Using ADO Recordsets
When you're scaling applications to user demand, it's often necessary to distribute various parts of an application among a number of computers. You have many deployment options. The strategy diagrammed in Figure 1-3 is one of them, and in many cases a reasonable one. According to this strategy, the person deploying the application has opted to place the two data-services objects as near the database as possible. The objects reside on the physical server that also runs the database management system.
The Customer persistent entity class has found its way to a separate application or business server. The webclass and facade classes, however, run on the same server as the Internet server, which of course is Microsoft Internet Information Service (IIS).
Transporting Data Between Servers
When you deploy your distributed application in the fashion illustrated in Figure 1-3, its data must move between servers. After fetching necessary data from the database, the Customer_Fetcher object must return it to the application server that asked for it by making a DCOM call.
Then the data must move to the facade object, which resides on the Internet server. The facade object works closely with the webclass object to display information from the data set on an HTML page.
If the user wants to change any data received from the server, the new version of it must travel all the way back to the database server. In short, in a distributed application, data is constantly being moved between the distributed components and thus between the machines they're installed on. You need to find an efficient, easily managed, and standardized way to move data.
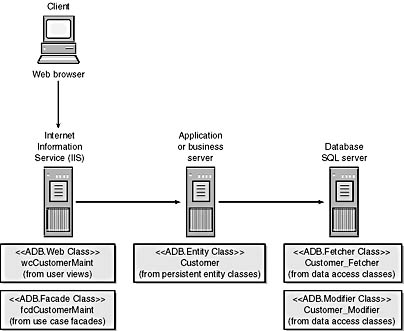
Figure 1-3. A distributed application deployed on four separate computers.
Transporting data is the perfect job for a disconnected ADO recordset
Unlike other COM objects, ADO recordsets can move between processes and machines. I mean really move, not just send references to themselves.
An ordinary COM object doesn't move like that. Instead, it sends a reference to itself to the other machine. Every time a client on that machine sends it a message, the message travels over the network to the never-changing location of the object.
Not so with ADO recordsets. If you follow some simple rules, ADO recordsets will use marshaling to move not only their data but also their metadata across process and even computer boundaries. Here are the rules:
- The ADO recordset must be disconnected from the database. You achieve this by setting the recordset's ActiveConnection property to Nothing.
- The ADO recordset must use the client-side cursor library. You can specify client-side cursors by setting the recordset's CursorLocation property to adUseClient. Otherwise, you can't disconnect the recordset from the database. If the recordset remains connected, as it must if it uses server-side cursors, the recordset refuses to move between machines in your architecture.
Figure 1-4 shows how each object takes advantage of these recordset capabilities. Each object uses an ADO recordset for its data-transportation needs, but also for its state-keeping requirements.
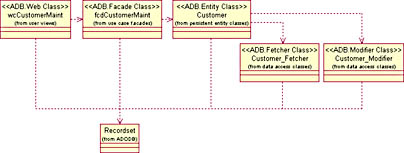
Figure 1-4. Every object in this architecture uses an ADO recordset for its state-keeping and data-transportation requirements.
Using Hierarchical ADO Recordsets
With ADO 2.0 and later, you can design a hierarchy of two or more recordsets contained in one recordset.
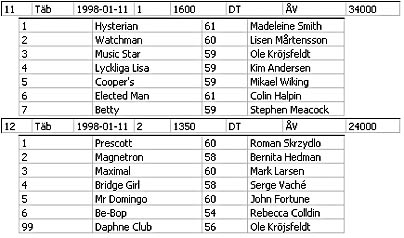
Consider the following case, belonging to a horse-racing application. A use case for this application requires that data about a race be shown on an HTML page. This data should include information about the race itself as well as about each horse entered in the race. You must display the following kinds of information:
- About the race: race track ID, date of race, race number, distance, track type, class, first prize, and so on.
- About each horse entered in the race: position at finish, horse's name, jockey's name, total weight carried, starting gate number, lengths behind winner, and so on.
Now consider another requirement: All the results of the races of a given day should be returned to the user for browsing. That would (at least in Sweden) typically be between 7 and 10 races.
Normally, this requirement would demand two separate recordsets. The first one would contain information about the 10 or so races, the second one about the entrants in each of these races. So you would see something like this:
Races
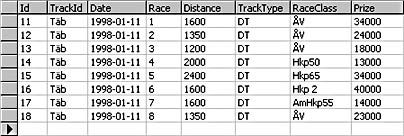
Entrants
We don't show the entire recordset here—only a small part of it to illustrate a point.
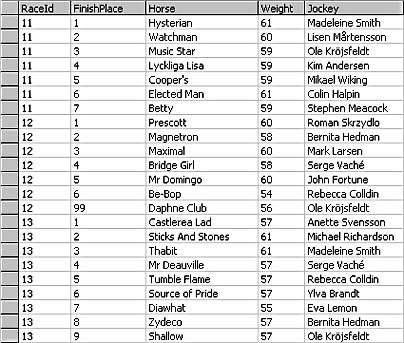
(FinishPlace 99 means that the horse didn't finish the race. Either the horse was scratched from the list of starters or it dropped out at some point during the race.)
Navigating with ease
Using the model we just described, you'll have to use code to navigate two separate recordsets."So what?" you might ask. "This is what I've always done, and it's not such a big deal!"
You're right. But a hierarchical recordset is more convenient to use because it sees the child set as a field in the parent recordset. So when you move to a new race in the recordset, the entrants of the race are the current content of the race entrant recordset. You will be able to see entrants belonging only to the race you're looking at.
Here is the structure of such a recordset.
Races
Id
TrackId
Date
Race
Distance
TrackType
RaceClass
Prize
RaceEntrants
FinishPlace
Horse
Weight
Jockey
In principle, the combined recordset will be organized as follows:
… and so on.
Let's suppose that the first race of the recordset—the 1600-meter race—is the current race and thus the current record of the Races recordset. Let's also suppose that a variable rsRaces refers to this recordset. Furthermore, let's suppose that it's your job to show this race together with all its entrants on an HTML page.
Setting up Visual Basic code for creating an HTML table with one row only, each column containing one piece of information on the race, is easy enough. Here's a code sample that does that:
strTableRace = "<TABLE><TR>" & _ "<TD>" & rsRaces!TrackId & "</TD>" & _ "<TD>" & rsRaces!Date & "</TD>" & _ "<TD>" & rsRaces!Race & "</TD>" & _ "<TD>" & rsRaces!Distance & "</TD>" & _ "<TD>" & rsRaces!TrackType & "</TD>" & _ "<TD>" & rsRaces!RaceClass & "</TD>" & _ "<TD>" & rsRaces!Prize & "</TD>" & _ "</TR></TABLE>" |
It's just as easy to get the data for the entrants of the race. That information belongs to a recordset that's identified by the last field of the rsRaces recordset, the one that's called RaceEntrants in the preceding recordset specification. All you have to do is to save a reference to this recordset in a separate recordset variable. Here goes:
Dim rsEntrants As Recordset Set rsEntrants = rsRaces("RaceEntrants").Value |
Then you can run through this recordset, creating one HTML table row for each record and one HTML table cell for each field to display:
strTableEntrants = "<TABLE>" While Not rsEntrants.EOF strTableEntrants = strTableEntrants & "<TR>" & _ "<TD>" & rsEntrants!FinishPlace & "</TD>" & _ "<TD>" & rsEntrants!HorseName & "</TD>" & _ "<TD>" & rsEntrants!Weight & "</TD>" & _ "<TD>" & rsEntrants!Jockey & "</TD>" & _ "</TR>" rsEntrants.MoveNext Wend strTableEntrants = strTableEntrants & "</TABLE>" |
The rsEntrants recordset exposes only the horses of the current race. So you can, as the preceding code suggests, use EOF to check when you have gone through the entire set of entrants for the race—even though the subordinate recordset, in fact, contains all the entrants of all the races in the rsRaces recordset.
So one of the things the hierarchical recordset does for you is to automatically filter the child recordset as you move through the parent recordset.
Moving data with ease
On top of making navigation through the combined recordset easier, a hierarchical recordset is also easier to transport between processes and computers than two or more separate recordsets would be.
In this respect, you treat a hierarchical recordset just as you would any ordinary recordset. The operations that don't look into the details of the recordset don't even have to know that it is hierarchical.
In contrast, when you use separate recordsets, as we had to do in the past, you have almost no choice but to transport them separately, as distinct recordsets. Your other alternative (other than to use a hierarchical recordset) would be to pack them together in a Variant array, using one array element for each recordset. Of course, if you do, you'll also have to unpack them using tailor-made code.
So one of the goals of hierarchical recordsets is to make life a little bit easier for you as a developer.
Going for gold?
Is everything gold that's bright and shining and the color of gold? Unfortunately not! Hierarchical recordsets could be very valuable to us as developers. They are, however, not yet everything we could have wished. There are issues, and we'll cover them as we take you through this book. Let's just mention two examples here, both of which will be covered in more detail in Chapter 19, "Hierarchical Recordsets—Pros and Cons":
- There are two methods of relating parent and child to each other. One of them relates one or more fields in the parent records to parameters in the child records. If you use this method, your recordset won't disconnect. Since it won't disconnect, it will stay on the server on which it was created. Consequently, all calls to it will be expensive remote calls. Furthermore, the object that created it won't deactivate itself as it should. (See Chapter 14, "Using Microsoft Transaction Server," and Chapter 15, "A COM+ Overview.") This hurts the scalability of your application.
- The other method always relates fields in the parent records to fields in the child records. All the recordsets involved will be filled immediately, and the recordset will disconnect if asked. However, if you don't take certain measures, described in Chapter 19, all the child records that exist in the database will be fetched into the child recordset, even if they're not related to any of the parent records fetched. The recordset will then locally filter child recordsets to show only those that relate to parent records. In bad cases, millions of records will fill a recordset, even if you need only a few dozen of them.
When (if?) these issues are resolved, I'm sure that we shall all fall in love with this new breed of recordset. Should they not be resolved, you can still love hierarchical recordsets, making allowance for their shortcomings as explained in Chapter 19.
As yet, we make no recommendation about hierarchical recordsets. You must decide for yourself whether or not to use them. If you decide to use them, you must use them properly because using them poorly could hurt the performance and scalability of your application.
We've dedicated Chapter 19 to helping you decide. In it we give you valuable information on how hierarchical recordsets work, how they can hurt you, and what you can do to prevent them from hurting you. Also, in Chapter 23, "Some Final Issues," is a section called "Complex Transactions." That section gives you an example of advanced use of hierarchical recordsets in a complex transactional environment. We hope the information in those chapters will give you a good idea of how you can make hierarchical recordsets work for you rather than against you.
EAN: 2147483647
Pages: 133