 | Normalization is a process of reducing redundancies of data in a database. Normalization is a technique that is used when designing and redesigning a database. Normalization is a process or set of guidelines used to optimally design a database to reduce redundant data. The actual guidelines of normalization, called normal forms, will be discussed later in this hour. It was a difficult decision to decide whether to cover normalization in this book because of the complexity involved in understanding the rules of the normal forms this early on in your SQL journey. However, normalization is an important process that, if understood , will increase your understanding of SQL. We have attempted to simplify the process of normalization as much as possible in this hour. At this point, don't be overly concerned with all the specifics of normalization; it is most important to understand the basic concepts. | The Raw Database A database that is not normalized may include data that is contained in one or more different tables for no apparent reason. This could be bad for security reasons, disk space usage, speed of queries, efficiency of database updates, and, maybe most importantly, data integrity. A database before normalization is one that has not been broken down logically into smaller, more manageable tables. Figure 4.1 illustrates the database used for this book before it was normalized. Figure 4.1. The raw database.  Logical Database Design | | Any database should be designed with the end user in mind. Logical database design, also referred to as the logical model, is the process of arranging data into logical, organized groups of objects that can easily be maintained . The logical design of a database should reduce data repetition or go so far as to completely eliminate it. After all, why store the same data twice? Naming conventions used in a database should also be standard and logical. | What Are the End User's Needs? The needs of the end user should be one of the top considerations when designing a database. Remember that the end user is the person who ultimately uses the database. There should be ease of use through the user's front-end tool (a client program that allows a user access to a database), but this, along with optimal performance, cannot be achieved if the user's needs are not taken into consideration. Some user- related design considerations include the following: -
What data should be stored in the database? -
How will the user access the database? -
What privileges does the user require? -
How should the data be grouped in the database? -
What data is the most commonly accessed? -
How is all data related in the database? -
What measures should be taken to ensure accurate data? Data Redundancy Data should not be redundant, which means that the duplication of data should be kept to a minimum for several reasons. For example, it is unnecessary to store an employee's home address in more than one table. With duplicate data, unnecessary space is used. Confusion is always a threat when, for instance, an address for an employee in one table does not match the address of the same employee in another table. Which table is correct? Do you have documentation to verify the employee's current address? As if data management were not difficult enough, redundancy of data could prove to be a disaster. The Normal Forms | | The next sections discuss the normal forms, an integral concept involved in the process of database normalization. | Normal form is a way of measuring the levels, or depth, to which a database has been normalized. A database's level of normalization is determined by the normal form. The following are the three most common normal forms in the normalization process: -
The first normal form -
The second normal form -
The third normal form Of the three normal forms, each subsequent normal form depends on normalization steps taken in the previous normal form. For example, to normalize a database using the second normal form, the database must first be in the first normal form. The First Normal Form The objective of the first normal form is to divide the base data into logical units called tables. When each table has been designed, a primary key is assigned to most or all tables. Examine Figure 4.2, which illustrates how the raw database shown in the previous figure has been redeveloped using the first normal form. Figure 4.2. The first normal form. 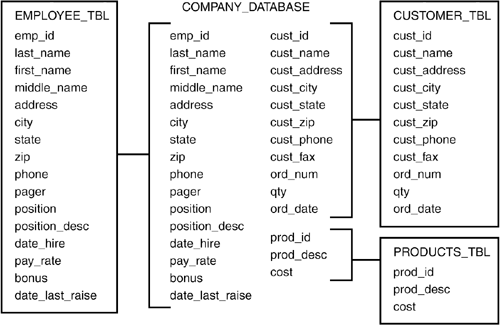 You can see that to achieve the first normal form, data had to be broken into logical units of related information, each having a primary key and ensuring that there are no repeated groups in any of the tables. Instead of one large table, there are now smaller, more manageable tables: EMPLOYEE_TBL, CUSTOMER_TBL, and PRODUCTS_TBL. The primary keys are normally the first columns listed in a table, in this case: EMP_ID, CUST_ID, and PROD_ID . The Second Normal Form The objective of the second normal form is to take data that is only partly dependent on the primary key and enter that data into another table. Figure 4.3 illustrates the second normal form. Figure 4.3. The second normal form. 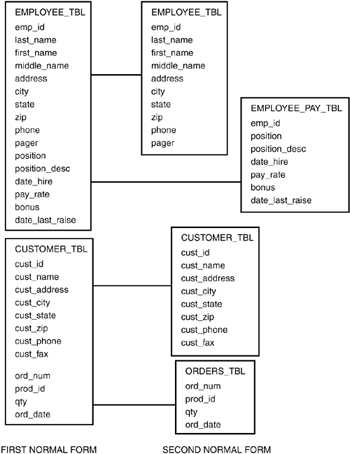 According to the figure, the second normal form is derived from the first normal form by further breaking two tables down into more specific units. EMPLOYEE_TBL split into two tables called EMPLOYEE_TBL and EMPLOYEE_PAY_TBL. Personal employee information is dependent on the primary key (EMP_ID), so that information remained in the EMPLOYEE_TBL (EMP_ID, LAST_NAME, FIRST_NAME, MIDDLE_NAME, ADDRESS, CITY, STATE, ZIP, PHONE, and PAGER). On the other hand, the information that is only partly dependent on the EMP_ID (each individual employee) is used to populate EMPLOYEE_PAY_TBL (EMP_ID, POSITION, POSITION_DESC, DATE_HIRE, PAY_RATE, and DATE_LAST_RAISE). Notice that both tables contain the column EMP_ID. This is the primary key of each table and is used to match corresponding data between the two tables. CUSTOMER_TBL split into two tables called CUSTOMER_TBL and ORDERS_TBL. What took place is similar to what occurred in the EMPLOYEE_TBL. Columns that were partly dependent on the primary key were directed to another table. The order information for a customer is dependent on each CUST_ID, but does not directly depend on the general customer information in the original table. The Third Normal Form The third normal form's objective is to remove data in a table that is not dependent on the primary key. Figure 4.4 illustrates the third normal form. Figure 4.4. The third normal form. 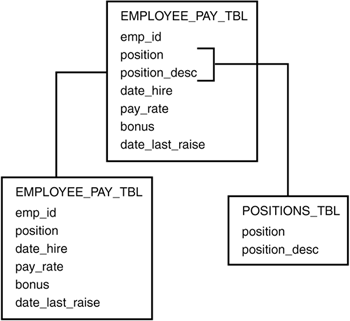 Another table was created to display the use of the third normal form. EMPLOYEE_PAY_TBL is split into two tables, one table containing the actual employee pay information and the other containing the position descriptions, which really do not need to reside in EMPLOYEE_PAY_TBL. The POSITION_DESC column is totally independent of the primary key, EMP_ID . Naming Conventions Naming conventions are one of the foremost considerations when you're normalizing a database. Names are how you will refer to objects in the database. You want to give your tables names that are descriptive of the type of information they contain so that the data you are looking for is easy to find. Descriptive table names are especially important for users querying the database that had no part in the database design. A company-wide naming convention should be set, providing guidance in the naming of not only tables within the database, but users, filenames, and other related objects. Designing and enforcing naming conventions is one of a company's first steps toward a successful database implementation. Benefits of Normalization Normalization provides numerous benefits to a database. Some of the major benefits include the following : -
Greater overall database organization -
Reduction of redundant data -
Data consistency within the database -
A much more flexible database design -
A better handle on database security Organization is brought about by the normalization process, making everyone's job easier, from the user who accesses tables to the database administrator (DBA) who is responsible for the overall management of every object in the database. Data redundancy is reduced, which simplifies data structures and conserves disk space. Because duplicate data is minimized, the possibility of inconsistent data is greatly reduced. For example, in one table an individual's name could read STEVE SMITH, whereas the name of the same individual reads STEPHEN R. SMITH in another table. Because the database has been normalized and broken into smaller tables, you are provided with more flexibility as far as modifying existing structures. It is much easier to modify a small table with little data than to modify one big table that holds all the vital data in the database. Lastly, security is also provided in the sense that the DBA can grant access to limited tables to certain users. Security is easier to control when normalization has occurred. | | Data integrity is the assurance of consistent and accurate data within a database. | Referential Integrity Referential integrity simply means that the values of one column in a table depend on the values of a column in another table. For instance, in order for a customer to have a record in the ORDERS_TBL table, there must first be a record for that customer in the CUSTOMER_TBL table. Integrity constraints can also control values by restricting a range of values for a column. The integrity constraint should be created at the table's creation. Referential integrity is typically controlled through the use of primary and foreign keys. In a table, a foreign key, normally a single field, directly references a primary key in another table to enforce referential integrity. In the preceding paragraph, the CUST_ID in ORDERS_TBL is a foreign key that references CUST_ID in CUSTOMER_TBL. Drawbacks of Normalization Although most successful databases are normalized to some degree, there is one substantial drawback of a normalized database: reduced database performance. The acceptance of reduced performance requires the knowledge that when a query or transaction request is sent to the database, there are factors involved, such as CPU usage, memory usage, and input/output (I/O). To make a long story short, a normalized database requires much more CPU, memory, and I/O to process transactions and database queries than does a denormalized database. A normalized database must locate the requested tables and then join the data from the tables to either get the requested information or to process the desired data. A more in-depth discussion concerning database performance occurs in Hour 18, "Managing Database Users." Denormalizing a Database | | Denormalization is the process of taking a normalized database and modifying table structures to allow controlled redundancy for increased database performance. Attempting to improve performance is the only reason to ever denormalize a database. A denormalized database is not the same as a database that has not been normalized. Denormalizing a database is the process of taking the level of normalization within the database down a notch or two. Remember, normalization can actually slow performance with its frequently occurring table join operations. (Table joins are discussed during Hour 13, "Joining Tables in Queries.") Denormalization may involve recombining separate tables or creating duplicate data within tables to reduce the number of tables that need to be joined to retrieve the requested data, which results in less I/O and CPU time. | There are costs to denormalization, however. Data redundancy is increased in a denormalized database, which can improve performance but requires more extraneous efforts to keep track of related data. Application coding renders more complications, because the data has been spread across various tables and may be more difficult to locate. In addition, referential integrity is more of a chore; related data has been divided among a number of tables. There is a happy medium in both normalization and denormalization, but both require a thorough knowledge of the actual data and the specific business requirements of the pertinent company. |
