Taxonomy Concepts
| < Day Day Up > |
| Let's explore the key concepts that relate to taxonomy and discuss its practicality in the context of managing large amounts of information within your business. A good place to start is to gain some insight into the nature of the data we are organizing. This data falls into two general categories: structured data and unstructured data. Structured DataStructured data is easier to understand than unstructured data, because it is more consistent and follows stricter rules. By understanding structured data, we will gain insights into unstructured data, which is a fundamental concept to taxonomy. Structured data resides within a database and contains well-defined tables, columns , and fields. Generally , a table represents some kind of entity, each row represents an instance of the entity, and each column represents a piece of data surrounding this entity. For example, we could represent the data surrounding a company's orders with Tables 10.1 and 10.2. Table 10.1. Customer Data
Table 10.2. Order Data
The first table represents data pertaining to customers, and the second table contains all information relating to orders. Furthermore, the association of which orders apply to which customers is tracked through the unique customer ID, which maps to an associated row in the Orders table. The point is that a user can query the database on very specific questions and receive answers, provided that the questions can be answered by the data model. For example, for the relational data model described in Tables 10.1 and 10.2, we could ask questions such as:
Unfortunately, unstructured information presents a situation that is not as straightforward because there is no well-defined model. Imagine trying to catalog the contents of your My Documents folder, which probably contains fax cover sheets, letters , work and personal documents, presentations, budget spreadsheets, family photos, downloaded software ready to install, and may other kinds of files. Unstructured DataUnstructured data is any electronic data that does not reside in a structured database (it is typically stored in documents). In contrast, structured data provides its own context: The data model itself describes what each field means. For instance, a field called Shipping Address in a table called Customers probably contains a physical address. A data field in the Invoices table probably stores the date that the invoice was created. Search techniques and rules for dealing with structured data are quite mature and generally understood . The mapping between data and metadata (data about data) is direct and straightforward. It is simple to generate a data dictionary in an automated fashion, even for a large database. Examples of unstructured information include Word documents, streaming audio and video, email, and PowerPoint presentations. Unstructured information presents many challenges compared to structured data. It is relatively simple to produce a query in a relational database that shows all invoices created in a specified date range, because the structure of the data lends itself to the query. Adherence to the data model ensures that your answer will be unambiguous and complete, and the results will be consistent and replicable over time. You can be assured that an important field such as invoice date would be a required field and thus be included in all records. It would be validated to ensure that only valid values were present. Neither completeness nor consistency is guaranteed for unstructured data, on the other hand. To search for all new articles on a topic such as knowledge management on a web site you are counting on the date of the article being entered in a metatag , and consistent terms being used to identify the key topics of articles. With unstructured data, you can search either data or metadata (or a combination of the two). The problem is that you cannot take much for granted in the quality of either. To find new articles, you could search for a date in the text of an article in a Word file or HTML, or in the metadata, such as in the HTML metatags or Word document properties. But how would you determine when the article was written? Does the file creation date mean the same thing as the date written? What if two conflicting dates were found? Which date formats should be considered ? What about vague or incorrect date values? Whereas a structured database encourages a fixed vocabulary of terms by means of dropdown lists, reference tables, and other means, unstructured data sources are by definition free of such constraints. Users cannot be sure that the same terms will be used in two different documents, even if both documents cover the same topic. On the other hand, the same word may be used in two unrelated documents. The richness of human language becomes the enemy of search accuracy. SemanticsSemantics is the science of modeling the context and relationships of all the objects in a system for the purpose of attaching meaning to the information generated by the system. All information must be placed within a specific context in order to be useful. Although beyond the scope of this book, this is the crux of the work surrounding artificial intelligence and the study of human intelligence. For example, the information "two" has little meaning unless you know two of what. By attaching two to the object apples, you have an answer to the "what" of two; but you lack any knowledge of how "two apples" relates to other objects within the system. By adding the entity "Jim" with the relationship "have," you have a clear understanding that "Jim has two apples." So in fact the basic constructs used to model the semantics of a system are very similar to the basic constructs of any language ”namely, subject-verb-object or entity-relationship-object, which is known as an associative model in the field of knowledge management. Knowledge Representation/OntologyA knowledge representation or ontology is a semantic representation of the objects within a specific domain of knowledge. The domain of knowledge could be sports, finance, insurance, and so on. The goal of the ontology would be to represent all the objects and relationships among objects within this domain. For example, suppose we chose to semantically model the same body of knowledge I described relationally earlier, namely, customer orders for a company. Within this knowledge space, only two objects exist ”customers and orders. Furthermore, only one basic relationship exists: A customer "has" an order. All objects inherently possess the IS relationship indicating the entity (or class) to which the object belongs. We could begin to describe the relationship of the data in words in the following way:
So we can start to talk about information that fits into this semantic model in the following way:
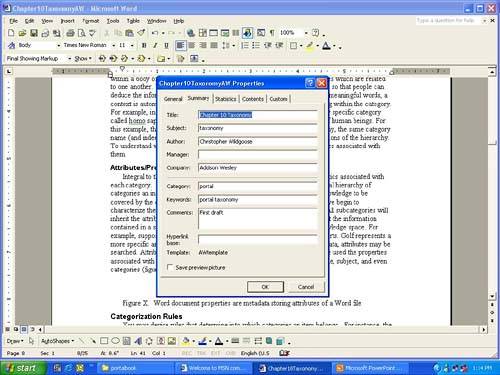
Obviously, an area of knowledge such as sports or even orders contains many more objects, and the relationships between objects within this body of knowledge are far more complex, but the idea is the same. For example, for sports, we would define objects such as baseball, player, team, and so on. Next we would begin to define the relationship rules, such as a player is part of a specific team, a team belongs to one type of sport, and baseball is a type of sport. Next we would begin to instantiate the model with real-life information, such as the Blue Jays is a type of baseball team. Whenever we read through a document, we naturally bring our own ontology to bear that is modeled by individual neural pathways within our brains . For example, when we study a subject, we are in effect strengthening our ontological map through the creation of neural pathways, thereby strengthening the associations between various concepts within a particular subject. What does this have to do with taxonomy? Well, unstructured documents are written using human languages. When someone reads a document, he is sifting through a large number of words that represent objects that are semantically related . By comparing our own internal ontological map to the information we read, we extract meaning. The goal of developing taxonomy is to make it easier for users to extract the meaning of content by providing a context. Once the meaning is determined, the document can be appropriately classified within the categories defined by the taxonomy. For example, suppose you wanted to classify this book within your book collection. You would probably identify the area of knowledge covered as being related to the computer industry even though the word "computer" is not used within the book. As discussed later in the chapter, there are a number of tools that automate the process of classification; however, all require some human intervention because of the inherent complexity of human judgment. Because the relationships that describe a whole body of knowledge are far more complex than the relationships represented through a relational model, we must use an associative model. The associative data model diagrams the semantics of the complex relationships of language using subject-verb-object terminology. While a database uses a relational model for describing the relationships between objects, a knowledge representation requires the associative model to model the concepts of a body of knowledge. The associative model represents the major technology used by the natural language query model. VocabularyWithin the context of the taxonomy, vocabulary represents a structured group of words that are used to define the main concepts used within the taxonomy. To enforce a system within your taxonomy, you must choose words carefully and consistently. Metadata tags content with words from your taxonomy. ThesauriA thesaurus keeps track of synonyms or words with the same or similar meanings. When we are dealing with unstructured information, the thesaurus creates a link between the words used to describe the same or similar concepts. Taxonomy built on the thesaurus model (designating a preferred or authorized term with entry terms or variants) helps to link these different terms together. At search time, the term that the knowledge worker uses is associated with the preferred (or key) term for more precise searching, or the knowledge worker's term is expanded to include the variant forms of the term as well as the authorized term for a broader search. Taxonomies built on the thesaurus model do not force all work groups to use a common set of terminology. CategoriesA category represents a structured vocabulary that is decided upon by a specific concept within a body of knowledge. It is an individual node among a group of nodes that are related to one another. When defining categories, the terms used should be intuitive so people can deduce the information contained within. When categories are created with meaningful words, a context is automatically created for all documents and subcategories residing within the category. For example, in the biological plants and animals taxonomy example, a very specific category called Homo sapiens is used to categorize the last leaf in the classification of human beings. For this example, the category names used are unique; but with a portal taxonomy, the same category name can exist within different locations of the hierarchy. To understand why, we first need to realize that all categories have properties associated with them. Attributes/PropertiesIntegral to the naming of the categories are the properties or characteristics associated with each category. The properties serve to describe where within the logical hierarchy of categories an individual category resides. All subcategories inherit the attributes describing the parent knowledge space, which means that the information contained in a subcategory represents a more specific area of the same knowledge space. For example, suppose we define a category called golf and a category called sports. Golf represents a specific area of knowledge within the parent category of sports. Like the data, attributes can be searched. Attributes can also be stored as metadata. For example, you may have used the properties associated with a Microsoft Word document to store data such as author, title, subject, and even categories (Figure 10.4). Figure 10.4. Word Document Properties Categorization RulesYou can devise rules that determine the categories in which an item belongs. For instance, the word "fly" could appear in items relating to civil aviation, bird watching, and trout fishing. You might have a rule that an item containing "trout," "rod," "reel," and "fly" pertains to fly fishing , while one containing "bird," "plumage," "habitat," and "binoculars" should be filed under "bird watching." SharePoint Portal Server offers categorization rules for its Audience feature. Document MetadataMetadata is information that describes another piece of information, object, or thing. Basically metadata makes finding a particular piece of information easier because moving through a stack of metadata takes much less time than moving through the data itself. For example, in the old days when you would thumb through a card catalog system in the library, you were using metadata to locate a book. The card catalog contained the necessary information for you to locate the physical book on the library shelf. Without the metadata located in the card catalog, you would have been forced to wade through all the books in the library to locate the book. Document CardA document card represents the metadata associated with a file, just as a paper card in a library card catalog contains information about a book it lists, such as author, title, publisher, and date. The document cards are indexed and made available for searching. The card contains a link to the original document. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| < Day Day Up > |
EAN: 2147483647
Pages: 164