Data and Relationships
| With the inclusion of our tenth table, we can be sure we have now taken care of all the information that our customers will need from the system. The next big step is to do a little abstract analysis on the logical way the tables will work in the real world. There are two things to consider: (1) what kind of data we want in the tables and (2) how the tables are related . In other words, it's OK to define ten tables according to established normalization principles, and you may get looks of admiration for doing so, but what does that mean in the real world? On the second point, can we just start throwing data into the tables, or is there a natural rhyme and reason to the structure? Should some data exist before other data is entered, or don't we care? On the first point (the type of data), do we care if any data is entered anywhere , or are we expecting numbers in some places, letters in others? Is some data mandatory? Does it make any difference how long the columns are? These are the two major issues we will be addressing in this chapter. DataFor those of you with programming background, or anyone with any kind of analytical experience ”whether with respect to handling foreign currency, working on the Human Genome Project, or cataloging books in a library ”you know that data has to be classified in some way for it to be useful, and for you to be able to find it when necessary. If data is left undefined, it may or may not behave the way you expect it to when you run it through your database programs. In relational databases we can use certain standard definitions to classify data. These classifications are defined for the columns, and all rows of data entered for the columns must adhere to the definitions or there will be an automatic error. This means that we can use the built-in integrity features to help edit our data, thus eliminating much of the tedious editing that would have to be done. Several standard data formats are commonly used. Others exist, but for our purposes the following will be more than adequate:
What's a string ? It is any group of things, such as an address, a phone number, all the letters in this chapter, and so forth. For a mixture of letters and numbers, always use CHAR and VARCHAR2 . For pure numeric strings, such as Social Security number, including any signs (plus, minus, etc.), use the NUMBER format. We'll cover more about strings later in the book. DATE provides information about a date. The default format is DD-MON-YY . Dates are usually enclosed in single quotes ”'09-Aug-01' ”and the default is the system date. Note As a quick refresher, go back to Chapter 3 and study up on keys and constraints. We will be using them in the steps outlined here. Let's define the data we want to capture, starting with the two question tables:
Note Here's a quick refresher. Remember that Chapter 4 talked about keeping things simple and clear? We use the Question_Type column instead of trying to put everything into the Question_ID column because this makes it much easier to find a group of like questions, and we do not run the risk of running out of positions to use. Making every position mean something is a good idea for table names , but not for keys. So don't try to cram too much information into your columns. Keep your major columns simple, and if at all possible, use ascending numerics. We will use a simple numeric ID, and we'll use another numeric column for the question type. We know that in the QUESTIONS table, Question_ID must be unique or we'll have chaos. The Question and Correct_Answer columns will contain alphanumerics, and Question_Type will contain a numeric. In the QUESTIONS_ TYPE_DESC table, Question_Type must be unique because we want only one entry per type, and the Questions_Type_Desc field will contain free-form alphanumerics. Our first pass at defining the tables looks like this:
In our second pass, let's make the two important columns unique, and let's make the system check whether data is entered. What we'll do is use the null constraint and the uniqueness constraint. NOT NULL means that data has to be entered or there will be an error; UNIQUE means that we cannot have duplicate entries for either Question_ID or Question_Type. The system will do all this editing for us! Using the same concepts of uniqueness and not null, we can define the columns for the remaining tables:
Let's keep going with our constraints. We want to introduce the concepts of a primary key and the check constraint. Further, the check constraint will let us talk about logical operators. And believe me, all these things will ultimately make your life easier! A primary key is a column or columns that will be unique for each row in a table. (By definition, a primary key cannot be null, so you do not have to specify NOT NULL for the primary key columns.) Think of the primary key as the best way to identify a table, as that thing that makes the table easy to identify. In many, if not most, cases the primary key will be the column called "Something ID." Tables do not have to have a primary key. A history table, for example, is a repository of transactions, and we can simply make the transaction number or another column unique. In almost all cases, you will want your primary keys to be unique and not null. One way to make the primary keys unique and also speed up processing is to use an index . An index operates in the same way as the index in this book: It helps find data quickly. Otherwise, Oracle would have to search every column when doing a query. (Yes, you can create an index for any column, up to 16 columns per table ”and there may be times when this is good practice. In the history table mentioned in the preceding paragraph, you might want to create an index for the transaction date, as well as the transaction number, because both will be used extensively for data retrieval. More on this later.) An index is an optional feature you set for a column(s) after the table has been created. There are two types of indexes: unique and nonunique . When you use the CREATE INDEX command, you can specify whether the index is unique. In the absence of that specification, a nonunique index is created. OK, what have we learned so far? Remember back in the discussion of normalization in Chapter 4, where we worked through the Third Normal Form and made sure that all the columns in a table were directly dependent on a primary key? Well, a primary key is not just a concept. We can actually make columns into a primary key and, using various constraints, make it unique and not null. Further, we can create a unique index for the primary key column, speeding up processing and preventing duplicates. Now let's take a look at logical operators . A logical operator is a way of asking Oracle to determine whether a particular piece of data fits a certain criterion. For example, we can say salary number(9,2) check (salary between 50000 and 1000000) and the system will automatically edit any inserts or updates and make sure that any salary entered is between $50,000 and $1 million. Table 5.1 lists the logical operators. Table 5.1. Logical Operators
Another feature that is not a constraint, but may be helpful, is that we can add a default attribute to a column. For example, when the student logs on to the system and is asked to enter identifying information, the Location field can default to something like "Main Computer Lab" if this is where most, if not all, of the testing will take place. If we had a field such as Veteran? and the U.S. Navy bought this system, we could change the Veteran? default to "Yes". Got the idea? Now we're going to go through the tables once again, adding the constraints we just talked about. We want to add primary keys and logical operators where applicable . Let's take a look at the STUDENTS table. This will set the example for the other tables. The key, naturally, is Student_ID. We want it to be unique and not null. However, later we will create an index for this column, so all we have to say now is that it is the primary key and not null. We can qualify the Sex field by using the check constraint and saying: Sex VARCHAR2(1) check (sex IN 'M', 'F', 'm', 'f') We can get around having to specify both upper- and lowercase through programming, but this is a good example of the IN operator with the check constraint. Here's how the modified STUDENTS and TEST_HISTORY tables now look:
Note Later, when we show you how to create a table, you will see that Oracle has certain rules. If you use only one column for a primary key, then you can say "primary key" in the column attributes, as in the STUDENTS table above. When you use more than one column, the primary key becomes a table constraint and must be defined at the end of the CREATE TABLE command. You'll see this in a couple of chapters when your tables come to life. Here are the rest of our tables after we've added the latest round of constraints:
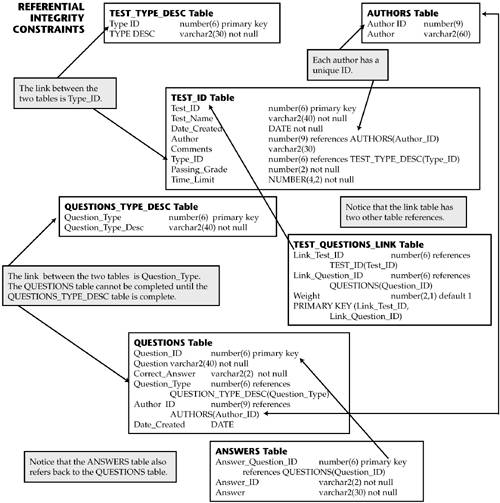
So far, is everything clear? Notice that not every table has a key. But, as you will see later, we will be creating indexes for some tables to make data retrieval faster and to enforce uniqueness among the keys. Now let's move on to the last constraint that we will use with our tables ”one that, like the ones we have just built, will save us a lot of grief later. This constraint is called referential integrity and is built on the relationships that naturally exist among the tables. RelationshipsLook at the ten tables at the end of the preceding section. Do you see a logical progression among them? That is, should we build the STUDENTS table first, or the TEST_HISTORY table, or is there a better way to do this? What really comes first ”students, test, questions, or history? If you guessed questions, take yourself a well-deserved five-minute break. Doesn't the entire database really depend on having questions defined, along with their answers? It makes no difference if we have nice tests or really good students; without the questions, nothing will work. This means that anything dependent on the QUESTIONS table is in a direct relationship with the QUESTIONS table. Take a look at the ten tables. See? The TEST_HISTORY, STUDENT_ANSWER_HISTORY, and TEST_QUESTIONS_LINK tables all depend on having real questions in the QUESTIONS table. Got the idea? Those tables reference the QUESTIONS table, and we will later build this reference into the tables. Why? Well, if we don't, then we can add anything to the other tables, or, we'd have to do a lot of programming to catch errors. For example, if you were logging the information for a student and entered that the student had answered #4 on question 123, and there was no question 123, the system would let you create a bad record for that student. Of course, this would be the student who would call, and now how would you explain that he or she got a wrong answer on a question that does not exist? With referential integrity, the system would catch the error and tell you that question ID 123 is invalid, and it would not let you update the student record. See? Referential integrity does error checking for you. Of course, as already mentioned, you could write code to edit the answer, but why bother when it can be done for you? If the fields are tied together, the database will automatically alert you if you or your program tries to do something illegal. So if the fields had been tied together in our example, when the program or the data entry person tried to enter question ID 123 for the student, the database would have stopped the process immediately and prevented you from future embarrassment. Clearly this referential integrity stuff is a good idea! So we can see that the first set of tables we have to build will be the QUESTIONS_TYPE_DESC table and the QUESTIONS table. We can't enter anything for Question_Type unless that type is already defined in the QUESTIONS_TYPE_DESC table, right? What next? Logically, the next step would be the ANSWERS table. Questions and answers go together like peanut butter and jelly . Next? Look at the TEST_ID table? Oh, you're already there? Great ”you've got the idea. And now, before we can add any test descriptions, we have to have entries in the TEST_TYPE_DESC table, right? So this table would be the next one to load with data. After that, the next table to load would be what? STUDENTS? If you chose STUDENTS, skip lunch . Students will enter their own data when they take the test! Of course, you may have some historical data you want to test, but that doesn't count. Your next table would be the TEST_ID table ”all those tests that you have in your development folder. What tests, you ask? Why, the ones you developed with the instructional and teaching staff while you were also doing all this! (We're going to give you some real questions to use, but remember that in practice, such things are really defined by the users, not the technical staff. You will translate their ideas into the relational database, but the definitions come from them. Unless of course you are also a professor or instructor, in which case you can talk to yourself, in private, and get the job done quickly.) See? The QUESTIONS, ANSWERS, TEST_TYPE_DESC, and TEST_ID tables are your foundation tables. Once those are in place, any student will be able to take the tests anytime , instructors will be able to create new tests, the history tables will start to be filled, you will be able to write reports and queries, and your customers will be writing glowing articles about you, and next thing you know, you'll be at the White House getting a medal. All because you thought out the relationships between your tables! Now that you have the idea that some data is inherently dependent on other data, the question is how to program the relationships. Remember our discussion of constraints and keys in Chapter 3? We mentioned foreign keys , columns that refer to another column in another (or foreign) table. The power of the foreign key is that it ensures that you do not end up with unconnected data. In the previous example we talked about a student requesting his or her answers to a test, and it turned out that somehow his test history had an invalid question, with ID 123. As I explained, one way to prevent such a thing from happening is to use the referential integrity constraint, where one column in a table refers to another column in a different table. Here's the theory. Table A has the names of all employees, including yours; Table B has the names of all employees and all the rewards they received. When you were testing these tables, you added, just to test, "Moby Dick" to the awards table and gave him the Golden Harpoon award. Then you forgot about it because the tables were done, and off they went into production. Now comes the annual awards banquet, and just before your name is called, the VP of your company or university, reading from a list that was created from Table B, says, "Would Moby Dick please stand and be recognized?" After a few seconds, and some stifled laughter , you try to sneak out of the room. Of course, the VP, being the consummate professional, makes some kind of joke about this, while whispering that she wants to see you first thing tomorrow morning. One way to avoid such embarrassment is to link the tables using referential integrity. Doing so would ensure that no names are allowed in Table B that are not in Table A. So if Moby Dick were not a valid employee listed in Table A, the system would stop you from adding it to Table B. (If there is a real employee named Moby Dick, you better hope he earned the reward you entered in Table B!) To create the referential integrity we need, we add the constraint references TABLE(column) command. In our example, Table B would have a name field set up as follows :
This would prevent anyone from entering a name in Table B that did not exist in Table A. Got the idea? If we look at our tables, there are several places where we can use referential integrity. As I already mentioned, we should not allow a test type to be entered on the TEST_ID table unless the type already exists in the TEST_TYPE_DESC table. Hence we would add a references statement to make the link. We would do the same with the ANSWERS table. Because all answers are tied to questions, we will link the ANSWERS table to the Question_ID column of the QUESTIONS table. See how it all works? We don't want any disconnected data out there that could cause havoc, so we purposely tie the important fields together with the threads of referential integrity. Now let's see what our tables look like with the addition of referential integrity constraints where necessary. Note Remember, for our purposes there are several foundation or base tables that the rest of the system depends on. These are the descriptor tables, and they question, answer, test, and link tables. We start our table definition with the TEST_TYPE_DESC table and the AUTHORS table. Remember that without these tables, we cannot build the TEST_ID table, so these are the logical starting points:
Once the TEST_TYPE_DESC table has been created, the next one is the AUTHORS table because the TEST_ID table also depends on the author's being defined:
Next we make the changes to the TEST_ID table:
Let's take a close look at what we just did. For Author, we added a referential integrity link back to the AUTHORS table, and we also created a default name just in case someone left it blank. For Type_ID, we added another referential integrity link, this one back to the TEST_TYPE_DESC table. Why? This way no one can enter an invalid test type description when creating a table entry in the TEST_ID table. Whatever someone enters in the Type_ID field of the TEST_ID table will automatically be checked against Type_ID in the TEST_TYPE_DESC table. Type_ID in the TEST_ID table is a foreign key that references Type_ID in the TEST_TYPE_DESC table. The same logic holds true for the Author column. This philosophy should now be making sense, and you should be able to follow how the other tables are going to be tied together. We follow the same logic for the QUESTIONS_TYPE_DESC and QUESTIONS tables. First the descriptor table for questions:
Next the actual QUESTIONS table:
Notice that again, a column in one table references a column in another table, so we let Oracle do the editing for us. Also observe how often we use the NOT NULL phrase. In general, we want to avoid nulls. They can cause unpredictable results in queries, among other things. As you undoubtedly expected, next we link the QUESTIONS and TEST_HISTORY tables by using the following linking table:
Look what we've done here! By using the references clause, we've really tied this table up so that no bad data can get in. Also notice that we have two columns for the primary key. We've done this to make queries and views go faster in case we ever want to get all the questions for a test, which we know we will have to be doing over and over as students take the tests. Now let's create the last base table, ANSWERS:
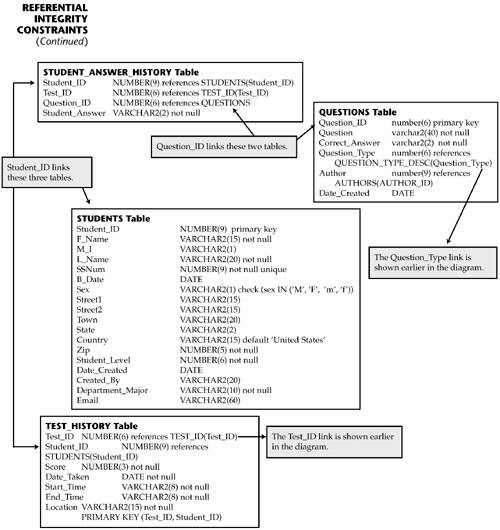
Notice that the primary key of this table refers back to the QUESTIONS table. We don't want any answers out there unless they are tied to a valid question, right? Once these base tables have been defined, we move on to the STUDENT and HISTORY tables. First look at the STUDENTS table; notice that nothing has changed. You could put in ranges for state, or have a STATE table with all the abbreviations, or a table for the departments or majors, and then use referential integrity. For our purposes we have kept this table as simple as possible. However, feel free to add additional tables and referential statements!
Only two more to go! Now finish defining the TEST_HISTORY table:
With TEST_HISTORY we have added two referential clauses ”one for Test_ID and one for Student_ID. This will make the system look at the TEST_ID table and the STUDENTS table anytime these fields are modified. We have also used these fields as a compound primary key. Finally we come to the STUDENT_ANSWER_HISTORY table:
Notice here that three of the four columns are defined by the use of referential integrity. This approach will really protect the data in this history file. Here's a diagram of how the tables now link together: Guidelines for Using the references Clause The foreign key that you refer back to must be unique and not null. It can be a primary key or not. So if you refer back to a nonprimary key, make sure that the column is defined as not null. This is very important, or you run the risk of duplicates, especially with nulls, and you will have problems. Note Referential integrity in which you can use a foreign key to reference a column in another table is an Oracle feature, and it works only in an Oracle environment. Although it is very powerful, it is not a recognized construct in other SQL databases. So if your environment includes databases other than Oracle, you cannot use the references statement when migrating tables and data. We have now completed the table design for our system. We're ready to go to the server and start creating our Oracle server, database, and users. Then we will build the client PCs, connect them to the server, load the tables, and start programming! | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
EAN: 2147483647
Pages: 84