Section 5.1. Files
5.1. FilesIn the following pages we will look at files from the user's point of view, that is, how they are used and what properties they have. 5.1.1. File NamingFiles are an abstraction mechanism. They provide a way to store information on the disk and read it back later. This must be done in such a way as to shield the user from the details of how and where the information is stored, and how the disks actually work. Probably the most important characteristic of any abstraction mechanism is the way the objects being managed are named, so we will start our examination of file systems with the subject of file naming. When a process creates a file, it gives the file a name. When the process terminates, the file continues to exist and can be accessed by other processes using its name. The exact rules for file naming vary somewhat from system to system, but all current operating systems allow strings of one to eight letters as legal file names. Thus andrea, bruce, and cathy are possible file names. Frequently digits and special characters are also permitted, so names like 2, urgent!, and Fig. 2-14 are often valid as well. Many file systems support names as long as 255 characters. Some file systems distinguish between upper- and lower-case letters, whereas others do not. UNIX (including all its variants) falls in the first category; MS-DOS falls in the second. Thus a UNIX system can have all of the following as three distinct files: maria, Maria, and MARIA. In MS-DOS, all these names refer to the same file. Windows falls in between these extremes. The Windows 95 and Windows 98 file systems are both based upon the MS-DOS file system, and thus inherit many of its properties, such as how file names are constructed. With each new version improvements were added but the features we will discuss are mostly common to MS-DOS and "classic" Windows versions. In addition, Windows NT, Windows 2000, and Windows XP support the MS-DOS file system. However, the latter systems also have a native file system (NTFS) that has different properties (such as file names in Unicode). This file system also has seen changes in successive versions. In this chapter, we will refer to the older systems as the Windows 98 file system. If a feature does not apply to the MS-DOS or Windows 95 versions we will say so. Likewise, we will refer to the newer system as either NTFS or the Windows XP file system, and we will point it out if an aspect under discussion does not also apply to the file systems of Windows NT or Windows 2000. When we say just Windows, we mean all Windows file systems since Windows 95. Many operating systems support two-part file names, with the two parts separated by a period, as in prog.c. The part following the period is called the file extension and usually indicates something about the file, in this example that it is a C programming language source file. In MS-DOS, for example, file names are 1 to 8 characters, plus an optional extension of 1 to 3 characters. In UNIX, the size of the extension, if any, is up to the user, and a file may even have two or more extensions, as in prog.c.bz2, where .bz2 is commonly used to indicate that the file (prog.c) has been compressed using the bzip2 compression algorithm. Some of the more common file extensions and their meanings are shown in Fig. 5-1
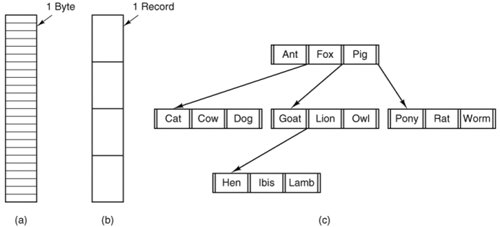
In some systems (e.g., UNIX), file extensions are just conventions and are not enforced by the operating system. A file named file.txt might be some kind of text file, but that name is more to remind the owner than to convey any actual information to the computer. On the other hand, a C compiler may actually insist that files it is to compile end in .c, and it may refuse to compile them if they do not. Conventions like this are especially useful when the same program can handle several different kinds of files. The C compiler, for example, can be given a list of files to compile and link together, some of them C files (e.g., foo.c), some of them assembly language files (e.g., bar.s), and some of them object files (e.g., other.o). The extension then becomes essential for the compiler to tell which are C files, which are assembly files, and which are object files. In contrast, Windows is very much aware of the extensions and assigns meaning to them. Users (or processes) can register extensions with the operating system and specify which program "owns" which one. When a user double clicks on a file name, the program assigned to its file extension is launched and given the name of the file as parameter. For example, double clicking on file.doc starts Microsoft Word with file.doc as the initial file to edit. Some might think it odd that Microsoft chose to make common extensions invisible by default since they are so important. Fortunately most of the "wrong by default" settings of Windows can be changed by a sophisticated user who knows where to look. 5.1.2. File StructureFiles can be structured in any one of several ways. Three common possibilities are depicted in Fig. 5-2. The file in Fig. 5-2(a) is just an unstructured sequence of bytes. In effect, the operating system does not know or care what is in the file. All it sees are bytes. Any meaning must be imposed by user-level programs. Both UNIX and Windows 98 use this approach. Figure 5-2. Three kinds of files. (a) Byte sequence. (b) Record sequence. (c) Tree. |
Attribute | Meaning |
|---|---|
Protection | Who can access the file and in what way |
Password | Password needed to access the file |
Creator | ID of the person who created the file |
Owner | Current owner |
Read-only flag | 0 for read/write; 1 for read only |
Hidden flag | 0 for normal; 1 for do not display in listings |
System flag | 0 for normal files; 1 for system file |
Archive flag | 0 for has been backed up; 1 for needs to be backed up |
ASCII/binary flag | 0 for ASCII file; 1 for binary file |
Random access flag | 0 for sequential access only; 1 for random access |
Temporary flag | 0 for normal; 1 for delete file on process exit |
Lock flags | 0 for unlocked; nonzero for locked |
Record length | Number of bytes in a record |
Key position | Offset of the key within each record |
Key length | Number of bytes in the key field |
Creation time | Date and time the file was created |
Time of last access | Date and time the file was last accessed |
Time of last change | Date and time the file has last changed |
Current size | Number of bytes in the file |
Maximum size | Number of bytes the file may grow to |
The first four attributes relate to the file's protection and tell who may access it and who may not. All kinds of schemes are possible, some of which we will study later. In some systems the user must present a password to access a file, in which case the password must be one of the attributes.
The flags are bits or short fields that control or enable some specific property. Hidden files, for example, do not appear in listings of the files. The archive flag is a bit that keeps track of whether the file has been backed up. The backup program clears it, and the operating system sets it whenever a file is changed. In this way, the backup program can tell which files need backing up. The temporary flag allows a file to be marked for automatic deletion when the process that created it terminates.
The record length, key position, and key length fields are only present in files whose records can be looked up using a key. They provide the information required to find the keys.
The various times keep track of when the file was created, most recently accessed and most recently modified. These are useful for a variety of purposes. For example, a source file that has been modified after the creation of the corresponding object file needs to be recompiled. These fields provide the necessary information.
The current size tells how big the file is at present. Some old mainframe operating systems require the maximum size to be specified when the file is created, in order to let the operating system reserve the maximum amount of storage in advance. Modern operating systems are clever enough to do without this feature.
5.1.6. File Operations
Files exist to store information and allow it to be retrieved later. Different systems provide different operations to allow storage and retrieval. Below is a discussion of the most common system calls relating to files.
Create. The file is created with no data. The purpose of the call is to announce that the file is coming and to set some of the attributes.
Delete. When the file is no longer needed, it has to be deleted to free up disk space. A system call for this purpose is always provided.
Open. Before using a file, a process must open it. The purpose of the open call is to allow the system to fetch the attributes and list of disk addresses into main memory for rapid access on later calls.
Close. When all the accesses are finished, the attributes and disk addresses are no longer needed, so the file should be closed to free up some internal table space. Many systems encourage this by imposing a maximum number of open files on processes. A disk is written in blocks, and closing a file forces writing of the file's last block, even though that block may not be entirely full yet.
Read. Data are read from file. Usually, the bytes come from the current position. The caller must specify how much data are needed and must also provide a buffer to put them in.
Write. Data are written to the file, again, usually at the current position. If the current position is the end of the file, the file's size increases. If the current position is in the middle of the file, existing data are overwritten and lost forever.
Append. This call is a restricted form of write. It can only add data to the end of the file. Systems that provide a minimal set of system calls do not generally have append, but many systems provide multiple ways of doing the same thing, and these systems sometimes have append.
Seek. For random access files, a method is needed to specify from where to take the data. One common approach is a system call, seek, that repositions the file pointer to a specific place in the file. After this call has completed, data can be read from, or written to, that position.
Get attributes. Processes often need to read file attributes to do their work. For example, the UNIX make program is commonly used to manage software development projects consisting of many source files. When make is called, it examines the modification times of all the source and object files and arranges for the minimum number of compilations required to bring everything up to date. To do its job, it must look at the attributes, namely, the modification times.
[Page 491] Set attributes. Some of the attributes are user settable and can be changed after the file has been created. This system call makes that possible. The protection mode information is an obvious example. Most of the flags also fall in this category.
Rename. It frequently happens that a user needs to change the name of an existing file. This system call makes that possible. It is not always strictly necessary, because the file can usually be copied to a new file with the new name, and the old file then deleted.
Lock. Locking a file or a part of a file prevents multiple simultaneous access by different process. For an airline reservation system, for instance, locking the database while making a reservation prevents reservation of a seat for two different travelers.
EAN: 2147483647
Pages: 102