Bi-Directional Text So far in this book, we've assumed that text is always read from left to right. In many languages, this is true, but both Java 2D and the Swing text components support the rendering of text in either left-to-right or right-to-left order. In fact, it is permissible to mix text ordering within a single paragraph, or even within the same line, so this feature is commonly referred to as bi-directional text. The most obvious example of a writing system that requires the use of bi-directional text is Arabic. Here, the text is read from right to left, apart from numerals, which use the more familiar left-to-right ordering. To display Arabic text properly, you need Java 2 and a font that can render Arabic script. Fortunately, however, you usually don't have to do anything special in your code to handle bi-directional text because the Swing text components do all the hard work for you. Core Note Even if you ignore the problems of ordering, properly rendering Arabic script is a complex operation because the appearance of many of the characters in the alphabet (glyphs in Java 2D terminology) depends in part on their context: Some characters have several different glyph representations. This is rather like drawing the letter "a" differently depending on which characters it is adjacent to. These details are taken care of by the Java 2D implementation of the Graphics drawString method, so we don't really need to be concerned with them here.
Some of the operating systems supported by Java 2 do not provide Arabic fonts unless you buy a version of the platform intended for a market in which Arabic script is used. Nevertheless, Java 2 provides a set of platform-independent fonts that do include Arabic characters, so you can make use of these fonts to render Arabic text. However, because Arabic characters are probably not familiar to you, we'll substitute the more usual Roman alphabet in the figures in this chapter where you would expect to see Arabic script, but we'll make it clear from the accompanying descriptions which characters should be considered to be Arabic. Core Note The extra fonts that Java 2 supplies are referred to as physical fonts to distinguish them from the virtual fonts that were supported by the Abstract Window Toolkit (AWT). Whereas virtual fonts have idealized names such as "Serif" or "Monospace" and are mapped to real fonts on the host platform through a mapping held in a resource file installed as part of the Java Developer's Kit (JDK) or Java Runtime Environment (JRE), physical fonts are referred to by their real names. The physical fonts that come with Java 2 are all TrueType fonts stored in the lib/fonts directory. They have the following names: Lucida Sans Regular Lucida Sans Bold Lucida Sans Oblique Lucida Sans Bold Oblique Lucida Bright Regular Lucida Bright Bold Lucida Bright Italic Lucida Bright Bold Italic Lucida Sans Typewriter Regular Lucida Sans Typewriter Bold Lucida Sans Typewriter Oblique Lucida Sans Typewriter Bold Oblique These fonts cover several different pages of the Unicode code set, including the Arabic characters that we'll be using in the examples in this chapter.
Model Order and Visual Order In all the examples that you have seen so far, we have been assuming that the characters that a text component contains are displayed in the same order in which they are stored. That is to say, the character at offset 0 is displayed to the left of that at offset 1, which appears to the left of the character at offset 2, and so on. As you saw in the last chapter, by creating a custom View, you can arrange to vary this a little by rendering characters that aren't actually in the model at all and, using similar means, you could also display fewer characters than are actually present. Nevertheless, so far we have not seen a case in which a View renders text in any order other than that suggested by the storage order within the model, which we will refer to as the logical order. The order in which a text component actually displays its content is referred to as its visual order. Figure 5-1 shows an example of what has, so far, been the rule the logical order matching the visual order. Figure 5-1. A text component displaying left-to-right text. The upper part of this diagram represents the model, containing the text in logical order. If you think of the model as being represented in concrete terms as an array of characters, the representation shown here will seem quite natural and matches what you have seen in earlier chapters. The visual order, shown at the bottom of the diagram, is how the text component will actually display these characters. Here, the text has a natural left-to-right ordering and is displayed that way. Compare this with Figure 5-2. Here, the model contains three distinct regions of text. The leftmost and rightmost regions have left-to-right ordering and are rendered in that way by the View. However, the word "bi-directional" has right-to-left ordering and, as you can see, the View reverses the order of the model characters when displaying them. This is an example of bi-directional text. Figure 5-2. A text component displaying bi-directional text.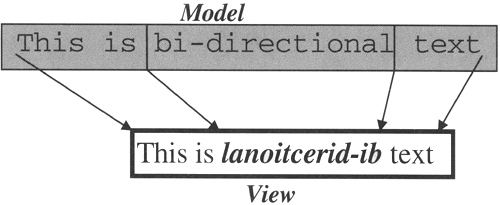 In the real world, the part of the text that has been shown in right-to-left order might be Arabic characters rendered using glyphs from an Arabic font, such as one of the physical fonts listed in the previous Core Note. As noted earlier, so that you can see that there is a change of order involved and because we're using exclusively Roman script in this figure (and in the others in this section), the part of the text that should be shown in a different font is instead shown in italics. What is it that determines whether characters have left-to-right or right-to-left ordering? So far, we've made the rather imprecise (and incomplete) statement that some (but not all) Arabic characters require a right-to-left visual ordering. This, of course, is not of much use to the person implementing the rendering algorithm how are Arabic characters going to be recognized and what about other writing systems that also don't use left-to-right ordering? The key to this problem is the fact that Java represents all characters internally in Unicode. Unicode assigns a unique 16-bit value to every character that it can represent and this value is actually stored in a Java char variable inside the text component's model. Every Unicode character is classified according to whether it belongs to a set of characters that needs left-to-right rendering or the reverse. This classification, along with the rules for handling bi-directional Unicode text, actually appears in the Unicode 2.0 specification published by the Unicode Consortium (see http://www.unicode.org for further information) and equivalent information is encoded into static data compiled into the Swing text classes. Although this data is stored in the compiled class files in a compressed form (using a simple compression technique called run-length encoding), it is expanded at runtime into a form that makes it simple to determine quickly, given any Unicode character, whether its natural rendering order is left-to-right or right-to-left. As you'll see later, this information is used to mark runs of text within the model according to their rendering requirements. Caret Position and the Selection One consequence of the fact that the logical order and the visual order of characters in a bi-directional string do not always match is that the mapping between model offset and view position is not as simple as it is when the text is rendered left to right throughout. To see the consequences of the presence of right-to-left text, type the following command: java AdvancedSwing.Chapter5.BidiTextExample This example creates a frame with a JTextPane containing a (nonsensical) sequence of mixed Roman and Arabic characters. When the program starts, you'll see a pretty meaningless representation of the pane's content, which will look something like the screen shot shown on the left of Figure 5-3. Figure 5-3. A JTextPane with bi-directional text. Depending on the exact fonts in use on your system, what you actually see may well be different from Figure 5-3. The first and last characters are actually the letters A and Z; these are also the first and last characters in the model. Because these are ASCII characters, their natural display order is left to right. The three characters in the middle are the representation of the Arabic characters with Unicode values 0xFE76, 0xFE77, and 0xFE78 given by the font that is selected for the virtual font name Serif on my machine. These characters all have the right-to-left display attribute. Unfortunately, on my system they all have the same glyph in the font, so it is impossible to tell which of the three squares corresponds to which Arabic character. For now, just take it as read that the leftmost character on the screen is the one with Unicode value 0xFE78, the middle one is 0xFE77, and the right one 0xFE76. This represents a right-to-left rendering of the middle part of the string, which is actually created as follows: String s = new String(new chart[] { (char) 'A', (char) 0xFE76, (char) 0xFE77, (char) 0xFE78, (char) 'Z' }); As you can see, the display order and the model order for the middle three characters are different. Core Note As well as the frame, you'll also see some diagnostic information displayed in the window in which you started this program; we'll examine this information when we look under the hood of the Swing text components' bi-directional text support later in this chapter.
There is another way to use this example that shows the Arabic characters as they should be represented. To do this, type the command java AdvancedSwing.Chapter5.BidiTextExample Arabic When you do this, the example selects a 32-point Lucida Sans Regular font instead of the Serif font used by default. Because this font contains glyphs for Arabic characters, you'll see something like the right side of Figure 5-3. The code that selects the font looks like this: if (args.length > 0 && args[0].equalsIgnoreCase("Arabic")) { GraphicsEnvironment.getLocalGraphicsEnvironment().getAllFonts(); System.out.println("Using physical font"); Font font = new Font("Lucida Sans Regular", Font.PLAIN, 32); tp.setFont(font); } else { Font font = new Font("Serif", Font.PLAIN, 32); tp.setFont(font); } The first part of this "if" statement selects the physical font. The only strange part of this is the first line, which uses the getAllFonts methods of the Java 2D GraphicsEnvironment class to load the physical fonts from the file system. This line is actually a workaround for a bug in the first few customer releases of the Java 2 platform, which would not recognize physical fonts unless you force them to be loaded in this way, and may no longer be necessary by the time you read this chapter. You'll probably notice that, whereas the left screen shot in Figure 5-3 clearly shows five characters, there appear to be only three characters when the text is rendered properly. We'll see later why this happens. In the rest of this chapter, we'll describe character and caret positions with reference to the left screen shot in Figure 5-3, because this makes it easier to visualize the connection between the five characters on the screen and the five in the underlying text component. For that reason, you are recommended to run the example program with the command line java AdvancedSwing.Chapter5.BidiTextExample so that what you see matches the descriptions in the text. Now let's see how bi-directional text affects the mapping between the model and the view. As well as displaying bi-directional text, this program also registers a CaretListener so that it can detect changes in the position of the Caret. Each time the Caret moves, it prints its new location as reported in the resulting CaretEvent, which is the offset of the Caret in the model. With the example program running, click to the left of the letter A that is, at the extreme left of the text component. When you do this, you should see the Caret's model offset reported as 0, which is consistent with its being at the beginning of the model. Core Note When a text component contains bi-directional text, it would be misleading to try to describe a location using the words before or after, because the interpretation of these words depends on the reading order of the text. To avoid any confusion, we'll specify position using the terms left and right, where these refer to the visual ordering that you see on the screen. Therefore, the start of the text component in Figure 5-3 is to the left of the letter A and the letter Z is four characters to its right
Next, click to the right of the letter Z; as you might expect, this positions the Caret at the end of the model and returns a model offset of 5. No surprises so far, but now click to the immediate right of the letter A immediately to the left of the leftmost Arabic character. You might have expected that this would be model position 1 but, in fact, depending on exactly where you click, it reports itself either as position 1 (if you click nearer the A) or as position 4 if the mouse is nearer to the first Arabic character. By varying the position of the mouse slightly and then clicking, you should be able to get both offsets reported in the window from which the program was started. Next, click one position to the right between the first and second Arabic characters counting from the left and, perhaps not surprisingly, the model offset now becomes 3. Finally, click to the left of the letter Z; this time, the Caret is apparently at offset 4 or 1 again, depending on the exact location of the mouse, despite the fact that the position immediately to the right of the letter A was earlier reported as being model offset 4 or 1. Clearly, something strange is going on here. To see what is happening, look at Figure 5-4. Figure 5-4. A model-to-view mapping with bi-directional text.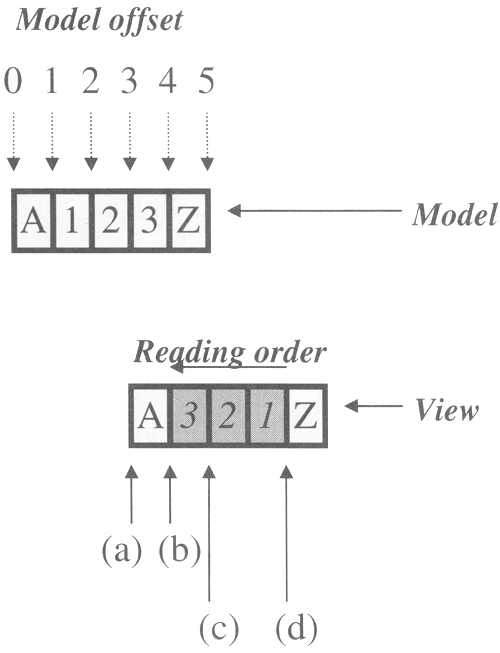 The boxed characters in the upper part of this figure show the logical ordering within the model. For clarity, the three Arabic characters are represented by the numerals 1,2, and 3. The correct model offset for each character position is shown above the model. Recall that a position offset actually refers to the offset not of a character within the model, but of the gap before that character so that, for example, the model offset corresponding to the letter A in this example is 0 and for the letter Z is 4. As far as the Arabic characters are concerned, the character denoted as 1 has model offset 1 (that is, the gap before it has this offset) and so on. The model offset is, of course, completely independent of the way the text is rendered on the screen. The lower half of the figure shows how this model is rendered in Java 2. The middle three characters have right-to-left ordering so their visual order is the reverse of the logical order shown at the top of the figure and an Arabic reader would read them right to left, as shown by the arrow labeled reading order. When you click somewhere between within the text component, the coordinates of the mouse are converted to a model location using the View's viewToModel method as you saw in Chapter 3. Clearly, clicking to the left of the a will always result in model offset 0 being returned. But what happens if you click to the right of the A and to the left of the 3 in Figure 5-4? Suppose you draw a vertical line where the Caret now resides, as shown in Figure 5-5; there are actually two ways to describe this location. Figure 5-5. An ambiguous model location. If you read the figure from left to right, the position to the left of the letter A (location (a)) obviously has model offset 0, so if you move your eye one character position to the right (location (b)), you would expect to encounter model position 1. However, this location is immediately to the left of the Arabic character denoted as 3 and earlier we saw that this location reported itself as having offset 4. At this point, an Arabic reader would skip to the character denoted by 1, in the position labeled (d) and begin reading from right to left. We know that the character 1 actually has model offset l, so if we now move from the location of the character 1 toward the left (following the reading order arrow), we would expect the gap between the characters 1 and 2 to have offset 2 (which we know to be correct) and that between 2 and 3 (location (c)) to have offset 3. What happens if we now read one more character position to the left that is, we move to location (b)? Having moved one position further through the model from offset 3, it can only be that this position has offset 4. This is, of course, exactly what was reported when the mouse was clicked in this location. It also seems to contradict the earlier description of this as being model location 1. Actually, when a text component contains bi-directional text, the boundaries at which the text flow reverses always have two possible model offsets, depending on whether you regard that point as being part of the flow to the left of that point or of the flow to its right. That is why the visual position denoted as (b) in Figure 5-4 could be thought of as corresponding to model offset 1 if you consider it to be part of the left-to-right flow that terminates with the letter A or to model offset 4 if it is regarded as belonging to the right-to-left flow that follows it. Internally, the View objects describe a location using two attributes the model offset and a bias that has the value forward or backward. The combination of a model offset and a bias always produces a unique visual position. You'll see some of the implementation details of this later in this section, but you can see the concept in action by looking again at the example program. With the example running, click again at the left edge of the JTextPane, so that the Caret moves to model offset 0. Now press the right arrow key once to move the Caret one position right. Here, the Caret is on the boundary at which the text flow changes from left to right to right to left. Clicking to bring the Caret to this location caused the model offset to be reported as 4 but, in this case, you'll find that the model offset displayed in the window from which you started the example is 1. Notice also that the Caret is not shown as a simple vertical line there is a small black box at the top, on the right of the Caret line, as shown in Figure 5-6. Figure 5-6. The caret showing a text direction indicator. This box shows the direction of flow of the text that the Caret is associated with. Because it's on the right side of the Caret line, you can tell that this is left-to-right text. However, because the Caret is actually at the location at which the text flow changes, it could legitimately adopt either orientation. In fact, because it was last in a left-to-right flow, it continues to indicate that the text flow is left to right, because it still associates itself with the flow that it was last in. This, of course, is why the model offset is currently being reported as 1, not 4. In this position, the Caret is at visual offset 1 with its bias set to backward. Now press the right arrow key one more time. Because the Caret is currently at the crossover point between flows, what should be the effect of pressing the right arrow key? Should it move right one character in terms of the model, or in terms of the View? The difference is important. If it moves one model location to the right, its model offset would be 2 which, as you saw earlier, would make it jump to the location between the 1 and the 2 in Figure 5-4. On the other hand, if it moved one character to the right visually, it would occupy the position in Figure 5-4 labeled (c), which corresponds to model offset 3. In fact, if you press the right arrow key, you'll find that it does neither of these things instead, it stays where it is and the black indicator box flips around to the left side of the Caret line, indicating that it is now in a right-to-left text flow. If you look at the output in the command window, you'll see that the model offset is now reported as 4! Instead of moving anywhere, then, the Caret hopped over the imaginary gap between the two directions of flow, but stayed in the same visual location. Press the right arrow key again and you'll see that the Caret continues to move to the right, increasing its visual offset but decreasing the model offset. Theoretically, the implementers of the text components could have chosen to make the right arrow key increase the model offset instead of the visual offset, but that would make the Caret move to the left in response to the right arrow key when it is in a right-to-left flow, which would be very confusing for the user. If you keep pressing the right arrow key, the Caret continues to move in that direction until it reaches the end of the right-to-left flow to the left of the letter z, at which point it reports its model offset as 1. At this point, the right arrow key causes the Caret to switch over into the left-to-right flow; as happened on the previous direction change, the Caret does not physically move. Instead, the directional indicator moves back to the right side and the model offset changes to 4 again. Finally, pressing the right arrow key once more moves the Caret to the end of the text, with model offset 5. Before we look at the implementation details of bi-directional text, there is one more wrinkle you need to know about. Recall that when you create a selection using the JTextComponent select method or the setSelectionStart and setSelectionEnd methods, you specify the model offsets of the two ends of the selection. When the component contains only left-to-right text, it is easy to visualize how this works. Things are not so simple with bi-directional text, however. Refer again to Figure 5-4. Suppose we create a selection that starts at model offset 1 and ends at model offset 3. Which part of the text component will actually be highlighted? There is no ambiguity about model offset 3 it is the gap between the digits 2 and 3 in the diagram. Offset 1, however, is ambiguous: Is it to the right of the letter aaa or to the right of the digit 1? These two interpretations produce different results. With the first, the selection highlight will cover the digit 3 only, while the latter would highlight the digits 1 and 2. The correct interpretation is obvious when you think in terms of the model, of course: the selection extends from offset 1 to offset 3, so it must correspond to the two characters at offsets 1 and 2, which are the digits 1 and 2. Indeed, if you click between the digits 2 and 3, which is offset 3, and then drag the mouse to the right until the Caret is to the left of the letter z, which is offset 1, you'll see that the selection appears in the correct place, as shown in Figure 5-7. Figure 5-7. A selection in a right-to-left text flow.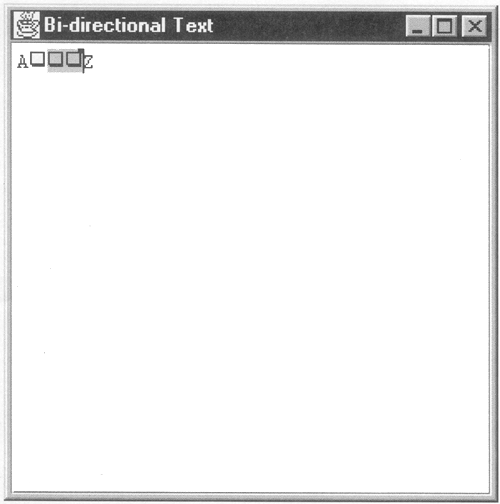 That, however, was a simple case. What happens if, instead, you create a selection that starts at offset 0, with the same ending location as before (offset 3)? Whereas in the previous example the whole selection was in the right-to-left flow, this one starts in the left-to-right flow and then crosses the boundary into the right-to-left flow. The characters covered by these offsets are A, 1, and 2, as you can see from the diagram of the model in Figure 5-4. However, if you look at the visual representation at the bottom of that figure, you'll see that these characters are not displayed as a contiguous block! This is a problem, because the selection highlight is usually a continuous colored rectangle. If that were the case here, it would cover not only the characters that it should highlight, but also the character shown in Figure 5-4 as 3, which is not part of the selection at all! In fact, this does not happen. To see this, click to the left of the character A and then drag it two character positions to the right, so that the Caret occupies the location shown as (c) in Figure 5-4, which has model offset 3. When you do this, you'll see that you have two selection rectangles, which cover only the characters that are actually selected in the model, as shown in Figure 5-8. This is, of course, the correct result. You'll see, in implementation terms, why this actually happens in the next section. Figure 5-8. A selection in bi-directional text. How Bi-Directional Text Is Handled in the Swing Text Components Now that you've seen the practical implications of using bi-directional text, this section looks at how the Swing text components represent bi-directional text internally and how the API is affected by the need to handle it. Representation of Bi-Directional Text within AbstractDocument The first thing to know about bi-directional text is that it does not have any special representation when stored in the Document model. The text components store Unicode and, because the Arabic character set (and other character sets that need to be rendered right to left) is just a subset of Unicode, the characters are stored directly in the model in the same way as the more familiar left-to-right text. The key to understanding how bi-directional text works is the Element framework that was introduced in Chapter 3. If you refer to the section entitled "The Element Structure of the Simple Text Components" in Chapter 3, you'll recall that a text component's data is logically grouped into sections using Elements that form a tree structure. In Chapter 3, we looked exclusively at the Elements that describe the line and paragraph structure of the data together with any attributes that might be attached to it. There is, however, a parallel Element structure that maps the same data content and has a separate root within the Document. To see how this second tree is constructed, type the following command: java AdvancedSwing.Chapter5.BidiTextExample and look at the output that appears in the window in which you run the example. Core Note If you are running this example in a DOS window, you may need to redirect the output to a file because it will probably run off the top of the window. If you do this, let the program run for 10 seconds before looking at the output file, because it waits 10 seconds before writing the document structure to the file.
The output from this command shows both the Document structure and the Views that are created for display purposes. Here, we are only interested in the Document structure, which is reproduced here. <section> <paragraph resolver=NamedStyle:default {name=default,nrefs=1} > <content> [0,5][A???Z] <content> [5,6] [ ] <bidi root> <bidi level bidiLevel=0 > [0,1][A] <bidi level bidiLevel=1 > [1,4][???] <bidi level bidiLevel=0 > [4,6] [Z ] The first part of this output shows the usual Document structure that you saw in Chapter 3. As you might expect for a JTextPane with one line of text and no attributes, all you get is a Section Element containing a single Paragraph Element that has two associated content Elements one for the data and another for the newline that marks the end of the data. Following this is a second Element structure, beginning with the tag bidi root. Up to now, we have completely ignored the Elements in this tree because we have only been interested in how to build lines and paragraphs and attach attributes that determine the font and colors used to display the text. In fact, these Elements contain the information that describes the orientation of the text independently of its logical structure. In this example, the text consists of the letter a, three Arabic characters, the letter z, and the terminating newline. If you look at the Element structure descending from the bi-directional root, you can see that each Element corresponds to a range of characters that all run in the same direction. The first Element maps the letter A that has left-to-right orien-tation, the second maps the three right-to-left Arabic characters, and the last one contains the left-to-right sequence consisting of the letter z and the newline. You saw in Chapter 3 that you can use the getRootElements method to get an array that holds the root Elements of any Element trees within a Document. AbstractDocument supports two parallel Element structures and therefore its implementation of getRootElements returns an array containing two entries, the first of which is the root of the usual Element tree that describes the content structure and the second is the root of the bi-directional text tree: JTextPane tp = new JTextPane(); // Add text and attributes (not shown here) Document doc = tp.getDocument(); Element[] rootElements = doc.getRootElements(); Element bidiRootElement = rootElements[1]; // Root of bidi Element tree Another way to get the root of the bi-directional Element tree is to use the getBidiRootElement method: JTextPane tp = new JTextPane(); // Add text and attributes (not shown here) AbstractDocument doc = (AbstractDocument)tp.getDocument(); Element bidiRootElement = doc.getBidiRootElement() // Root of bidi Element tree Notice that the second code extract casts the returned Document reference to an AbstractDocument, whereas the first does not. The Document interface contains a getRootElements method because the generic Document model allows the concept of multiple Element trees but does not specify how they are used. It does not, however, have the concept of bi-directional text, so it doesn't supply a getBidiRootElement method. To get the notion of bi-directional text, you have to use a concrete implementation of Document derived from AbstractDocument, so the second code extract casts the returned Document reference accordingly. Both of these code extracts are, of course, assuming that the JTextPane has been built with a model that is a subclass of AbstractDocument the first extract assumes this, even though it doesn't use a cast, because it knows that the array returned by the getRootElements method has at least two entries and that the second entry is for the bi-directional text Element tree. The bi-directional Element tree is made of objects of type Abstract-Document.BidiElement, which are derived from AbstractDocument.Leaf Element. BidiElements are leaf elements, not branch elements, because they do not need to be nested. As a result, the bi-directional Element tree is only a single level deep and each entry in the tree maps all of a single range of the Document. In the example shown earlier, there are three BidiElements, two of which cover the left-to-right text at the beginning and end of the Document and a third covering the right-to-left section in the middle. A BidiElement, like all Elements, has an associated AttributeSet, which contains only one attribute called the "bidi level" (see Table 2-1 in Chapter 2 for the definition of this attribute). The value of this attribute is the nesting level of bi-directional text; text with an even nesting level is to be rendered left to right, while an odd level implies right-to-left rendering. In the case of the example that we have been using in this section, the first and last characters have a nesting level of 0, while the Arabic characters are at level 1. However, because BidiElements are not directly concerned with the rendering of the text, it is not possible (or useful) to add other attributes to their AttributeSets. Core Note This simple example shows only two bi-directional levels. However, the Swing text components can support up to 16 levels of nested direction directional changes.
Bi-directional text has a certain amount of overhead in terms of memory and the time taken to determine which parts of a Document should be drawn in which direction. If you don't need to support bi-directional text, you can minimize these overheads by setting the document property i18n to false: JTextPane tp = new JTextPane(); tp.getDocument().putProperty("i18n", new Boolean(false)); Core Note In the Swing I.I.I and the first Java 2 releases, this property is false by default, thus disabling bi-directional text. If you are using either of these releases, you need to set the i18n property to true to enable it The example we have been using in this section displays the initial value of this property when it starts and then switches on bi-directional text support.
Rendering Bi-Directional Text You saw in Chapter 3 that a single Element maps a run of characters with a constant set of character attributes and that the View structure usually contains one View for each leaf Element in the Document model. For simplicity, some Views, such as LabelView, create fragments to restrict themselves to drawing text on only one screen line, an example of which was shown in Figure 3-9. The presence of bi-directional text is another reason for a View to create a fragment and the example that we have been using in this section demonstrates this. If you look at the output in the window from which you run it, you'll see that it displays the View structure of the JTextPane, which looks like this: javax.swing.plaf.basic.BasicTextUI$RootView; offsets [0, 6] javax.swing.text.BoxView; offsets [0, 6] javax.swing.text.ParagraphView; offsets [0, 6] javax.swing.text.ParagraphView$Row; offsets [0, 6] javax.swing.text.LabelView$LabelFragment; offsets [0, 1] [A] javax.swing.text.LabelView$LabelFragment; offsets [1, 4] [???] javax.swing.text.LabelView$LabelFragment; offsets [4, 5] [Z] javax.swing.text.LabelView; offsets [5, 6] [ ] Here you can see the usual structure for a JTextPane, with a single Row fragment nested inside a single ParagraphView. Even though there is enough horizontal space to display the five characters in this Document on one screen line, the LabelView has created three fragments (of type LabelView.Label-Fragment) that correspond to the same line of text. Each of these Views maps a region in which the text flows in only one direction. In fact, if you look at the BidiElements for this Document (shown previously), you'll see that each fragment maps directly to a BidiElement. This happens because LabelView is coded to look at the BidiElement structure as part of the process of determining whether to create a View fragment. Notice that the newline at the end of the Document has its own LabelView, even though it is considered to be left-to-right text like the character z that appears before it in the model. This happens because these two characters are actually mapped by different Elements and so cannot share a View. The reason for this View structure is, of course, that it makes the implementation of LabelView easier. As you saw in Chapter 3, each View independently renders only the part of the text component that it covers. If a single View mapped a run of characters that contained changes of direction, its paint method would need to take into account the direction change boundaries as well as take note of whether some or all of the text is selected and so should use a different foreground color. With this implementation, the paint method only has to deal with left-to-right text or with right-to-left text, not with a mixture. In Chapter 3, you also saw that the paint method of the FieldView used by JTextField uses convenience methods in the javax.swing.text.Utilities class to render text. Currently, JTextField supports only left-to-right text, so it does not have the complications of having to handle text flowing in the reverse direction. LabelView does not have this luxury, however. It has to use a more different text rendering algorithm. In fact, although the details are somewhat complex, the technique used by LabelView in Java 2 is very simple. In Chapter 3, you saw that FieldView obtained a reference to the text from the model that it needs to draw by calling the Document getText method and then calling the Utilities.drawTabbedText method to render it. What LabelView does is slightly different. Core Note In Java 2, LabelView uses some of the facilities of the Java2D API. A proper discussion of these features is beyond the scope of this book. Instead of doubling the size of this chapter with an overview of Java2D text handling, we'll content ourselves here with a simple description of how the Java2D features are used. For a more in-depth description, refer to Core Java 2, Volume 2: Advanced Features by Cay Horstmann and Gary Cornell (Prentice Hall).
In Java 2, when a LabelView is created, it extracts the portion of text that it maps from the Document and builds a separate object that contains the Glyphs that will be drawn for that text on the screen. A Glyph is simply a character from a font. In simple terms, what this process does is to use the Unicode characters from the Document to access the font used over the part of the text component mapped by the LabelView and extract the corresponding Glyphs. These are then organized into an object called a GlyphVector, which can be drawn directly by the Java2D feature of Java 2. There are several complications that can cause the arrangement of Glyphs in the GlyphVector to differ from the Unicode characters held in the Document, of which the following are examples: Adjacent characters may be merged together into a single Glyph. For example, it is common practice to merge the letters "fi" into a single Glyph in which the horizontal bar of the letter "f" joins to the top of the letter "i." In some writing systems, of which Arabic is an example, the Glyph used to represent a character may depend on the characters that it is adjacent to. You can think of this as being somewhat similar to longhand writing, where the exact shape of a character depends on those adjacent to it, because of the need to join the characters up. The merging of the three Arabic characters in our example program into one glyph in the right screen shot of Figure 5-3 is an example of this. The order of Glyphs may be reversed. The last of these examples is actually the way in which LabelView handles right-to-left text when it extracts the characters from the Document, it assembles them in the GlyphVector in reverse order! Having done this, it can simply use the following Graphics2D method to draw the text in the correct order (actually rendering it left to right): public void drawGlyphVector(GlyphVector g, int x, int y); Core Note In Swing I.I.I, there is no support in LabelView for bi-directional text. All text is rendered left to right, using the same drawTabbedText method used by FieldView.
Views and Position Bias Earlier in this section, you saw that mapping between model and View positions when there is bi-directional text present is not a simple matter. At the boundaries where the direction change takes place, it is apparently possible to assign two model offsets for the corresponding View location (and vice versa), while in a right-to-left run of characters, the model offsets decrease as the View offset increases. Having two possible model offsets for a single View offset is not very convenient because the View modelToView method can only return a single offset and the same is true of viewToModel. To solve this problem, the text components have the notion of bias. To understand how bias is used to select a single offset at a bi-directional text boundary, look at the situation shown in Figure 5-9. Figure 5-9. Using bias to select an unambiguous location in a text component. This diagram is another representation of a JTextPane with three right-to-left characters surrounded by the more usual left-to-right text flow. The top of the diagram shows the model representation in logical order, while the bottom shows how these characters would be rendered in Java 2. For clarity, small gaps have been left at the direction change boundaries and arrows have been used to show the direction of the text flow. The diagram clearly shows how the model locations map to View offsets. Consider the location just after the letter A in the model. Conventionally, this location would be called model offset 1 but, as you can see, because of the bi-directional text, it may map to View offset 1 or to View offset 4. In fact, the way to obtain an unambiguous View offset is to qualify the model offset by specifying whether you are referring to the end of the previous character in the model or the beginning of the next. This is done by using a bias value, which may take the value forward or backward. In Figure 5-9, the location just after the a is labeled offset 1, backward. This model offset maps to View position 1. By contrast, the position just before the right-to-left character shown here as 1 is labeled offset 1, forward and has View offset 4. As you can see, the combination of a model offset and a bias leads to a unique View position. In implementation terms, the concept of bias is provided by the inner class Bias of the javax.swing.text.Position class, which, as you saw in Chapter 1, is used to anchor a logical location within a document so that its model offset can be retrieved at a later time. The Position.Bias class simply declares two constants that are used to refer to forward and backward bias: public static final Bias Forward; public static final Bias Backward; Forward bias (or Bias.Forward) is used when you want to refer to the right side of a model location at which there is a change in the direction of text flow, as you can see from Figure 5-9. In this context, because we are referring to the model and dealing with logical ordering, the term right side is not ambiguous. To see how bias is used in practice, consider the implementation of a View's modelToView method. If you refer to Table 3-2, you'll see that this method has two variants, defined as follows: public abstract Shape modelToView(int pos, Shape a, Position.Bias b) throws BadLocationException public Shape modelToView(int p0, Position.Bias b0, int p1, Position.Bias b1, Shape a) throws BadLocationException Let's look at the first of these two methods, which maps a single model position to a Shape whose bounding rectangle occupies the corresponding location on the screen. As you saw in Chapter 3, the standard implementations of this method return a Rectangle of width 1, whose height matches that of the space allocated to the View and whose horizontal position corresponds to the screen location of the character at the given model offset. Suppose that, in the case of the text component represented by Figure 5-9, this method were called with offset 1, which is the first boundary at which a change of text direction occurs. As you know, for this component the mapping from model offset 1 to a View position is ambiguous unless a bias value is also supplied. If the bias argument passed to modelToView in this case is Bias.Backward, the Shape returned by this method will be a Rectangle whose left edge lies at the boundary between the characters A and 3 in the representation of the View shown at the bottom of the figure. On the other hand, if the bias argument is given as Bias.Forward, the returned Shape will correspond to the location between the characters 1 and z. The situation is similar for the reverse mapping, which is performed by the viewToModel method: public abstract int viewToModel (float x, float y, Shape a, Position.Bias[] biasReturn); Here, the x and y values give the location of a point within the text component and the returned value is the corresponding model offset. Looking again at Figure 5-9, as you know there would be an ambiguity if the View position passed to this method corresponded to either of the locations at which the text changes direction. If, for example, the user clicked in the gap between the A and the 3, should the returned offset be 1 or 4? We actually tried this earlier in this chapter and discovered that the result was 4. As well as the offset, this method also returns, in the biasReturn array passed as the last argument, the corresponding bias value that, taken together with the returned model offset, would produce the same View location if they were both supplied to the modelToView method. In this case, the returned offset would be 4 and the returned bias Bias.Backward. Core Note A return offset of 4 with Bias.Forward would correspond to the forward (that is, the right-hand) side of the gap at the change of text direction that is, the location between the 1 and the z in Figure 5-9.
You should be able to see straight away that the returned model offset and bias are consistent with the initial View location. However, the same View position could also have been described as having model offset 1 with bias value Bias.Backward that is, the location immediately after the character A. Why was the offset 4 chosen? The reason for this is simple. When the user clicks over a text component, the x and y coordinates from the MouseEvent are used to find the single leaf View at that location. In this case, there are two possible Views that could correspond to this location the one mapping the character A and the adjacent one mapping the reverse text characters 1 through 3. If the exact location of the click matches the first of these Views, it will see the event as having occurred at its right boundary. This would give a model offset of 1 with Bias.Backward. On the other hand, if the event occurs within the boundary of the other View, it will be seen as having happened at its left end and will produce a model offset of 4 with bias Bias.Backward. Notice that in both of these cases, the bias returned is Bias.Backward. The viewToModel method returns Bias.Backward whenever the point it is given is at the right end of the portion of the model that it represents, speaking in terms of logical ordering, and Bias.Forward in all other cases. In the case of right-to-left text, the right end of the logical ordering (shown at the top of Figure 5-9) is, of course, the left side as seen in visual order (the lower part of the figure). It is worth noting that in this section we have been discussing the modelToView and viewToModel methods of the View class. Views are,of course, objects that are internal to a Swing text component and usually an application would not be aware of their existence, much less try to invoke their methods. Should an application want to map between model and View locations, it would use the modelToView and viewToModel methods of JTextComponent, which are defined as follows: public Rectangle modelToView(int pos) throws BadLocationException; public int viewToModel(Point pt); The interesting point about these methods is that neither of them concerns itself with the issue of bias. We know that this cannot yield an unambiguous result unless some convention is used to choose between the two possible mappings that can occur in the boundary cases. In fact, if you use the modelToView method, the bias is taken to be Bias.Forward. In the case of viewToModel, the underlying View will return the appropriate bias, but there is no way to communicate it to the application. Therefore, viewToModel may not give expected results if used on a boundary between different text flow directions. The Caret You saw in "Caret Position and the Selection" that both the movement and the appearance of the Caret are affected by the presence of bi-directional text. Now that you've seen some basic implementation of bidirectional text, we'll look a bit more closely at the details of the Caret handling in the presence of mixed left-to-right and right-to-left text. In Chapter 3, we said that moving the Caret left and right (or up and down in a two-dimensional text component) is not simply a matter of changing its x (or y) coordinate by a fixed amount each time an arrow key is pressed, or even as simple as adjusting a coordinate by the width of the character that is passing over. As an example of this, the custom View that was implemented in Chapter 3 included characters that were not in the model; moving the Caret left and right through a View that contains virtual characters like these involves skipping over the virtual text that is not actually in the model. In fact, what exactly needs to happen to do something as simple as move the Caret one position in any direction depends entirely on the View that is responsible for drawing the text that the Caret is moving through. This is why Views implement a getNextvisualPositionFrom method, which is defined like this: int getNextvisualPositionFrom(int pos, Position.Bias b, Shape a, int direction, Position.Bias[] biasRet, boolean rightToLeft, int startOffset, int endOffset) throws BadLocationException The meaning of the arguments should be obvious. The pos argument is the current model position of the Caret; as you might expect by now, it is qualified by a bias. The Shape argument represents the area of screen allocated to the text component. The direction indicates which way the Caret needs to move (north, south, east, or west) and depends on which arrow key was pressed. The rightToLeft argument is true when the text associated with the View is to be rendered from right to left and the two offsets are the bounding offsets of the region of the model mapped by this View. The return value is the offset in the model that represents the next position that the Caret should occupy given the direction in which it was asked to move; this value is qualified by the bias value returned in the biasRet argument, in the same way as positions returned by the viewToModel method discussed in the last section require both a model offset and a returned bias to completely describe them. Let's consider first a simple case. Suppose, in Figure 5-9, the Caret is currently placed between the characters 3 and 2. Relating the visual representation at the bottom of the diagram to the logical representation at the top, you can see that this means that the Caret is currently at model offset 3 and has bias Bias.Forward. Core Note When the Caret is not at a boundary at which a direction change occurs, its bias is arbitrarily considered to be forward. Because a View never crosses a direction change boundary, the bias of the Caret is always forward except when the Caret is at the end offset of the View, at which point it may have a backward bias. However, if the end of the View does not correspond to a change in direction flow (perhaps because some attribute such as the font changed or the end of the screen line was reached), the Caret will still have forward bias there.
Now suppose the user presses the right arrow key. The expectation is that the Caret will move to the right. In response to this action, the getNextVisualPosition method of the LabelView mapping the Arabic text will be called, with the model offset initialized to 3, the bias set to Bias.Forward, the direction set to East, and the rightToLeft set to true. Under normal circumstances, you would expect pressing the right arrow to increase the model offset by one. When there is a rightToLeft text flow, however, this does not happen instead, the model offset is decreased by one, in this case giving it the value 2. If you refer again to the top half of Figure 5-9, you'll see that this places it between the 2 and the 1. Relating this to the visual representation at the bottom of the figure, it is clear that this corresponds to a movement to the right. Furthermore, because the Caret has not yet reached the end of the area mapped by this View (which spans model offsets 1 to 4), its bias remains forward. Thus, in this case, getNexVisualPosition returns the value 2 and the biasRet value is set to Bias.Forward. Similarly, when there is right-to-left text, pressing the left arrow key causes the model offset to be increased by one instead of being decreased, as would be the case in a left-to-right flow. The Selection When the user clicks and drags left or right to create a selection, the Caret is responsible for setting the values of its dot and mark attributes to record the endpoints of the selected region. These values are model offsets, so you won't be surprised to discover that both the dot and mark actually store both a model offset and the corresponding bias. When the user begins a selection, the dot and mark, which are attributes of the Caret (in this case implemented by the DefaultCaret class), are both set to the model offset and bias returned by the viewToModel method of the View underneath the mouse location. To illustrate the discussion with some typical values, let's look again at the JTextPane example that we've been using throughout this section. Start the program using the command java AdvancedSwing.Chapter5.BidiTextExample and click to the left of the character A, thus starting a new (empty) selection. As you've already seen, with the mouse in this location, the viewToModel method will return a model offset of 0 with a bias of Bias.Forward. Now drag the mouse to the right until the Caret is between the second and third characters (reading from left to right); at this point, the text component should look like Figure 5-8. As the mouse was dragged, the viewToModel method was called in response to each MouseMotionEvent to get the location and bias for the changing dot attribute. At the end of the operation, the dot will be at model offset 3 with bias Bias. Forward while the mark, which denotes the other end of the selection, has model offset 0 and bias Bias.Forward. As we saw earlier in this section, the interesting thing about this example is that the selection is displayed as two separate highlighted regions, reflecting the actual characters from the model that are selected. The Highlighter that is supplied with the Swing text package, however, can highlight only a single rectangular region. So how does this work? The key to understanding how this works is to realize that there are actually two Views involved in rendering the characters that are part of the selection in this example the LabelView.LabelFragment mapping the left-to-right character A and another one covering the right-to-left Arabic characters. Because the default Highlighter is a layered Highlighter, each View is responsible for rendering its own part of the selection highlight. Therefore, the first View highlights the character A, which is its part of the selection, while the second one needs to highlight the Arabic characters at model offsets 1 and 2. As you saw in Chapter 3, layered highlights are drawn using the paintLayer method of the LayeredPainter responsible for the highlight. In this case, the default layered highlight painter supplied with Swing is being used. The paintLayer method of this object works by taking two model offsets that bound the highlight and the Shape allocated to the View it is rendering on and calls the View's modelToVxiew method, from which it gets a Rectangle that represents the screen area appropriate for the highlight. Because the View in this case is LabelView.LabelFragment, which is aware of bi-directional text, the returned Rectangle will occupy the right end of the View's screen area, so the second part of the selection will be drawn there. As well as user-generated selections, it is possible to create a selection programmatically using the JTextComponent select method, or as a two-step process using setCaretPosition followed by moveCaretPosition. All these methods require a model offset, but none of them accept a Position.Bias argument. In fact, when you use these methods, the start offset is implicitly given the bias Bias.Forward and the end offset uses Bias.Backward. The same is true of the Caret setDot and moveDot methods, which can also be used to specify a selection. Similarly, when you retrieve the model locations of the boundaries of the selection, the start and end offsets have the same implicit bias values. Core Note Code within the Swing text package is not restricted in this way, however, because the DefaultCaret class has variants of the setDot and moveDot method that accept a model offset and a bias as argument and methods called getDotBias and getMarkBias that return the bias values of the two extremes of the selection. These are of no use to an application programmer, however, because they are package private and, hence, not accessible outside the text package.
|