WHAT WORKS FOR CRM
| only for RuBoard - do not distribute or recompile |
WHAT WORKS FOR CRM
Data warehousing is now a mature business solution. However, the evolution of business requires the evolution of data warehouses. That business people have to grasp the CRM nettle is an absolute fact. In order to do this, information is the key. It is fair to say that an organization cannot be successful at CRM without high-quality , timely , and accurate information. You cannot determine the value of a customer without information. You cannot personalize the message to your customer without information, and you cannot assess the risk of losing a customer without information.
If you want to obtain such information, then you really do need a data warehouse. In order to adopt a personalized marketing approach, we have to know as much as we can about our customers' circumstances and behavior. We described the difference between circumstances and behavior in the section on market segmentation in Chapter 1. The capability to accurately segment our customers is one the important properties of a data warehouse that is designed to support a CRM strategy. Therefore, the distinction between circumstances and behavior, two very different types of data, is crucial in the design of the data warehouse. Let's look at the components of a traditional data warehouse to try and determine how the two different types of data are treated.
The diagram in Figure 3.5 is our now familiar Wine Club example.
Figure 3.5. Star schema for the Wine Club.
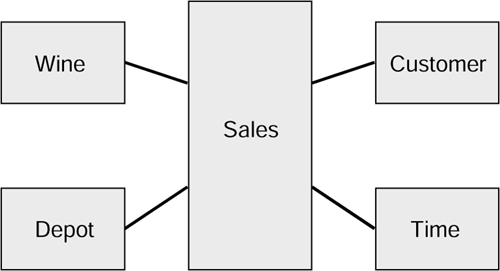
It remains in its star schema form for the purposes of this examination, but we could just as easily be reviewing a snowflake model.
The first two questions we have to ask are whether or not it contains information about:
-
Customers' behavior
-
Customers' circumstances
Clearly it does. The Sales table (the Fact table) contains details of sales made to customers. This is behavioral information, and it is a characteristic of dimensional data warehouses and data marts that the Fact table contains behavioral information. Sales is a good example, probably the most common, but there are plenty more from all industries:
-
Telephone call usage
-
Shipments and deliveries
-
Insurance premiums and claims
-
Hotel stays
-
Aircraft flight bookings
These are all examples of the subject of a dimensional model, and they are all behavioral.
The customer dimension is the only place where we keep information about customer circumstances. According to Ralph Kimball (1996), the principal purpose of the customer dimension, as with all dimensions in a dimensional model, is to enable constraints to be placed on queries that are run against the fact table. The dimensions merely provide a convenient way of grouping the facts and appear as row headers in the user 's result set. We need to be able to slice and dice the Fact table data any which way. A solution based on the dimensional model is absolutely ideal for this purpose. It is simply made for slicing and dicing.
Returning to the terms behavior and circumstances, a dimensional model can be described as behavior centric. It is behavior centric because its principal purpose is to enable the easy and comprehensive analysis of behavioral data.
It is possible to make a physical link between Fact tables by the use of a common dimension tables as the diagram in Figure 3.6 shows.
Figure 3.6. Sharing information.
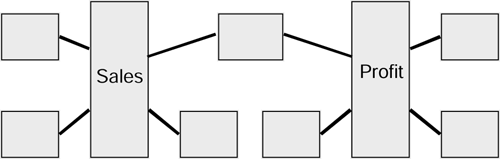
This daisy chain effect enables us to drill across from one star schema to another. This common dimension is sometimes referred to as a conformed dimension.
We have seen previously how the first-generation data warehouses tended to focus on the analysis of behavioral information. Well, the second generation needs to support big business issues such as CRM and, in order to do this effectively, we have to be able to focus not only on behavior, but circumstances as well.
Customer Behavior and Customer Circumstances “The Cause-and-Effect Principle
We have explored the difference between customers' circumstances and their behavior, but why is it important?
Most of the time in data warehousing, we have been analyzing behavior. The Fact table in a traditional dimensional schema usually contains information about a customer's interaction with our business. That is: the way they behave toward us. In the Wine Club example we have been using, the Fact table contained information about sales. This, as has been shown, is the normal approach toward the development of data warehouses.
Now let us look again at one of the most pressing business problems, that of customer loyalty and its direct consequence, that of customer churn. For the moment let us put ourselves in the place of a customer of a cellular phone company and think of some reasons why we, as a customer, may decide that we no longer wish to remain as a customer of this company:
-
Perhaps we have recently moved to a different area. Maybe the new area has a poor reception for this particular company.
-
We might have moved to a new employer and have been given a mobile phone as part of the deal, making the old one surplus to requirements.
-
We could have a child just starting out at college. The costs involved might require economies to be made elsewhere, and the mobile phone could be the luxury we can do without.
Each of the above situations could be the cause for us as customers to appear in next month's churn statistics for this cellular phone company. It would be really neat if the phone company could have predicted that we are a high-risk customer. The only way to do that is to analyze the information that we have gathered and apply some kind of predictive model to the data that yields a score between, say, 1 for a very low risk customer to 10 for a very high risk customer.
But what type of information is likely to give us the best indication of a customer's propensity to churn? Remember that, traditionally, data warehouses tend to be organized around behavioral systems. In a mobile telephone company, the most commonly used behavioral information is the call usage. Call usage provides information about:
-
Types of calls made (local, long distance, collect, etc.)
-
Durations of calls
-
Amount charged for the call
-
Time of day
-
Call destinations
-
Call distances
If we analyze the behavior of customers in these situations, what do you think we will find? I think we can safely predict that, just before the customer churned, they stopped making telephone calls! The abrupt change in behavior is the effect of the change in circumstances.
The cause-and-effect principles can be applied quite elegantly to the serious problem of customer churn and, therefore, customer loyalty. What we are seeing when we analyze behavior is the effect of some change in the customer's circumstances. The change in circumstances, either directly or indirectly, is the cause of their churning. If we analyze their behavior, it is simply going to tell us something that we already know and is blindingly obvious “the customer stopped using the phone. By this time it is usually far too late to do anything about it.
In view of the fact that most dimensional data warehouses measure behavior, it seems reasonable to conclude that such models may not be much help in predicting those customers that we are at risk of losing. We need to turn our attention to being very much more rigorous in our approach to tracking changes in circumstances, rather than behavior. Thus, the second-generation data warehouses that are being built as an aid to the development of CRM applications need to be able to model more than just behavior.
So instead of being behavior centric, perhaps they should be dimension centric or even circumstances centric. The preferred term is customer centric. Our second-generation data warehouses will be classified as customer centric.
Does this mean that we abandon behavioral information? Absolutely not! It's just that we need to switch the emphasis so that some types of information that are absolutely critical to a successful CRM strategy are more accessible.
So what does this mean for the great star schema debate? Well, all dimensional schemes are, in principle, behavioral in nature. In order to develop a customer-centric model we have to use a different approach.
If we are to build a customer-centric model, then it make sense to start with a model of the customer. We know that we have two major information types “behavior and circumstances. For the moment, let's focus in on the circumstances. Some of the kinds of things we might like to record about customers are:
| Customer | |
|---|---|
| Name | |
| Address | |
| Telephone number | |
| Date of birth | |
| Sex | |
| Marital status | |
Of course, there are many, many more pieces of information that we could hold (check out Appendix D to see quite a comprehensive selection), but this little list is sufficient for the sake of example. At first sight, we might decide that we need a customer dimension as shown in Figure 3.7.
Figure 3.7. General model for customer details.

The customer dimension in Figure 3.7 would have some kind of customer identifier and a set of attributes like those listed in the table above. But that won't give us what we want. In order to enable our users to implement a data warehouse that supports CRM, one of the things they must be able to do is analyze, measure, and classify the effect of changes in a customer's circumstances. As far as we, that means the data architects , are concerned , a change in circumstances simply means a change in the value of some attribute. But, ignoring error corrections, not all attributes are subject to change as part of the ordinary course of business. Some attributes change and some don't. Even if an attribute does change, it does not necessarily mean that the change is of any real interest to our business. There is a business issue to be resolved here.
We can illustrate these points if we look a little more closely at the simple list of attributes above. Ignoring error corrections, which are the attributes that can change? Well, in theory at least, with the exception of the date of birth, they can all change. Now, there are two types of change that we are interested in:
-
Changes where we need to be able to see the previous values of the attribute, as well as the new value
-
Changes where the previous values of the attribute can be lost
What we have to do is group the attributes into these two different types. So we end up with a model with two entities like the one in Figure 3.8.
Figure 3.8. General model for a customer with changing circumstances.
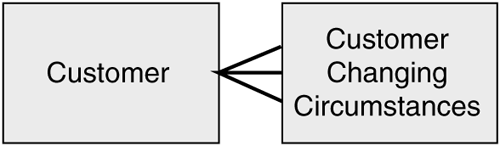
We are starting to build a general conceptual model for customers. For each customer, we have a set of attributes that can change as well as a set of attributes for which either they cannot change or, if they do, we do not need to know the previous values. Notice that the relationship has a cardinality of one to many. Please note this is not meant to show that there are many attributes that can change; it actually means that each attribute can change many times. For instance, a customer's address can change quite frequently over time.
In the Wine Club, the name, telephone number, date of birth, and sex are customer attributes where the business feels that either the attributes cannot change or the old values can be lost. This means that the address and marital status are attributes where the previous values should be preserved. So, using the example, the model should look as shown in Figure 3.9.
Figure 3.9. Example model showing customer with changing circumstances.
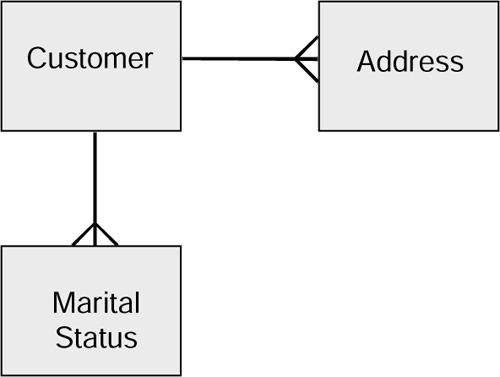
So each customer can have many changes of address and marital status, over time.
Now, the other main type of data that we need to capture about customers is their behavior. As we have discussed previously, the behavioral information comes from the customers' interaction with our organization. The conceptual general model that we are trying to develop must include behavioral information. It is shown in Figure 3.10.
Figure 3.10. The general model extended to include behavior.

Again the relationship between customers and their behavior is intended to show that there are many behavioral instances over time. The actual model for the Wine Club would look something like the diagram in Figure 3.11.
Figure 3.11. The example model extended to include behavior.
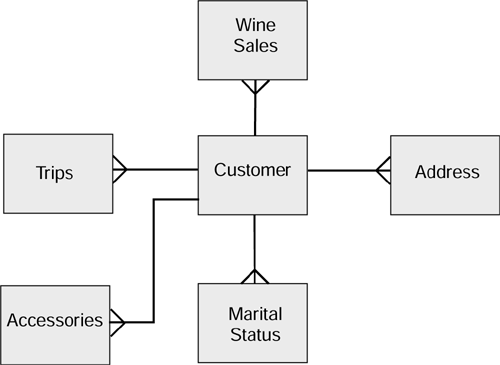
Each of the behavioral entities (wine sales, accessories, and trips) probably would have previously been modeled as part of individual subject areas in separate star schemas or snowflake schemas. In our new model, guess what? They still could be! Nothing we have done so far means that we can't use some dimensional elements if we want to and, more importantly, if we can get the answers we need. Some sharp-eyed readers at this point might be tempted into thinking, Just hold on a second, what you're proposing for the customer is just some glorified form of common (or conformed) dimension, right?. Well, no.
There is, of course, some resemblance in this model to the common dimension model that was described earlier on. But remember this: The purpose of a dimension, principally, is to constrain queries against the fact table. The main purpose of a common dimension is to provide a drill across facility from one fact table to another. They are still behavior-centric models. It is not the same thing at all as a model that is designed to be inherently customer centric. The emphasis has shifted away from behavior, and more value is attached to the customer's personal circumstances. This enables us to classify our customers into useful and relevant segments. The difference might seem quite subtle, but it is, nevertheless, significant.
Our general model for a customer centric-data warehouse looks very simple, just three main entity types. Is it complete? Not quite. Remember that there were three main types of customer segmentation. The first two were based on circumstances and behavior. We have discussed these now at some length.
The third type of segment was referred to as a derived segment. Examples of derived segments are things like estimated life time value and propensity to churn. Typically, the inclusion and classification of a customer in these segments is determined by some calculation process such as predictive modeling. We would not normally assign a customer a classification in a derived segment merely by assessing the value of some attribute. It is sensible , therefore, to modify our general model to incorporate derived segments, as shown in Figure 3.12.
Figure 3.12. General conceptual model for a customer-centric data warehouse.
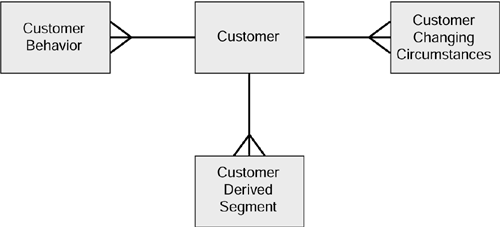
So this is it. The diagram in Figure 3.12 is the boiled-down general model for a customer centric data warehouse. In theory, it should be able to answer almost any question we might care to throw at it. I say in theory because in reality the model will be far more complex than this. We will need to be able to cope with customers whose classification changes. For example, we might have a derived segment called life time value where every customer is allocated an indicator with a value from, say, 1 to 20. Now, Lucie Jones might have a lifetime value indicator of 9. But when Lucie's salary increases , she might be allocated a lifetime value indicator of 10. It might be useful to some companies to invent a new segment called, say, increasing life time values. This being the case, we may need to track Lucie's lifetime value indicator over time. When we bring time into our segmentation processes, the possibilities become endless. However, the introduction of time also brings with it some very difficult problems, and these will be discussed in the next chapter.
Our model can be described as a general conceptual model (GCM) for a customer-centric data warehouse. The GCM provides us with a template from which all our actual conceptual models in the future can be derived. While we are on the subject of conceptual models, I firmly believe it is high time that we reintroduce the conceptual, logical, and physical data model trilogy into our design process.
Whatever Happened to the Conceptual/Logical/Physical Trilogy?
In the old days there was tradition in which we used a three-stage process for designing a database. The first model that was developed was called the conceptual data model and it was usually represented by an entity relationship diagram (ERD). The purpose of the ERD was to provide an abstraction that represented the data requirements of the organization. Most people with any experience of database design would be familiar with the ERD approach to designing databases.
One major characteristic of the conceptual model is that it ought to be able to be implemented using any type of database. In the 1970s, the relational database was not the most widely used type of DBMS. In those days, the databases tended to be:
-
Hierarchical databases
-
Network databases
The idea was that the DBMS to be ultimately deployed should not have any influence over the way in which the requirements were expressed . So the conceptual data model should not imply the technology to be used in implementing the solution.
Once the DBMS had been chosen , then a logical model would be produced. The logical model was normally expressed as a schema in textual form. So, for instance, where the solution was to be implemented using a relational database, a relational schema would be produced. This consisted of a set of relations, the relationships expressed as foreign key constraints, and a set of domains from which the attributes of the relations would draw their values.
The physical data model consisted of the data definition language (DDL) statements that were needed to actually build, in a relational environment, the tables, indexes, and constraints. This is sometimes referred to as the implementation model.
One of the strengths of the trilogy is that decisions relating to the logical and physical design of the database could be taken and implemented without affecting the abstract model that reflected the business requirements.
The astonishing dominance of relational databases since the mid-1980s has led, in practice, to a blurring of the boundaries between the three models, and it is not uncommon nowadays for a single model to be built, again in the form of an ERD. This ERD is then converted straight into a set of tables in the database. The conceptual model, logical model, and physical model are treated as the same thing. This means that any changes that are made to the design for, say, performance-enhancing reasons are reflected in the conceptual model as well as the physical model. The inescapable conclusion is that the business requirements are being changed for performance reasons. Under normal circumstances, in OLTP-type databases for instance, we might be able to debate the pros and cons of this approach because the business users don't ever get near the data model, and it is of no interest to them. They can, therefore, be shielded from it. But data warehouses are different. There can be no debate; the users absolutely have to understand the data in the data warehouse. At least they have to understand that part of it that they use. For this reason, the conceptual data model, or something that can replace its intended role, must be reintroduced as a necessary part of the development lifecycle of data warehouses.
There is another reason why we need to reinvent the conceptual data model for data warehouse development. As we observed earlier, in the past 15 years , the relational database has emerged as a de facto standard in most business applications. However, to use the now well worn phrase, data warehouses are different. Many of the OLAP products are nonrelational, and their logical and physical manifestations are entirely different from the relational model. So the old reasons for having a three- tier approach have returned, and we should respond to this.
The Conceptual Model and the Wine Club
Now that we have the GCM, we can apply its principles to our case study, the Wine Club. We start by defining the information about the customer that we want to store. In the Wine Club we have the following customer attributes:
| Customer Information | |
|---|---|
| Title | |
| Name | |
| Address | |
| Telephone number | |
| Date of birth | |
| Sex | |
| Marital status | |
| Childrens' details | |
| Spouse details | |
| Income | |
| Hobbies and interests | |
| Trade or profession | |
| Employers' details | |
The attributes have to be divided into two types:
-
Attributes that are relatively static (or where previous values can be lost)
-
Attributes that are subject to change
| Customer's Static Information |
|---|
| Title |
| Name |
| Telephone number |
| Date of birth |
| Sex |
| Customer's Changing Information |
| Address |
| Marital status |
| Childrens' details |
| Spouse details |
| Income |
| Hobbies and interests |
| Trade or profession |
| Employers' details |
We now construct a model like the one in Figure 3.13.
Figure 3.13. Wine Club customer changing circumstances.
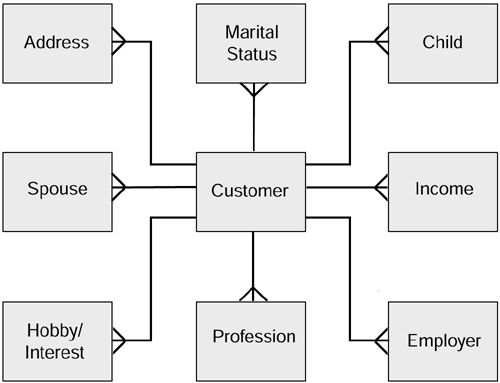
This represents the customer static and changing circumstances. The behavior model is shown in Figure 3.14.
Figure 3.14. Wine Club customer behavior.
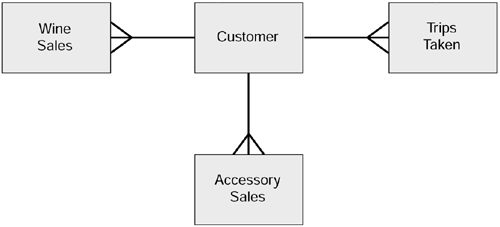
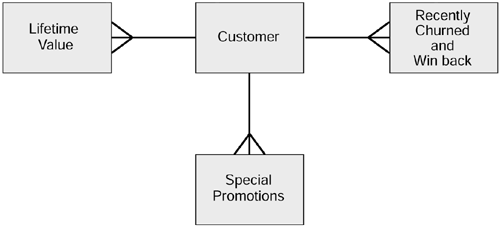
Now, thinking about derived segments, these are likely to be very dynamic in the sense that some derived segments will change over time, some will remain fairly static over time, and others still will appear for a short while and then disappear. Some examples of these, as they apply to the Wine Club, are:
Lifetime value. This is a great way of classifying customers, and every organization should try to do this. It is an example of a fairly static form of segmentation. We would not expect dramatic changes to customers' positions here. It would be good to know which customers are on the generally increasing and the generally decreasing scale.
Recently churned. This is an example of a dynamic classification that will be constantly changing. The ones that we lose that had good lifetime value classifications would appear in our Win back derived segment.
Special promotions. These can be good examples where a kind of one-off segment can be used effectively. In the Wine Club there would be occasions when, for instance, it needs to sell off a particular product quickly. The requirement would be to determine the customers most likely to buy the product. This would involve examination of previous behavior as well as circumstances (e.g., income category in the case of an expensive wine). The point is that this is a use once segment.
Using the three examples above, our derived segments model looks as shown in Figure 3.15.
Figure 3.15. Derived segment examples for the Wine Club.
There is a design issue with segments generally, and that is their general dynamic nature. The marketing organization will constantly want to introduce new segments. Many of them will be of the fairly static and dynamic types that will have long lives in the data warehouse. What we don't want is for the data warehouse administrator to have to get involved in the creation of new tables each time a new classification is invented. This, in effect, results in frequent changes to the data warehouse structure and will lead to the marketing people getting involved in complex change control procedures and might ultimately result in a stifling of creativity. So we need a way of allowing the marketing people to add new derived segments without involving the database administrators too much. Sure, they might need help in expressing the selection criteria, but we don't want to put too many obstacles in their path . This issue will be explored in more detail in Chapter 7 ”the physical model.
| only for RuBoard - do not distribute or recompile |
EAN: 2147483647
Pages: 96