WHAT SORT OF TEAM DO I NEED?
| only for RuBoard - do not distribute or recompile |
WHAT SORT OF TEAM DO I NEED?
In order to properly plan the project, the project manager needs to know what kind of resources are needed, and when they are needed. So we can begin with an outline development team structure, as shown in Figure 9.2.
Figure 9.2. Example project team structure.
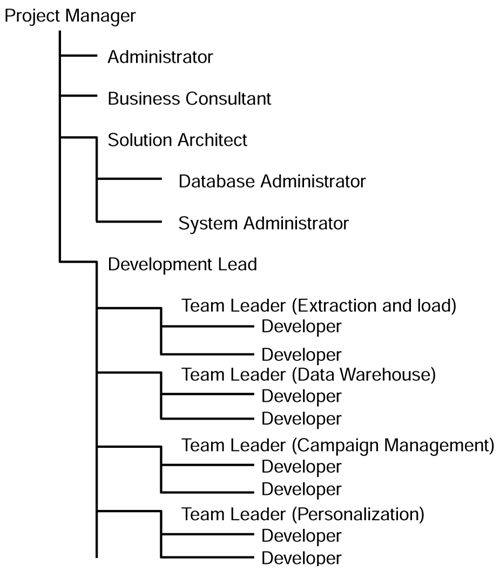
Just a brief note about some of the roles identified in Figure 9.2:
Project manager. The project manager needs to be fairly happy in dealing with a certain amount of ambiguity, uncertainty, and change. Data warehouse projects, being different from normal development projects, tend to have to be more flexible to the changing business landscape and are not so rigidly defined as we might prefer. An experienced project manager, in system development, can usually adapt to the more fluid requirements of a data warehouse project. Project managers who are used to working from a fixed deliverable , such as the dreaded system specification, without wavering, will find it more difficult.
Business consultant. This role is crucial to the success of the project. The business consultant, and by this we absolutely do not mean management consultant, is the person who can help the customer to understand the benefits of CRM and can explain how all the components fit together to help to implement the CRM strategy. Ideally, the business consultant should have a good understanding of the customer's business environment. This person is responsible for gathering the business requirements and helping to develop the conceptual model.
Solution architect. This person is also a key player in ensuring the ultimate success of the project. The solution architect specifies the components of the warehouse jig-saw puzzle, making sure that all the pieces fit together neatly. The solution architect role is the most senior technical role on the project and the role involves gaining an understanding of the requirements and converting them into a solution. It is important that the person assigned to this role is highly skilled, not only in the field of systems integration generally but, also, specifically in the field of data warehousing. In a CRM project, traditional data warehousing techniques need to be modified, as described throughout this book.
Development lead. In many respects, this can be regarded as being quite similar to a traditional systems development manager's role. What is happening in a data warehouse is that there are many little subprojects going along at the same time. Each of the subprojects consists of a small team having a team leader and one or more developers. The teams are variously developing the extraction and load process, the warehouse itself as well as the applications, such as campaign management, as shown in Figure 9.2. The number of teams that will be needed will vary from project to project but, so long as an incremental delivery approach is being adopted, we would never need more than three or four of these little teams. As one increment ends and a new one starts, we just reassign the teams to the next deliverable.
Database administrator. Much of the work we do in a data warehouse development involves, axiomatically, databases. For this we do need a highly qualified DBA to work with us on the project. If possible we would prefer a DBA with data warehouse experience. The data warehouse database design will be undertaken by one of the design teams, but they will have to work very closely with the DBA and a good knowledge of warehousing techniques is highly desirable. Similarly, the extraction and load team would benefit from working with a DBA who understands the loading issues surrounding data warehouses.
System administrator. This is our operating system and infrastructure expert. This person assigns access rights to the development machines and generally keeps house for the team. However, if we can get someone who can help with more technical stuff, then so much the better. This means configuring the CPU usage and memory in an optimal fashion for the warehouse, also the disks, mirroring, controller cache, etc. These things will have to be addressed at some point when we get into performance tuning, so it is a great advantage if we can get someone at the outset who can deal with this stuff.
The Work Breakdown Structure for Data Warehousing
In this section we introduce a general work breakdown structure (WBS) for data warehousing projects. Our WBS has well over 100 elements and it comes complete with dependencies between elements. It's quite comprehensive, but if you want to add to it or modify it in any way, then feel free to do so.
We present the WBS in logical sections so that some of the elements that may not be immediately obvious can be explained. Notice that the leftmost column in Table 9.1 is the Project Increment. This WBS is designed to handle the incremental approach. We have to complete the WBS for each increment in our data warehouse.
The first section is the conceptual model. In the conceptual model we include all the components that were identified in the conceptual modeling chapter of this book. Note that there is no absolute need to adopt the dot modeling technique if you don't wish to. This WBS has no allegiance to any particular methodology, although it fits quite snugly with dot.
Table 9.1. Conceptual Modeling Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days |
|---|---|---|---|---|
| Conceptual Model | ||||
| CM010 | Capture business requirements | |||
| CM020 | Create conceptual dimensional model | CM010 | ||
| CM030 | Determine retrospection requirements | CM020 | ||
| CM040 | Determine data sources | CM020 | ||
| CM050 | Determine transformations | CM040 | ||
| CM060 | Determine changed data dependencies | CM040 | ||
| CM070 | Determine frequencies and time lags | CM040 | ||
| CM080 | Create metadata | CM040 | ||
So retrospection, changed data dependencies, and frequencies and time lags should, by now, be fairly familiar terms.
The next step is to convert the conceptual model to a logical model (Table 9.2). Again, this is covered in Chapter 6.
Table 9.2. Logical Modeling Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days |
|---|---|---|---|---|
| Logical Model | ||||
| LM010 | Create conceptual?logical map | CM030 | ||
| LM020 | Design security model | CM020 | ||
| LM030 | Create logical data model | LM010 | ||
The creation of the physical model is described in detail in Chapter 7. The output from the physical model stage of the project is the data definition language (DDL) statements required to instantiate all the data warehouse objects (tables, indexes, etc.) (Table 9.3).
Table 9.3. Physical Modeling Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days |
|---|---|---|---|---|
| Physical Model | ||||
| PM010 | Create logical ? physical map | LM030 | ||
| PM020 | Create security model | LM020 | ||
| PM030 | Design physical model | PM010 | ||
| PM040 | Create DDL | PM030 | ||
Much of the next part of the project can be executed in parallel with the data modeling. The logical and physical modeling will be carried out by the data warehouse team and the capture of the data from the source systems is executed by the extraction and load team. There is, to some extent, a dependency on the conceptual model in that it is the metadata that will direct the extract and load team to the appropriate source systems and associated data elements. Table 9.4 lists the tasks involved in the initial loading of the dimensional behavioral models. Remember that the initial loading is a one off and, therefore, is not an ongoing requirement. It is all right for this part of the system to be a bit less rigorous than the incremental extracts and loads.
Table 9.4. Initial Data Capture and Load Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days | |
|---|---|---|---|---|---|
| Initial Data Capture and Load | |||||
| Behavioral Data | |||||
| IB010 | Design data extraction process | CM040 | |||
| IB020 | Develop data extraction process | IB010 | |||
| IB030 | Test data extraction process | IB020 | |||
| IB040 | Design data VIM process | CM050 | |||
| IB050 | Develop data VIM process | IB040 | |||
| IB060 | Test data VIM process | IB050 | |||
| IB070 | Design data load process | PM030 | |||
| IB080 | Develop data load process | IB070 | |||
| IB090 | Test data load process | IB080 | |||
| IB100 | Execute loading of fact data | IB090 | |||
| IB110 | Verify data accuracy and integrity | IB100 | |||
| IB120 | Implement metadata | CM080 | |||
| Circumstances and Dimension Data | |||||
| ID010 | Design data extraction process | CM040 | |||
| ID020 | Develop data extraction process | ID010 | |||
| ID030 | Test data extraction process | ID020 | |||
| ID040 | Design data VIM process |  | CM050 | ||
| ID050 | Develop data VIM process | ID040 | |||
| ID060 | Test data VIM process | ID050 | |||
| ID070 | Design data load process | PM030 | |||
| ID080 | Develop data load process | ID070 | |||
| ID090 | Test data load process | ID080 | |||
| ID100 | Execute loading of dimension | ID090 | |||
| ID110 | Verify data accuracy and integrity | ID100 | |||
| ID120 | Implement metadata | CM080 | |||
Notice that the processes ID010 through ID120 are to be repeated for each entity.
The next set of processes appear to be very similar and, in some respects, they are. However, the significant difference is that these processes will be used as part of the live, delivered system and must be developed to industrial strength. Each process should record its progress in some kind of system log. The information written in the log should be classified as:
Informational. Informational messages include the date and time started and time finished. Elapsed time is another useful piece of information as it helps the system administrators to figure out which are the most time-consuming processes in the system. Number of records processed and if possible, monetary sums involved are also very useful pieces of information. This will help to provide a kind of audit trail from source system to data warehouse and will be invaluable in error tracing. Another good idea is to write an entry into the log as the process proceeds rather than just at the end. If the process routinely handles around a million records, then it is helpful to write a log entry every 100,000 records or so. One way of making this more dynamic is to provide for a run-time argument that specifies the frequency of progress entries to be written to the log.
Warnings. A process should append a warning to a log file when something of concern has been detected but, for which, there is no immediate cause for concern. The rejection of records, for instance, may result in the generation of a warning message. Sometimes, a record in the log may be informational, such as the fact that the file system is 10 percent full, 20 percent full, etc. These informational messages might be promoted into warning messages when the file system exceeds 60 percent capacity. In a proactive system this could cause a different kind of message to be sent to an operator so that action can be taken before the situation becomes critical.
Errors. When an error occurs, the process cannot proceed any further and has to stop. For instance, when the file system overflows, unless the process can get access to another file system, it cannot proceed and has to stop. Sometimes, errors are detected right at the start, such as when the process detects that it has been given a file of data that it has already dealt with. Errors generally imply that the system has come to a grinding halt, and some intervention is required before further progress can be made.
When an error occurs, there is a natural inclination to start over. By that we mean that the process is rerun. In relational database terms, this usually means rolling back all the work that has been done successfully and then redoing the work from the start once the problem has been solved . The problem with this approach is that, in a data warehouse, we might be trying to process many millions of transactions. Often, it takes as long to roll back the work as it did to carry out the work in the first place. Usually, rolling back all the transactions is unnecessary, especially in cases where we have simply run out of space “which is a common data warehouse problem. If we get, say, halfway through processing all our data, then have to roll it all back and then redo the work from the beginning, the task ultimately will take twice as long as originally expected. If we are operating within a tight overnight time window, this might have the effect of us not being able to open the warehouse in time in the morning. It is important to remember that some of these processes might take several hours to complete under normal circumstances. It is well worth considering allowing processes to be restarted. This means that, although they stop when an error is detected, they can pick up where they left off once the situation has been resolved.
Table 9.5. Ongoing Data Capture and Load Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days | |
|---|---|---|---|---|---|
| Subsequent Data Capture and Load | |||||
| Behavioral Data | |||||
| SB010 | Identify entity lifecycle points of capture | CM040 | |||
| SB020 | Design data extraction process | CM040 | |||
| SB030 | Develop data extraction process | SB020 | |||
| SB040 | Test data extraction process | SB030 | |||
| SB050 | Design data VIM process | | CM050 | ||
| SB060 | Develop data VIM process | SB050 | |||
| SB070 | Test data VIM process | SB060 | |||
| SB080 | Design data load process | PM030 | |||
| SB090 | Develop data load process | SB080 | |||
| SB100 | Test data load process | SB090 | |||
| Circumstances and Dimension Data | |||||
| SD010 | Identify changed data | CM040 | |||
| SD020 | Create dependency links | CM060 | |||
| SD030 | Design data extraction process | CM040 | |||
| SD040 | Develop data extraction process | SD030 | |||
| SD050 | Test data extraction process | | SD040 | ||
| SD060 | Design data VIM process | CM050 | |||
| SD070 | Develop data VIM process | SD060 | |||
| SD080 | Test data VIM process | SD070 | |||
| SD090 | Design data load process | PM030 | |||
| SD100 | Develop data load process | SD090 | |||
| SD110 | Test data load process | SD100 | |||
As with the initial loading of the data, the tasks associated with the subsequent loading of dimensions, SD010 through SD110 in Table 9.5, must be repeated for each entity.
The next set of tasks is associated with enabling the users. The kind of things we need to do here are fairly self-explanatory. Also, once the user roles have been defined, these tasks can be executed in parallel to other things. (Table 9.6).
The next thing we have to do is organize all the warehouse admin stuff (Table 9.7). This includes the user role definition, the user schemas (users views of the data), as well as any summary-level tables that have been identified so far. As a general principle, it is recommended that we hold off on producing the summary tables at this stage. The reasons for this are:
Table 9.6. User Access Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days |
|---|---|---|---|---|
| User Access | ||||
| UA010 | Assign users to user roles | WA010 | ||
| UA020 | Enroll users | UA010 | ||
| UA030 | Configure user software | |||
| UA040 | Test user access | UA030 | ||
| UA050 | Design user manual | UA030 | ||
| UA060 | Create user manual | UA050 | ||
| UA070 | Design help processes | UA030 | ||
| UA080 | Develop help processes | UA070 | ||
| UA090 | Test help processes | UA080 | ||
Table 9.7. Warehouse Administration Processing Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days |
|---|---|---|---|---|
| Warehouse Administration | ||||
| WA010 | Define user roles | LM020 | ||
| WA020 | Map security model to roles | WA010 | ||
| WA030 | Design user schemas | WA020 | ||
| WA040 | Develop user schemas | WA030 | ||
| WA050 | Test user schemas | WA040 | ||
| WA060 | Design data summary process | PM030 | ||
| WA070 | Develop data summary process | WA060 | ||
| WA080 | Test data summary process | WA070 | ||
| WA090 | Design data summary navigation process | WA060 | ||
| WA100 | Develop data summary navigation process | WA090 | ||
| WA110 | Test data summary navigation process | WA100 | ||
-
Their creation causes a delay in the point at which we can release the system to our users. Quite often, the summary processing consumes a significant percentage of the development effort. Any question that can be answered by a summary level table can also be answered from a detail table, since the summary tables get their data from the detail. The only issue is one of performance. It is perfectly reasonable for us to release the system to the users and work on the performance aspects afterward.
-
Allowing the users to get at the data as soon as is practical gives us another benefit. We can observe their usage and use the knowledge gleaned from these observations to determine which summary tables we should be putting in place. It is commonplace in data warehouse development projects to try to second guess the summary level tables. Often we are right, but sometimes we are not right and some of our carefully crafted summaries are never, or only infrequently, utilized by the users.
The next step is automation (Table 9.8). Many professional project managers will testify that this is the biggest gotcha in building data warehouses. Our incremental approach, with all its advantages, tends to exacerbate the problem. What happens is that we try very hard to get the first increment to a point where the users can actually use the data. It is only at this point that they can begin to get convinced that, hey, there really is some business benefit to be obtained from all this data! Once they have it, they can't get enough of it and they want more “not just a tweak here and there “they want a whole lot more. Before we know where we are, some of the team have been diverted onto the second increment. However, what the customer does not know is that the first increment is far from being finished. All we have done is show them the data, but they think we're done. They don't see the fact that, in order to get the data out of the source systems, VIMmed, and loaded into the data warehouse, an awful lot of hand cranking takes place. None of the processes have been integrated and the system does not hang together. What is needed is to go back to the first increment and put in place all the scheduling, controls, error handling, etc., that are needed to turn the system into an industrial strength product with strong welds and nuts and bolts to replace all the string and blue tack.
This is a serious issue in the ancient art of expectation setting. If we let this get away from us, we may never recover. The operations department of any company will never accept any system that cannot stand on its own two feet, especially a system that is as huge and resource hungry as a data warehouse. All the time we must keep impressing on our customer the fact that what they are seeing is not the finished article and that we do need sufficient time to complete the work. There is a case to be made for not allowing the users to have access to the data warehouse until the first increment is fully completed. While having some sympathy for this view, I am still of the opinion that the users should be given access as soon as possible. After all, it is their data, not ours. Strong project management and equally strong expectation management are the key to success here.
Table 9.8. Automation Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days |
|---|---|---|---|---|
| Automate Processing | ||||
| AP010 | Design automation process | |||
| AP020 | Develop automation process | AP010 | ||
| AP030 | Test automation process | AP020 | ||
| AP040 | Perform integration test | AP030 | ||
| AP050 | Design operational procedures manual | AP010 | ||
| AP060 | Develop operational procedures manual | AP050 | ||
| AP070 | Obtain operations acceptance | AP060 | ||
Now let's consider support. Support exists at a number of levels (Table 9.9). Each of our customers will have specific requirements. There are two principal classes of support:
-
User support. This is where we provide a kind of hot line or customer support desk environment that assists our users when they have questions about the system or the service or when they have gotten into difficulty.
-
System support. Ordinarily, as suppliers of the system, we will have some responsibility for supporting it, at least for some period of time, after it has been implemented. Beyond that, some provision must be made for more ongoing support. This includes the routine maintenance of the system, including upgrades to systems software and application software. Support of a general nature is also needed with storage space, recovery from hardware and software failures, etc.
The levels of support that are required will always vary from customer to customer as will the way in which the support is implemented. Some organizations have their own support departments, while others outsource their support entirely. Whatever the situation, we have to design our support strategy to fit into the requirements.
Another gotcha is in failing to involve the support people early on. It is often the case with these guys that they've got their acts together big time and they will be able to tell us precisely what it is they will need. This means precisely what we have to give them before they will take the responsibility for the system off our hands. A lot of project time and money can get wasted by not paying attention to the support requirements. It's a bit like the automation issue, and it gets left and left until the end of the project and tends to be considered to be one of the tidy up tasks instead of being given the strategic level of importance that it deserves .
Table 9.9. User Support Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days |
|---|---|---|---|---|
| User Support | ||||
| US010 | Design support processes | |||
| US020 | Develop support processes | US010 | ||
| US030 | Test support processes | US020 | ||
We touched on backup and backout in Chapter 7. It's worth repeating that backing up a data warehouse is a nontrivial exercise, and considerable effort has to be applied to the design of an effective solution (Table 9.10). There is also the backout problem. How do we manage to get data out of the system when it should never have found its way into the warehouse in the first place?
So what is backin ? Backin is the opposite of backout. Sometimes we find that the wrong file of data was used to load the warehouse. The first we know about it is when someone from the operations team appears and says that one of the files they gave us four days ago was wrong and, by the way, here is the right one. So we have to use the backout procedure to remove the offending data and the backin procedure to put the correct data back in (not forgetting that this new data might end up getting backed out if it turns out to be wrong “this has happened ).
Table 9.10. Backup & Recovery Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days |
|---|---|---|---|---|
| Backup and Recovery | ||||
| BR010 | Design backup process | |||
| BR020 | Develop backup process | BR010 | ||
| BR030 | Test backup process | BR020 | ||
| BR040 | Design backout process | |||
| BR050 | Develop backout process | BR040 | ||
| BR060 | Test backout process | BR050 | ||
| BR070 | Design backin process | |||
| BR080 | Develop backin process | BR070 | ||
| BR090 | Test backin process | BR080 | ||
In order to get the data warehouse to operate normally, we have discussed the fact that all the routine processes have to be automated as much as possible. The actual execution of the processes and their timing, dependencies, etc., will normally be placed under the control of some scheduler. Schedulers are extremely variable in the level of functionality that they provide, but most are quite sophisticated. For instance, we would not want our data warehouse extraction process to be started until the file of data that it needs to work on had materialized in the designated place. Although the file may be due to arrive by, say, seven o'clock in the evening each day, there is no real guarantee that it will actually do so. And if it is not there at the appointed hour , we don't want the extraction process to start. The schedulers can be configured to respond to the presence or absence of files, as well as the return codes of other processes, signifying their success or failure.
The operations team will not take any responsibility for running the system if they do not know how to do so. This is a similar issue to those of support and automation and is another famous gotcha, not only in data warehouse projects but, in all IT projects. Just like the support team, ops will have their own set of requirements, often written down, that we will absolutely have to satisfy before we can hand the system off to them.
Other things we have to do include performance monitoring and tuning as well as capacity planning. Do schedule some time in the plan for this kind of activity. There is no point in delivering a system that works brilliantly on day one but that runs out of memory, CPU cycles, disk space, or network bandwidth by day five (Table 9.11).
Table 9.11. System Management Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days |
|---|---|---|---|---|
| System Management | ||||
| SM010 | Scheduling | |||
| SM020 | Operations training | |||
| SM030 | Performance monitoring | |||
| SM040 | Capacity planning | |||
Table 9.12 lists some other items that also sometimes get forgotten or that get left so late that they get rushed. Another gotcha is not to have user equipment with a high enough specification. It does not matter how well configured the server is nor how much headroom exists within it. Many a well-designed, well-configured, superbly performing data warehouse has been let down by attempting to shoe-horn the end-user component into clapped out desktop machines.
Table 9.12. Installation & Rollout Tasks
| Project Incre. number | WBS Number | Task Description | Dependency | Person Days |
|---|---|---|---|---|
| Installation and Rollout | ||||
| IR010 | Conduct user training | |||
| IR020 | Install user equipment | |||
| IR030 | Test user software configuration | UA030 | ||
Lastly, Table 9.13 lists some initial things we need to sort out before the development team turns up with their coding pencils sharpened and ready to go.
Table 9.13. Initial Setup Tasks
| Initial System Requirements | ||
|---|---|---|
| Acquire and install DBMS software | ||
| Acquire and install user access software | ||
| Acquire and install metadata repository software | ||
| Acquire and install aggregate navigation software | ||
| Acquire and install high-speed sort software | ||
| Acquire and install backup systems | ||
| Acquire and install Web server and client software | ||
| Acquire and install capacity planning software |
| only for RuBoard - do not distribute or recompile |
EAN: 2147483647
Pages: 96