| Figure 9.1 shows a script that downloads the URL given on the command line. If successful, the document is printed to standard output. Otherwise , the script dies with an appropriate error message. For example, to download the HTML source for Yahoo's weather page, located at http://www.yahoo.com/r/wt, you would call the script like this: Figure 9.1. Fetch a URL using LWP's object-oriented interface  % get_url.pl http://www.yahoo.com/r/wt > weather.html The script can just as easily be used to download a file from an FTP server like this: % get_url.pl ftp://www.cpan.org/CPAN/RECENT The script will even fetch news articles, provided you know the message ID: % get_url.pl news:3965e1e8.1936939@enews.newsguy.com All this functionality is contained in a script just 10 lines long. Lines 1 “3: Load modules We turn on strict syntax checking and load the LWP module. Line 4: Read URL We read the desired URL from the command line. Line 5: Create an LWP::UserAgent We create a new LWP::UserAgent object by calling its new() method. The user agent knows how to make requests on remote servers and return their responses. Line 6: Create a new HTTP::Request We call HTTP::Request->new() , passing it a request method of "GET" and the desired URL. This returns a new HTTP::Request object. Line 7: Make the request We pass the newly created HTTP::Request to the user agent's request() method. This issues a request on the remote server, returning an HTTP::Response. Lines 8 “9: Print response We call the response object's is_success() method to determine whether the request was successful. If not, we die with the server's error message, returned by the response object's message() method. Otherwise, we retrieve and print the response contents by calling the response object's content() method. Short as it is, this script illustrates the major components of the LWP library. HTTP::Request contains information about the outgoing request from the client to the server. Requests can be simple objects containing little more than a URL, as shown here, or can be complex objects containing cookies, authentication information, and arguments to be passed to server scripts. HTTP::Response encapsulates the information returned from the server to the client. Response objects contain status information, plus the document contents itself. LWP::UserAgent intermediates between client and server, transmitting HTTP::Requests to the remote server, and translating the server's response into an HTTP::Response to return to client code. In addition to its object-oriented mode, LWP offers a simplified procedural interface called LWP::Simple. Figure 9.2 shows the same script rewritten using this module. After loading the LWP::Simple module, we fetch the desired URL from the command line and pass it to getprint() . This function attempts to retrieve the indicated URL. If successful, it prints its content to standard output. Otherwise, it prints a message describing the error to STDERR . Figure 9.2. Fetch a URL using LWP::Simple procedural interface  In fact, we could reduce Figure 9.1 even further to this one-line command: % perl -MLWP::Simple -e 'getprint shift' http://www.yahoo.com/r/wt The procedural interface is suitable for fetching and mirroring Web documents when you do not need control over the outgoing request and you do not wish to examine the response in detail. The object-oriented interface is there when you need to customize the outgoing request by providing authentication information and data to post to a server script, or by changing other header information passed to the server. The object-oriented interface also allows you to interrogate the response to recover detailed information about the remote server and the returned document. HTTP::Request The Web paradigm generalizes all client/server interactions to a client request and a server response. The client request consists of a Uniform Resource Locator (URL) and a request method. The URL, which is known in the LWP documentation by its more general name , URI (for Uniform Resource Identifier), contains information on the network protocol to use and the server to contact. Each protocol uses different conventions in its URLs. The protocols supported by LWP include: HTTP The Hypertext Transfer Protocol, the "native" Web protocol described in RFCs 1945 and 2616, and the one used by all Web servers. HTTP URLs have this familiar form: http://server.name:port/path/to/document The http: at the beginning identifies the protocol. This is followed by the server DNS name, IP address, and, optionally , the port the server is listening on. The remainder of the URL is the path to the document. FTP A document stored on an FTP server. FTP URLs have this form: ftp://server.name:port/path/to/document GOPHER A document stored on a server running the now rarely used gopher protocol. Gopher URLs have this form: gopher://server.name:port/path/to/document SMTP LWP can send mail messages via SMTP servers using mailto: URLs. These have the form: mailto:user@some.host where user@some.host is the recipient's e-mail address. Notice that the location of the SMTP server isn't part of the URL. LWP uses local configuration information to identify the server. NNTP LWP can retrieve a news posting from an NNTP server given the ID of the message you wish to retrieve. The URL format is: news:message-id As in mail: URLs, there is no way to specify the particular NNTP server. A suitable server is identified automatically using Net::NNTP's rules (see Chapter 8). In addition to the URL, each request has a method. The request method indicates the type of transaction that is requested . A number of methods are defined, but the most frequent ones are: GET Fetch a copy of the document indicated by the URL. This is the most common way of fetching a Web page. PUT Replace or create the document indicated by the URL with the document contained in the request. This is most commonly seen in the FTP protocol when uploading a file, but is also used by some Web page editors. POST Send some information to the indicated URL. It was designed for posting e-mail messages and news articles, but was long ago appropriated for use in sending fill-out forms to CGI scripts and other server-side programs. DELETE Delete the document indicated by the URL. This is used to delete files from FTP servers and by some Web-based editing systems. HEAD Return information about the indicated document without changing or downloading it. HTTP protocol requests can also contain other information. Each request includes a header that contains a set of RFC 822-like fields. Common fields include Accept:, indicating the MIME type(s) the client is prepared to receive, User-agent:, containing the name and version of the client software, and Content-type:, which describes the MIME type of the request content, if any. Other fields handle user authentication for password-protected URLs. For the PUT and POST methods, but not for GET, HEAD, and DELETE, the request also contains content data. For PUT, the content is the document to upload to the location indicated by the URL. For POST, the content is some data to send, such as the contents of a fill-out form to send to a CGI script. The LWP library uses a class named HTTP::Request to represent all requests, even those that do not use the HTTP protocol. You construct a request by calling HTTP::Request->new() with the name of the desired request method and the URL you wish to apply the request to. For HTTP requests, you can then add or alter the outgoing headers to do such things as add authentication information or HTTP cookies. If the request method expects content data, you'll normally add the data to the request object using its content () method. The API description that follows lists the most frequently used HTTP:: Request methods. Some of them are defined in HTTP::Request directly, and others are inherited. One begins by creating a new request object with HTTP::Request->new() . | $request = HTTP::Request->new($method, $url [,$header [,$content]]) The new() method constructs a new HTTP::Request. It takes a minimum of two arguments. $method is the name of the request method, such as GET, and $url is the URL to act on. The URL can be a simple string or a reference to a URI object created using the URI module. We will not discuss the URI module in detail here, but it provides functionality for dissecting out the various parts of URLs. | new() also accepts optional header and content arguments. $header should be a reference to an HTTP::Headers object. However, we will not go over the HTTP::Headers API because it's easier to allow HTTP::Request to create a default headers object and then customize it after the object is created. $content is a string containing whatever content you wish to send to the server. Once the request object is created, the header() method can be used to examine or change header fields. | $request->header($field1 => $val1, $field2 => $val2 ...) @values = $request->header($field) Call header() with one or more field/value pairs to set the indicated fields, or with a single field name to retrieve the current values. When called with a field name, header() returns the current value of the field. In a list context, header() returns multivalued fields as a list; in a scalar context, it returns the values separated by commas. | This example sets the Referer: field, which indicates the URL of the document that referred to the one currently being requested: $request->header(Referer => 'http://www.yahoo.com/whats_cool.html') An HTTP header field can be multivalued. For example, a client may have a Cookie: field for each cookie assigned to it by the server. You can set multivalued field values by using an array reference as the value, or by passing a string in which values are separated by commas. This example sets the Accept: field, which is a multivalued list of the MIME types that the client is willing to accept: $request->header(Accept => ['text/html','text/plain','text/rtf']) Alternatively, you can use the push_header() method described later to set multivalued fields. | $request->push_header($field => $value) The push_header() method appends the indicated value to the end of the field, creating it if it does not already exist, and making it multivalued otherwise. $value can be a scalar or an array reference. $request->remove_header(@fields) The remove_header() method deletes the indicated fields. | A variety of methods provide shortcuts for dealing with header fields. | $request->scan(\&sub) The scan() method iterates over each of the HTTP headers in turn, invoking the code reference provided in \&sub . The subroutine you provide will be called with two arguments consisting of the field name and its value. For multivalued fields, the subroutine is invoked once for each value. $request->date() $request-> expires () $request->last_modified() $request->if_modified_since() $request->content_type() $request->content_length() $request->referer() $request->user_agent() These methods belong to a family of 19 convenience methods that allow you to get and set a number of common unique-valued fields. Called without an argument, they return the current value of the field. Called with a single argument, they set it. The methods that deal with dates use system time format, as returned by time() . | Three methods allow you to set and examine one request's content. | $request->content([$content]) $request->content_ref The content() method sets the content of the outgoing request. If no argument is provided, it returns the current content value, if any. content_ref() returns a reference to the content, and can be used to manipulate the content directly. When POSTing a fill-out form query to a dynamic Web page, you use content() to set the query string, and call content_type() to set the MIME type to either application/x-www-form-urlencoded or multipart/form-data. It is also possible to generate content dynamically by passing content() a reference to a piece of code that returns the content. LWP invokes the subroutine repeatedly until it returns an empty string. This facility is useful for PUT requests to FTP servers, and POST requests to mail and news servers. However, it's inconvenient to use with HTTP servers because the Content-Length: field must be filled out before sending the request. If you know the length of the dynamically generated content in advance, you can set it using the content_length() method. $request->add_content($data) This method appends some data to the end of the existing content, if any. It is useful when reading content from a file. | Finally, several methods allow you to change the URL and method. | $request->uri([$uri]) This method gets or sets the outgoing request's URI. $request->method([$method]) This method() gets or sets the outgoing request's method. $string = $request->as_string The as_string() method returns the outgoing request as a string, often used during debugging. | HTTP::Response Once a request is issued, LWP returns the server's response in the form of an HTTP::Response object. HTTP::Response is used even for non-HTTP protocols, such as FTP. HTTP::Response objects contain status information that reports the outcome of the request, and header information that provides meta-information about the transaction and the requested document. For GET and POST requests, the HTTP::Response usually contains content data. The status information is available both as a numeric status code and as a short human-readable message. When using the HTTP protocol, there are more than a dozen status codes, the most common of which are listed in Table 9.1. Although the text of the messages varies slightly from server to server, the codes are standardized and fall into three general categories: -
Informational codes, in the range 100 through 199, are informational status codes issued before the request is complete. -
Success codes, which occupy the 200 through 299 range, indicate successful outcomes . -
Redirection status codes, in the 300 through 399 range, indicate that the requested URL has moved elsewhere. These are commonly encountered when a Web site has been reorganized and the administrators have installed redirects to avoid breaking incoming external links. -
Errors in the 400 through 499 range indicate various client-side errors, and those 500 and up are server-side errors. When dealing with non-HTTP servers, LWP synthesizes appropriate status codes. For example, when requesting a file from an FTP server, LWP generates a 200 ("OK") response if the file was downloaded, and 404 ("Not Found") if the requested file does not exist. The LWP library handles some status codes automatically. For example, if a Web server returns a redirection response indicating that the requested URL can be found at a different location (codes 301 or 302), LWP automatically generates a new request directed at the indicated location. The response that you receive corresponds to the new request, not the original. If the response requests authorization (status code 401), and authorization information is available, LWP reissues the request with the appropriate authorization headers. HTTP::Response headers describe the server, the transaction, and the enclosed content. The most useful headers include Content-type: and Content-length:, which provide the MIME type and length of the returned document, if any, Last-modified:, which indicates when the document was last modified, and Date:, which tells you the server's idea of the time (since client and server clocks are not necessarily synchronized). Table 9.1. Common HTTP Status Codes and Messages | Code | Message | Description | | 1XX codes: informational | | | 100 | Continue | Continue with request. | | 101 | Switching Protocols | It is upgrading to newer version of HTTP. | | 2XX codes: success | | | 200 | OK | The URL was found. Its contents follows. | | 201 | Created | A URL was created in response to a POST. | | 202 | Accepted | The request was accepted for processing at a later date. | | 204 | No Response | The request is successful, but there's no content. | | 3XX codes: redirection | | | 301 | Moved | The URL has permanently moved to a new location. | | 302 | Found | The URL can be temporarily found at a new location. | | 4XX codes: client errors | | | 400 | Bad Request | There's a syntax error in the request. | | 401 | Authorization Required | Password authorization is required. | | 403 | Forbidden | This URL is forbidden, and authorization won't help. | | 404 | Not Found | It isn't here. | | 5XX codes: server errors | | | 500 | Internal Error | The server encountered an unexpected error. | | 501 | Not Implemented | Used for unimplemented features. | | 502 | Overloaded | The server is temporarily overloaded. | Like the request object, HTTP::Response inherits from HTTP::Message, and delegates unknown method calls to the HTTP::Headers object contained within it. To access header fields, you can call header() , content_type() , expires() , and all the other header-manipulation methods described earlier. Similarly, the response content can be accessed using the content() and content_ref() methods. Because some documents can be quite large, LWP also provides methods for saving the content directly to disk files and spooling them to subroutines in pieces. Although HTTP::Response has a constructor, you will not usually construct it yourself, so it isn't listed here. For brevity, a number of other infrequently used methods are also omitted. See the HTTP::Response documentation for full API. | $status_code = $response->code $status_message = $response->message The code() and message() methods return information about the outcome of the request. code() returns a numeric status code, and message() returns its human-readable equivalent. You can also provide these methods with an argument in order to set the corresponding field. $text = $response->status_line The status_line() method returns the status code followed by the message in the same format returned by the Web server. $boolean = $response->is_success $boolean = $response->is_redirect $boolean = $response->is_info $boolean = $response->is_error These four methods return true if the response was successful, is a redirection, is informational, or is an error, respectively. $html = $response->error_as_HTML If is_error() returns true, you can call error_as_HTML() to return a nicely formatted HTML document describing the error. $base = $response->base The base() method returns the base URL for the response. This is the URL to use to resolve relative links contained in the returned document. The value returned by base() is actually a URI object, and can be used to "absolutize" relative URLs. See the URI module documentation for details. $request = $response->request The request() method returns a copy of the HTTP::Request object that generated this response. This may not be the same HTTP::Request that you constructed . If the server generated a redirect or authentication request, then the request returned by this method is the object generated internally by LWP. $request = $response->previous previous() returns a copy of the HTTP::Request object that preceded the current object. This can be used to follow a chain of redirect requests back to the original request. If there is no previous request, this method returns undef . | Figure 9.3 shows a simple script named follow_chain.pl that uses the previous() method to show all the intermediate redirects between the requested URL and the retrieved URL. It begins just like the get_url.pl script of Figure 9.1, but uses the HEAD method to retrieve information about the URL without fetching its content. After retrieving the HTTP::Response, we call previous() repeatedly to retrieve all intermediate responses. Each response's URL and status line is prepended to a growing list of URLs, forming a response chain. At the end, we format the response chain a bit and print it out. Figure 9.3. The follow_chain.pl script tracks redirects 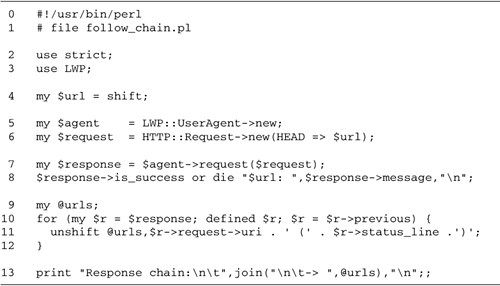 Here is the result of fetching a URL that has been moved around a bit in successive reorganizations of my laboratory's Web site: % follow_chain.pl http://stein.cshl.org/software/WWW Response chain: http://stein.cshl.org/software/WWW (302 Found) -> http://stein.cshl.org/software/WWW/ (301 Moved Permanently) -> http://stein.cshl.org/WWW/software/ (200 OK) LWP::UserAgent The LWP::UserAgent class is responsible for submitting HTTP::Request objects to remote servers, and encapsulating the response in a suitable HTTP::Response. It is, in effect, a Web browser engine. In addition to retrieving remote documents, LWP::UserAgent knows how to mirror them so that the remote document is transferred only if the local copy is not as recent. It handles Web pages that require password authentication, stores and returns HTTP cookies, and knows how to negotiate HTTP proxy servers and redirect responses. Unlike HTTP::Response and HTTP::Request, LWP::UserAgent is frequently subclassed to customize the way that it interacts with the remote server. We will see examples of this in a later section. | $agent = LWP::UserAgent->new The new() method constructs a new LWP::UserAgent object. It takes no arguments. You can reuse one user agent multiple times to fetch URLs. $response = $agent->request ($request, [$dest [,$ size ]]) The request() method issues the provided HTTP::Request, returning an HTTP:: Response. A response is returned even on failed requests. You should call the response's is_success() or code() methods to determine the exact outcome. The optional $dest argument controls where the response content goes. If it is omitted, the content is placed in the response object, where it can be recovered with the content() and content_ref() methods. | If $dest is a scalar, it is treated as a filename. The file is opened for writing, and the retrieved document is stored to it. Because LWP prepends a > symbol to the filename, you cannot use command pipes or other tricks. Because the content is stored to the file, the response object indicates successful completion of the task, but content() , returns undef . $dest can also be a reference to a callback subroutine. In this case, the content data is passed to the indicated subroutine at regular intervals, giving you a chance to do something with the data, like pass it to an HTML parser. The callback subroutine should look something like this: sub handle_content { my ($data,$response,$protocol) = @_; ... } The three arguments passed to the callback are the current chunk of content data, the current HTTP::Response object, and an LWP::Protocol object. The response object is provided so that the subroutine can make intelligent decisions about how to process the content, such as piping data of type image/jpeg to an image viewer. The LWP::Protocol object implements protocol-specific access methods that are used by LWP internally. It is unlikely that you will need it. If you use a code reference for $dest , you can exercise some control over the content chunk size by providing a $size argument. For example, if you pass 512 for $size , the callback will be called repeatedly with 512-byte chunks of the content data. Two variants of request() are useful in certain situations. | $response = $agent->simple_request($request, [$dest [,$size]]) simple_request() behaves like request() , but does not automatically reissue requests to handle redirects or authentication requirements. Its arguments are identical to those of request() . $response = $agent->mirror($url,$file) The mirror() method accepts a URL (a URI object or a string) and the path to a file in which to store the remote document. If the local file doesn't already exist, then mirror() fetches the remote document. Otherwise, mirror() compares the modification dates of the remote and local copies, and only fetches the document if the local copy appears to be out of date. For HTTP URLs, mirror() constructs an HTTP::Request object that has the correct If-Modified-Since: header field to perform a conditional fetch. For FTP URLs, LWP uses the MDTM (modification time) command to fetch the modification date of the remote file. | Two methods allow you to set time and space limits on requests. | $timeout = $agent->timeout([$timeout]) timeout() gets or sets the timeout on requests, in seconds. The default is 180 seconds (3 minutes). If the timeout expires before the request completes, the returned response has a status code of 500, and a message indicating that the request timed out. $bytes = $agent->max_size([$bytes]) The max_size() method gets or sets a maximum size on the response content returned by the remote server. If the content exceeds this size, then the content is truncated and the response object contains an X-Content-Range: header indicating the portion of the document returned. Typically, this header has the format bytes start-end, where start and end are the start and endpoints of the document portion. By default, the size is undef , meaning that the user agent will accept content of any length. | The agent() and form() methods add information to the request. | $id = $agent->agent([$id]) The agent() method gets or sets the User-Agent: field that LWP will send to HTTP servers. It has the form name/x.xx (comment), where name is the client software name, x.xx is the version number, and (comment) is an optional comment field. By default, LWP uses libwww-perl/x.xx , where x.xx is the current module version number. You may need to change the agent ID to trigger browser-specific behavior in the remote server. For example, this line of code changes the agent ID to Mozilla/4.7, tricking the server into thinking it is dealing with a Netscape version 4.X series browser running on a Palm Pilot: $agent->agent('Mozilla/4.7 [en] (PalmOS)') $address = $agent->from([$address]) The from() method gets or sets the e-mail address of the user responsible for the actions of the user agent. It is incorporated into the From: field used in mail and news postings, and will be issued, along with other fields, to HTTP servers. You do not need to provide this information when communicating with HTTP servers, but it can be provided in Web crawling robots as a courtesy to the remote site. | A number of methods control how the agent interacts with proxies, which are commonly used when the client is behind a firewall that doesn't allow direct Internet access, or in situations where bandwidth is limited and the organization wishes to cache frequently used URLs locally. | $proxy = $agent->proxy($protocol => $proxyy) The proxy() method sets or gets the proxy servers used for requests. The first argument, $protocol , is either a scalar containing the name of a protocol to proxy, such as "ftp", or an array reference that lists several protocols to proxy, such as ['ftp','http','gopher'] . The second argument, $proxy , is the URL of the proxy server to use. For example: $agent->proxy([qw(ftp http)] => 'http://proxy.cshl.org:8080') You may call this method several times if you need to use a different proxy server for each protocol: $agent->proxy(ftp => 'http://proxy1.cshl.org:8080'); $agent->proxy(http => 'http://proxy2.cshl.org:9000'); As this example shows, HTTP servers are commonly used to proxy FTP requests as well as HTTP requests. $agent->no_proxy(@domain_list) Call the no_proxy() method to deactivate proxying for one or more domains. You would typically use this to turn off proxying for intranet servers that you can reach directly. This code fragment disables proxying for the "localhost" server and all machines in the "cshl.org" domain: $agent->no_proxy('localhost','cshl.org') Calling no_proxy() with an empty argument list clears the list of proxyless domains. It cannot be used to return the current list. $agent->env_proxy env_proxy() is an alternative way to set up proxies. Instead of taking proxy information from its argument list, this method reads proxy settings from *_ proxy environment variables. These are the same environment variables used by UNIX and Windows versions of Netscape. For example, a C-shell initialization script might set the FTP and HTTP proxies this way: setenv ftp_proxy http://proxy1.cshl.org:8080 setenv http_proxy http://proxy2.cshl.org:9000 setenv no_proxy localhost,cshl.org | Lastly, the agent object offers several methods for controlling authentication and cookies. | ($name,$pass) = $agent->get_basic_credentials($realm,$url [,$proxy]) When a remote HTTP server requires password authentication to access a URL, the user agent invokes its get_basic_credentials() method to return the appropriate username and password. The arguments consist of the authentication "realm name", the URL of the request, and an optional flag indicating that the authentication was requested by an intermediate proxy server rather than the destination Web server. The realm name is a string that the server sends to identify a group of documents that can be accessed using the same username/password pair. By default, get_basic_credentials() returns the username and password stored among the user agent's instance variables by the credentials() method. However, it is often more convenient to subclass LWP::UserAgent and override get_basic_credentials() in order to prompt the user to enter the required information. We'll see an example of this later. $agent->credentials($hostport,$realm,$name,$pass) The credentials() method stores a username and password for use by get_basic_credentials() . The arguments are the server hostname and port in the format hostname:port , authentication realm, username, and password. $jar = $agent->cookie_jar([$cookie_jar]) By default, LWP::UserAgent ignores cookies that are sent to it by remote Web servers. You can make the agent fully cookie-compatible by giving it an object of type HTTP::Cookies. The module will then stash incoming cookies into this object, and later search it for stored cookies to return to the remote server. Called with an HTTP::Cookies argument, cookie_jar() uses the indicated object to store its cookies. Called without arguments, cookie_jar() returns the current cookie jar. | We won't go through the complete HTTP::Cookies API, which allows you to examine and manipulate cookies, but here is the idiom to use if you wish to accept cookies for the current session, but not save them between sessions: $agent->cookie_jar(new HTTP::Cookies); Here is the idiom to use if you wish to save cookies automatically in a file named .lwp-cookies for use across multiple sessions: my $file = "$ENV{HOME}/.lwp-cookies"; $agent->cookie_jar(HTTP::Cookies->new(file=>$file,autosave=>1)); Finally, here is how to tell LWP to use an existing Netscape-format cookies file, assuming that it is stored in your home directory in the file ~/.netscape/cookies (Windows and Mac users must modify this accordingly ): my $file = "$ENV{HOME}/.netscape/cookies"; $agent->cookie_jar(HTTP::Cookies::Netscape->new(file=>$file, autosave=>1));  |
