Significance of Buffer Overflow Vulnerability
In the field of information technology, such behavior can result in serious trouble as did occur on Oct 19 2000, when hundreds of flights were grounded or delayed because of a software problem in the Los Angeles air traffic control system. The cause was attributed to Mexican Controller typing 9 (instead of 5) characters of flight-description data, resulting in a buffer overflow.
| |
-
A buffer overrun is when a program allocates a block of memory of a certain length and then tries to stuff too much data into the buffer, with extra overflowing and overwriting possibly critical information crucial to the normal execution of the program. Consider the following source code:
-
When the source is compiled and turned into a program and the program is run, it will assign a block of memory 32 bytes long to hold the name string.
#include <stdio.h> int main ( ) { char name[31] printf("Please type your name: "); gets(name) ; printf("Hello, %s", name) ; return 0;
Buffer overflow will occur if you enter:
'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAA
| |
| Note | A buffer overflow occurs when a program or process tries to store more data in a buffer (temporary data storage area) than it was intended to hold. Since buffers are created to contain a finite amount of data, the extra information which has to be directed elsewhere can overflow into adjacent buffers, corrupting or overwriting the valid data held in them. |
Extending the earlier scenario into the world of information technology, we find that when a program is designed, it is designed with an interface to the outside world. By 'interface' we include those aspects of the program which communicates with other programs as well as the operating system. Therefore, we will focus primarily on the application programming interface (API), which is a set of programming conventions facilitating direct communication with another piece of code; and the protocol - which is a set of data and commands to be passed between programs. It is a fact that many programs use standard sets of code provided by the operating system when they want to use a protocol.
The APIs associated with a program and the concerned protocol determines the nature of information that will be exchanged by the program. Take for instance a simple user login form. The program may define that the user name must be restricted to fifteen characters. This meant that the programmer would typically allot a temporary storage space of fifteen characters for the input user name. Now, if a user entered a name that was longer than fifteen characters, the particular web application he is trying to use may crash or perform erroneously. In this example, the web application cannot be considered faulty as it did not do anything wrong in the first place. On the contrary, it was the form or the user that did not perform as expected. From a security standpoint, it is what the web application did after it received the data, which caused the breach. Let us try to understand how and why.
| |
-
Buffer overflow attacks depend on two things: the lack of boundary testing and a machine that can execute code that resides in the data/stack segment.
-
The lack of boundary is very common and usually the program ends with segmentation fault or bus error. In order to exploit buffer overflow to gain access or escalate privileges, the offender must create the data to be fed to the application.
-
Random data will generate a segmentation fault or bus error, never a remote shell or the execution of a command.
| |
| Note | Program code and related data are components that are closely interlinked. The program code instructs the computer what to do, while the data component is that with which it does this. The data component consists of constants or fixed values that never change and variable values (which are usually initialized to "0" or other default value because the actual values will be supplied by the user of the program). Usually, both constants and variables are defined as particular data type, which prescribes and limits the form of the data. |
When a program is run, both the code and the data it requires are loaded into the system memory. When the program uses an API to interact with another program and retrieve data, the program code will determine the course of action to be taken - based upon the data received.
Extend this scenario to a network where the local system's program accepts input from a remote system. The local system will be instructed regarding future course of action by the local code based upon the remote data. In other word, the remote program can only tell the local program to execute within the constraints of the original code. This means that a remote program cannot tell the local program to do anything that it was not supposed to do originally. If this be the case, where does the security threat arise?
| Threat | The Security Threat Programming techniques and applications has evolved such that there is little to differentiate data and code. Therefore if a remote program can convince the local code that the data it has supplied is valid, the local code will execute it. Herein lies the security threat. If a malicious user can find a means of transporting malicious code to the target system and get the local system to execute it, he can gain access to the system and its resources. |
A familiar analogy is the email virus that manages to reach the target system under the cloak of email and relies on the unsuspecting user to execute itself. If a malicious user can detect or uncover a program on a target system that did not check for a buffer overflow, it can be very trivial to exploit that program to execute a malicious code of the attacker's choice. Needless to say, there exist tools that automate this process to a great extent.
However, it must be pointed out that this scenario can happen on a system that has escaped a thorough boundary checking, only if the attacker can access the program remotely over the network. Typically this is a program that facilitates external access such as printer servers, file sharing etc. The other obvious option is when the attacker is present at the system.
| |
-
Buffer is expecting a maximum number of guests.
-
Send the buffer more than x guests
-
If the system does not perform boundary checks, extra guests continue to be placed at positions beyond the legitimate locations within the buffer. ( Java does not permit you to run off the end of an array or string as C and C++ do)
-
Malicious code can be pushed on the stack.
-
The overflow can overwrite the return pointer so flow of control switches to the malicious code.
| |
| Note | What exactly happens when a buffer overflow occurs? Let us put together the basic terms we need to know in this context. Here, the term buffer refers to a data area shared by program processes that operate with different sets of priorities. In other words, a buffer is a contiguous area in the system's memory space that holds multiple instances of the same data type. The buffer allows each process to operate without being held up by the other. In order for a buffer to be effective, the size of the buffer and the way data is moved into and out of the buffer need to be considered. |
Let us look at a typical example of a vulnerable code.
Void foo (char *s) { char name [5]; strcpy (name's); printf ("Name is %s\n", name); } int main (void) { char buf [10]; read (0,buf,10); foo (buf); } In the above code the variable name is assigned a length of 5 characters, however, the main function allows the program to read an input that can be 10 characters long. The 'buf or buffer variable can only store a maximum of 5 characters. Now the question is where does the excess characters find place on the system?
If "buf" is a global variable, then the excess data will probably be allocated in a data segment elsewhere in the memory segment. The excess characters may then overwrite an unrelated portion. Again, this is a possibility only. However in most cases, 'buf' is likely to be a local variable, allocated on the stack. So instead of overwriting data, the program tries to overwrite the stack itself.
In programming terms, a stack is an abstract data type. Stacks consist of objects and typically function by placing the last object such that it is the first object to be removed from the stack.
In other words, it follows a last in, first out (LIFO) queuing operation. The various operations associated with a stack are:
-
NewStack - creates a new stack that is empty
-
Push(x) - adds x to the stack
-
Pop - returns the value from the top of the stack
-
Top - sees what's on the top of the stack without removing it
-
isEmpty - true if the stack is empty, false if not
Of the various operations defined on stacks two significant operations are PUSH and POP. PUSH adds an element at the top of the stack, while POP reduces the stack size by one by displacing the last element at the top of the stack.
| Attack Methods | A malicious user of the program will try to input such that the program will overwrite the rest of the data stored on the stack. Remember that there was code initially on the stack. Once this is done, the attacker will try to input some machine code that will overwrite the part of the stack that had code on it. It is possible for the attacker to arrange for the execution of his code the next time the system calls the affected function. If so, the program will execute the malicious code instead of the code that normally would have been executed. It is a home run for the attacker. Note that the attacker does not need to transfer very much data, but just enough to run something that will allow him to connect to the target machine. |
| |
-
C functions and the stack
-
A little knowledge of assembly/machine language.
-
How system calls are made ( at the level of machine code level).
-
exec ( ) system calls
-
How to 'guess' some key parameters.
| |
Logically, the question arises why do we use stacks when it can pose such a threat? The answer lies in the high level object oriented programming languages where procedures or functions form the basis of every program.
The stack is useful for storing context. For instance, if a procedure simply pushes all its local variables onto the stack when it enters, and pops those off when it is over, its entire context is cleaned up such that; when the procedure calls another procedure, the called procedure can do the same with its context and, without the aid of the calling procedure's data.
The flow of control is determined by which procedure or function is called after the current one is done. This high-level abstraction is implemented with the help of the stack. Apart from this the stack also serves in dynamically allocating local variables used in functions, passing parameters to functions, and to return values from the function.
In fact, though several applications are written in C, programs written in C are particularly susceptible to buffer overflow attacks. This is because C programming language allows direct pointer manipulations. C provides direct low-level memory access and pointer arithmetic without bounds checking. Moreover, the standard C library provides unsafe functions (such as gets) that write an unbounded amount of user input into a fixed size buffer without any bounds checking.
| |
-
The stack is a (LIFO) mechanism that computers use both to pass arguments to functions and to reference local variables.
-
It acts like a buffer, holding all of the information that the function needs.
-
The stack is created at the beginning of a function and released at the end of it.
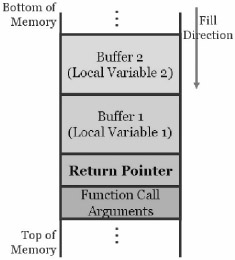
| |
| Concept | A Closer look at Memory and Stack Segment Let us take a closer look at how the memory is structured so that we can explore the stack - (which is a contiguous block of memory containing data) - in a detailed manner. 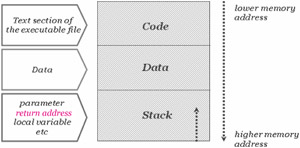 |
-
Code Segment
We had mentioned that when a program is run, both code and data are loaded into the memory. In the figure above, code refers to the area where the instructions for the program are located. This segment contains all the compiled executable code for the program. Write permission to this segment is disabled here as the code by itself does not contain any variables, and therefore has no need to write over itself. By having the read-only attribute, the code can be shared between different copies of the program executing at the same time.
-
Data Segment
The next section data refers to the data - initialized and/or uninitialized - required for running the instructions. This segment contains all the global data for the program. A read-write attribute is given as programs would want to change the global variables. There is no 'execute' attribute set as global variables are not usually meant for execution. One does not usually want to execute their global variables, and so execute permission is disabled. As shown above, there is a progression from a lower memory address to a higher memory address as we move down to the stack.
-
Stack Segment
Consider the stack as a single ended data structure with a first in, last out data ordering. This means that when two or more objects / elements are "pushed" into the stack, to retrieve the first element, the subsequent ones have to be "popped" out of the stack. In other words, the most recent element remains on top of the stack.
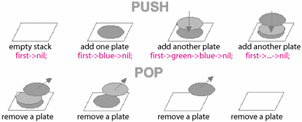
| |
Two most important operations in a stack:
-
Push -put one item on the top of the stack
-
Pop - "remove"one item from the top of the stack
typically returns the contents pointed to by a pointer and changes the pointer (not the memory contents)

| |
| Concept | Stack Implementation A stack is implemented by the system for programs running on the system. The implementation of a stack is very simple. A variable is kept inside the processor itself and a region of memory is allocated. The variable is called the register and the region of memory is the stack. The register used for the stack is called the Stack Pointer or SP for short. The SP points to the top of the stack, while the bottom of the stack is at a fixed address. |
The stack size is adjusted dynamically by the kernel at run time. A stack frame or record is an activation record that is stored on the stack. It contains the parameters to a function, its local variables, and the data necessary to recover the previous stack frame, including the value of the instruction pointer at the time of the function call.
When the system loads the program, the stack pointer is set to the highest address of the stack segment. This will be the top item in the stack. When an item is pushed onto the stack, two events take place. The stack pointer is reduced by subtracting the size of the item in bytes from the initial value of the pointer. Next, all the bytes of the item in consideration are copied into the region of the stack segment, to which the stack pointer now points.
Similarly, when an item is popped from the stack, the size of the item in bytes is added to the stack pointer. However, the copy of the item continues to reside on the stack. This will eventually be overwritten when the next push operation takes place. Depending on the implementation the stack will either grow down (towards lower memory addresses), or up.
We had mentioned about instruction pointer when we addressed stack frames . Now, when a procedure is called, it is not only the item that is pushed onto the stack. Among others is the address of the instruction immediately after the procedure call. This is followed by the parameters to the function. After the function completes, it will pop its own local variables off of the stack, followed by its parameters. The last instruction run by the function is a special instruction called a return. This is a special processor instruction which pops off the top value of the stack and loads it into the IP. At this point, the stack will have the address of the next instruction of the calling procedure in it. This is explained here so that the reader can comprehend buffer overflow better.
The other concept that the reader needs to imbibe in order to understand the complete essence of stack overflows is the pointers. Apart from the stack pointer which points to the top of the stack, there is a frame pointer (FP) which points to a fixed location within a frame. Local variables are usually referenced by their offsets from the stack pointer. However, as the stack operations take place, the value of these offsets vary. Moreover, on processors such as the Intel-based processors, accessing a variable at a known distance from the stack pointer requires multiple instructions.
Therefore, a second register may be used for referencing those variables and parameters whose relative distance from the frame pointer does not change with stack operations. On Intel processors, the base pointer (BP) also known as the extended base pointer (EBP) is used for this purpose. Let us see how this is used when a procedure is called.
| |
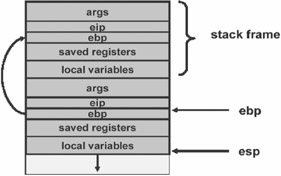
| |
Associated with each procedure is a stack frame that contains the arguments to the function, the instruction pointer (extended instruction pointer (EIP) in the register) of the caller (i.e. the address to which control should return when the procedure exits), a copy of the caller's frame pointer (the EBP in the register), which links the stack frame to the previous frame, space to save any registers modified by the procedure, and space for local variables used by the procedure.
If we look at the events in the register, we see that the frame pointer register (EIP) points into the stack frame at a fixed position, immediately after the saved copy of the caller's instruction pointer. The value of the frame pointer is not changed by the procedure, other than setting it on entry to the procedure and restoring it on exit. The stack pointer (i.e. extended stack pointer (ESP)) always points to the last item on the stack, while new allocations (e.g. for arguments to be passed to the next procedure) are performed here.
When a procedure is called, it first saves the previous frame pointer and pushes the frame pointer, and extended base pointer onto the stack. It then copies the stack pointer into the extended base pointer, thereby creating a new frame pointer. This process is called the procedure prolog and also involves reserving space for the local variables (by subtracting the size of the local variable from the stack pointer) and advancing the stack pointer. When the procedure exits, another process called the procedure epilog cleans up the stack and restores the frame pointer. Note that these frames are of variable size ”the size of the space reserved for local data depends on the procedure, as does the size of the space reserved for registers.
So, what does it take to deal with buffer flow exploits? Knowledge of the C programming language, an understanding of assembly language and working of system calls as we have discussed above, and the ability to guess a few parameters. In the next section we will explore how an attacker discovers code with buffer overflow vulnerability and exploits it. Let us see how the allocation is done on a run -time stack.
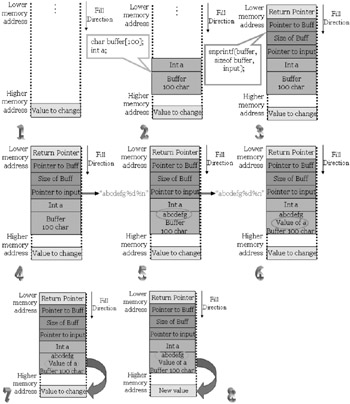
| |
There are two ways to detect buffer overflows.
-
The first one is looking at the source code. In this case, the hacker can look for strings declared as local variables in functions or methods and verify the presence of boundary checks. It is also necessary to check for improper use of standard functions, especially those related to strings and input/output.
-
The second way is by feeding the application with huge amounts of data and check for abnormal behavior.
| |
| Note | The first question that arises in the practical context is: how does an attacker discover buffer overflow vulnerability in particular software. We are referring to those who systematically examine programs to discover such vulnerabilities. To start, he can try to reverse the code using a disassembler or debugger and examine the code for vulnerabilities. Disassembly begins from the entry point of the program, and follows all routes of execution, then continues to locate functions outside of the main flow of the program. He may train his focus on functions lying outside the main ( ) and check those subroutines that take strings as their input or generate them as output. |
We had mentioned that programs written in C are particularly susceptible. This is because the language does not have any built-in bounds checking, and overflows are discernible as they write past the end of a character array. The standard C library provides a number of functions for copying or appending strings that perform no boundary checking. These include: strc at (), strcpy (), sprintf (), and vsprintf (). These functions operate on null- terminated strings, and do not check for overflow of the receiving string.
The gets () function reads a line from stdin into a buffer until either a terminating newline or EOF occurs. It performs no checks for buffer overflows. The scanf() family of functions can also give rise to potential overflows if the program attempts to match a sequence of non- white-space characters (%s), or non-empty sequence of characters from a specified set (%[]); and the array pointed to by the char pointer, is inadequate to accept the entire sequence of characters, and the optional maximum field width is not specified. If the target of any of these functions is a buffer of static size, and its other argument is derived from user input there is a good chance of encountering a buffer overflow.
Most hackers point out that ingenuity is critical for exploiting buffer overflow vulnerability. This is true especially when one has to guess a few parameters. For instance, if you are looking at software that assists in communication such as FTP, you will be looking at commands that are typically used and how they are implemented. For instance, the attacker can search for text and pick out a suspect variable from a table. He can then go on and check the code for any boundary checks and functions such as strcpy () that take input directly from the buffer. The emphasis will be on local variables and parameters. He can then test the code by providing malformed input and observe the behavior of the code.
Another method an attacker can use to discover a buffer overflow vulnerability is to adopt a brute force approach by using an automated tool to bombard the program with excessive amounts of data and cause the program to crash in a "meaningful way". He can then examine the dump of the registers for evidence that the data bombarding the program made its way into the instruction pointer.
What happens after the buffer overflow vulnerability is discovered ? On discovering vulnerability, the attacker will observe carefully how the call obtains its user input and how it is routed through the function call. The attacker can write an exploit by which he can make the software do things it would not do normally. This can range from simply crashing the machine to injecting code so that the attacker can gain remote access to the machine. He may use the remote system as a launch base for further attacks. However, the greatest threat comes when a malicious program such as a worm is written to take advantage of the buffer overflow. This can cause extensive damage. Building an exploit requires knowledge of the specific CPU and operating system of the target.
| |
-
Assuming that a string function is being exploited, the attacker can send a long string as the input.
-
This string overflows the buffer and causes a segmentation error.
-
The return pointer of the function is overwritten and the attacker succeeds in altering the flow of execution.
-
If he has to insert his code in the input, he has to:
-
Know the exact address on the stack
-
Know the size of the stack
-
Make the return pointer point to his code for execution
-
| |
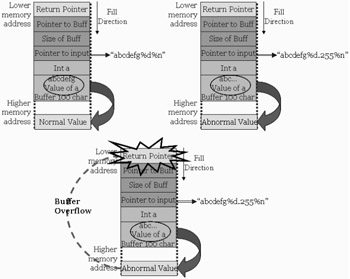
The illustration above depicts the way an abnormal input causes the buffer to overflow and cause segmentation error. Eventually the return pointer is overwritten and the execution flow of the function is interrupted . Now, if the attacker wants to make the function execute an arbitrary code of his choice, he will have to make the return pointer point towards this code.
The challenge he faces are:
-
He has to first determine the size of the buffer.
-
He must know the address of the stack so that he can get his input to rewrite the return pointer. He must ascertain the exact address for this.
-
He must write a program small enough that it can be passed through the input.
Usually, the goal of the attacker is to spawn a shell and use it to direct further commands.
The code to spawn a shell in C looks like:
---------------------------------------------------------------------------- #include <stdio.h> Void main () { char *name [2]; name[o] = "/bin/sh"; name [1] = NULL; execve (name [0], name, NULL); } ----------------------------------------------------------------------------- Alternatively, he can place arbitrary code to be executed in the buffer that is to be overflowed, and overwrite the return address so that it points back into the buffer. For this, he must know the exact location in the memory space of the program whose code is to be exploited. A workaround for this challenge is to use a jump (JMP), and a CALL instruction. These instructions allow relative addressing and permit the attacker to point to an offset relative to the instruction pointer. This eliminates the need know the exact address in the memory to which the exploit code must point.
As, most operating systems mark the code pages with the read-only attribute, this makes the above discussed workaround an unfeasible one. The alternative is place the code to be executed into the stack or data segment, and transfer control to it. One way of achieving this is to place the code in a global array in the data segment. Does the exploit work? Yes.
Nevertheless, in most buffer overflow vulnerabilities, it is the character buffer that is subjected to the attack. Therefore any null code occurring in the shell code will be considered as the end of the string, and the code transfer will be terminated. The answer to this hindrance lies in NOP.
| |
-
Most CPUs have a No Operation instruction - it does nothing but advance instruction pointer.
-
Usually we can put some of these ahead of our program (in the string)
-
As long as the new return address points to a NOP we are OK
-
Attacker pad the beginning of the intended buffer overflow with a long run of NOP instructions (a NOP slide or sled) so the CPU will do nothing till it gets to the 'main event' (which preceded the 'return pointer')
-
Most intrusion detection Systems (IDS) look for signatures of NOP sleds ADMutate (by K2) accepts a buffer overflow exploit as input and randomly creates a functionally equivalent version (polymorphism)
| |
Even the best guess may not be good enough for an attacker to find the right address on the stack. If he is off by one byte more or one byte less there will be a segmentation violation or an invalid instruction. This can even cause the system to crash. The attacker can increase the odds of finding the right address by padding his code with NOP instructions. A NOP is just a command telling the processor to do nothing. Almost all processors have a NOP instruction that perform a null operation. In the Intel architecture the NOP instruction is one byte long and it translates to 0x90 in machine code. A long run of NOP instructions is called a NOP slide or sled and the CPU does nothing till it gets to the 'main event' (which precedes the 'return pointer').
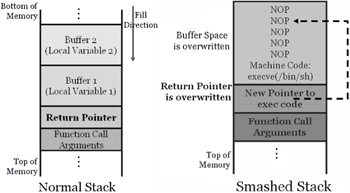
By including NOPs in advance of the executable code, the attacker can avert a segmentation violation if the pointer goes to the NOPs. The program will continue to execute down the stack until it gets to the attacker's exploit. In the preceding illustration, the attacker's data is written into the allocated buffer by the function. As the data size is not checked, the return pointer can be overwritten by the attacker's input. By this method, the attacker places exploit machine code in the buffer and overwrite the return pointer such that when the function returns, attacker's code is executed.
| |
For the NOP portion
-
Randomly replace the NOPs with functionally equivalent segments of code (e.g.: x++; x-; ? NOP NOP)
For the "main event"
-
Apply XOR to combine code with a random key unintelligible to IDS and CPU code must also decode the gibberish in time to run decoder is itself polymorphic, so hard to spot
For the "return pointer"
-
Randomly tweak LSB of pointer to land in NOP-zone.
| |
Most Intrusion Detection Systems (IDSs) look for signatures of NOP sleds. Detecting an array of NOP can be indicative of a buffer overflow exploit over the network. Taking the concept a bit further is ADMutate (by K2). ADMutate accepts a buffer overflow exploit as input and randomly creates a functionally equivalent version (polymorphism, part deux). This is also known as polymorphic buffer overflow. Polymorphism is the ability to exist in multiple forms.
| Tools | ADMutate substitutes the conventional NOP with operationally inert commands. ADMutate encodes the shellcode with a simple mechanism (xor) so that the shellcode will be unique to any NIDS sensor. This makes it bypass shellcode signature analysis. The shell code is encoded by XORing with a randomly generated key. It modulates the return address - least significant byte altered to jump into different parts of NOPs. |
It also allows the attacker to apply different weights to generated ASCII equivalents of machine language code, and to tweak the statistical distribution of resulting characters. This makes the traffic look more like "standard" for a given protocol, from a statistical perspective. For example: more heavily weight characters "<" and ">" in HTTP protocol. To further reduce the pattern of the decoder, out-of-order decoders are supported. This allows the user to specify where in the decoder certain operational instructions may be located.
ADMutate is designed to defeat IDS signature checking by altering the appearance of buffer overflow exploits. It uses techniques borrowed from virus creators and works on Intel, Spare, and HPPA processors. The likely targets are Linux, Solaris, IRIX, HPUX, OpenBSD, UnixWare, OpenServer, TRU64, NetBSD, and FreeBSD. While the polymorphic buffer overflow might be the most dramatic way to sneak by IDS, there are many other ways that involve hiding attack code inside large data flows directed at a target.
| |
-
Once vulnerable process is commandeered, the attacker has the same privileges as the process can gain normal access, then exploit a local buffer overflow vulnerability to gain super-user access.
Create a backdoor
-
Using (UNIX-specific) inetd
-
Using Trivial FTP (TFTP) included with Windows 2000 and some UNIX flavors
Use Netcat to make raw, interactive connection
-
Shoot back an Xterminal connection
-
UNIX-specific GUI
| |
| Threat | There are two parts to the attacker's input - an injection vector and a payload. They may be separate or put together. The injection vector is the actual entry-point, and usually tied explicitly with the bug itself. It is OS/target/application/protocol/encoding dependant. On the other hand, the payload is usually not tied to bug at all and contained by the attacker's ingenuity alone. Even though it can be independent of the injection vector, it still depends on machine, processor, etc. |
Once the stack is smashed the attacker can deploy his payload. This can be anything. For example, in UNIX, a command shell can be spawned. Example: /bin/sh. In Windows NT/2000, a specific Dynamic Link Library (DLL) - external ones may be preferable - may be used for further probing. Example: WININET.DLL can be used to send requests to and get information from network, to download code or retrieve commands to execute.
Denial of Service may be launched by the attacker or he may use the system as a launching point (arp spoofing). Probably the common use is to spawn a remote shell. The exploited system can be converted into a covert channel or simulate 'netcat' to make raw, interactive connection. The payload can be a worm that replicates itself and searches fresh targets. The attacker can also install a rootkit eventually and remain in a stealth mode after gaining super-user access.
| |
-
Manual auditing of code
-
Disabling Stack Execution
-
Safer C library support
-
Compiler Techniques

| |
| Countermeasures | Countermeasures Manual auditing of code: Search for the use of the unsafe functions in the C library like strcpy() and replace them with safe functions like strncpy () which takes the size of the buffer into account. Manual auditing of the source code must be used for each program which makes this a massive and very expensive approach. |
Disabling Stack Execution: A simple solution is the option to install the operating system with stack execution disabled. The idea is simple, inexpensive to install and relatively effective against the current crop of attacks. There are some serious weaknesses to this approach. Some programs do rely on the stack to be executable. Most common buffer overflows rely on code to be injected into the buffer and then executed.
Safer C library support: A robust alternative is to provide a safe version to the C library functions on which the attack relies to overwrite the return address. It works with the binaries of the target program's source code and does not require access to program's source code. It can be deployed without having to wait for the vendor to react to security threats. This is available for Windows 2000 systems. It is an effective technique.
Compiler Techniques: Range checking of indices is a defense that is 100% effective against buffer overflow attacks. Java automatically checks if an array index is within the proper bounds. Use compiler like Java instead of C to avoid buffer overflow attacks.
| |
-
StackGuard: Protects Systems From Stack Smashing Attacks
-
StackGuard is a compiler approach for defending programs and systems against "stack smashing" attacks.
-
Programs that have been compiled with StackGuard are largely immune to Stack smashing attack.
-
Protection requires no source code changes at all. when a vulnerability is exploited, StackGuard detects the attack in progress, raises an intrusion alert, and halts the victim program.
http://www.cse.ogi.edu/DISC/projects/immunix/StackGuard/
| |
| Tools | StackGuard is a compiler that emits programs hardened against "stack smashing" attacks. Stack smashing attacks are the most common form of penetration attack. Programs that have been compiled with StackGuard are largely immune to stack smashing attack. Protection requires no source code changes at all. |
When a vulnerable program is attacked , StackGuard detects the attack in progress, raises an intrusion alert, and halts the victim program. Usually, buffer overflows occur by writing data past the end of an allocated array. Thus the attacker can make arbitrary changes to program state stored adjacent to the array. The common data structure to attack is the current function's return address stored on the stack.
StackGuard detects and defeats stack smashing attacks by protecting the return address on the stack from being altered. StackGuard places a "canary" word next to the return address when a function is called. If the canary word has been altered when the function returns, then a stack smashing attack has been attempted, and the program responds by emitting an intruder alert into syslog, and then halts. To be effective, the attacker must not be able to "spoof" the canary word by embedding the value for the canary word in the attack string.
StackGuard is implemented as a small patch to the gcc code generator, specifically the function_prolog() and function_epilog() routines. function_prolog () has been enhanced to lay down canaries on the stack when functions start, and function_epilog () checks canary integrity when the function exits. Any attempt at corrupting the return address is thus detected before the function returns. The original release of StackGuard also supported an un-released kernel extension called "MemGuard" that provided fine-grained memory protection. This mechanism simply made the return address on the stack non-writable while the function is active.
| |
-
Immunix System 7 is an Immunix-enabled RedHat Linux 7.0 distribution and suite of application-level security tools.
-
Immunix secures a Linux OS and applications
-
Immunix works by hardening existing software components and platforms so that attempts to exploit security vulnerabilities will fail safe. i.e. the compromised process halts instead of giving control to the attacker, and then is restarted.
http://immunix.org
| |
| Tools | Immunix Secured Linux 7+ is an Immunix-enabled distribution similar to RedHat Linux 7.0 and a suite of application-level security tools. Immunix" is a family of tools designed to enhance system integrity by hardening system components and platforms against security attacks. Immunix secures a Linux OS and applications. Immunix works by hardening existing software components and platforms so that attempts to exploit security vulnerabilities will fail safe, i.e. the compromised process halts instead of giving control to the attacker, and then is restarted. The software components are effectively "laminated" with Immunix technologies to harden them against attack. |
The most common strategy for dealing with buffer overflows is to apply a patch to the code that will check the length of the data before it is saved to the buffer. This patching strategy has several fundamental drawbacks:
-
It is a reactive strategy, i.e., by the time the patch is issued, damage may have occurred.
-
There is a large time and expense associated with constant patching, and often patches go uninstalled .
-
Linux administration expertise is necessary to apply patches.
Immunix technology works by proactively protecting the operating system and applications from buffer overflows, both known and unknown. When Immunix detects such an attack, it causes the application to exit, rather than yield control to the attacker. By neutralizing buffer overflow vulnerabilities, hackers cannot exploit them to compromise the server. Immunix is designed specifically to provide containment of suspect programs, allowing the system administrator to clearly and concisely specify the set of resources that a program may access, and the operations the program may perform.
| |
| |
| |
-
A buffer overflow occurs when a program or process tries to store more data in a buffer (temporary data storage area) than it was intended to hold.
-
Buffer overflow attacks depend on two things: the lack of boundary testing and a machine that can execute code that resides in the data/stack segment.
-
Buffer Overflows vulnerability can be detected by skilled auditing of the code as well as boundary testing.
-
Once the stack is smashed the attacker can deploy his payload and take control of the attacked system.
-
Countermeasures include: checking the code, Disabling Stack Execution, Safer C library support, using safer Compiler Techniques.
-
Tools like stackguard, Immunix and vulnerability scanners help securing systems.
| |
EAN: N/A
Pages: 109