XPath
Identifying sections of XML documents is an essential part of using Extensible Stylesheet Language (XSL) and XPath. XSL is based on the idea of identifying sections of an XML document and transforming them according to a set of rules. XPath provides a means for identifying sections of an XML document.
XPath is based on the idea of repeating patterns. XML documents develop distinctive patterns in the way their elements are presented and ordered. For example, in Chapter 5 we put an a element within the body element of an XML document to create an anchor to the top of the document. This established a pattern in which the a element was always included within a p element and the p element was included within the body element. We also had a pattern in which the a element was included in a p element within a td element. In this instance, the a element was used as a hyperlink. Thus, the body, p, a pattern represents an anchor and the td, p, a pattern represents a hyperlink.
If you can identify these two patterns in the document, you can use XSL to transform the two a elements in different ways—for example, the hyperlinks can be underlined and displayed in a specified color, and the anchor can be made invisible in the document. Pattern identification enables XSL to find specific elements and transform them in a specified manner. We'll have a detailed discussion of XSL in Chapter 12.
You can also use patterns to select and link to specific sections of a document. For example, you could create a link that finds all of the item_name elements in a purchase order document and returns a reference to these elements. In both XLink and XSL, XPath is used to identify portions of an XML document. Let's begin with location paths.
Location Paths
The XPath specification is designed to address different parts of the XML document through the use of location paths. The location path provides instructions for navigating to any location in an XML document. You can use XPointer to specify an absolute location or a relative location. An absolute location points to a specific place in the document structure. A relative location points to a place that is dependent upon a starting location. If you were giving directions, an absolute location would be 12 Main Street, whereas a relative location would be drive 1 mile up Main Street from the intersection of Oak Street and Main Street. In the case of an XML document, an absolute location would be the root or the second customer element. A relative path would be the fourth child node of the root.
The entire XML document is called the document element. The document is represented as a treelike structure where location paths return sets of nodes on node axes. Movement will occur up and down these node axes.
Types of Nodes
The XPath data model includes seven possible node types: root, element, attribute, namespace, processing instruction, comment, and text. Let's look at each of these node types in detail.
root nodes
The root node is at the root of the tree. It is the parent of the document element. As mentioned, in XPath the document element contains the entire document. The root node contains element nodes. It also contains all of the processing instructions and comments that occur in the prolog and end of the document. The prolog consists of two optional parts: the XML declaration and a DTD.
element nodes
Every element in the document has a corresponding element node. The children of an element node include other element nodes, comment nodes, processing instruction nodes, and text nodes for their content. When you view an element node, all internal and external entity references are expanded. All character references are resolved. The descendants of an element node are the children of the element and their descendants.
The value for an element node is the string that results from concatenating all the character content in all the element's descendants. The value for the root node and the document element node are the same. Element nodes are ordered according to the order of the begin tags of the elements in the document after expansion of general entities. This ordering is called document order.
An element node can have a unique identifier that is declared in the DTD as ID. No two elements can have the same value for an ID in the same document. If two elements have the same ID in the same document, the document is invalid.
attribute nodes
Each element has an associated set of attribute nodes. An attribute that is using a default value is treated the same as an attribute that has a specified value. For an optional attribute (declared as #IMPLIED) that has no default value, if there is no value specified for the attribute, there will be no node for this attribute.
Each attribute node has a name and a string value. The value can be a zero length string ("").
namespace nodes
Every element has an associated set of namespace nodes, one for each namespace prefix that is within the scope of the element and one for the default namespace if it exists. This means that there will be a namespace node for the following attributes:
- Every attribute of the element whose name begins with xmlns;
- Every attribute of an ancestor element whose name begins with xmlns (unless the ancestor element has been used previously);
- The xmlns attribute, unless its value is an empty string
Each namespace node has a name, which is a string giving the prefix, and a value, which is the namespace URI.
processing instruction nodes
An XML parser ignores processing instructions, but they can be used to pass instructions to an XML application. Every processing instruction in the XML document has a corresponding processing instruction node. Currently, processing instructions located within the DTD don't have corresponding processing instruction nodes. A processing instruction node has a name, which is a string equal to the processing instruction's target, and a value, which is a string containing the characters following the target and ending before the terminating ?> characters.
comment nodes
Every comment in the XML document has a corresponding comment node. Every comment node has a value, which is a string containing the comment text.
text nodes
All character content is grouped into text nodes. Text nodes do not have preceding or following text nodes.
Node Axes
Each element in the XML document can be considered a point in the tree structure. These element points can be seen as having a set of axes, each containing nodes extending from the element point. For example, you could have the following XML fragment:
<message> <customer customerID = "c1" customerName = "John Smith"/> <customer customerID = "c2" customerName = "William Jones"/> <order orderID = "o100" customerID = "1"/> </message> |
As shown in Figure 6-1, this message element has a child axis that consists of three nodes: two customer element nodes and one order element node.
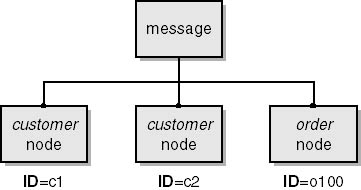
Figure 6-1. Representation of a child axis consisting of three nodes.
Thus, each axis moves through the element tree, selecting a set of nodes based on its axis type (child in this example), and places these elements on the axis. Using node axes, you can select a set of elements within the document. The syntax for an XPath node axis is shown here:
context axis::name |
The name can be the name of an element, attribute, or other node. The context is the starting point of the path, which is usually the root of the XML document. The axis is the type of the axis that you want to select. As you will see, this format is extremely flexible and will allow you to select any pattern of elements within your XML documents.
The root element can be represented by a slash (/). When the root element is used as the context, it is equivalent to the document element.
XPath defines the following types of the node axis:
- child The child axis selects all children of the context element in document order.
- descendant The descendant axis contains all the descendants of the context node in document order. A descendant can be a child, a child of a child, and so on. The descendant axis does not contain attribute or namespace nodes.
- parent The parent axis contains the parent of the context node.
- following-sibling The following-sibling axis contains the following siblings of the context node in document order. A sibling is an element on the same level of the tree. If the context node is either an attribute or a namespace node, the following-sibling axis is empty.
- preceding-sibling The preceding-sibling axis contains the preceding siblings. If the context node is either an attribute or a name-space node, the preceding-sibling axis is empty.
- following The following axis contains the nodes in the same document as the context node that are immediately after the context node. Attribute, namespace, and descendant nodes are not included on the following axis.
- preceding The preceding axis contains all the nodes in the same document as the context node that are immediately before the context node. Attribute, namespace, and ancestor nodes are not included on the preceding axis.
- ancestor The ancestor axis contains all the context node ancestors, including the context node's parent, the parent's parent, and so on. The ancestor axis will store the nodes in reverse document order.
- attribute The attribute axis contains the attributes of the context node. There are three possible attribute axes. If you use the following syntax, the attribute axis will contain the value of the attribute with attributeName:
- namespace The namespace axis contains the namespace nodes of the context nodes; the order will be defined by the implementation. This axis will be empty unless the context node is an element node.
- self The self axis contains only the context node.
- ancestor-or-self The ancestor-or-self axis contains the context node and all the context node's ancestors, in reverse document order.
- descendant-or-self The descendant-or-self axis contains the context node and all the context node's descendants.
attribute::attributeName |
In the following syntax, the attribute axis contains all the elementName elements that have an attribute with the value of attributeName:
elementName[attribute::attributeName] |
Finally, in the following syntax, the axis contains all the elementName elements that have an attribute with the attribute-Name equal to the attributeValue:
elementName[attribute::attributeName=attributeValue] |
All of these axes will be empty unless the context node is an element node.
When an axis contains more than one element, you can select an element by using [position()=positionNumber]. The first element is assigned a positionNumber value of 1.
The following XML document fragment will be used to demonstrate how these axes can be used:
<message> <date>01-01-2001</date> <customer customerID = "c1" customerName = "John Smith"/> <order orderID = "o100"/> <customer customerID = "c2" customerName = "William Jones" > <order orderID = "o101"/> </customer> </message> |
As you can see, this document has a message root element, one date child element, and two customer child elements; each customer element has one order child element. Let's take a look at how an axis selects a set of nodes when it navigates through the element tree according to the instruction provided by the location path. The following table lists the example location paths and the element nodes selected based on these location paths.
Example Location Paths
| Location Path | Description |
|---|---|
| /child::customer | /child selects all the children of the root (the date and two customer elements). /child::customer selects all the customer elements that are children of the root—in this case, there are two customer elements. |
| /descendant::order | /descendant selects all the descendants of the root (the date element, the two customer elements, |
| /descendant-or-self::message | /descendant-or-self selects all the descendants of the root (the date element, the two customer elements, the two order elements, and the message root element). /descendant-or-self::message selects the message element. |
| /child::customer [attribute::customerID= c1] | Selects the customer element that has an attribute with a value of c1. |
| /child::customer [attribute::customerID= c1] [position() = 1] | Selects the first customer element having an attribute with a value of c1 (the first customer element—which is actually the only customer element with an attribute value equal to c1). |
| /child::customer [attribute::customerID= c1] [position() = 1]/following-sibling::customer | Selects all the customer elements that are following siblings to the customer element having an attribute with a value of c1—in this case, the second customer element (customerID = c2). |
| /child::customer [attribute::customerID= c2] [position() = 2]/preceding-sibling::customer | Selects all of the customer elements that are preceding siblings to the customer element having an attribute with a value of c2—in this case, the first customer element (customerID = c1). |
| /following::customer | Selects the two customerelements. |
| /child::customer [attribute::customerID= c1] [position() = 1]/ customer preceding::date | Selects the date elements preceding the first element that has an attribute with a value |
| /self | Selects the message element. |
Basic XPath Patterns
XPath includes a set of terms that can be used to find patterns within an XML document. These patterns are described here:
- node Selects all child elements with a given node name
- * Selects all child elements
- @attr Selects an attribute
- @* Selects all attributes
- ns:* Selects elements in a given namespace
- node() Matches an element node
- text() Matches a text node
- comment() Matches a comment node
- processing-instruction() Matches a processing instruction node
- . (dot) Selects the current node
- .. (double dots) Selects the parent of the current node
- / (slash) Selects the document node
- // (double slash) Selects descendants and self—which is equivalent to descendant-or-self
Note that because the default axis is child, when an axis is omitted, the child axis is used. The XML document fragment mentioned in the previous section is used to demonstrate how to use these basic patterns. The following table lists a set of example XPath patterns and the element nodes selected based on these shortcuts.
Example XPath Patterns
| Location Path | Description |
|---|---|
| /customer | / is equal to /child and selects all the children of the root (the date element and the two customer elements in our sample document). /customer selects all the customer elements that are children of the root—in this case, there are two customer elements. |
| //order | Selects all the order elements that are descendants of the root (document) node—in this case, there are two order elements. |
| /.//order | /.//order is equivalent to /self::node()/descendant- or-self/child/order. /self::node() is the root node, /self:: node()/descendant-or-self selects all of the descendant elements of the root and the root itself, and /self::node()/descendant-or-self/child/order selects the order elements that are descendants of the root. |
| /.//order[@orderID =o100]../customer | /.//order selects the two order elements. [@orderID=o100] selects the order element with an attribute named orderID that has a value equal to o100 (the first order element in the document). .. selects the parent element, /.//order[@orderID =o100]../customer selects the customer element containing the order element with an orderID attribute equal to o100. |
| /descendants[@customerID] | Selects all the elements that are descendants of the root element and that have a customerID attribute (the two customer elements). |
| /* | Selects all the children of the root element (the twocustomer elements and the date element). |
| /*/order | Selects all the order elements that are grandchildren of the root element (in this case, the two order elements). |
| //order[2]/@orderID | //order[2]/ selects the second order element, //order[2]/@orderID retrieves the value of the orderID attribute for the second order element. |
XPath also contains functions. These functions will be discussed when we discuss XSL in Chapter 12.
EAN: 2147483647
Pages: 115