Custom Views and Input Fields The ExtendedParagraphview that you saw earlier in this chapter was relatively simple, but it allowed us to look at the steps needed to add custom rendering to a text component. Now that you've seen the basic principles, in this section you'll see how to apply them to create a specialized input field that can be used to provide visual cues to the user as to what the format of the data being input into the field should be. Although the component that we'll create will be fairly general in scope, to stay focused on what we are trying to achieve, we'll use a particular application of this input field when describing the implementation. Our aim will be to produce a text component that can accept a telephone number of fixed length as its input. The feature of this component that requires a custom View is the fact that it will display the characters in the telephone number together with characters added to make the user's input look like a telephone number, even though those extra characters will not be stored in the text field and will not be returned to the application program when it uses the getText method to extract the text field's contents. Using a View is the natural way to achieve this kind of effect, because what we are trying to do is present some data to the user in a natural way, without changing the nature of the data. In many ways, you can consider a View to be analogous to the renderers that are used by other Swing components like JTree, JTable, Jlist, and JComboBox. Views are a little more complex to create, but not unacceptably so. The Formatted Text Field Creating a new View that renders the content of a text field in a particular way is not the only thing you have to do to make the View useful. As you saw when we looked at the ExtendedParagraphview, the View needs a viewFactory that will create instances of it as appropriate. The viewFactory is provided either by a text component's editor kit or by its UI delegate class, so it follows that we'll need to customize one or other of those as well. Furthermore, if the View needs to be configured in any way for particular circumstances, we'll probably need a new text component with methods that can be used to pass the configuration information to the View and we might even need to use a specialized Document to impose constraints on the data that the user can supply, if any are needed. Our formatted text field will be a subclass of JTextField, called FormattedTextField, to which the programmer can attach some formatting instructions that control how the characters that the user types should be displayed. The job of the View will be to use these instructions when the text field's content is painted on the screen. For example, if the text field were to be used for the input of a telephone number, you might want the phone number with digits 1234567890 to be displayed as follows: (123)-456-7890 whereas a field used to display a stock code number would need the following format for the same number: 12-345-6-7890 The characters that have been added to make the value more readable to the user supplying the input will not be stored in the model because they are of no use to the application that will eventually use them, perhaps to dial a modem or to look up the associated stock item in an orders database. These characters are provided to the text field as a configurable property that can be set by the programmer. To keep this example simple, we'll assume that the characters appear in the same order in both the model and when being displayed. However, with a little more work, you could modify this example to make it possible to specify a more complex mapping between the model and the View. The simplest way to specify the manner in which the data should be displayed is to use a String in which a particular character represents a character from the model. For example, if the character * were used for this purpose, the two display formats shown earlier might be specified as follows: (***)_***_**** **_***_*_**** This has the drawback that whichever character is chosen as a place marker for the model content could not appear in the formatted string. So instead of taking this simple approach, we'll use a slightly more complex representation that adds a mask to the formatting specification. The mask takes over the job of specifying where the model data should appear. With this approach, the telephone number field might have the following format and mask fields, where the formatting field is shown first: (...)-...-.... (***)_***_**** Wherever the * character appears in the mask field, the corresponding character in the format string will be replaced with the character from the model. When the text field has no real data in it, the format string is copied directly to the screen, so you can use the positions that will be filled with model data to give visual cues to the user as to where the characters being typed will appear. In the example shown above, the places reserved for the digits of the telephone number will be filled with periods. By contrast, the characters in the mask that are not in the * locations are not important they just have to be there to align the * characters properly. Because we need to specify two character strings to define the way in which the text in the input field will be formatted, we'll create a dedicated class that contains both strings and, because this class is only of use with this text field (or subclasses thereof), we'll define it as an inner class of FormattedTextField. The implementation of FormattedTextField and the inner class, called FormatSpec, is shown in Listing 3-7. Listing 3-7 A Formatted Input Field package AdvancedSwing.Chapter3; import javax.swing.*; import javax.swing.text.*; import java.awt.*; import AdvancedSwing.Chapter2.BoundedPlainDocument; public class FormattedTextField extends JTextField { public FormattedTextField() { this(null, null, 0, null); } public FormattedTextField(String text, FormatSpec spec) { this(null, text, 0, spec); } public FormattedTextField(int columns, FormatSpec spec) { this(null, null, columns, spec); } public FormattedTextField(String text, int columns, FormatSpec spec) { this(null, text, columns, spec); } public FormattedTextField(Document doc, String text, int columns, FormatSpec spec) { super(doc, text, columns); setFont(new Font("monospaced", Font.PLAIN, 14)); if (spec != null) { setFormatSpec (spec); } } public void updateUI() { setUI(new FormattedTextFieldUI() ) ; } public FormatSpec getFormatSpec() { return formatSpec; } public void setFormatSpec(FormattedTextField.FormatSpec formatSpec) { FormatSpec oldFormatSpec = this.formatSpec; //Do nothing if no change to the format specification if (formatSpec.equals(oldFormatSpec) == false) { this.formatSpec = formatSpec; // Limit the input to the number of markers. Document doc = getDocument(); if (doc instanceof BoundedPlainDocument) { ((BoundedPlainDocument)doc).setMaxLength( formatSpec.getMarkerCount()); } // Notify a change in the format spec firePropertyChange(FORMAT_PROPERTY, oldFormatSpec, formatSpec); } } // Use a model that bounds the input length protected Document createDefaultModel() { BoundedPlainDocument doc = new BoundedPlainDocument(); doc.addInsertErrorListener( new BoundedPlainDocument.InsertErrorListener() { public void insertFailed(BoundedPlainDocument doc, int offset, String str, AttributeSet a) { // Beep when the field is full Toolkit.getDefaultToolkit().beep(); } }); return doc; } public static class FormatSpec { public FormatSpec(String format, String mask) { this.format = format; this.mask = mask; this.formatSize = format.length(); if (formatSize != mask.length()) { throw new IllegalArgumentException( "Format and mask must be the same size");} for (int i = 0; i < formatSize; i++) { if (mask.charAt(i) == MARKER_CHAR) { markerCount++; } } } public String getFormat() { return format; } public String getMask() { return mask; } public int getFormatSize() { return formatSize; public int getMarkerCount() { return markerCount; } public boolean equals(Object fmt) { returnfmt != null && (fmt instanceof FormatSpec) && ((FormatSpec)fmt).getFormat().equals( format) && ((FormatSpec)fmt).getMask().equals(mask); } public String toString() { return "FormatSpec with format <" + format +">, mask <" + mask +">"; } private String format; private String mask; private int formatSize; private int markerCount; public static final char MARKER_CHAR = ' * ' ; } protected FormatSpec formatSpec; public static final String FORMAT_PROPERTY = "format"; } Let's first look at FormatSpec. FormatSpec is a simple class that stores the format and masks strings for the text field. The constructor verifies that the two strings are the same length and throws an exception if they are not. This check, although not strictly necessary from a design point of view, simplifies the code in the custom View that works with the format specification, at the possible cost of requiring extra spaces to be provided in the mask or format field if they were, for some reason, not naturally of the same length. Note that the marker character that is used to indicate which positions in the mask should be replaced by characters from the model is fixed. You could make this another parameter to the constructor but, because this character only appears in the mask and not in the string drawn on the screen, there is little to be gained by doing this and it would add extra complication to the View class. FormatSpec defines accessors for the format and mask fields and a method that counts the number of marker positions in the mask. There's also an implementation of the equals method (inherited from Object) that allows two FormatSpec objects to be compared. As you might expect, a pair of FormatSpecs are considered equal if they have the same format string and the same mask string. You'll see how these methods are used later The FormattedTextField class is also very simple. It is derived from JTextField, so it has all the normal text field methods and its constructors allow access to all the constructors of its superclass. With the exception of the default constructor, however, they all require a FormatSpec to be specified. In fact, the FormatSpec can be given as null, in which case FormattedTextField will behave as an expensive version of JTextField. The FormatSpec supplied to the constructor is applied using the setFormatSpec method, which can also be called directly if the default constructor was used or in the unlikely event that the format or mask string needs to be changed after the text field has been created. This method does two important things. First, it counts the number of markers in the mask. This is necessary to limit the number of characters that the user can type into the text field to the same number as there are markers. Because characters that do not correspond to markers will not be displayed, it would be confusing to user if they were allowed to continue typing once all the marker slots in the input field were filled. In the telephone number example shown earlier, for example, there are 10 markers, allowing a 10-character telephone number to be displayed. Once the user has typed 10 characters, no more will be displayed (and no more are valid), so they should be ignored and, preferably, the user should get feedback to indicate this. To enforce this restriction, FormattedTextField overrides the JTextComponent createDefaultModel method and installs a BoundedPlainDocument, the implementation of which you saw in Chapter 1, as its model. When the FormatSpec is configured, the number of markers in the mask is used to set the number of characters allowed in the model, as you can see from the implementation of the setFormatSpec method. An error handler is also installed in the model so that the user will hear a beep if too many characters are typed. The second function of setFormatSpec is to fire a PropertyChangeEvent when the FormatSpec is installed for the first time or if it is changed to a new value. To ensure that the event is fired only if the format is actually changing, the new and old values are compared using the equals method of FormatSpec, which returns false if neither the format string nor the mask have changed. If a genuine change has occurred, a PropertyChangeEvent is sent to all registered listeners, notifying both the new and old values. This behavior is very common in Swing components. One reason for doing this is to make it easier to treat FormattedTextField as a Java-Bean and configure it from a integrated development environment (IDE) or application builder, although to support this properly you would have to add a customizer class that allowed the IDE to configure the FormatSpec value. In the case of this component, the more important motivation for this event is to notify its ViewFactory that the FormatSpec has been changed, as you'll see shortly. One other detail to notice is the fact that the FormattedTextField constructor installs a monospaced font by default. Using a monospaced font in place of a proportional font in this type of control is preferable, because it stops the fixed elements of the fields content moving around as the user types. Returning to the example of the telephone number, if the positions that will be occupied by digits of the telephone number are initially set to "." as shown previously, the string displayed in the field will initially be very narrow if a proportional font is used, because a period takes up very little space. As the user types, the periods will be replaced by wider characters and the field content will expand. If a constant width font is used, the total width of the input string will be the same no matter how many characters the user has typed, which is more natural. You can, of course, override the initial choice of font if you wish by installing your own using the setFont method inherited from Component. The ViewFactory As you know, there are two places that a text component might find a viewFactory either in its editor kit or in its UI delegate class. Because it is derived from JTextField, FormattedTextField will be created with an instance of DefaultEditorKit, which does not supply a ViewFactory so, like JTextField, it would get its ViewFactory from its UI delegate. While we could create and install a subclass of DefaultEditorKit that included a ViewFactory suitable for FormattedTextField, much as was done (with StyledEditorKit) for the customized ParagraphView you saw in the last section, in this case we'll take the opportunity here to show you how to create a custom ViewFactory within a text component's UI delegate. Being derived from JTextField, FormattedTextField would naturally be given whichever UI delegate the selected look-and-feel would install for JTextField. To install a different UI delegate, you have two choices: -
Change the UIDefaults table for the installed look-and-feel to install an instance of your UI delegate for every FormattedTextField. -
Explicitly install an instance of the UI delegate by overriding the updateUI method that FormattedTextField inherits from JTextField. Either of these techniques will work and there is very little to choose between them, so we arbitrary elect to use the second. If you look at Listing 3-7, you'll see that the updateUI method creates an instance of a class called FormattedText-FieldUI and installs it as the UI delegate. This method is called whenever the selected look-and-feel is changed. As you can see, this will ensure that our private UI delegate is installed whichever look-and-feel is selected. Because the UI delegate will contain the ViewFactory, it is important that changing the look-and-feel does not result in a different delegate being installed, because the behavior of the FormattedTextField would revert to that of JTextField if this were to happen. Placing the viewFactory in the UI delegate is relatively simple, as you'll see, but, because the selected UI delegate is now independent of the selected look-and-feel, any look-and-feel specific behavior of JTextField will be lost. Our implementation will use the UI delegate from the Metal look-and-feel. This is a good choice, because Metal is always present when Swing is installed; if we had chosen instead to extend the Windows UI delegate, you would only be able to use the FormattedTextField on Windows platforms. An alternative solution is to subclass BasicTextFieldUI, which is the superclass of all the UI delegates used for JTextField. This class is, like the Metal UI delegate, always installed. This wouldn't cost very much in terms of loss of functionality by comparison to using the Metal UI delegate, because the only thing that Metal adds to BasicTextFieldUI is setting a different background color depending on whether the text control is editable. In fact, there isn't very much difference in the behavior of a simple text field whichever look-and-feel is being used. The Windows UI delegate selects the field content when the text field gets the focus and both Windows and Motif use slightly different Caret implementations. In the unlikely event that these differences are critical to your application, you might prefer the approach of customizing the editor kit instead. To implement a custom ViewFactory, all we need to do is override the create method, which is inherited from BasicTextFieldUI. Formatted-TextField will use the same basic View hierarchy as JTextField, which was shown in Figure 3-6, except that the Fieldview used by JTextField will be replaced by a custom View that we'll call FormattedFieldView. The code for the create method is shown in Listing 3-8, along with the rest of the UI delegate implementation. Listing 3-8 The FormattedTextField UI delegate package AdvancedSwing.Chapter3; import javax.swing.*; import javax.swing.text.*; import javax.swing.plaf.*; import javax.swing.plaf.metal.*; import java.beans.*; public class FormattedTextFieldUI extends MetalTextFieldUI implements PropertyChangeListener { public static ComponentUI createUI(JComponent c) { return new FormattedTextFieldUI(); } public FormattedTextFieldUI() { super(); } public void installUI(JComponent c) { super.installUI(c); if (c instanceof FormattedTextField) { c.addPropertyChangeListener(this); editor = (FormattedTextField)c; formatSpec = editor.getFormatSpec(); } } public void uninstallUI(JComponent c) { super.uninstallUI(c); c.removePropertyChangeListener(this); } public void propertyChange(PropertyChangeEvent evt) { if (evt.getPropertyName().equals( FormattedTextField.FORMAT_PROPERTY)) { // Install the new format specification formatSpec = editor.getFormatSpec(); // Recreate the View hierarchy modelChanged(); } } // ViewFactory method - creates a view public View create(Element elem) { return new FormattedFieldView(elem, formatSpec); } protected FormattedTextField.FormatSpec formatSpec; protected FormattedTextField editor; } Note that the UI delegate registers itself to receive PropertyChangeEvents from its host FormattedTextField when it is installed and removes itself from the listener list when it is uninstalled. This allows it to receive notification of changes to the FormatSpec, which would affect the way in which the fields contents should be drawn. When this event is received, the new FormatSpec is retrieved and stored. Because the View needs to know the FormatSpec, when a change occurs it is necessary to inform the View. The simplest way to do this is to recreate the complete View hierarchy by calling the modelChanged method, which is inherited from BasicTextUI. This method is usually called when a new Document is installed (not in response to content insertion or removal which are notified directly to the View). The modelChanged method creates a new View hierarchy to replace any existing one. During this process, the FormattedTextFieldUI create method will be called and a FormattedFieldview with the new FormatSpec will be created. This is, in fact, the same mechanism that builds the initial View hierarchy for any text component. In this case, of course, the hierarchy is very flat, consisting only of the standard Rootview and the custom FormattedFieldview. In most cases, the FormatSpec will be set when the component is created and never changed, so this process will only happen once. A Custom FieldView FormattedFieldView will, not surprisingly, be derived from FieldView. To do its job, this view (like all Views) requires a reference to the Element that it will map and also to the FormatSpec that it will use to determine how the content should be displayed. As you saw in the implementation of the ViewFactory in Listing 3-8, references to both of these are available when the View is created and are passed as arguments to its constructor. The custom paragraph View that you saw in the previous section was relatively simple it didn't have to override many of the View methods because the implementations it inherited from Paragraphview were suitable and did not need to be extended or modified. This time, though, we are not going to be so lucky. Our View will have to take full responsibility for the following: Determining its preferred width and height. Drawing itself onto the screen. Mapping a position in the View to the corresponding location in the model. Mapping a model position to the location within the View at which it is drawn. Returning the appropriate preferred width and height means overriding the getPreferredSpan method. We can't use the implementation of this method provided by FieldView because it assumes that the View is displaying exactly what is in the model and computes the required width accordingly. We can, however, delegate to the FieldView for the height calculation. For similar reasons, the FieldView paint method is not directly usable. In fact, the paint method is, at least logically, where most of the differences between FieldView and FormattedFieldView appear because the reason for implementing FormattedFieldView is simply to render the model content differently than it is by FieldView. In fact, as you'll see, the FormattedFieldView paint method is very simple most of the code that is specific to FormattedFieldView appears in other methods, inherited from FieldView and from its superclass Plainview, that are called from within the paint method. The mapping between model and view locations (and vice versa) is done in the modelToView and viewToModel methods. FieldView provides implementations for both of these methods, but we can't use them because we will be adding characters from the format string that don't appear in the model so, for example, in the case of the telephone field example, if the text field looks like this: (789)-012-3456 and the user clicks between the digits 1 and 2, the viewToModel method should return the value 5, because the cursor will be occupying position 5 in the model, even though it is in position 8 on the screen. Performing this mapping requires access to the FormatSpec, which indicates how the characters on the screen map to those in the model. A similar process is performed to map from a model location to the place in the View where that character will be displayed. Initialization and State The complete implementation of the FormattedFieldview is shown in Listing 3-9. As you can see, this is quite a bit more complex than the last example we looked at, so we'll examine the code in pieces, starting with the constructor. As you already know, the constructor is passed a reference to the Element that the View will map and the FormatSpec to be used. The Element reference is saved for later use, but the FormatSpec is not saved because it is more useful, for performance, reasons, to extract information from it that can be used directly as needed. The constructor allocates three Segment objects, which will be used as follows: | contentBuff | Used to hold the content of the text field as it will be displayed. Initially, this contains the format field from the FormatSpec; as the user types characters into the model, they will be transferred into this buffer in the correct locations as determined by the mask field. | | measureBuff | This segment points to a character array that is used in the process of determining the desired width of the text component. | | workBuff | This object is a scratch area that points to a region of the text field while it is being painted. You'll see exactly how this object is used when the painting mechanism is described. | A Segment object maps a portion of a character array, a reference to which is held in its array member. The offset and count fields indicate a contiguous region of the character array that typically corresponds to a range of positions within the text component's model. Directly creating a Segment object, as shown in the FormattedFieldview constructor, allocates the Segment object but not the character array, which is logically separate from the Segment. The three Segments created in the constructor, therefore do not initially point to any associated data. There are two ways to connect a Segment to some data: -
Directly set the array, offset, and count members to point to some portion of an existing character array. -
Call the Document getText method with an offset, length, and Segment object as arguments. When you use the second of these methods, you cannot make any assumptions about the returned value of the offset argument in the Segment object. Even if you ask for a part of the document starting at offset 0, you cannot assume that the offset value in the Segment object will be returned as 0. Furthermore, for efficiency, whenever possible the getText method initializes the Segment object to point directly into the content of the model, so the returned character array should be considered to be read-only. In this example, you'll see cases in which the Segment is initialized by calling getText and other instances in which the Segment is manually set to point to a character array that is not part of the document model. Listing 3-9 A Custom Text FieldView package AdvancedSwing.Chapter3; import javax.swing.text.*; import javax.swing.event.*; import java.awt.*; public class FormattedFieldView extends FieldView { public FormattedFieldView(Element elem, FormattedTextField.FormatSpec formatSpec) { super(elem); this.contentBuff = new Segment(); this.measureBuff = new Segment(); this.workBuff = new Segment(); this.element = elem; buildMapping(formatSpec); // Build the model -> // view map createContent(); // Update content string } // View methods start here public float getPreferredSpan(int axis) { int widthFormat; int widthContent; if (formatSize == 0 || axis == View.Y_AXIS) { return super.getPreferredSpan(axis); } widthFormat = Utilities.getTabbedTextWidth(measureBuff, getFontMetrics(), 0, this, 0) ; widthContent = Utilities.getTabbedTextWidth(contentBuff, getFontMetrics(), 0, this, 0); return Math.max(widthFormat, widthContent); } public Shape modelToView(int pos, Shape a, Position.Bias b) throws BadLocationException { a = adjustAllocation(a); Rectangle r = new Rectangle(a.getBounds()); FontMetrics fm = getFontMetrics(); r.height = fm.getHeight(); int oldCount = contentBuff.count; if (pos < offsets.length) { contentBuff.count = offsets[pos]; } else { // Beyond the end: point to the location // after the last model position. contentBuff.count = offsets[offsets.length - 1] + 1; } int offset = Utilities.getTabbedTextWidth(contentBuff, metrics, 0, this, element.getStartOffset()); contentBuff.count = oldCount; r.x += offset; r.width = 1; return r; } public int viewToModel(float fx, float fy, Shape a, Position.Bias[] bias) { a = adjustAllocation(a); bias[0] = Position.Bias.Forward; int x = (int)fx; int y = (int)fy; Rectangle r = a.getBounds(); int startOffset = element.getStartOffset(); int endOffset = element.getEndOffset(); if (y < r.y || x < r.x) { return startOffset; } else if (y > r.y + r.height || x > r.x + r.width) { return endOffset - 1; } // Given position is within bounds of the view. int offset = Utilities.getTabbedTextOffset(contentBuff, getFontMetrics(), r.x, x, this, startOffset); // The offset includes characters not in the model, // so get rid of them to return a true model offset. for (int i = 0; i < offsets.length; i++) { if (offset <= offsets[i]) { offset = i; break; } } // Don't return an offset beyond the data // actually in the model. if (offset > endOffset - 1) { offset = endOffset - 1; } return offset; } public void insertUpdate(DocumentEvent changes, Shape a, ViewFactory f) { super.insertUpdate(changes, adjustAllocation(a), f) ; createContent(); // Update content string } public void removeUpdate(DocumentEvent changes, Shape a, ViewFactory f) { super.removeUpdate(changes, adjustAllocation(a), f); createContent(); // Update content string } // End of View methods // View drawing methods: overridden from PlainView protected void drawLine(int line, Graphics g, int x, int y) { // Set the colors JTextComponent host = (JTextComponent)getContainer(); unselected = (host.isEnabled()) ? host.getForeground() : host.getDisabledTextColor(); Caret c = host.getCaret(); selected = c.isSelectionVisible() ? host.getSelectedTextColor() : unselected; int p0 = element.getStartOffset(); int p1 = element.getEndOffset() - 1; int sel0 = ((JTextComponent)getContainer()).getSelectionStart(); int sell = ((JTextComponent)getContainer()).getSelectionEnd(); try { // If the element is empty or there is no selection // in this view, just draw the whole thing in one go. if (p0 == p1 || se10 == sell || inView(p0, p1, sel0, se11) == false) { drawUnselectedText(g, x, y, 0, contentBuff.count); return; } // There is a selection in this view. Draw up to // three regions: // (a) The unselected region before the selection. // (b) The selected region. // (c) The unselected region after the selection. // First, map the selected region offsets to be // relative to the start of the region and // then map them to view offsets so that they take // into account characters not present in the model. int mappedSel0 = mapOffset(Math.max(sel0 - p0, 0)); int mappedSel1 = mapOffset(Math.min(sell - p0, p1 - p0)); if (mappedSel0 > 0) { // Draw an initial unselected region x = drawUnselectedText(g, x, y, 0, mappedSel0); } x = drawSelectedText(g, x, y, mappedSel0, mappedSell); if (mappedSell < contentBuff.count) { drawUnselectedText(g, x, y, mappedSel1, contentBuff.count); } } catch (BadLocationException e) { // Should not happen! } } protected int drawUnselectedText(Graphics g, int x, int y, int p0, int p1) throws BadLocationException { g.setColor(unselected); workBuff.array = contentBuff.array; workBuff.offset = p0; workBuff.count = p1 - p0; return Utilities.drawTabbedText(workBuff, x, y, g, this, p0); } protected int drawSelectedText(Graphics g, int x, int y, int p0, int p1) throws BadLocationException { workBuff.array = contentBuff.array; workBuff.offset = p0; workBuff.count = p1 - p0; g.setColor(selected); return Utilities.drawTabbedText(workBuff, x, y, g, this, p0); } // End of View drawing methods // Build the model-to-view mapping protected void buildMapping( FormattedTextField.FormatSpec formatSpec) { formatSize = formatSpec != null ? formatSpec.getFormatSize() : 0; if (formatSize != 0) { // Save the format string as a character array formatChars = formatSpec.getFormat().toCharArray(); // Allocate a buffer to store the formatted string formattedContent = new char[formatSize]; contentBuff.offset = 0; contentBuff.count = formatSize; contentBuff.array = formattedContent; // Keep the mask for computing // the preferred horizontal span, but use // a wide character for measurement char[] maskChars = formatSpec.getMask().toCharArray(); measureBuff.offset = 0; measureBuff.array = maskChars; measureBuff.count = formatSize; // Get the number of markers markerCount = formatSpec.getMarkerCount(); // Allocate an array to hold the offsets offsets = new int[markerCount]; // Create the offset array markerCount = 0; for (int i = 0; i < formatSize; i++) { if (maskChars[i] == FormattedTextField.FormatSpec.MARKER_CHAR) { offsets[markerCount++] = i; // Replace marker with a wide character // in the array used for measurement. maskChars[i] = WIDE_CHARACTER; } } } } // Use the document content and the format // string to build the display content protected void createContent() { try { Document doc = getDocument(); int startOffset = element.getStartOffset(); int endOffset = element.getEndOffset(); int length = endOffset - startOffset - 1; // If there is no format, use the raw data. if (formatSize != 0) { // Get the document content doc.getText(startOffset, length, workBuff); // Initialize the output buffer with the // format string. System.arraycopy(formatChars, 0, formattedContent, 0, formatSize); // Insert the model content into // the target string. int count = Math.min(length, markerCount); int firstOffset = workBuff.offset; // Place the model data into the output array for (int i = 0; i < count; i++) { formattedContent[offsets[i] ] = workBuff.array[i + firstOffset]; } } else { doc.getText(startOffset, length, contentBuff); } } catch (BadLocationException bl) { contentBuff.count = 0; } } // Map a document offset to a view offset. protected int mapOffset(int pos) { pos -= element.getStartOffset(); if (pos >= offsets.length) { return contentBuff.count; } else { return offsets[pos]; } } // Determines whether the selection intersects // a given range of model offsets. protected boolean inView(int p0, int p1, int sel0, int sell) { if (sel0 >= p0 && sel0 < p1) { return true; } if (sel0 < p0 && sell >= p0) { return true; } return false; } protected char[] formattedContent; // The formatted content for display protected chart] formatChars; // The format string as characters protected Segment contentBuff; // Segment pointing to formatted . // content protected Segment measureBuff; . // Segment pointing to mask string protected Segment workBuff; // Segment used for scratch purposes protected Element element; // The mapped element protected int[] offsets; // Model-to-view offsets protected Color selected; // Selected text color protected Color unselected; // Unselected text color protected int formatSize; // Length of the formatting string protected int markerCount; // Number of markers in the format protected static final char WIDE_CHARACTER = 'm'; } Having allocated the Segment objects, the constructor invokes two initialization methods. The first of these, buildMapping, performs setup tasks that need to be carried out whenever the FormatSpec changes. Because a new FormattedFieldView is created whenever this occurs, this method is actually used only once during the View's lifetime. By contrast the other method, createContent, is called during construction and also every time the models content is changed in any way. Lets look first at buildMapping. This method performs two functions: -
It initializes the Segment objects. -
It uses the FormatSpec object to create a mapping from model position to the location in the View at which the corresponding character should be displayed. The first step is to get the format string from the FormatSpec in the form of a character array and save a reference to it for later use in the formatChars field. This reference will be used in the createContent method as the starting point from which to build the representation of the model as it will appear in the text field. Next, a new character array is allocated to hold the constructed view of the model data and the Segment object contentBuff is initialized to point to it. Initially, this buffer will not have any useful content, but it is large enough to hold the content of the model formatted according to the FormatSpec. The length of this array is the same as the length of the format string (and also the same length as the mask). Having dealt with the formatting string, the next step is to handle the mask. A copy of the mask, in the form of a character array, is obtained from the FormatSpec and the Segment object measureBuff is set up to point to it. As you'll see later, this object is used when determining the preferred width of the View. Next, the buildMapping method allocates an array of integers called offsets that has as many entries as there are markers in the mask. Then, it loops over all the characters in the mask doing two things. First, it checks each character looking for mask characters that indicate locations that will be occupied by the characters from the model. As each of these is found, the next entry in the offsets array is filled with the offset of the marker down the mask (and hence the offset from the start of the formatting string). Then, once the locations occupied by the markers have been recorded, their actual content is no longer important and the positions in the character array that corresponded to markers are filled with the lowercase letter m, which is a wide character in most fonts. You'll see the reason for this in the next section. To clarify what the buildMapping method has done, let's look at how the various pieces of state information would be set up from a Formatspec corresponding to the telephone number example that we've been using throughout this section. In this case, the format and mask fields would be set up by the programmer as follows: (...)-...-.... (***)_***_**** The formatchars field will first be initialized with a reference to a character array that contains the characters of the format string, the first of the two strings shown above. Then, a character array with 14 characters will be created and the contentBuff Segment object initialized to point to it, with code equivalent to the following contentBuff.array = new char[14]; contentBuff.offset = 0; contentBuff.count = 14; Note that this array does not yet have any useful content. The measureBuff object is then set up to point to a copy of the mask in which all the marker positions have been replaced by the letter m. Here is how it will look: measureBuff.arrray is a character array containing "(mmm)-mmm-mmmm" measureBuff.offset = 0; measureBuff.count = 14; Finally, the offsets array is initialized to map from model location to the position in the view at which the corresponding character will appear. In the case of this example, the offsets array will have 10 entries (because there are 10 markers in the mask field) and will be set up as follows: | offsets[0] = 1 | offsets[l] = 2 | offsets[2] = 3 | offsets[3] = 6 | offsets[4] = 7 | | offsets[5] = 8 | offsets[6] = 10 | offsets[7] = 11 | offsets[8] = 12 | offsets[9] = 13 | In other words, the first character in the model will appear at offset 1 in the view, the second at offset 2, the third at offset 3, the fourth at offset 6, and so on. Taking a concrete example of how the offsets array would be used when the text control is being drawn, suppose the model contained the first five digits of a telephone number, like this: 98765 For display purposes, the digit 9 would be placed at position offsets [0], that is, position 1, within the text view. This is as you would expect, because position 0 is occupied by the opening parenthesis of the pair that surrounds the first three digits. Similarly, the digit 8 appears at offset 2 and the digit 7 at offset 3. The next two digits, 6 and 5, would be placed at offsets 6 and 7 respectively, because of the intervening close parentheses and the hyphen. Positions for which the model does not yet contain data are occupied by the characters that were specified in the original format string, so this is how the text component would look at this stage: (987) 65.-.... To verify this, you can try out the FormattedTextField by typing the command: java AdvancedSwing.Chapter3.FormattedTextFieldExample This simple program creates a text field formatted to look like the telephone number example that we've been using in this chapter. Here is the snippet of code that created this text field: final FormattedTextField tf = new FormattedTextField(); FormattedTextField.FormatSpec formatSpec = new FormattedTextField.FormatSpec( "(...)-...-....", "(***)_***_****") ; tf.setFormatSpec(formatSpec); If you type the digits 98765, you'll see that the text field is indeed drawn as was suggested above, as Figure 3-18 shows. If you now press RETURN, the content of the text field's model will be displayed in the window in which you started the program. You should see the following output: Figure 3-18. A FormattedTextField displaying a telephone number. Field content is <98765> which demonstrates that the extra formatting characters (the parentheses, the hyphens, and the periods) are not held in the model, even though they are being displayed. The other method called from the constructor, createContent, is the method that builds the text for the View from the model content and the information saved by buildMapping. This method is called when the View is first created and each time the model content changes. It extracts the data from the model and builds the formatted content in the character array pointed at by contentBuff, which was allocated by buildMapping. You can see how this is done by looking at the code near the end of Listing 3-9. The first step is to work out how many characters have been inserted into the portion of the model mapped by this View. In practice, while this View is being used by FormattedTextField, it will map the whole model so we could just get the number of characters by calling the Document getLength method. However, in this implementation we make the View slightly more general, and more like the other Views in the text package, by using the start and end offsets of the element that the View maps to determine the number of characters to be rendered. In the case of FormattedTextField, this will give the same result as calling getLength. Having obtained the length, we call the Document getText method to get the characters. As you saw in Chapter 1, there are two variants of getText, one of which returns the content in a String and another that uses a Segment. The second of these is usually the more efficient of the two, so we make use of it here, passing it the workBuff Segment object that was allocated by the constructor. When this method returns, the array field of workBuff points to a character array that contains the model data, while the offset and count fields indicate which part of the array actually holds the data. The process of building the formatted result is very simple. First, the output buffer is initialized with a copy of the format string. This is done by copying the character array formatchars, saved by the buildMapping method, to the array pointed to by the contentBuff Segment, which was also allocated by buildMapping. At this stage, contentBuff contains an image of the original format string. In the case of the telephone number example, it would look like this: (...)-...-.... The next step is to copy the characters from the model into their correct locations in contentBuff. This is done using the offsets array created by buildMapping. The process terminates as soon as the number of characters in the model, or the number of characters indicated by the number of markers in the mask, whichever is the smaller, has been copied. While the user is typing into the field, the copy will finish when the model data is exhausted. In fact, because a BoundedPlainDocument is installed as the default model and then set to limit the number of characters to the number of markers in the mask, it should not be possible to have more characters in the model than markers, so a simple test against the marker count should be sufficient. However, the programmer is at liberty to install a different model or to change the maximum length constraint on the BoundedPlainDocument. In either case, it is possible to create a control that can hold more characters than the mask in the FormatSpec requires. To protect against this possibility, the loop that copies the characters checks both possible terminating conditions. This will have the effect of not displaying data in the model that does not have a corresponding marker position. Note carefully how the data is copied from the model into the output buffer: int count = Math.min(length, markerCount); int firstOffset = workBuff.offset; // Place the model data into the output array for (int i = 0; i < count; i++) { formattedContent[offsets[i]] = workBuff.array[i + firstOffset]; } The important point to note about this is the array index used when accessing the source character array pointed to by the workBuff Segment. As we said earlier, you cannot assume that the useful data in the array starts at index 0; because of this, the initial offset (obtained from the offset field) is used as the starting point of the copy. The target location of the copy is obtained, as explained earlier, by extracting the correct offset from the offsets array. When createContent is complete, the character array pointed to by contentBuff contains the text that should be displayed as the text control's content. Because this method is called when the control is initially created and whenever the user inserts or deletes characters from the control, this ensures that contentBuff is always up to date, so painting the content of the control is just a matter of drawing the text in contentBuff. Because the text control is likely to be painted at least as often as its content changes, it is more efficient to build the text to be displayed as each change occurs than it would be to do so just before each paint operation. Determining the Preferred Span of the Text Field The preferred size of a text component is actually determined by its UI delegate, which uses the View hierarchy to calculate how much space is needed in each direction. Each View can implement the getMinimumSpan, getPreferredSpan, and getMaximumSpan methods to indicate preferences and constraints that exist on its width and height. In the case of FormattedFieldview, implementations of all three of these methods will be inherited from its superclasses. The inherited getMinimumSpan and getMaximumSpan methods come from View and return 0 and integer.MAX_VALUE respectively, for both the width and the height. These values are acceptable, so there is no need to override these methods. The getPreferredSpan method, however, is inherited from FieldView. If called with argument Y_AXIS, this method returns the height of the selected font, which is also acceptable for FormattedFieldView. However, the preferred horizontal span for Fieldview is the width needed to draw the characters stored in the model. Because FormattedFieldView will usually display more characters than exist in the model, this would usually not yield the correct result. Therefore, it is necessary to override getPreferredSpan to provide a more accurate preferred width. How should we work out the preferred width of the View? The simplest possible way would be to take advantage of the fact that the number of characters that can be displayed in the View is limited to the length of the formatting string. Using this information, we could multiply the maximum number of characters by the width of a single character in the selected font to obtain the maximum width of the input field. This would work very well, and would give a constant value for the result that could be calculated once and returned on each call to getPreferredSpan, were it not for the following two points: The programmer is not forced to use a constant-width font, even though the FormattedTextField installs one by default. If, instead, a proportional font were used, the initial size calculation could produce a result that differed greatly from the width required when the field is fully populated with user input. In the case of the telephone field, the format string would be much narrower in a proportional font than the complete telephone number, because the periods that appear when the control is created are not nearly as wide as the digits that will replace them. Although it isn't very likely, the format string could legitimately include TAB characters. If you create a JTextField and initialize it with a String that includes a TAB character, the text field will act on it, even though you can't type a TAB into the field unless you arrange for the focus manager to pass TABs directly to the text field instead of moving the focus to the next component. This behavior should, at least by default, be preserved by FormattedTextField. This makes it harder to calculate the width of the View. If a monospaced font is used, the width will still be constant even if there are TABs, but it is no longer a simple matter of multiplying the width of one character in the font by the number of characters in the formatting string. Because of these issues, it isn't possible to guess the correct width for the View. In fact, just working out the maximum width of the formatting string isn't always good enough. If a proportional font is in use, the width of the data in the control at any given time depends entirely on the characters that have been typed. Ideally, the first value returned from getPreferredSpan would be large enough to accommodate the longest string that could ever appear in the text field. Because of the possibility of TAB characters, it is almost impossible to work out in advance the maximum possible width, so we take the following approach when asked for the preferred width of the View: -
Measure the width of the formatting string with wide characters in place of the locations that will be occupied by characters from the model. -
Measure the actual width of the current content of the View. -
Return the larger of these two widths. Although this may sound complicated, it is actually fairly simple. To start with, we already have all the necessary information available. The string whose width is measured in step 1 is actually created during initialization, because, as described earlier, we take a copy of the formatting string, substitute an "m" in all the locations that will be filled from the model and initialize the Segment object measureBuff to point to it. This is exactly the string that we need to measure in step 1. As for step 2, the string we need here is exactly the current state of the data to be displayed in the View. This string is main- tained by the createContent method and is pointed to by the contentBuff object. Given that we have the necessary strings available, how do we calculate their lengths? Usually, you measure the width of strings using the FontMetrics stringWidth method, but that won't work here because the strings might contain TAB characters. Because the TAB characters can be expanded in ways that depend on the TabExpander that happens to be installed, in general the only way to get the correct width is to actually perform the TAB expansion and work out how wide the resulting string would be. Fortunately, the text package contains a class called Utilities that includes a method that does this job for you: public int getTabbedTextWidth(Segment s, FontMetrics metrics, int x, TabExpander e, int startOffset) All the arguments required by this method are easily available from within the getPreferredSpan method. The first argument is the Segment that points to the string to be measured; this will be measureBuff for the first measurement and contentBuff for the second. Core Note The fact that this method, like some others in the utilities class that you'll see later, uses Segment objects is the main reason for using them in the implementation of this View.
The FontMetrics are available from the FormattedTextField. In fact, FieldView, from which FormattedFieldView is derived, has a convenience method that obtains the FontMetrics from whichever text component it is mapping. The third argument is the x position of the start of the string to be measured. This value is passed to the TabExpander, the fourth argument. This is necessary, because if, for example, tab stops are placed at fixed offsets along the View, the effect of any TABs that might be present in the string will depend on where the string starts. The last argument is the offset within the document of the start of the string, which will always be 0 in this case. PlainView implements the TabExpander interface. Because FormattedFieldView is derived from FieldView, which is a subclass of PlainView, this implementation is inherited by FormattedFieldView, so the Tab-Expander argument is supplied simply as this and the start offset of the text within the document is not actually used by this implementation. Mapping from View Location to Model Position The mapping from View location to model position in a component that performs custom rendering is not something that can be done by generic code in the component it can only be done by the View. The most obvious case in which this mapping is needed is when the user clicks inside the component with the mouse. This action causes the caret to move to the location of the mouse click. As you already know, however, the caret's location is actually specified by its position within the model. What actually happens when the user attempts to move the caret using the mouse is the following: -
The mouse press is detected by the text component's installed Caret, which is registered as a MouseListener of the text component. -
The Caret mousePressed method gets the new mouse location from the MouseEvent and converts it to a model location by calling the viewToModel method of the text component's UI class. This call is directed to the viewToModel method of the View that contains the mouse location. -
Having obtained the model location, the Caret position is changed by passing the location to the Caret's setDot method. The process of converting a View offset to the corresponding model location is not a simple one. One obvious reason for this is that the component may be using a proportional font, so it isn't possible to work out where the caret should be by taking the x position from the MouseEvent and dividing it by the width of a single character. Another complication is the possibility of the presence of TAB characters, which, in general, occupy more than one character position on the screen. In fact, though, both of these problems are taken care of by the viewToModel method of FieldView, which FormattedFieldView inherits. So why do we need to implement our own viewToModel at all? The inherited viewToModel method works by using the utilities getTabbedTextOffset method, which you'll see shortly. Loosely speaking, this method takes a character array, a FontMetrics object, and an offset and returns the number of characters in the array that lie to the left of the given offset. As an example, suppose that a constant-width font in which each character occupies eight points is in use and that the text component contains the string: FormattedFieldView If the getTabbedTextOffset method is called with this text, the FontMetrics object for the constant-width font and the offset is 16, it would return the value 2, because each character occupies eight points. This would correspond to the user clicking the mouse between the characters o and r; you can easily see that 2 is the correct model offset for this View position. This is fine for FieldView, because it only displays characters that are in the model. Now suppose that FormattedFieldView is in use and the text component shows the following content: (123)-456-7890 Suppose also that the FormatSpec that we have been using in our telephone number example is applied and that the same 8-point constant-width font is being used. If the user now clicks the mouse between the digits 1 and 2, the View offset 16 will still be obtained from the MouseEvent and, consequently, getTabbedTextOffset would still return the answer 2. However, this is not the correct model offset because it includes the opening parenthesis, which is not part of the model. In fact, the correct model offset in this case is 1, because there is only one character from the model to the left of the mouse location. For this reason, we have to implement our own viewToModel method that works in the same way as that of Fieldview, and then converts the value returned by getTabbedTextOffset to take account of the extra characters in the format string that are not in the model. The FormattedFieldView implementation of viewToModel is shown in Listing 3-9. Let's ignore for now the first two lines of this method, which read: a = adjustAllocation(a) ; bias[0] = Position.Bias.Forward; This first of these two statements takes account of another complication that FormattedFieldView shares with FieldView that we'll deal with at the end of this section, while the second is another consequence of handling bidirectional text, which is discussed in Chapter 5. This method first converts the given View location from the floating-point values that are passed in to the ints that are required by the methods in the Utilities class, and then gets the bounding rectangle of the space allocated to the View. For the sake of simplicity, let's assume for now that this rectangle corresponds to the visible area of the text component on the screen (as we'll see later, this is not always true). The first check to be made is that the View location is actually within the bounding rectangle of the component's visible area. If the View location is to the left of or above the bounding rectangle, and then it is taken as being before the first character in the model in other words, the corre-sponding model offset will be the start offset of the Element within the model that is mapped by this View. On the other hand, if the View location is below or to the right of the bounding rectangle, it is taken as indicating the last valid offset in the mapped Element. Usually, however, the coordinates passed to this method will map to a position that lies somewhere between these two extremes. Having verified that this is the case, we get the model location, as described earlier, by invoking getTabbedTextOffset, a method of the javax.swing.text.utilities class that is declared as follows: public static final int getTabbedTextOffset(Segment s, FontMetrics metrics, int x0, int x, TabExpander e, int startOffset) This method looks very similar to the getTabbedTextWidth method that we used earlier in this example. In fact, in many ways these methods are the reverse of each other; while getTabbedTextWidth returns the width of a given string, getTabbedTextOffset is given a size and returns the answer to the question "How much of this string occupies this much horizontal space?" The first argument is a Segment object that points to the string being measured, in the form of a character array. In this example, the string is the text being displayed by the FormattedFieldView, which is always pointed to by the contentBuff object. The second, fifth, and sixth arguments should also be familiar from the description of getTabbedTextWidth they refer to the FontMetrics for the font being used by the FormattedTextField, the object to be used to expand tabs, which, as before, will be the FormattedFieldView itself and the starting offset of the text within the model, which is used by the TabExpander. That leaves the third and fourth arguments, which are both obviously the x coordinates of two points. The first is the x coordinate of the View's bounding rectangle, measured relative to the space occupied by the text component. Usually, this would be zero because FormattedTextField only has one real View that displays all of its content and so occupies all of its screen space; as we'll shortly see, this isn't always true. For Views such as LabelView that are used by more complex text components, the bounding rectangle can correspond to any area of the space occupied by the component because a LabelView can cover part of a line of text that need not begin at the left side of the component, so this argument need not be zero even in the simplest of cases. The second x coordinate is that of the View location whose model offset is required, measured from the same origin as the first x coordinate. In the simple case of a mouse click in a FormattedTextField, this will be the x coordinate from the MouseEvent. Figure 3-19 shows this pictorially for the less trivial case of a LabelView in a JTextPane. Figure 3-19. Offsets passed to the getTabbedTextOffset method.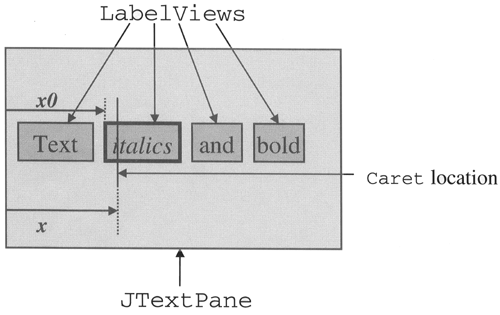 Here, you can see the Views that correspond to a single line of text rendered on a JTextPane. Because there are several attribute changes within the line, each section has its own LabelView that maps an Elements with a particular set of attributes. Let's suppose that the user clicks to place the Caret between the letters i and t of the word italics, as shown by the vertical line in the diagram. Initially, the viewToModel method of the JTextPane UI delegate is called, which passes the request to the RootView viewToModel method. The RootView locates the ParagraphView that contains the location at which the user clicked and calls its viewToModel method. This process continues through the Paragraphview.Row containing the mouse location and finally reaches the LabelView that actually draws the text italics. At this point, the Shape passed to the viewToModel method (the third argument) is the box that bounds the area occupied by the LabelView (shown with bold edging in Figure 3-19) and the coordinates passed as the first two arguments are the x and y values of the point where the mouse was clicked, relative to the JTextPane. In other words, the x coordinate supplied to the LabelViewmodelToView method is the value shown as x in Figure 3-19, while the bounding box of the View has the x coordinate shown as x0. These designations are the same as those used in the definition of getTabbedTextOffset above. However, in the case of FormattedFieldView, the bounding box covers the whole line, so the x0 value is 0. In effect, the getTabbedTextOffset method is asked to return the offset of the model location that is (x - x0) points from the left edge of the View's bounding box. The actual algorithm used by getTabbedTextOffset is not important to the rest of this discussion; in fact, it operates by working along the characters that it is given, adding the width of each (taken from the FontMetrics object passed in) to the initial offset (x0) until the resulting offset is equal to or greater than the target offset x. When this occurs, the number of characters needed to reach this point, added to the startoffset argument, is the required model offset and becomes the return value, unless the given offset is nearer to the next character, in which case the offset of the next character is returned. For example, suppose that, in Figure 3-19, the user clicked somewhere in the middle of the letter a in italics. If the mouse click is nearer to the t than to the l, the offset returned is that of the a (that is, the offset of the position between t and a), whereas if it is closer to the 1, the offset of is returned. There is, in fact, another variant of getTabbedTextOffset with an additional boolean argument called round, which can be supplied as true if the rounding described here is to be performed, or false if the location before the given offset is required (that is, rounding down). The return value from getTabbedTextOffset, then, is the number of characters that lie to the left of the given view location. As we said earlier, though, for FormattedFieldView, this is not the final answer, because not all these characters are in the model. What we need is to map the number of characters in the view to the number of model characters that appear in that segment of the view. This mapping is, fortunately, very simple to perform. Let's look again at our telephone number example, which has the following format string: (...)-...-.... As you know, the dots are the locations that will be occupied by characters from the model. Now, if the user clicks between the first and second dots, there will be two characters in the view in front of the Caret, so the offset returned by getTabbedTextOffset will be 2. However, as you can see, there is only one model character before this location, so the correct return value for viewToModel would be 1. To see how to convert the value 2 to the correct value, recall that the offsets array created by FormattedFieldView maps model offset to offset with the format string. This is exactly the reverse of the mapping that is required for viewToModel, so we can map the getTabbedTextOffset value to the correct value by iterating through the offsets array until we find an entry that contains an offset greater than that returned by getTabbedTextOffset. When we have located this entry, the correct return value is the index in the offsets array of the previous entry. Looking again at our telephone example, the offsets array in this case looks like this: | Index | Offset | | 0 | 1 | | 1 | 2 | | 2 | 3 | | 3 | 6 | | 4 | 7 | | 5 | 8 | | 6 | 10 | | 7 | 11 | | 8 | 12 | | 9 | 13 | Walking down the array, you can see that the first entry containing an offset greater than 2 is the one with index 2. Therefore, the correct return value for viewToModel would be (2 1) = 1. Similarly, if the user clicked after the first dot in the second group (the fourth dot overall), getTabbedTextOffset would return the value 7, which would map to 4 according to the earlier table. This is, of course, the correct result. However, there is another complication. What happens if the user clicks to the right of the last dot? In this case, getTabbedTextOffset returns the value 14, because all 14 characters are now to the left of the click point. There is, however, no entry in the offsets table that is larger than 14. When this happens, the largest possible model offset is returned as the model offset. As a consequence of this, the Caret will actually be placed to the right of the last dot so the user cannot move the Caret into a location further right than the last actual character from the model. Similarly, because model offset 0 corresponds to display offset 1, the Caret cannot actually be moved to the left of the first character in the model, which will be just after the opening parenthesis in the telephone number example. Another consequence of the way the viewToModel method works is that the user cannot move the caret further to the right than the space occupied by characters from the model, even though there will be characters from the mask there. Thus, for example, if only the first three digits of a telephone number have been typed, it will not be possible to move the Caret beyond the third digit, either using the mouse or the arrow keys on the keyboard. Finally, let's return to the first line of the viewToModel method that have so far omitted to describe: a = adjustAllocation(a); To see what this line achieves, start the telephone number example again by typing the command java AdvancedSwing.Chapter3.FormattedTextFieldExample and then resize the window horizontally to make the space allocated to the telephone number smaller. As you do this, the space reserved for the rightmost part of the number will be clipped, leaving only the start of the input field in view. Now start typing numbers into the input field. As you do so, everything works as normal until you reach the right side of the visible area, at which point the content scrolls to the left to make room for further input, as shown in Figure 3-20. Figure 3-20. Scrolling in a FormattedTextField. The scrolling occurs as characters are entered into or removed from the text field, by the insertUpdate and removedUpdate methods of FieldView, which are inherited by FormattedFieldView. As the content of the input field changes, the getPreferredSpan method is invoked to determine how wide the visible area would need to be to hold all the characters that it should display. JTextField contains a BoundedRangeModel that holds the preferred size of the control as the maximum value and the size of the area allocated to the control on the screen is usually held in the extent. The value of the BoundedRangeModel is set as the Caret moves so that the correct portion of the component is visible; as the BoundedRangeModel's value is changed, the control is repainted. Painting the control causes the View's paint method to be called. It is this method that actually determines which part of the text component's content will actually be displayed. As you'll see later, the FormattedFieldView paint method, like that of FieldView, uses the values held in the BoundedRangeModel to decide which characters to render on the screen. The scrolling also affects the view-to-model mapping, of course. Look again at Figure 3-20. Suppose the user now clicks the mouse a little way in (say 16 pixels) from the left side of the FormattedTextField. In the earlier discussion, we assumed that the text would actually be aligned with its start at the left side of the visible area, so that a distance of 16 pixels would correspond to, say, two characters from the start of the text fields content. Here, though, that logic plainly does not work the 16 pixels should be, perhaps, two characters from the start of the visible text content. To map this to an actual model offset, you need to know how many characters have been moved out of view to the left of the visible area. In fact, when a proportional font is in use, it is difficult to know how many characters have been lost you can't just work out how many characters on the screen are to the left of the cursor and add that to what is not on view. To solve this problem, the FormattedFieldView viewToModel method starts by calling adjustAllocation, which it inherits from FieldView. This method does two things: Gets the actual height of the area assigned to the View (its bounding rectangle) and compares it to the View's preferred height. If these are not the same, the y component of the View's bounding rectangle and its height are adjusted so that it has the preferred height and is vertically centered in the component's allocated screen area. So, for example, if the content of a FormattedTextField is being drawn with a font that requires a vertical space of 17 pixels but the component is 31 pixels high, the bounding box will be changed so that it starts 7 pixels from the top of the screen area and its height is 17 pixels. On the other hand, if the actual screen area allocated is only 13 pixels, the bounding box is still changed to be 17 pixels high, but now it will start 2 pixels above the upper boundary of the screen area, which will result in the text being clipped at the top and the bottom. In either case, however, the text is vertically centered. Gets the width of the bounding rectangle and compares it to the View's preferred width. If the bounding rectangle is not smaller than the preferred width, the bounding box is adjusted so that the text is centered or right- or left-aligned depending on the horizontal alignment specified using the setHorizontalAlignment method of the text control. On the other hand, if the preferred width of the text is larger than the actual width, the visible rectangle is adjusted to fit around the text, placing the location indicated by the BoundedRangeModel's value at the left side of the screen area occupied by the component. This will usually result in the x value of the bounding rectangle becoming negative. To see how this works and how calling this method helps the viewToModel method return the correct model offset when some of the control's content has been scrolled of the screen, let's look at a couple of examples. First, consider the simple case in which the screen space is larger than the area required to draw the control's content and suppose also that the text control has right-alignment specified. In this case, the text area is vertically centered and moved to the right of the screen area, as shown in Figure 3-21. In this figure (and the next), the shaded area represents the bounding rectangle of the Shape that will be returned by adjustAllocation, while the area with the bold border is the Shape that was passed to it that is, the area allocated to the View on the screen. Figure 3-21. Adjusting a View's allocation: case 1. In Figure 3-21, the view is only partly populated, because the user has only supplied the first three characters of the telephone number; however, because of the formatting string, the rendered text still requires the full 112 pixels horizontally and 17 vertically. In this case, the text control is 200 pixels wide and 23 pixels high, leaving extra room in each direction. When the viewToModel method is called, the Shape passed to it will describe the text component, less some space reserved for insets. A typical bounding rectangle for this shape would be: x = 2, y = 2, width = 196, height = 19 The adjustAllocation method would change this bounding rectangle to allocate extra vertical space equally above and below the View and place the text horizontally according to the text component's horizontal alignment, which, in this case, will move the text to the right side of the visible area. When adjustAllocation completes, it returns a Shape whose bounding rectangle is the following: x = 86, y = 3, width = 112, height = 17 This arrangement leaves 3 pixels above and below the View, 86 pixels to the left of it, and 2 to the right (as margin space). Now suppose the reason for entering this method is that the user has clicked with the mouse between the digits 1 and 2. As we'll see, the adjustAllocation method is called when the View's paint method is executed, so the View will have drawn itself with the same bounding rectangle and the digits will appear in the locations shown in Figure 3-21. Assuming a monospaced font in which each character occupies 8 pixels horizontally, the mouse event will have an x value of 102, because it is given relative to the actual bounds of the text component. We discovered earlier that the viewToModel method computes the number of characters to the left of the cursor by calling getTabbedTextOffset, passing it the x coordinate of the left edge of the bounding box as argument x0 and that of the View location to be converted (in this case the position of the mouse) as the x value. The model offset is then computed as the number of characters needed to span (x - x0) pixels horizontally. In this example, x is 102 and x0 is 86, so the value that getTabbedTextOffset will use is 16, which, of course, corresponds to two characters in the font in use here. Note that this arithmetic works only because the adjustAllocation method changes the bounding rectangle to match the actual location of the text, not that of the actual View. Now let's look at the situation shown in Figure 3-20. Here, the container that the text component is mounted in has been narrowed so that there is not enough room for it to be allocated its preferred space. Not only that, but the user has typed the same three digits, causing the Caret to move to the right. As the Caret moves, it causes the content of the text control to scroll so that it remains visible, by changing the value field of the text control's BoundedRangeModel. Figure 3-22 shows another example of this. Figure 3-22. Adjusting a View's allocation: case 2.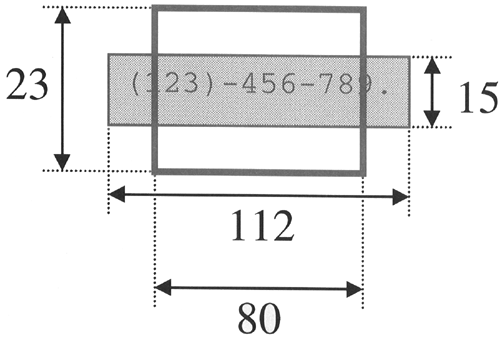 Here, the user has typed nine digits of the telephone number into a narrowed text field which, in this case is 80 pixels wide, and then scrolled the display so that the first digit and the opening parenthesis are obscured by the left side of the control. The scrolling effect is actually achieved by setting the value of the BoundedRangeModel to 16. Because the preferred width of the View is still 112 pixels, that leaves 16 pixels, or two characters, that are also not visible to the right. When the viewToModel method is called, the bounding rectangle of the Shape that it receives would be: x = 2, y = 2, width = 76, height = 19 When the preferred span is larger than the width of the bounding rectangle, the adjustAllocation method does not take into account the horizontal text alignment specified by the setHorizontalAlignment method of JTextField. Instead, it reshapes the bounding rectangle so that its width matches the preferred width of the content and places the position that corresponds to the value of the BoundedRangeModel at the left of the visible area. In this case, the value of the BoundedRangeModel is 16, so the x coordinate of the bounding rectangle will be changed to -16, making the Shape that adjustAllocation returns look like this: x = -16, y = 3, width = 112, height = 17 In terms of the calculation used in the viewToModel method, if the user clicks with the mouse at the left edge of the visible area shown in Figure 3-22, between the digits 1 and 2 in the rendered string, the x value passed to getTabbedTextOffset will be 0 and the x0 value will be -16. The pixel offset that it calculates will therefore be (0 -(-16)) = 16, which is equivalent to two characters, so once again the correct result is obtained. Mapping from the Model to the View The modelToView method translates a position within the model to the corresponding location within the View. As you might expect, it is essentially the reverse of viewToModel. Neglecting first of all the scrolling complications that pose the same problems here as they did for viewToModel, lets look at how a model position can be translated to the correct View location. In a simple text field with a monospaced font, to calculate the View position for the character at model offset n, you would simply multiply n by the width of a character in the font. However, for our View this is an oversimplification for two reasons: There isn't a one-to-one mapping between characters in the model and the characters being displayed in the View. For example, in the case of the telephone number display field, the digit at offset 0 in the model is not the first character displayed on the screen an open parenthesis appears before it. In general, the font will not be monospaced, so a simple multiplication does not work. This problem also exists for the normal FieldView, from which FormattedFieldView is derived. Solving both of these problems is not difficult. To address the first problem, you need to know where in the View a given character from the model will be displayed. This information is readily available from the offsets array, which, as you saw earlier, maps directly from model offset to the position that the given character will occupy in the formatted string. In the telephone number example, the offsets array tells us that the first digit occupies offset 1 within the displayed string, so to find the actual offset of the start of this character in the View, we have to compute the width of the first character in the character array pointed to by the contentBuff Segment object. Similarly, the fourth model character (that is, the character at model offset 3) will be displayed in position 6 in the rendered string; to get its View offset, we need to measure the total width of characters 0 through 5 of contentBuff. The width of a contiguous range of characters can be obtained from the getTabbedTextwidth method of the Utilities class, which you saw when we discussed getting the preferred width of the View. If you look at the implementation of the modelToView method in Listing 3-9, you'll see both the translation of the model offset to an offset within contentBuff and the use of getTabbedTextwidth to get the width of the portion of the text that precedes the given location. The offset that getTabbedTextWidth returns will be relative to the beginning of the string in the View, so it's absolute position relative to the text component is obtained by adding this offset to the x coordinate of the View's bounding box. The modelToView method is actually supposed to return a Shape that corresponds to the View location; by convention, the returned Shape is a Rectangle whose height is the same as that of the View's bounding box and whose width is 1 pixel; the x and y coordinates are those of the top left corner of the imaginary rectangle drawn to the left of the character in question. You can see how this Rectangle is constructed at the end of the modelToView method. Finally, let's look at the effect of scrolling on this method. Most of the algorithm that has been described is actually independent of the scrolling the calculation of the offset of the required position from the start of the string does not depend on where the string is positioned within the component's display area. As with the viewToModel method, though, it looks like things go wrong if the text field is made smaller so that not all the content is visible and the user places the Caret in such a way as to force the telephone number to be scrolled to the left. Fortunately, however, the same solution as we used for viewToModel also works for modelToView all that is required is to call adjustAllocation at the beginning of the method. Lets look at the example shown in Figure 3-22 again to see why this is so. In this case, the leftmost two characters of the formatted string have scrolled out of view to the left. When modelToView is entered, the bounding rectangle of the Shape that describes the text component's allocated area looks like this: x = 2, y = 2, width = 76, height = 19 If the modelToView method were now called with model offset 2, we would need to return the View offset of the position before the digit 3 (refer to Figure 3-22). Ignoring the effect of adjustAllocation, the algorithm outlined earlier would first find the position within the rendered string of the digit in model position 2, which would be 3, then calculate the length of the first three characters of the rendered text using getTabbedTextWidth. Assuming the usual fixed-width font with 8 pixels per character, this would give a View offset of 24, which would be correct if the View had not been scrolled. However, as we saw in the discussion of viewToModel, in this case adjustAllocation changes the bounding rectangle to the following: x = -16, y = 3, width = 112, height = 17 We also know that the Shape returned by modelToView has its x coordinate determined by adding the x coordinate of the bounding box to the offset returned by getTabbedTextWidth. This calculation results in a final x coordinate of (-16 + 24) = 8, which is the width of one character. If you look back to Figure 3-22, you'll see that the digit 3 is, indeed, one character to the right of the left boundary of the component's visible area, so this result is correct. In fact, you should be able to see that this algorithm also works if a proportional font is in use and that it also works if the text component is wider than the View's preferred width, as shown in Figure 3-21. Drawing the Field Content Overview The most obvious duty of a View is to paint a representation of the portion of the model that it maps onto the area of the screen allocated to its host control. Now that you've seen some of the issues surrounding the mapping between model and View locations, the process of drawing the model's content onto the screen will be simpler to understand. Painting the control can be thought of as first locating the correct screen position for the first character to be drawn, and then rendering each character from contentBuff in the order in which they are stored. This is, however, not so straightforward in the case shown in Figure 3-22, because only a subset of the rendered telephone number is visible but, if you followed the descriptions of the viewToModel and modelToView methods, you should be able to see that we can use the same technique here to compensate for the scrolling effect. Before we look in detail at how the actual painting occurs, let's step back and take an overview of how the process works. The paint method of a View is called whenever some part of the region covered by that View is damaged and needs to be redrawn, or is being drawn for the first time. The paint method of a content-rendering View like FormattedFieldView will, in fact, always be invoked from the paint method of its parent container View. In more complex text components like JTextPane, there may be several levels of nesting before a primitive paint method is called; not all of the paint methods that are called along the way will contain any real drawing logic. The paint method of ParagraphView, for example, doesn't draw anything it just arranges for the paint methods of all of its child Views to be called. By contrast, the ExtendedParagraphView that you saw earlier in this chapter has a paint method that does have real drawing logic, because it may need to paint its background or draw a border. A View's paint method is declared as follows: public void paint(Graphics g, Shape allocation); It is important to understand the relationship between the View, the text component, the Graphics object, and the Shape that describes the View's allocated region of the screen space used by the text component. Because text fields are so simple in structure, lets look at these relationships in the context of the more complex JTextPane. Here, text is usually rendered by a LabelView. Each text run has its own dedicated LabelView, so these objects could be required to map any part of the JTextPane's allocated space. Consider, for example, the View structure shown in Figure 3-23, which you first saw at the beginning of this discussion on Views. Figure 3-23. A typical View structure. Here you see a JTextPane with two rows of text, each of which requires two LabelViews to map its contents. To draw this JTextPane, the paint method of the ParagraphView will be called with a Graphics that covers the entire text component and with a matching allocation. In this case, where the component is 128 pixels wide and 110 pixels high, the Graphics and allocations passed to the ParagraphView paint method will be configured like this: | Graphics clip rectangle: | x = 0, y = 0, width = 128, height = 110 | | Shape bounding rectangle: | x = 3, y = 3, width = 122, height = 104 | As you can see, the bounding rectangle of the allocated area for the ParagraphView covers the whole area of the component, less a small outside margin. The ParagraphView will not do any drawing instead, it will call the paint method of the upper ParagraphView.Row, followed by the paint method of the lower ParagraphView.Row. Each of these Views is itself a container that will just call the paint methods of the left and then the right LabelView object that they each contain. The LabelView paint methods will therefore be called in the order A, B, C, and finally D it is here where the actual drawing work gets done. Let's look at the paint method of the LabelView marked D. The paint method of this LabelView will be called with Graphics and Shape arguments that are initialized like this: | Graphics clip rectangle: | x = 0, y = 0, width = 128, height = 110 | | Shape bounding rectangle: | x = 32, y = 64, width = 88, height = 16 | The important things to note here are the following: -
The Graphics clip rectangle covers the entire host text component, even though the paint method is required only to draw the part of the component that its content should occupy. -
The bounding rectangle corresponds to the area that the View actually occupies. Its coordinates are specified relative to the parent text component. As a result of this, the paint method of any View could draw anywhere on the surface of the text component, but usually it would change the Graphics object's clipping area to match the region that has been allocated to it to prevent accidental drawing outside of its own area. This is especially important for FormattedFieldView (and the standard FieldView), because of the way in which the scrolling of text within the View is handled, as you'll see shortly. Before implementing the paint method for FormattedFieldView, we need to look at the corresponding method of its superclass, to see if there is anything useful that can be inherited. In fact, the paint method of FieldView does almost nothing other than call the paint method of its own superclass, PlainView. This latter method actually contains the core of the drawing logic used by JTextArea, JtextField, and JPasswordField. It works like this: -
Using the Shape passed as its second argument, a modified one is obtained by calling the package private method adjustPaintRegion. The bounding rectangle of the Shape returned from this method is used throughout the rest of the paint method. -
The font attribute of the Graphics context passed as the first argument is set from the font of the host text component and its FontMetrics are obtained. Because getting the metrics for a font can be a relatively expensive operation, they are cached when first acquired and a new set is obtained only if the font is changed. -
Two package private fields called selected and unselected are initialized to contain the text color to be used for text in the selected region of the component and text outside that region, respectively. The unselected color is usually just the foreground color of the text component but, if the component is disabled (because setEnabled(false) has been called on it), the disabled text color (set using the JTextComponent setDisabledTextcolor method) is used instead. The selected color depends on whether the selection is visible. The Caret, and the selection highlighting that is provided if you drag the Caret using the mouse, can be made invisible by calling the Caret method setSelectionVisible(false). If the selection is visible (which is the default), the color set using the setSelectedTextColor method of JTextComponent is used; otherwise text in the selected region is drawn in the same color as unselected text. -
Finally, a loop is performed with each pass handling one line of text. For each line, any layered highlights that apply to that line are drawn, followed by the text, which is actually rendered using a protected method called drawLine. If FormattedFieldView did not provide its own paint method, it would simply inherit that of PlainView, plus the small additional task performed by FieldView's paint method, which sets the clipping rectangle of the Graphics context to restrict drawing operations to the area bounded by the Shape that describes the space allocated to the View. To decide whether to take this course or to implement a new paint method, we need to examine how much of the inherited code is useful for FormattedFieldView and what changes need to be made to provide the extra functionality of this View. Let's look at the above list, point-by-point. The first action, calling the package private method adjustPaintRegion, may not at first seem to be useful. This step certainly cannot be directly overridden from a subclass outside of the javax.swing.text package; however, the actual implementation of adjustPaintRegion that would be used by FormattedFieldView is actually inherited from FieldView (which is in javax. swing. text and so can override the adjustPaintRegion method of PlainView). This method calls the protected method adjustAllocation, which we made much use of while implementing both viewToModel and modelToView. As we'll see later, it is as essential to use adjustAllocation from within the paint method as it was within the other two, so the invocation of adjustPaintRegion is useful. The second action, setting the font of the Graphics object, clearly also applies to FormattedFieldView and the caching of font metrics is just as useful to our View as it is to both FieldView and PlainView. The third action, however, is not of any benefit to FormattedFieldView, because this step sets the values of two package private fields. These fields are used in the various drawing methods implemented by PlainView, which are invoked from its drawLine method. These fields cannot, of course, be accessed from a class that is not in the javax.swing.text package, so they could not be used by the custom drawing code that will need to be implemented for FormattedFieldView. When drawing the formatted string that represents the content of our View, we will certainly need to use different text colors, exactly as PlainView does and, in fact, if the selected and unselected fields of PlainView were protected or had protected or public accessors, we could make use of their values directly. Because this is not the case, we will need to shadow these fields with our own copies that are initialized to the same values. The last of the four actions is, of course, the most interesting because it is here that the text control's content is drawn. PlainView is written to work with a multiline component like JTextArea and so it has a loop that processes a single line of text at a time, but it works just as well for the single line JTextField and for our FormattedTextField. From the point of view of FormattedFieldView, the automatic handling of layered highlights is beneficial if the programmer decides to create a subclass of FormattedTextField that uses a layered highlight, while the fact that drawLine is called to render a single line of text gives us a handy override point to install our own functionality. Here is the how PlainView defines the drawLine method: protected void drawLine(int lineIndex, Graphics g, int x, int y) For a single-line component, this method will be called once, with linelndex set to 0. The Graphics object will be the same object passed to the paint method, but by now clipped to the area allocated to the View, while x and y will usually (but not always, as you'll see shortly) be the coordinates allocated to the top left corner of the View. The PlainView implemen tation of this method just gets the content of the model that corresponds to the View's offset range and draws it at the given coordinates using the Graphics object, taking care to handle TAB characters correctly. This, of course, is the area in which FormattedFieldView differs from both FieldView and PlainView: FormattedFieldView cannot simply draw the characters from the model instead, it needs to draw the formatted version of the model, a cached copy of which is stored in its contentBuff Segment object. There are at least two ways in which the FormattedFieldView drawing functionality could be implemented. The most obvious way would be to override the paint method, thereby short-circuiting all the code that has just been described, and handle everything ourselves. This would involve writing code that performs the useful parts of the four actions listed earlier and reusing little or none of the PlainView drawing code. At the other extreme, we could avoid overriding the paint method and just provide our own implementation of drawLine. Which of these approaches is better? There is no simple answer to this question. Overriding the paint method has the advantage of putting FormattedFieldView in direct control of how it is drawn and places the code in one place where it might be easier to maintain. It does, however, mean that there will be some avoidable duplication of code. Overriding the drawLine method maximizes code reuse at the cost of a small sacrifice in maintainability and a small performance cost because of extra method calling overhead and the fact that the code to obtain the selected and unselected foreground text colors (see action 3 above) is executed in PlainView's paint method and then a copy of that code will run in our drawLine implementation. Because there is little to choose between these two possibilities, FormattedFieldView is implemented to use the paint method of FieldView and override the drawLine method to handle the drawing. If you prefer the alternative, it is a relatively simple exercise to override the paint method instead and place all the drawing logic there. If you are going to do this, however, remember that you'll need to do the following things before rendering the text: Call adjustAllocation to take care of the case in which the context of the field has been scrolled. Clip the Graphics object to restrict drawing to the View's allocated area. Draw any layered highlights that are in the View. Implementing the drawLine Method In principle, all the drawLine method needs to do is render the text from contentBuff into the View's visible area using the Graphics object that is passed to it. The task should be particularly easy, because the text packages Utilities class contains a useful method that handles the actual text drawing for you: public static final int drawTabbedText(Segment s, int x, int y, Graphics g, TabExpander e, int startOffset) We first saw this method in "Handling Tabs". As you can see, it conveniently takes a Segment object as the source of the characters to be drawn, a Graphics object to draw into and the x and y coordinates of the starting location. All of these values are passed as arguments to drawLine or are readily available. Similarly, the TabExpander argument can be supplied as this, because FormattedFieldView inherits the implementation of this interface from PlainView. Finally, the startOffset argument is the offset of the first character to be drawn. Usually, this would be the offset of the first character within the element of the model that this View maps. However, for our View there are characters to be drawn that are not actually in the model, so this offset will actually be the offset of a character within contentBuff and will initially be set to 0. This argument is actually used to determine the distance to the next TAB location in case there should be TAB characters to be drawn, as described earlier in this chapter. The drawTabbedText method returns the x value of the first pixel following the end of the string that it renders, which is useful for drawing several blocks of text placed end-to-end. With this reasoning, the drawLine method would appear to be as simple as this: protected void drawLine(int line, Graphics g, int x, int y) { Utilities.drawTabbedText(contentBuff, x, y, g, this, 0); } Unfortunately, it isn't quite that easy. What this simple implementation neglects is the possibility that some or all the text in the component might be selected. If this is the case, the selection highlight (that is, the background) will already have been drawn, but it is usual for the foreground color of selected text to be different from that of unselected text, if only to ensure that the selected text contrasts properly with the highlighted background that it is drawn over. The drawTabbedText method draws using the color selected into the Graphics object passed to it, so to arrange for the correct color to be used, you need to call drawTabbedText with different colors selected depending on whether it is rendering text that is selected or not. There are several possible cases: None of the text is selected. The selection extends from the start of the component to the end. The selection extends from the start of the component to somewhere in the middle. The selection extends from somewhere after the start of the component and reaches the end. The selection starts after the start of the component but does not reach the end. The first case is the simplest, because this could be implemented by just using drawTabbedText. The next three cases are really special cases of the last one, but all of them can be considered as being of the form: A leading section that is not selected. A middle section that is selected. A trailing section that is not selected. In all but the fourth case, one or more of these sections is empty. To implement the drawLine method with an arbitrary selection, we need a method, which we'll call drawUnselectedText, that can draw part of the text in the unselected foreground color and another called drawSelectedText that draws in the unselected color. Other than the foreground color that they use, however, these methods will be identical. Here is the implementation of drawUnselectedText, extracted from Listing 3-9: protected int drawUnselectedText(Graphics g, int x, int y, int p0, int p1) throws BadLocationException { g.setColor(unselected); workBuff.array = contentBuff.array; workBuff.offset = p0; workBuff.count = p1 - p0; return Utilities.drawTabbedText(workBuff, x, y, g, this, p0); } This method assumes that an instance variable called unselected has been initialized with the color to be used for text that has not been selected; a similar variable called selected will also be set to the selected text foreground color at the start of the drawLine method, as you'll see later. The Graphics argument is the one passed to drawLine, while x and y are the coordinates of the location on the text baseline at which this segment of text should start. The drawTabbedText method requires a Segment object in which the array field points to the character array containing the text, the count field is the number of characters to be drawn and the offset field is the offset into the array of the first character to be rendered. The range of characters from the Segment passed as the argument to drawUnselectedText is given by the arguments p0 and p1, which represent the beginning and end of the range respectively. To convert this to the form required by drawTabbedText, we use a second Segment object (held in the instance variable workBuff), which is set so that its array member points to the base of the formatted character array while its offset and count fields correspond to the range between offsets p0 and p1. When the drawing has been done, drawUnselectedText returns the pixel offset of the end of the drawn string, which can be used to place the next piece of text. Let's take an example that shows how the drawUnselectedText and drawSelectedText methods work. Figure 3-24 shows a FormattedTextField fully populated with a telephone number, with part of the field selected. As you can see, the selected text has been drawn in white so that it contrasts with the selection highlight. Figure 3-24. Drawing the content of FormattedFieldView. Assuming the usual 2-pixel insets, the drawLine method will, in this case, be called with the x = 2 and y = 2, corresponding to the top left of the rectangle in which the text should be drawn. The contentBuff Segment object will contain all the text to be drawn and will therefore point to an array containing 14 characters its offset field will be 0 and count will be 14. Drawing the first part this field requires a call to the drawUnselectedText method. The important parameters of this call will be: x = 2 y = 2 p0 = 0 p1 = 3 because the drawing operation starts at the beginning of the allocated area and should draw the first three characters from contentBuff. This would result in drawTabbedText being invoked with a Graphics object in which the drawing color is that for unselected text, x and y values as shown earlier, and the Segment object workBuff, which will point to the same character array used by contentBuff, set up with an offset of 0 and a count of 3. Assuming a fixed-width font in which each character occupies 8 pixels horizontally, the value returned from drawUnselectedText after drawing the first three characters would be 26, which accounts for the three characters and the initial inset of 2 reflected in the value of the x parameter that drawUnselectedText was called with. Next, the selected text needs to be drawn by calling drawSelectedText, which takes the same set of arguments as drawUnselectedText. For this call, they will be set as follows: x = 26 Y = 2 p0 = 3 p1 = 11 These parameters cause drawTabbedText to be invoked with x = 26, y = 2, and the workBuff object set up with offset 3 (from p0) and count 8 (from p1 - p0). Therefore, 8 characters will be drawn in the selected text foreground color, which drawSelectedText will select into the Graphics object and the returned pixel offset will be 90 (the initial offset of 26, plus 8 characters each spanning 8 pixels). Finally, the trailing unselected part will be drawn with another call to drawUnselectedText, this time with arguments x = 90 y = 2 p0 = 11 p1 = 14 which will select the unselected text color into the Graphics object and again invoke drawTabbedText, the return value of which will be 114. You can see how these calls are made and exactly how the parameters for each call are constructed by looking at the implementation of the drawLine method in Listing 3-9, which is repeated here for ease of reference. // View drawing methods: overridden from PlainView protected void drawLine(int line, Graphics g, int x, int y) { // Set the colors JTextComponent host = (JTextComponent)getContainer(); unselected = (host.isEnabled()) ? host.getForeground(): host.getDisabledTextColor(); Caret c = host.getCaret (); selected = c.isSelectionVisible() ? host.getSelectedTextColor(): unselected; int p0 = element.getStartOffset(); int p1 = element.getEndOffset() - 1; int sel0 = ((JTextComponent)getContainer()) .getSelectionStart(); int sel1 = ((JTextComponent)getContainer()) .getSelectionEnd(); try { // If the element is empty or there is no selection // in this view, just draw the whole thing in one go. if (p0 == p1 || sel0 == sel1 || inView(p0, p1, sel0, sel1) == false) { drawUnselectedText(g, x, y, 0, contentBuff.count); return; } // There is a selection in this view. Draw up // to three regions: // (a) The unselected region before the selection. // (b) The selected region. // (c) The unselected region after the selection. // First, map the selected region offsets to be relative // to the start of the region and then map them to view // offsets so that they take into account characters not // present in the model. int mappedSel0 = mapOffset(Math.max(sel0 - p0, 0)); int mappedSel1 = mapOffset(Math.min(sel1 - p0)); p1 - p0)); if (mappedSel0 > 0) { // Draw an initial unselected region x = drawUnselectedText(g, x, y, 0, mappedSel0); } x = drawSelectedText(g, x, y, mappedSel0, mappedSel1); if (mappedSel1 < contentBuff.count) { drawUnselectedText(g, x, y, mappedSel1, contentBuff.count); } } catch (BadLocationException e) { // Should not happen! } } The first part of this method initializes the instance variables selected and unselected to the appropriate colors. This code will also be found in the paint method of PlainView and would also need to be included in any overridden implementation of paint because, as noted earlier, the PlainView copies of these fields are package private and hence not accessible to code in FormattedFieldView. The next step is to find out whether there is any text selected and, if so, whether the selection intersects the part of the text component mapped by this View. To do this, we get the offset range of the part of the model that corresponds to this View from the element that the View is associated with (which was passed to the FormattedFieldView constructor and stored in an instance variable), and then get the range of offsets for the selected region from the host component. Given these two ranges, it is simple to work out whether they overlap; the code for this test is in the method inView, which is shown in Listing 3-9. Core Note In the case of FormattedTextField, there will only ever be one leaf View, so the FormattedFieldView will always map all the document content That being the case, being careful to check both that there is a selection and that it overlaps the region mapped by the View looks like overkill, because it would be good enough just to check whether a nonempty selection exists. Making the extra check, however, allows you to make use of FormattedFieldView should you write a more general text component that needs this functionality but also uses more than one View to map its content
If there is no selection within the area covered by the View, all the content can be drawn in a single call to drawUnselectedText, passing the start offset as 0 and the end offset as the number of characters in contentBuff. In fact, this is likely to be the most common path through the drawLine method. When there is a selection, the rest of the code in drawLine calls drawUnselectedText to draw the initial unselected part, drawSelectedText for the selected region, and finally drawUnselectedText to render the unselected portion at the end. As described earlier, some of these calls will be skipped if they are not required. There is only one subtle point in this code that we have not yet mentioned. Remember that the getSelectionStart and getSelectionEnd methods return the location of the start and end of the selected region in terms of model offsets, but the drawSelectedText and drawUnselectedText methods deal in terms of offsets into contentBuff. These offsets do not match, as you can see by looking again at Figure 3-24. In this example, the selection start and end offsets as returned by getSelectionStart and getSelectionEnd are 2 and 7 respectively, but the offsets required by the drawing methods are 3 and 11. Before we can use the selection offsets, they need to be mapped to the correct values for the View. This mapping is performed by the mapOffset method, the implementation of which is shown in Listing 3-9. As you can see by looking at the code, getting from the model offset to the View offset is very simple and it is a problem we have already solved the mapping we need is exactly that provided by the offsets array, so all that is required is to use the model offset as an index into offsets to retrieve the required View position. Now that you've seen all the code in the FormattedFieldView class, there is one last point to be cleared up. The description of the drawLine method so far has made the simplifying assumption that the text in the View has not been scrolled to the left as a result of the space allocated to the component being too narrow to accommodate its content. When we discussed the viewToModel and modelToView methods, we saw that it was necessary to adjust our calculations to cater for the possibility that the View had been scrolled and that we could do this by simply invoking the adjustAllocation method of FieldView before attempting either mapping. The effect of calling adjustAllocation was to change the bounding rectangle of the Shape that described the area allocated to the View to compensate for the scrolling, so that the simple algorithms for mapping between model and View that work when the content has not been scrolled also work when scrolling has taken place. In fact, the same trick also works when painting the View if adjustAllocation is called and the Shape that it returns is used as the basis for drawing, everything will work whether the View has been scrolled and whichever part of the View should be visible will appear in the component on the screen. If you look back a few pages to the description of the PlainView paint method, which we chose not to override, you'll see that adjustAllocation is actually called at the start of the painting process from the package private adjustPaintRegion method, so the bounding rectangle of the View will already have been modified to take the scrolling into account before drawLine is invoked. The x and y values that are passed to drawLine are taken from the adjusted bounded rectangle, so any changes that adjustAllocation method made will affect drawLine. As an example, let's look again at the case that we examined in connection with the viewToModel method and shown in Figure 3-22. In this example, the user has typed a complete telephone number and scrolled the display so that the Caret is located between the first and second digits of the number, so that the opening parenthesis and the first digit are out of view. In this situation, when paint is called, the Shape that it receives will have the bounding rectangle: x = 2, y = 2, width = 76, height = 19 We know from the earlier discussion that adjustAllocation will change this rectangle to the following: x = -16, y = 3, width = 112, height = 17 As a result of this, when our drawLine method is called, the initial x coordinate will be -16 instead of 2. However, the origin of the Graphics context will not be changed, so the drawTabbedText method (called by either drawSelectedText or drawUnselectedText) will start rendering the control's content 16 pixels to the left of the visible area, which is outside the clipping rectangle of the Graphics object. Therefore, the first two characters of the field will not be displayed the leftmost character that you'll see will be the one rendered at x coordinate 2, which will be the third character in the text area. This, of course, creates the effect of scrolling the text to the left by two characters. |