68 Tracking Changes on Web Pages
#68 Tracking Changes on Web Pages
Sometimes great inspiration comes from seeing an existing business and saying to yourself, "That doesn't seem too hard." The task of tracking changes on a website is a surprisingly simple way of collecting such inspirational material, as shown in this script, changetrack . This script does have one interesting nuance: When it detects changes to the site, it emails the new web page, rather than just reporting it on the command line.
The Code
#!/bin/sh # changetrack - Tracks a given URL and, if it's changed since the last # visit, emails the new page to the specified address. sitearchive="/usr/tmp/changetrack" # change as desired sendmail="/usr/sbin/sendmail" # might need to be tweaked! fromaddr="webscraper@intuitive.com" # change as desired if [ $# -ne 2 ] ; then echo "Usage: $(basename#!/bin/sh # changetrack - Tracks a given URL and, if it's changed since the last # visit, emails the new page to the specified address. sitearchive="/usr/tmp/changetrack" # change as desired sendmail="/usr/sbin/sendmail" # might need to be tweaked! fromaddr="webscraper@intuitive.com" # change as desired if [ $# -ne 2 ] ; then echo "Usage: $(basename $0) url email" >&2 exit 1 fi if [ ! -d $sitearchive ] ; then if ! mkdir $sitearchive ; then echo "$(basename $0) failed: couldn't create $sitearchive." >&2 exit 1 fi chmod 777 $sitearchive # you might change this for privacy fi if [ "$(echo $1 cut -c1-5)" != "http:" ] ; then echo "Please use fully qualified URLs (e.g., start with 'http://')" >&2 exit 1 fi fname="$(echo $1 sed 's/http:\/\///g' tr '/?&' '...')" baseurl="$(echo $1 cut -d/ -f1-3)/" # Grab a copy of the web page into an archive file. Note that we can # track changes by looking just at the content (e.g., '-dump', not # '-source'), so we can skip any HTML parsing ... lynx -dump "$1" uniq > $sitearchive/${fname}.new if [ -f $sitearchive/$fname ] ; then # We've seen this site before, so compare the two with 'diff' if diff $sitearchive/$fname $sitearchive/${fname}.new > /dev/null ; then echo "Site $1 has changed since our last check." else rm -f $sitearchive/${fname}.new # nothing new... exit 0 # no change, we're outta here fi else echo "Note: we've never seen this site before." fi # For the script to get here, the site must have changed, and we need to send # the contents of the .new file to the user and replace the original with the # .new for the next invocation of the script. ( echo "Content-type: text/html" echo "From: $fromaddr (Web Site Change Tracker)" echo "Subject: Web Site $1 Has Changed" echo "To: $2" echo "" lynx -source $1 \ sed -e "s[sS][rR][cC]=\"SRC=\"$baseurlg" \ -e "s[hH][rR][eE][fF]=\"HREF=\"$baseurlg" \ -e "s$baseurl\/http:http:g" ) $sendmail -t # Update the saved snapshot of the website mv $sitearchive/${fname}.new $sitearchive/$fname chmod 777 $sitearchive/$fname # and we're done. exit 0) url email" >&2 exit 1 fi if [ ! -d $sitearchive ] ; then if ! mkdir $sitearchive ; then echo "$(basename#!/bin/sh # changetrack - Tracks a given URL and, if it's changed since the last # visit, emails the new page to the specified address. sitearchive="/usr/tmp/changetrack" # change as desired sendmail="/usr/sbin/sendmail" # might need to be tweaked! fromaddr="webscraper@intuitive.com" # change as desired if [ $# -ne 2 ] ; then echo "Usage: $(basename $0) url email" >&2 exit 1 fi if [ ! -d $sitearchive ] ; then if ! mkdir $sitearchive ; then echo "$(basename $0) failed: couldn't create $sitearchive." >&2 exit 1 fi chmod 777 $sitearchive # you might change this for privacy fi if [ "$(echo $1 cut -c1-5)" != "http:" ] ; then echo "Please use fully qualified URLs (e.g., start with 'http://')" >&2 exit 1 fi fname="$(echo $1 sed 's/http:\/\///g' tr '/?&' '...')" baseurl="$(echo $1 cut -d/ -f1-3)/" # Grab a copy of the web page into an archive file. Note that we can # track changes by looking just at the content (e.g., '-dump', not # '-source'), so we can skip any HTML parsing ... lynx -dump "$1" uniq > $sitearchive/${fname}.new if [ -f $sitearchive/$fname ] ; then # We've seen this site before, so compare the two with 'diff' if diff $sitearchive/$fname $sitearchive/${fname}.new > /dev/null ; then echo "Site $1 has changed since our last check." else rm -f $sitearchive/${fname}.new # nothing new... exit 0 # no change, we're outta here fi else echo "Note: we've never seen this site before." fi # For the script to get here, the site must have changed, and we need to send # the contents of the .new file to the user and replace the original with the # .new for the next invocation of the script. ( echo "Content-type: text/html" echo "From: $fromaddr (Web Site Change Tracker)" echo "Subject: Web Site $1 Has Changed" echo "To: $2" echo "" lynx -source $1 \ sed -e "s[sS][rR][cC]=\"SRC=\"$baseurlg" \ -e "s[hH][rR][eE][fF]=\"HREF=\"$baseurlg" \ -e "s$baseurl\/http:http:g" ) $sendmail -t # Update the saved snapshot of the website mv $sitearchive/${fname}.new $sitearchive/$fname chmod 777 $sitearchive/$fname # and we're done. exit 0) failed: couldn't create $sitearchive." >&2 exit 1 fi chmod 777 $sitearchive # you might change this for privacy fi if [ "$(echo cut -c1-5)" != "http:" ] ; then echo "Please use fully qualified URLs (e.g., start with 'http://')" >&2 exit 1 fi fname="$(echo sed 's/http:\/\///g' tr '/?&' '...')" baseurl="$(echo cut -d/ -f1-3)/" # Grab a copy of the web page into an archive file. Note that we can # track changes by looking just at the content (e.g., '-dump', not # '-source'), so we can skip any HTML parsing ... lynx -dump "" uniq > $sitearchive/${fname}.new if [ -f $sitearchive/$fname ] ; then # We've seen this site before, so compare the two with 'diff' if diff $sitearchive/$fname $sitearchive/${fname}.new > /dev/null ; then echo "Site has changed since our last check." else rm -f $sitearchive/${fname}.new # nothing new... exit 0 # no change, we're outta here fi else echo "Note: we've never seen this site before." fi # For the script to get here, the site must have changed, and we need to send # the contents of the .new file to the user and replace the original with the # .new for the next invocation of the script. ( echo "Content-type: text/html" echo "From: $fromaddr (Web Site Change Tracker)" echo "Subject: Web Site Has Changed" echo "To: " echo "" lynx -source \ sed -e "s[sS][rR][cC]=\"SRC=\"$baseurlg" \ -e "s[hH][rR][eE][fF]=\"HREF=\"$baseurlg" \ -e "s$baseurl\/http:http:g" ) $sendmail -t # Update the saved snapshot of the website mv $sitearchive/${fname}.new $sitearchive/$fname chmod 777 $sitearchive/$fname # and we're done. exit 0
How It Works
Given a website URL and a destination email address, this script grabs the URL's web page content and compares it against the content of the site from the previous check.
If it's changed, the new web page is emailed to the specified recipient, with some simple rewrites to try to keep the graphics and HREF s working. These HTML rewrites are worth examining:
lynx -source \ sed -e "s[sS][rR][cC]=\"SRC=\"$baseurlg" \ -e "s[hH][rR][eE][fF]=\"HREF=\"$baseurlg" \ -e "s$baseurl\/http:http:g"
The call to lynx retrieves the source of the specified web page, and then sed performs three different translations. SRC=" is rewritten as SRC="baseurl/ to ensure that any relative pathnames of the nature SRC="logo.gif" are rewritten to work properly as full pathnames with the domain name. If the domain name of the site is http://www.intuitive.com/ , the rewritten HTML would be: SRC=" http://www.intuitive.com/logo.gif " . HREF attributes are similarly rewritten, and then, to ensure we haven't broken anything, the third translation pulls the baseurl back out of the HTML source in situations where it's been erroneously added. For example, HREF=" http://www.intuitive.com/http://www. some-whereelse .com/link " is clearly broken and must be fixed for the link to work.
Notice also that the recipient address is specified in the echo statement ( echo "To: $2" ) rather than as an argument to sendmail . This is a simple security trick: By having the address within the sendmail input stream (which sendmail knows to parse for recipients because of the -t flag), there's no worry about users playing games with addresses like "joe;cat /etc/passwdmail larry" . It's a good technique to use for all invocations of sendmail within shell scripts.
Running the Script
This script requires two parameters: the URL of the site being tracked (and you'll need to use a fully qualified URL that begins with http:// for it to work properly) and the email address of the person or comma-separated group of people who should receive the updated web page, as appropriate.
The Results
The first time the script sees a web page, the page is automatically mailed to the specified user:
$ changetrack http://www.intuitive.com/blog/ taylor@intuitive.com Note: we've never seen this site before.
The resultant emailed copy of the site, while not exactly as it would appear in the web browser, is still quite readable, as shown in Figure 7-2.
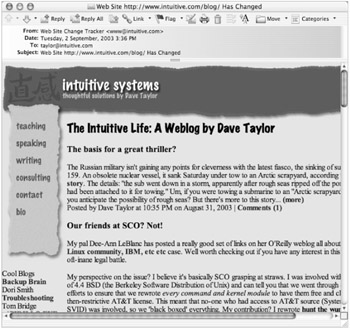
Figure 7-2: The site has changed, so the page is sent via email from changetrack
All subsequent checks of http://www.intuitive.com/blog/ will produce an email copy of the site only if the page has changed since the last invocation of the script. This change can be as simple as a single value or as complex as a complete redesign. While this script can be used for tracking any website, sites that don't change frequently will probably work best: If the site changes every few hours (such as the CNN home page), checking for changes is a waste of CPU cycles, because it'll always be changed.
When the script is invoked the second time, nothing has changed, and so it has no output and produces no electronic mail to the specified recipient:
$ changetrack http://www.intuitive.com/blog/ taylor@intuitive.com $
Hacking the Script
There are a lot of ways you can tweak and modify this script to make it more useful. One change could be to have a "granularity" option that would allow users to specify that if only one line has changed, don't consider it updated. (Change the invocation of diff to pipe the output to wc -l to count lines of output changed to accomplish this trick.)
This script is also more useful when invoked from a cron job on a daily or weekly basis. I have similar scripts that run every night and send me updated web pages from various sites that I like to track. It saves lots of time-wasting surfing!
Most interesting of the possible hacks is to modify this script to work off a data file of URLs and email addresses, rather than requiring those as input parameters. Drop that modified version of the script into a cron job, write a web-based front end to the utility, and you've just duplicated a function that some companies charge people money to use on the Web. No kidding.
| Another way to track changes | There's another way to track web page changes that's worth a brief mention: RSS. Known as Really Simple Syndication, RSS-enabled web pages have an XML version of the site that makes tracking changes trivial, and there are a number of excellent RSS trackers for Windows, Mac, and Linux/Unix. A good place to start learning about RSS is http://rss.intuitive.com/ . The vast majority of sites aren't RSS enabled, but it's darn useful and worth keeping an eye on! |