDC6E3F0-6DA3-11d1-A2A3-00AA00C14882' xmlns:dt='uuid:C2F41010-65B3-11d1-A29F-00AA00C14882' xmlns:rs='urn:schemas-microsoft-com:rowset' xmlns:z='#RowsetSchema'> <s:Schema id='RowsetSchema'> <s:ElementType name='row' content='eltOnly'> <s:AttributeType name='Name' rs:number='1' rs:nullable='true' rs:write='true'> <s:datatype dt:type='string' rs:dbtype='str' dt:maxLength='50'/> </s:AttributeType> <s:AttributeType name='Joke' rs:number='2' rs:nullable='true' rs:write='true'> <s:datatype dt:type='string' rs:dbtype='str' dt:maxLength='2147483647' rs:long='true'/> </s:AttributeType> <s:extends type='rs:rowbase'/> </s:ElementType> </s:Schema> <rs:data> <z:row Name='Brian Travis' Joke='Two peanuts were walking down the road, and one was assaulted'/> <z:row Name='Ben Kinessey' Joke='A guy walks into a doctor's office. The guy says,"Doc, everywhere I look I see spots". The doctor says,"Have you seen a doctor?" The guy says ,"No, just spots."'/> </rs:data> </xml> |
Notice that the document has two main sections: one that describes the schema for the fields returned and a data section that contains the resulting rows. The schema is a fixed schema defined by the database, but it can easily be transformed into whatever schema form you need by using an Extensible Stylesheet Language (XSL) Transformations, or (XSLT) style sheet. (See Chapter 6 for a description of this style sheet.)
HTML as XML
By knowing when a visitor last accessed our site, we can look for company information that is saved in another database. This information might take the form of static HTML pages containing press releases, new product announcements, or any other type of dated material. Knowing the date the visitor last accessed the site allows us to return pages that contain only material that is new or has been updated since that date.
We query this database to find any information that is newer than the information posted on the date of our visitor's last visit to our site. In a situation like this, XML can be used as a standard syntax for returning information from a database. Figure 1-4 demonstrates a marketing application that retrieves information from the data tier and returns it to the Web server.
You will see later that HTML is sort of like XML. An HTML document is an XML document if it adheres to a number of rules called well-formedness constraints. This means that we can continue to use HTML in our environment for display while using XML tools to process the information.
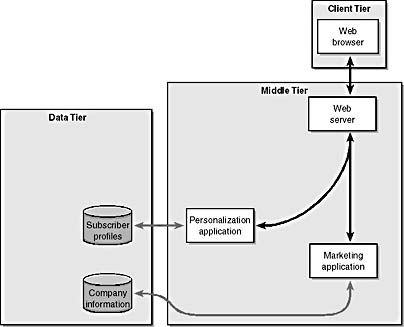
Figure 1-4. The marketing application uses information about when the visitor last visited the site to look for new company information.
E-Commerce Services
The whole purpose of our site is to generate business. To this end, we fire off an ecommerce application that makes a connection to a catalog of products and services our company provides. This catalog takes the form of a SQL database, shown in the data tier in Figure 1-5. In this case, the online catalog uses the personal information captured from the subscriber profile database to display a list of products or services that can be targeted to the current visitor.
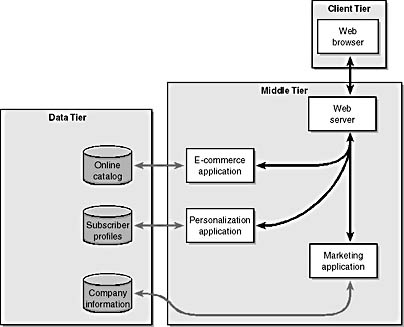
Figure 1-5. Adding another database to the data tier. The online catalog is a SQL database, so we can use the same SQL-to-XML technique as we used with the subscriber profile.
Content
Now we need to start giving information back to our user. If we don't personalize the site with information that is useful to our visitor, she might not bother coming back.
External sites can provide a rich source of data. These sites are not databases on our local machine, but have valuable content. We can use XML to request information and get information back as XML objects in order to process them further. Some external services, such as current weather status or traffic conditions, provide this information for a fee. These external sites give us information that we can process into a form that is useful for our visitors. Our job is to aggregate certain types of content from several sites onto our page to give our visitor what she needs. Figure 16 illustrates the use of external sites in our three-tier architecture.
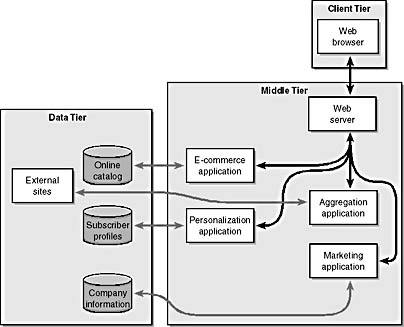
Figure 1-6. External data sites become part of our data tier, and an aggregation application is used to integrate this new data in the middle tier.
Suppose I wanted to add real-time weather data to my site. Current weather conditions and forecasts change on an hourly basis. I could start to gather that information myself, but setting up weather stations all over the country is a bit out of my price range and not within the scope of my business plan.
I could also get free weather information from the National Oceanic and Atmospheric Administration (NOAA), which has under its purview the National Weather Service. This organization captures weather from many reporting stations throughout the country and makes it available to qualified providers. However, the data is raw and requires interpretation to create forecasts. This is also outside the scope of my business plan.
However, there is an organization that specializes in capturing, forecasting, and providing weather data: The Weather Channel. I remember first hearing about a 24hour channel that reported the weather back in the early 1980s when cable TV was starting to appear in more households. Of course, I thought that was quite a silly idea: an all-day television channel doing nothing but reporting weather.
Now, eating my words, I have weather.com bookmarked in my browser, I keep the current conditions synced to my Palm-size PC via AvantGo, and I frequently refer to The Weather Channel (channel 362 on DirecTV) when I want to plan a party, leave town, or am just bored with the other 499 channels showing The Piano.
Part of The Weather Channel's content offerings is weather.com. This site provides weather forecasting information for 25,000 zip codes around the United States. If I go to weather.com—which is shown in Figure 1-7—I can see current weather for my city by providing only the zip code.
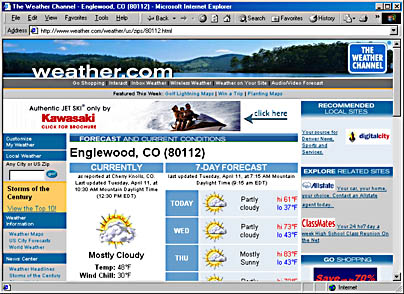
Figure 1-7. The Weather Channel provides real-time weather conditions and multiple-day forecasts through its weather.com Web site.
I want to provide this information for visitors to my site. However, I don't want to link them to the weather.com site because they would leave my site. Also, I don't particularly like weather.com's format—the little sun-and-cloud icon takes up too much space. Also, I might sometimes want to provide a three-day forecast or a seven-day forecast. And finally, I want to provide the temperature in Celsius for visitors who indicate that as a preference.
So, instead of using the data as the weather.com site presents it, I decide to try to purchase the information directly from them in a way that makes it possible for me to provide extra value to my customers. I go down to The Weather Channel offices, knock on the door, and ask the staff if they are willing to work with me to leverage their content assets.
I tell them my requirements, and I suggest that whenever I need weather information from them, I send them an electronic request with the XML stream below.
<weather_request days="5" temp="fahrenheit" wind="mph"> <zipcode>80112</zipcode> </weather_request> |
In response, I would like them to send back a stream that looks like this:
<weather_response zipcode='80012' Updated='2000-01-07 21:49:06'> <location>Aurora, CO</location> <current> <condition name='temp'>28</condition> <condition name='wind chill'>12</condition> <condition name='wind'>from the Southeast at 8 mph</condition> <condition name='dewpoint'>18</condition> <condition name='relative humidity'>66%</condition> <condition name='visibility'>25 miles</condition> <condition name='barometer'>30.02 inches</condition> <condition name='Sunrise'>7:20 am MST</condition> <condition name='Sunset'>4:50 pm MST</condition> </current> <forecast> <day date='20000108 21:49:06' High='49' Low='20' Sky='Partly Cloudy'/> <day date='20000109 21:49:06' High='46' Low='21' Sky='Partly Cloudy'/> <day date='20000110 21:49:06' High='51' Low='25' Sky='Partly Cloudy'/> <day date='2000-01-11 21:49:06' High='51' Low='19' Sky='Partly Cloudy'/> <day date='2000-01-12 21:49:06' High='53' Low='21' Sky='Partly Cloudy'/> </forecast> </weather_response> |
Let's look at this code for a moment, before we get back to my story. This is a two-way transaction consisting of a request and a response to that request. This request-response architecture is a fundamental piece of error-free transactions. What about potential errors?
Suppose I send the following request:
<weather_request days="5" temp="fahrenheit" wind="mph"> <zipcode>80000</zipcode> </weather_request> |
In this case, The Weather Channel doesn't understand the zip code. It can send me a response like this:
<weather_response zipcode='80000'/> |
This response is an empty document, confirming that I entered a zip code. If I get a document back with this structure, I need to do something to inform my user that the zip code supplied was incorrect, and perhaps invite the user to select another zip code.
Now suppose I send a completely wrong request:
<weather_request days="365" temperature="f"> <zipcode>none of your beeswax</zipcode> </weather_request> |
At some level, the receiving system can punt, and send back the following response:
<weather_response/> |
In my meeting with The Weather Channel people, I need to deal with the transfer of data and any potential problems. This is an important part of any business-to-business transaction. Remember Ecclesiastes? There is nothing new under the sun. Even in Pony Express days a business deal required a contingency for all conceivable problems. Well-formed agreements have a way of handling even the most inconceivable of problems.
In the end, The Weather Channel agrees that providing raw weather forecast information is something it wants to do, but doing so will cost money to develop and maintain, so they want me to pay for the data.
No problem, I say, I will give The Weather Channel a half a cent every time I ask for a forecast, payable in monthly installments. Agreed, they say. The Weather Channel will develop a system to give me the information I need, and I will pay them on an ongoing basis for the content they provide.
So, what do I do with the content once I get it? The XML documents The Weather Channel sends contain just the data that I need. I can apply different processes to this data depending on the type of output that I need at any given time. I can format the weather to appear as it does on The Weather Channel site, or I can list just the current conditions in a box and have a link to a place where the five-day forecast is rendered. In other words, I can make the data look however I want it to look because I have access to that raw data. I apply the process as I deem appropriate.
SOAP
Now let's talk about how the data gets from external sites to our site. Since our data-provider partners can make their services available in a number of ways, I need to be prepared to make any type of connection required. Data might be available via an FTP connection, via an encrypted tunneling protocol, or even via e-mail. More and more, however, HTTP has been used as the preferred connection protocol. HTTP is preferable because it's a simple protocol to process and, most important, it passes through almost any firewall. These factors make it easy to build systems that communicate in a loosely coupled environment by using data as the binding layer.
How do we request this information and get a response? With the Simple Object Access Protocol, or SOAP. SOAP is an Internet Engineering Task Force (IETF) Internet draft that lets you invoke procedures on remote systems by using a standard set of XML tags. SOAP uses HTTP as its data request and response protocol, so you can deploy it quickly and efficiently to get data between you and your content-provider partners. I'll describe SOAP in detail in Chapter 8.
XML for Content Providers
A number of sites provide content on a syndicated basis. Examples of syndication partners are newspapers, traditional syndicates such as King Features or UPI, and even Web-savvy content providers reselling information gathered online.
I spent considerable time negotiating with The Weather Channel to get its content. But The Weather Channel isn't the only provider of weather data. There are Accuweather, the National Oceanic and Atmospheric Administration (NOAA), and countless re-marketers of this data. There are also providers of weather information in other countries. What if I didn't like the service I received from The Weather Channel, or they couldn't give me all of the information I needed? Or, what if I wanted to make international weather forecasts available on the site? If this were the case, I would need to go through the process of negotiating with another provider of the content we need.
From the consumer perspective, our site isn't the only site on the Web that needs to purchase weather information from providers. Many general consumer portal sites provide weather information in exchange for some marketing information about the visitor. In our scenario, each one of these portal sites would need to go to one or more of the providers of weather data and negotiate the data formats it requires.
Wouldn't it be nice if all the providers of weather information got together with all the consumers of such data and came up with a standard format for exchanging information?
Such a thing happened in the news business. Let's look at the problem the news business faced and then examine the solution they've adopted. Figure 1-8 illustrates the type of three-tier architecture that we would like to use to access news data.
Companies that supply news content, such as the members of Newspaper Association of America (NAA), realized they had a product to sell, but format differences got in the way. For example, the New York Times uses an editorial management and typesetting system to create its flagship product. In fact, it has many different systems, depending on what it is creating. The daily newspaper uses one system, but the Sunday magazine uses another.
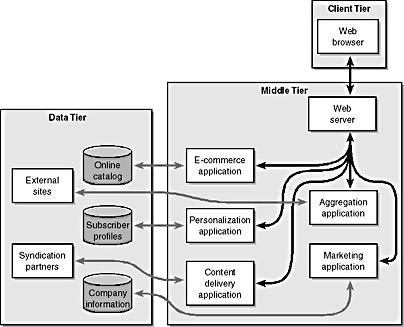
Figure 1-8. Multiple syndication partners provide content based on standards, so we can aggregate many different sources into a single, cohesive list of articles.
If I wanted to purchase content from the New York Times, I would either need to be able to accept files in the format it uses or convince the paper to convert its information to be compatible with my system. I could get national and world news from the New York Times, but I might also want to offer local news to my users.
If my users were only in New York, the New York Times would be all I needed. However, to give my users what they expect from me, I would need to contract with many different local newspapers in many different locations.
As a small Web site wanting headline news, I'd have a hard time convincing the mighty New York Times to convert their data for my convenience. Plus, I would need to independently approach potentially hundreds of other newspapers around the country and try to convince them to give me their content in my format. I'm not likely to convince them to do this. If I wanted to buy content from all these sites, I would more likely need to write conversion filters to translate their data into a form appropriate for my site.
Since each one of these providers of editorial content manages information in a different way, I would need to investigate all their data formats, understand them, and write conversion filters—this is time-consuming and prone to synchronization errors. The system illustrated in Figure 1-9 shows traditional newspaper providers (New York Times and Denver Post) and a new media content provider (MSNBC), as well as a provider of news in a monthly magazine format (Reason).
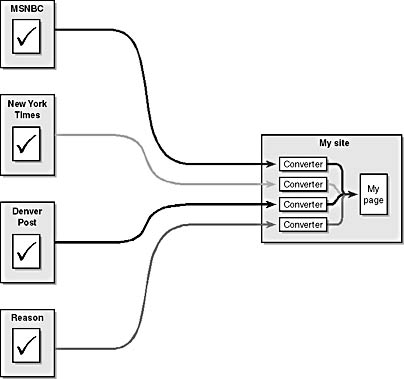
Figure 1-9. Each syndication partner requires a specialized converter that transforms its custom structure into a form that our page can use.
But it is even more complicated than Figure 1-9 suggests. Suppose another site wanted to buy content from the same sites I wanted to buy information from. These sites would need to write conversion filters as well. Since we are competitors, I'm not going to share my conversion programs with them. With all these different sites involved, the system really looks more like Figure 1-10.
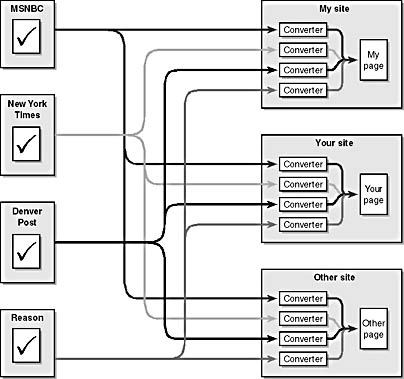
Figure 1-10. Multiply the customer conversion approach by the number of sites using content, and the problems with individual sites are also multiplied.
That's a whole lotta conversion going on.
And that's not the worst part. All these information sources create content for their own print newspapers and Web sites. Reporters who put these stories together often generate more information than can be printed in the paper. For example, consider the following sentence:
The Burning Man Festival is set for next June. The admission price is $150.
There is potentially useful information. We get some information about the festival that might be useful to a reader, but let's say that the news source has more information that isn't necessarily appropriate for their target audience. For example, the Burning Man Festival is an event held in the Nevada desert every year. Let's say that our audience wants all the details that they can get on the show. Noting the fact that the event is in June is helpful, but it would be better if we knew the exact dates.
For the purposes of brevity and journalistic style, however, putting that information in the national newspaper article would be overkill:
The Burning Man Festival, an event happening in the Nevada desert, is set for the week of June 12-19, 2000. The admission price, in U.S. dollars, is 150.
Instead, the information could be captured in a form that allows the style-conscious editor to create appropriate printed material and provides the user with targeted, useful information. Wouldn't it be nice if we could use the same information for multiple audiences? If we could, our information assets would have a broader appeal and have more chance of being picked up by re-marketers who pay for that data. In other words, the more relevant our data is for the most people, the more valuable it will be for our company and investors.
Standards
When the Web gained critical momentum in the mid-1990s, many traditional providers of news realized that many sites in the world, like mine, might want to buy content but couldn't afford the cost of converting the typesetting data. If these news outlets could provide their data in some form that we small providers could use, perhaps they could create new revenue streams.
Many newspapers belong to the NAA. In the 1970s, the NAA (then called the American Newspaper Publishers Association), through its Wire Service Committee, created a specification known as ANPA 1312. The committee designed the spec to provide a way for wire services to consistently transmit stories to newspapers. The spec also ensured that the coding embedded by the wire service—boldface, spacing, typographic markup, and so on—would not only survive the trip, but actually appear correctly (as boldface or a thin space) when it got to the newspaper.
Virtually all North American wire services and all the suppliers of wire collection software adopted ANPA 1312 as the standard, though there were reports of certain wire services not completely adhering to the specification. When the ANPA turned into the NAA, ANPA 1312 became the News Industry Text Format (NITF), and the Wire Service Committee became the News Information Task Force (NITF). Get it?
In 1998, the NITF specification was reviewed and turned into an XML schema. This schema added much more to the original specification—it allowed for tags that described the data rather than the typography.
Compare Figure 1-11 with Figure 1-10 shown earlier. Using a standardized approach to news delivery requires that each provider and consumer of syndicated content create only a single converter, since all sites use the same vocabulary of elements to communicate. Figure 1-11 illustrates how data gets from a provider to a site using this standardized approach.
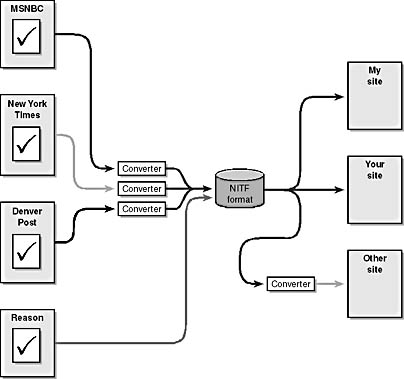
Figure 1-11. Providing data in a single format eliminates the need for proprietary conversion software for each data provider.
Each provider needs to create just one conversion filter, which takes content from the provider's format into the NITF format. Then sites can either take that format natively, or they can convert it to the form required for their production systems.
But that's not even the best part. Consider the Burning Man example we looked at earlier in the chapter. The basic information (event title, location, and cost) can be tagged in a way that makes more information available than what was available in the original, simple story. This extra information gives a site designer more information from which to generate content.
The <event><location>Nevada desert</location>Burning Man Festival </event> is set for <chron norm="20000612">next June </chron>. The admission price is <money unit="USD">150</money>. |
For example, suppose that clicking on the text specified by the <event> tag brought up a list of all events happening in the Nevada desert, or clicking on "next June" brought up all events happening in that time frame. The fact that all the data in the store is tagged in a standard way allows the site designer to target information directly to users. For example, a user in Germany who has asked that all currencies be displayed in deutsch marks gets the page one way and a reader in Australia gets currencies displayed according to his personal preferences.
The NITF format provides the rich tagging of the story content, plus extra information that might be useful to consumers of this content who want to render the information in other ways.
Consider the news article from MSNBC displayed in Figure 1-12.
Figure 1-12. A traditional newspaper article rendered as an HTML page.
This information would appear as an NITF article with the following tagging:
<?xml version="1.0"?> <nitf> <head> <title>Technology Tools and Toys</title> </head> <body> <body.head> <headline> <hl1>Pac-Man chomps its way toward 20</hl1> <hl2>Seminal video game rose from humble beginnings</hl2> </headline> <byline> By<person>Steven Kent</person> <bytag>MSNBC CONTRIBUTOR</bytag> </byline> <dateline> <location></location> <story.date>1999-09-03</story.date> </dateline> </body.head> <body.content> <p>He may have been a fixture in bars for most of the last two decades, but Pac-Man, one of the video game industry's greatest living legends, is still a bit shy of legal age.</p> ... </body.content> <body.end></body.end> </body> </nitf> |
The NITF format gives news providers a standard way to provide raw news to consumer sites. It gives consumer sites an easy way to read content sold by news providers. Now I don't need to make a separate deal with providers such as the Denver Post and the Reason Foundation to get news that I can read. I can just say, "Do you speak NITF?" If so, their content fits into my production system. If not, they might lose my business and should consider this industry standard.
The site we are creating is targeted to individual visitors. It is a consumer-oriented site. Using a standard like NITF lets us create specific information that's useful to the visitor. We are trying to attract customers to expose them to our products and services. In this way, our site is a B2C site.
Getting the information from the providers of information to the consumers of information requires careful coordination between sites and content-provider partners. This aspect is clearly a B2B requirement.
Building the Page
All the information we've discussed so far is captured using middle-tier applications and is generated into pages targeted to individual visitors. These pages are built specifically for users when the information is requested and are formatted according to each user's machine configuration and preferences. Our Web site builds the pages, delivers them, and waits for further requests. And XML made it all possible!
EAN: 2147483647
Pages: 150