Using Graphical Status Monitors
| I l @ ve RuBoard |
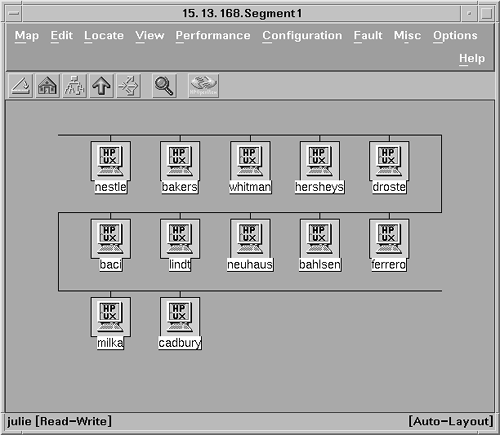
Using Graphical Status MonitorsThe graphical status monitoring tools described in this chapter are also referred to as enterprise management frameworks. These tools monitor multiple systems from a central location and display status information graphically. Because you may not be able to sit at a console or watch the front panel of each system for which you are responsible, you need to be able to monitor system faults from a tool that is external (or remote) to the system. Besides, even if the console or front panel doesn't indicate any problems, network problems can make the system inaccessible to the end- user . Graphical status monitors can detect connectivity problems because they rely on network polls to gather status information. Your server may depend on services provided by other systems. For example, network services such as the Domain Name Service (DNS), Dynamic Host Configuration Protocol (DHCP), Network File System (NFS), and e-mail are critical to the server, but are unlikely to be running on the server that you're monitoring, and consequently aren't tracked by any local monitors. This is critical information, because if the DNS is down, other systems may not be able to reach the system being monitored. Because the enterprise framework products are gathering status information about multiple systems at a central site, it is more likely that both the server and its service providers are being monitored . Graphical status monitors provide many features that can help you to detect system faults, especially hardware or software faults. Most graphical status monitors provide hierarchical maps or visual displays that indicate status information. This saves you the time of correlating event data from logs to determine status. The graphical status monitors provide remote management capabilities, so you aren't required to have a physical console for each system. Furthermore, they can automatically discover the systems in your enterprise, so you don't have to remember system names and manually configure them. A graphical view typically can be customized by setting up filters, so that you see only those systems that you are responsible for managing. This section describes only a couple of the available graphical status monitors. Others with similar system monitoring capabilities, such as HP's IT/O, Sun's Enterprise SyMON, or BMC PATROL, are mentioned in other parts of the book. OpenView Network Node ManagerNetwork Node Manager (NNM) is a management product based on the HP OpenView platform. NNM is used primarily to view and monitor the status of network and system resources. Information is displayed graphically through a window-based display. A hierarchical set of submaps is available, enabling the customer to navigate and drill down through complex network topologies. Network and system components are represented graphically in maps as icons, which are color -coded to indicate the health of the objects represented. Events are propagated, based on severity, to higher-level submaps to indicate events, such as failures, at lower levels. Through pull-down menus available in NNM, the operator can run tools to get additional real-time status information, or remotely log in to the system and execute diagnostic commands. One key feature of NNM is its ability to discover automatically network-addressable components, such as routers, hubs, and computer systems. Because the network discovery activity uses noticeable network resources, you may want to limit it to just the networks that you manage. This can be done by using discovery filters, a configurable option in NNM; or, alternatively, you can schedule discovery process(es) to run during off-peak hours. After discovery is complete, the network topology information is then displayed on submaps, with colors used to indicate status. An operator can navigate through the submaps to find a particular LAN segment to monitor. In addition to viewing systems, an operator can also drill down to see system information, such as configured network interfaces. Figure 4-1 shows a segment map with icons indicating the health of each system in the segment. Figure 4-1. Network Node Manager segment submap shows the health of the systems in the segment. NNM provides mechanisms to collect statistics and generate reports on individual network devices, including systems. NNM periodically checks the status of systems and devices by sending an ICMP echo request (ping). If no reply is received, a Node Down event is sent as an SNMP trap and logged in the Event Browser. NNM also listens to SNMP traps from SNMP supported devices. For instance, if NNM gets a Node Down trap, it changes the color of the icon representing the node that just went down. The NNM Event Browser is a graphical display of the events that have been received from systems on the network. Events are sent to the management station as SNMP traps. The trap handler receives these traps and stores them in a database. The events can be viewed through the Event Browser, and filters can be used to prevent the operator from being flooded with noncritical information. Filters can be configured based on the sending system or event criticality, for example. NNM can also process Common Management Information Protocol (CMIP) events for multivendor interoperability. You can use filtering to get history events from a particular system when troubleshooting a problem. After an event is handled, you can use the Event Browser to acknowledge the event. By using the NNM Event Configuration utility, you can configure how specific SNMP traps should be handled, including the following:
Events can be configured to automatically display a pop-up notification, or to run a command on the management station to send e-mail, call a pager, change an icon color, or generate an audible alert. After you recognize that a problem exists, the NNM menu interface provides many tools to troubleshoot problems or monitor the system in more detail. NNM provides a performance menu that you can use to check network activity, CPU load, and disk space, or to graph SNMP data. A configuration menu is provided so that you can check network configuration, system statistics, or the SNMP trap configuration. From the fault menu, you can try to reach the system through the network connectivity poll, a ping from the management station, or a ping initiated from another remote system. If you suspect that the route to a system is down, you can test that from the fault menu as well. A terminal window, the SAM interface (HP-UX only), and a MIB Browser are all available from the pull-down menus. NNM also provides several utilities to help you gather and process data provided in MIBs. You can configure data collection of MIB objects and define thresholds for when to generate an event. You can build your own MIB application to collect MIB objects for graphing or generating tabular output. As this section has described, OpenView NNM can provide help for numerous system monitoring categories. Faults can be detected and shown graphically, with failure events sent to the Message Browser. You can monitor network performance by using the performance menus. You can check some of the system resource limits by using predefined tools or the MIB Browser. NNM, however, is typically used only if you have many systems to monitor. NNM is a building block for other HP OpenView applications. Application integration is provided through developer's kits and registration files. More than 300 applications are integrated today with HP OpenView. HP IT/O, discussed later, is one product that extends NNM's capabilities. The most commonly used partner applications are CiscoWorks, Bay Networks Optivity, 3Com Transcend, Remedy ARS, and HP NetMetrix. OpenView NNM runs on NT and UNIX platforms. Both versions can be used to monitor UNIX systems. ClusterViewClusterView is a graphical monitoring tool integrated with OpenView NNM and IT/O. It provides monitoring of systems and other resources in MC/ServiceGuard environments. MC/ServiceGuard is a Hewlett-Packard high availability software product that detects system failures, network or LAN card failures, and the failure of critical applications. While MC/ServiceGuard can be configured to handle these failures automatically, it is through ClusterView that you can capture these high availability events and graphically view the health of systems that are part of MC/ServiceGuard clusters. MC/ServiceGuard is supported only on HP 9000 Series 800 systems running HP-UX 10. x or later operating systems. MC/ServiceGuard is most commonly used in a cluster environment. Software on each system monitors the other systems. When system failures occur, MC/ServiceGuard software can detect the problem and automatically restart critical applications on an alternate node. Monitoring of failures is done automatically, but without ClusterView, you may need to use MC/ServiceGuard commands to verify that the cluster software itself is working. MC/ServiceGuard detects numerous cluster events, such as the failure of a critical application. These events can be forwarded to a management station by using either SNMP traps or opcmsg, a proprietary communication mechanism used by IT/O. Information about an MC/ServiceGuard cluster is stored in the HP Cluster and HP MC/ServiceGuard Cluster MIBs. These Cluster MIBs are listed in Appendix A. The following is a list of the MC/ServiceGuard events that trigger SNMP traps from the MC/ServiceGuard subagent:
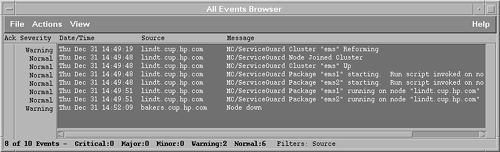
MC/ServiceGuard software detects a variety of error conditions, but it does not have a sophisticated notification mechanism for customers to learn what happened . Errors often are written to the system log, which can be used to help retrace what occurred. Whereas MC/ServiceGuard can monitor the system, network, and processes and provide automatic recovery, ClusterView provides you with event notification of these recovery events. For example, if MC/ServiceGuard detects a local LAN card failure, it can reconfigure the IP con nectivity on a backup LAN card on the local system transparently . Using ClusterView, you will see an event indicating that MC/ServiceGuard has performed a local switch to a backup LAN card. The bad LAN card should be replaced , to eliminate the LAN card as a single point of failure. ClusterView can be used to help you with diagnosis in MC/ServiceGuard environments. ClusterView is an OpenView application with custom monitoring capabilities for MC/ServiceGuard and MC/LockManager clusters. An SNMP subagent that can be used to send events to an OpenView management station is included with the MC/ServiceGuard and MC/LockManager products. These events, sent as SNMP traps, can actually be received by any management station that understands SNMP (for example, Computer Associates' Unicenter product). These events are received in OpenView's event browser. ClusterView provides automatic discovery and real-time status and event notification via the Event Browser and graphical displays of MC/ServiceGuard clusters, systems, and packages. Templates are provided to map the cluster events to readable text. Without these templates, events are unrecognized or unmatched traps in OpenView. With these templates, the traps are formatted in the NNM Event Browser or IT/O Message Browser when ClusterView is installed. When a system failure is detected by MC/ServiceGuard, it moves all critical resources to an alternate node. A series of SNMP traps are generated by the MC/ServiceGuard subagent as an event occurs. Figure 4-2 shows the events in the NNM Event Browser after the system "bakers" fails. MC/ServiceGuard first detects the failure and starts the two packages, ems1 and ems2, on the alternate system, lindt. The Node Down trap is generated by NNM when it detects that system "bakers" is down. Figure 4-2. NNM Event Browser showing MC/ServiceGuard events after a system failure. ClusterView provides additional capabilities when used with IT/O. SNMP events are sent to the Event Browser, where ClusterView provides special troubleshooting instructions and recommends actions to help resolve the problems. Some data collection activities are done automatically. For example, in response to a package failure, ClusterView automatically retrieves the system's system log file entries from the time of failure to aid in diagnosis. Common HP-UX monitoring tools, such as netstat and lanscan, are included by ClusterView in IT/O's Application Desktop, along with MC/ServiceGuard-specific tools, such as cmviewcl. In addition to high availability clusters, ClusterView can monitor user-defined clusters. ClusterView provides a configuration tool that enables the administrator to create a cluster, and then displays that cluster on its cluster submap. The operator can then monitor all the cluster systems at a glance, because they are all in the same OpenView window. Also, the operator can launch monitoring tools, such as HP PerfView, on the cluster, avoiding the need to select each system manually when running each tool. ClusterView can be a useful extension to the capabilities of NNM if you are managing MC/ServiceGuard clusters, MC/LockManager clusters, or groups of systems. You can view detailed screens containing high availability configuration information about your cluster. In addition to processing faults, ClusterView provides recovery actions and troubleshooting help for these events. ClusterView runs on HP-UX and NT systems and requires OpenView NNM or IT/O. The ClusterView software for either platform can also be used to monitor Microsoft's NT Cluster Servers, its high availability clusters. Both NT and MC/ServiceGuard clusters can be monitored concurrently from the same ClusterView software. Unicenter TNGComputer Associates' Unicenter TNG is an enterprise management platform that provides graphical status monitoring and provides system and network management for a heterogeneous enterprise. Unicenter TNG provides monitoring and management for all the resources in your environment, including system resources, networks, databases, and applications. Unicenter TNG provides the framework for an integrated management solution to manage all IT resources via a common infrastructure. The TNG framework itself includes the following components: auto discovery, object repository, Real World interface, event management, calendar management, reporting, virus detection, and desktop support. Together with vendor, third-party, and custom-built applications, Unicenter TNG provides increased management and maintenance capabilities for the enterprise. Unicenter TNG provides automatic discovery of networked objects, including systems and other resources within the enterprise. Information is stored in the Common Object Repository and can be displayed topographically in the Real World interface. Discovery filters can also be used, to limit discovery to a specific subnetwork or to specify which types of resources Unicenter TNG should discover. A Common Object Repository stores the information used to create the Real World graphical views. You can browse the repository by using the Class Browser, Object Browser, or Topology Browser. Using ObjectView, you can get details on the performance of devices, and you can even graph the data. The Real World interface provides graphical views that can be organized based on business functions, geographical location, or any logical groupings. The views can show the topology of the enterprise in two or three dimensions. These views can be used to see the status of the systems and resources in your environment. Unicenter TNG provides management by using a distributed management approach. Distributed agents are responsible for monitoring and control. Centralized managers provide core management throughout the enterprise, including data correlation from one or more agents, workload management, and job management. The agents monitor and control based on policies provided by managers. The agents run on managed nodes and gather data, apply filters, and report when necessary. Some provide control or execution on behalf of the managers. The agents send notifications, and can be polled. The agents can also collect performance data or be configured to send events and perform actions based on thresholds. To view agents and get information about them, Unicenter TNG provides a MIB-II agent display to view MIB-II information, a node view, Distributed State Machine (DSM) view, and an Event Browser. The DSM tracks the status of objects across the network. It gathers information from the repository and agents to maintain the state of objects based on configured policies. The node view displays detailed state information about the system objects that are watched by the DSM. Finally, managing events is one of the core capabilities provided by Unicenter TNG. The hub of event management is at the Unicenter TNG Event Console. You can configure policies to respond automatically to specific events, send SNMP traps based on events, forward events, filter out unimportant events, correlate events from several agents, or feed events into the DSM. In conjunction with the calendar management provided by Unicenter TNG, you can change or set event policies based on the time. For example, you may want to apply different policies during the weekend . |
| I l @ ve RuBoard |
EAN: 2147483647
Pages: 90