Applying the SAN to OLTP Workloads
| |
What are OLTP workloads? Multiple users performing a set of consistent transactions characterize online transaction processing workloads. The transaction mix will be simple to complex, but consistent in its processing requirements, usually applying an 80/20 rule (that is, 80% simple, 20% complex). The transaction type identifies its nature in terms of resource utilization, I/O content, and I/O utilization. If we use our banking application as an example, the tellers perform most of their transactions using the deposit transaction. This transaction verifies a customer account and adds the deposit to a suspense balance. The suspense files would be used as input for later off-shift processing during a batch cycle to update permanent customer records and accounts.
In this case, the simple transactions I/O content is approximately 80 bytes of customer and account information. This is accomplished with a minimum of simple math additions and balance calculations within the application. Although small, these are executed on a transaction-by-transaction basis and require an existing file or database table be updated. Given that profile, each transaction generates an I/O operation to complete the transaction process. Meanwhile, every associated I/O completes a read/write operation to a specific disk within the supporting storage array. In the case of RAID implementation, the physical I/Os will increase based upon the type of RAID level in operation within the storage array.
Consequently, the I/O workload is characterized by many small transactions where each will require an I/O operationmultiple I/Os as RAID is introduced. As the transaction rate builds during peak utilization, the workload is further characterized by additional simple transactions adding multiple I/Os, all requiring completion within a three- to five-second time period ( essentially the service level for the deposit transaction). The workload and service level demands a configuration that can handle the peak load. This requires a large number of data paths to handle the I/O transaction rate.
SANs are excellent choices for OLTP workloads because they can provide more data paths than any other storage model. Given the flexibility of the storage network, the scalability of the I/O workload can be enhanced without the addition of server resources.
SANs also provide the additional benefit of data partitioning flexibility. Given that most OLTP applications leverage the services of an RDBMS, the ability to utilize the databases partitioning schemes intra-array and inter-array provides the additional balance necessary to physically locate data for OLTP access.
Most OLTP applications support an operational aspect of a business. Therefore, data availability is important given that the day-to-day activities of the business depend on processing transactions accurately. Any downtime has an immediate effect on the business and therefore requires additional forms of redundancy and recovery to compensate for device failures and data integrity problems. SANs offer an environment that enhances a configurations ability to provide these mechanisms in the most efficient manner.
Additional discussion regarding recovery and fault-tolerant planning can be found in Part VI of this book. However, its important to note that each of the workloads discussed will have various degrees of business impact and therefore require different levels of recovery management.
The Data Organizational Model
The use of relational database technology (RDBMSs) defines the major I/O attributes for commercial applications. This provides OLTP workloads with a more defined set of processing metrics that enhances your ability to estimate I/O behavior and utilization. The use of the relational database has become so accepted and widespread that its macro behavior is very predictable. In recognition of this, additional consideration should be given to I/O workload characteristics relative to I/O processing requirements such as caching, temporary workspace, and partitioning.
Dont make the mistake of overlaying the storage infrastructure too quickly. The consideration of recovery scenarios and availability requirements should be considered at the macro-level first, followed by decisions on how to handle workload specifics. Particular subsets of a workload, such as a complex set of deposit transactions, may require different resources or configurations.
OLTP workloads using an RDBMS can be supported through RAID arrays using level 5 configurations. This provides both redundancy and fault tolerance needs. RAID 5 allows the storage array to continue to function if a disk is lost, and although running in a degraded mode it permits dynamic repair to the array, or, if needed, an orderly shutdown of the database itself. Additional storage system features, such as caching strategies and recovery models, require due consideration given the unique nature of the data contained within the relational database model.
User Access
User traffic plays a significant role in defining the number of data paths necessary for the OLTP transactions to be processed within the service level. Obviously, we need to know the estimated traffic to understand the type, number, and behavior of the data paths prior to assigning the configuration ports. We basically need three types of information from the end users or their representativesthe application systems analysts. This information consists of the number of transactions, the time period within which the transactions will be executed, and the expected service level.
The deposit transaction used in our example banking application comes in three forms: simple, authorized, and complex. Simple requires an update to a customer table, while authorized requires an authorized write to the permanent system of record for the account, necessary for a double write to take place when accessing more than one database table. Complex requires the authorized transactions but adds an additional calculation on the fly to deposit a portion into an equity account. Each of these have a different set of data access characteristics even though they belong to the same OLTP workload.
Service levels become critical in configuring the SAN with respect to user access. This places our eventual, albeit simple, calculations into a framework to define the resources needed to sustain the amount of operations for the OLTP workload. From our initial information, we find there are two goals for the I/O system. First, the banking applications data needs to be available from 9 A.M . to 5 P.M. each workday . Second, the transactions should complete within a time frame of 5 seconds. It is important to note that although the I/O can and will take up a great deal of the response time factors, network latency issues should not go without consideration.
In addition, the configuration must support a high availability uptime, usually expressed in terms of the percentage of downtime for a period. Therefore, 99 percent uptime requires the configuration to only be down 1 percent of the time. For example, if the OLTP time period is 12 hours each workday, the downtime cannot exceed 7.2 minutes every day. The users expect availability of data, which is a foundation requirement for meeting the response time (in other words, the data must be available to process the transactions, as well as be available during the batch cycle to process information for updating other database tables). This also forms the requirement for supporting the reliability factors and defines the type of storage partitioning and structure suited to providing this.
Data Paths
Next, we need to understand the data highway required for this workload. This necessitates breaking down our first two categories into a logical infrastructure for the workload. By comparing the data organizational model (that is, the database type and its characteristics, as well as the byte transfer requirements) with something called the concurrent factor , we can begin to formulate the number of data paths necessary to meet workload service levels. The concurrent factor provides us with a minimal and logical set of paths to sustain our service level, given the probability of all tellers executing deposit transactions at the same time.
This estimate provides a more accurate picture of the amount of resources needed to sustain the service level in real time. In reality, the probability of all tellers executing a deposit transaction is actually quite high during peak hours, and could be calculated at 90 percent. Therefore, for each time period, 90 percent of the tellers would be executing a deposit transaction. Using our previous calculation, we estimate the mix of simple, authorized, and complex deposit transactions to be 80, 15, and 5 percent, respectively.
We can develop our own OLTP SAN model by using the preceding considerations as well as the guidelines for I/O workload port estimates. With our banking example, we estimate that 116 switch ports are required to support the OLTP application. From this information, we can begin to model the appropriate design topology for the I/O workloads. Our previous definitions lead us to a core /edge configuration, which supports the maximum number of data paths into the storage arrays, while minimizing the length of each transfer for each I/O (for example, the number of interswitch hops is kept to a minimum). This is also the configuration that provides the best redundancy when alternative paths are needed in the event of a port interruption or switch failure. Cost not withstanding, we can now evaluate configuration options with this logical model in terms of switch types, port densities , and recovery options.
The value of workload identification, definition, and characterization becomes evident as we move into the OLTP SAN implementations .
The Design and Configuration of OLTP-Based Workloads
Figure 18-4 shows an example of our core/edge configurations supporting the OLTP application. This configuration is comprised of four FC switches, 15 disk arrays, intersystem -link ports, and an integrated FC-SCSI bridge into a tape library. This supports our workload analysis estimate of ports using three servers with two HBAs, respectively. It assumes a relational database that is capable of partitioning among the storage arrays and leveraging a RAID 5level protection scheme within each array.
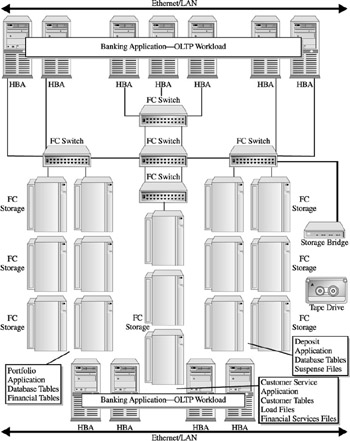
Figure 18-4: An OLTP workload using a core/edge SAN configuration
| |
EAN: 2147483647
Pages: 192