Chapter 4. Business Opportunity
| All computer system projects, such as the Oracle database project we're about to start, begin with a business opportunity. Someone who has identified a problem that may or may not be a good candidate for automation comes to you, looking for potential solutions. Imagine that you have arranged to meet with the director of computer training, or the chair of the Computer Science department, or the coordinator for a large consulting firm. The meeting stems from a phone call you received two weeks ago about a problem with the training classes. On the phone you were told that many of the people taking the introductory class turned in rather poor evaluations, and your ideas for improvement are needed. So the meeting starts, and being a good business analyst, you ask directly what the poor evaluations say. Is the problem a lack of equipment, mediocre instructors, a very difficult syllabus? The answer surprises you: The class was boring for many of the students! And it was boring because the students already knew the material, but this was a mandatory class; they had to attend . This immediately gets you thinking. If the students know the material, the real issue is how to test them easily and let those who are adept move on to the next level of classes. You modestly present this idea, it is received very well, and you find yourself charged to produce the system immediately. Nothing like pressure! Your first step is to find out what is covered in the introductory class. This means patiently talking to the instructors of both the introductory class and the class at the next level. You need to know what is covered in the intro class and what level of expertise is expected as a prerequisite for enrolling in the second-level class. You find that the goal of the first-level , or intro, class is to teach the basics of computer concepts and office software, so that the students will be able to use word processing for papers, include graphs and graphics in reports , and use e-mail and the Internet. Armed with this information, you now start to probe for the level of expertise. Should students be able to create complex word processing documents, formula-rich spreadsheets, and fantastic slide shows, or should they know just enough to get a term paper done, create simple graphs, and insert graphics when necessary? You go through this exercise several times as you clarify the types of questions you need to adequately test the student's knowledge. After repeated meetings with the educational staff, you have finally developed a list of questions that everyone agrees with. You think that now you can run back to your desk and start coding. "Aha," one of the instructors says, "What about . . . ?" This is a phrase that strikes fear into a systems person's heart. Actually, when users start to ask questions like this, you are really moving into the next step of system design (that's what you've been doing so far without knowing it). Once you've clearly identified the business problem ”and I mean clearly ”you have to test your ideas against the real world. That's what the What about means. "What about mixing up the questions?" "What about adding new questions?" "What about one person taking the test for someone else?" "What about seeing the scores on the 'Net'?" "What about someone taking the test over and over?" These are the real business questions that will help refine your system into something truly useful, and you must probe over and over until you have uncovered all such issues. The rule here is to design carefully . It is very difficult to change the basic design once you've started building your database. A suggestion is to run your ideas past knowledgeable users, especially those who will be using your new system. Do not be critical: rather listen, listen, and listen more. Ask questions such as, "What problems do you currently have with testing students?" "How soon do you need to know the results?" "Would you like a report each morning, or would you want to run reports on demand?" Although this is not a book on system design, let me share with you a "best practice." Find out what your customers expect to get out of the system. What reports do they want, what charts , graphs, and online information? How timely must the data be, and what will it be used for? Are there weekly or monthly cycles? A good place to start is to see what the current output is ”any reports, screens, and charts that your customers now have or always wanted to have. Take a close look at them and you will start to see the data elements that your customer needs. The more time you spend digging into their needs, the more complete your final system will be. This is, in effect, working from the output back. If you know what they must get out of the system, you can be pretty certain that you will be able to determine what has to go in to produce those results. Just look at the output from your system design and see if the data is contained somewhere in your tables or can easily be calculated. If not, then redo your design. Now you have a list of questions, and you have the system specifications:
With the questions and the system parameters finalized, the next step is to determine the data that will be necessary. Of the several possible starting points, the most obvious is to begin with the student information you will need. First make a list of the elements. It will look something like this:
Looking at this list, we can identify the student; the date, time, and name of the exam; the exact questions; the student's answers; and the correct answers. We also know the age, sex, and proficiency level of the student. And we will have a complete record of every exam that the student takes. What could be better? Take another look. There are a couple of obvious problems. If we build the table so that it can contain, say, 30 questions for each exam, and we have enough tables for 10 exams, what will happen when someone decides to have 35 or 50 questions on an exam? What if your program becomes so popular that it grows to 100 exams? Obviously we cannot constantly be modifying our tables, so we have to take another look. Other Uses Another use for this program would be a kiosk at a department store that would help people make decisions. For example, if a customer were looking for a washing machine, and there were 200 possible models on the floor, you could modify this program to ask the customer a series of questions: what the desired price range is; what features the customer wants; how many loads the customer expects to do each week; whether any heavy loads, such as horse blankets, will need to be done; and whether front or top loading is desired. Your program would then produce a list of in-stock and on-order models meeting the criteria, thereby helping the customer narrow down the choices. Looking again at the list of elements needed, it is clear that there are a few major sections.
In other words, for a given student you must be able to show the exam, the questions on that exam, the student, and the correct answers. Then you might want to know who wrote the exam, when it was written, and perhaps how many students have taken it and what their scores were. So there are really three logical groups: student, test, and history. What we have just done is the beginning of what's called data normalization. Yes, I've snuck normalization in on you, and you're still alive ! To be completely honest, what we're doing right now is working to create the First Normal Form, which has the simple rule of identifying and splitting out any repeating groups. Bear with me; I think this will become clear as we go through the next couple of steps. Now back to our example. We have taken a look at our one big record and identified and split out any repeating groups, such as the test and the test questions. The result is one table with student information and one table with test number information:
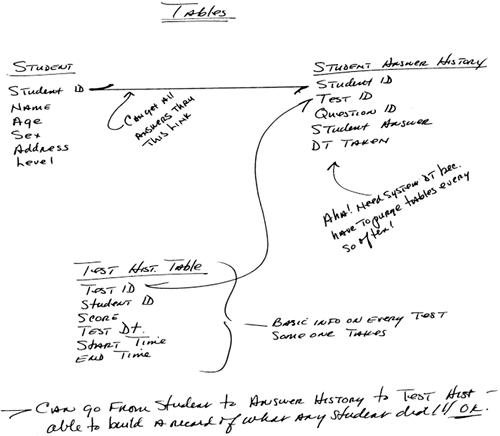
The two tables are linked by Student ID. If the student takes another test, it is added to the TEST TAKEN table. Following the same reasoning, we have to split out another repeating group , the questions, into its own table. Questions are not dependent on test number because the same questions may appear on more than one test. We do not want to have all the repeated questions listed over and over for each test a student takes. Instead, we will add a QUESTIONS table that has the detailed questions, and each question will have a test number linking it to the TEST TAKEN table. From there, we can follow Student ID back to the STUDENTS table:
Does this make sense? There's an immediate problem here. We have created another set of repeating data! The problem is that the questions and answers will have to be repeated for every test. We need another table to link the tests and the questions. The First Normal Form continues!
Now we can link everything. The QUESTIONS table has each question identified by Question ID. Question ID links to the TESTS table, which has a list of the question IDs associated with each test. We can now link to the test that the student took, and then to the student information. Student ID gives us data on the student and links us to the TEST TAKEN table, which in turn links us to the TESTS table. From there we can get the detailed questions and answers from the QUESTIONS table. What we've done is move the test number out of the QUESTIONS table into another table. Because the questions had nothing to do with Test Number, we've taken care of the Second Normal Form , removing a multivalued key. Look at it this way. The original keys in the QUESTIONS table were Test Number and Question. However, the questions and answers do not depend at all on Test Number, so the table was changed to separate the two. In practice, you will do the First Normal and Second Normal forms over and over until you have eliminated repeating information from your tables and have made sure that all the data in each column depends entirely on the primary key. Notice below that we have made another change: We have put the answers into their own table. Why? Follow this thinking: If we design a table that has four answers to each question, we will have a problem when someone wants to have five answers. Sketching Table Design Do your table design as a series of simple sketches , such as the one shown here. It will be easier to see the relationships and duplicate data. And as many of you know, some of your best ideas will be your notes on a napkin over lunch : Here's what the tables for the waiver exam look like after several passes with First and Second Normal Forms:
The final step, or Third Normal Form , is to go back to the TEST ID table. Type does not depend directly on the primary key, and if left in as is, it would cause an update nightmare. The student might take several tests of the same type, such as several SQL tests, and if the type description were changed, you would have to find every occurrence and change it. Instead, we build another table for Type that contains two columns :
There are many books on normalization, but they often scare people away. As a summation of the several favorite standards that are taught in universities, here's the gist of the first three normal forms:
Normalization is done for several reasons, as you must have guessed by now:
Tip Here's a tip on building the tables, the next step. Use nonmeaningful primary keys. A simple sequential number is probably the easiest and best. If, for example, you create a student key that starts with C for computer courses, and your system then becomes expanded into other areas, the C prefix may become meaningless, and it may actually be a hindrance. As with every rule, however, there are logical exceptions. If you're building a system that already has a meaningful identifier, such as UPC code, then by all means use it! To review, we have covered the first three steps of normalization. There are actually two more steps, but in practice, usually only the first three are used. The reason is that in many database designs, the first three steps will result in a good, practical, working schema. Going into the fourth and fifth normal forms just is usually not necessary. In doing the first three forms, we have had to take a very close look at the data, the relationships between the data, and how we could build our tables in a logical and structured way. Some of what you have to be familiar with before we move on to tables, the server, client, and programming are the concepts behind tables, such as rows and columns, relationships such as one to many, many to many, and many to one. These concepts were covered briefly in Chapter 3. For a much more complete discussion, I refer you to the many, many books on data normalization. |
EAN: 2147483647
Pages: 84
- RIPv2 PE-CE Routing Overview, Configuration, and Verification
- Case Study-Hub and Spoke MPLS VPN Network Using BGP PE-CE Routing for Sites Using Unique AS Numbers
- Overview of Inter-Provider VPNs
- Command Reference
- Case Study 4: Implementing Layer 3 VPNs over Layer 2 VPN Topologies and Providing L2 VPN Redundancy