Basic Modification Operations
SQL has three basic data modification statements: INSERT, UPDATE, and DELETE. In previous chapters, we used some of these in examples without comment, assuming that you're already familiar with them. Here, we'll quickly review the most typical operations. Along with SELECT, the INSERT, UPDATE, and DELETE statements are referred to as DML , or data manipulation language . (DML is sometimes mistakenly referred to as data modification language , in which case SELECT couldn't be included, because it doesn't modify anything.) SELECT can manipulate data as it's being returned by using functions, aggregates, grouping, and so forth. (Create operations such as CREATE TABLE are DDL ” data definition language ”whereas security operations such as GRANT/DENY/REVOKE are DCL ” data control language .)
INSERT
You generally use INSERT to add one row to a table. Here's the most common form of INSERT:
INSERT [INTO] {table_nameview_name} [(column_list)] VALUES value_list |
In SQL Server, the use of INTO is always optional. ANSI SQL specifies using INTO, however. If you're providing a value for every column in the table, and the values appear in the exact order in which the columns were defined, the column list is optional. (The one exception to this is when the table has an identity column, which you must not include in the list of values. You'll learn more about inserting into a table that contains an identity column a bit later in this chapter.) If you omit a value for one or more columns or if the order of your values differs from the order in which the columns were defined for the table, you must use a named columns list. If you don't provide a value for a particular column, that column must allow NULL, or it must have a default declared for it. (You can use the keyword DEFAULT as a placeholder.) You can explicitly enter NULL for a column, or SQL Server will implicitly enter NULL for an omitted column for which no default value exists.
You can issue an INSERT statement for a view, but the row is always added to only one underlying table. (Remember that views don't store any data of their own.) You can insert data into a view, as long as values (or defaults) are provided for all the columns of the underlying table into which the new row is added. Following are some simple examples of using INSERT statements in a table that is similar to publishers in the pubs sample database. The CREATE TABLE statement is shown so that you can easily see column order and so that you can see which columns allow NULL and which have defaults declared.
CREATE TABLE publishers2 ( pub_id int NOT NULL PRIMARY KEY IDENTITY, pub_name varchar(40) NULL DEFAULT ('Anonymous'), city varchar(20) NULL, state char(2) NULL, country varchar(30) NOT NULL DEFAULT('USA') ) GO INSERT publishers2 VALUES ('AAA Publishing', 'Vancouver', 'BC', 'Canada') INSERT INTO publishers2 VALUES ('Best Publishing', 'Mexico City', NULL, 'Mexico') INSERT INTO publishers2 (pub_name, city, state, country) VALUES ('Complete Publishing', 'Washington', 'DC', 'United States') INSERT publishers2 (state, city) VALUES ('WA', 'Poulsbo') INSERT publishers2 VALUES (NULL, NULL, NULL, DEFAULT) INSERT publishers2 VALUES (DEFAULT, NULL, 'WA', DEFAULT) INSERT publishers2 VALUES (NULL, DEFAULT, DEFAULT, DEFAULT) INSERT publishers2 DEFAULT VALUES GO |
The table has these values:
pub_id pub_name city state country ------ ------------------- ----------- ----- ------------- 0001 AAA Publishing Vancouver BC Canada 0002 Best Publishing Mexico City NULL Mexico 0003 Complete Publishing Washington DC United States 0004 Anonymous Poulsbo WA USA 0005 NULL NULL NULL USA 0006 Anonymous NULL WA USA 0007 NULL NULL NULL USA 0008 Anonymous NULL NULL USA |
These INSERT examples are pretty self-explanatory, but you should be careful of the following:
- If a column is declared to allow NULL and it also has a default bound to it, omitting the column entirely from the INSERT statement results in the default value being inserted, not the NULL value. (This is also true if the column is declared NOT NULL.)
- Other than for quick-and-dirty, one-time use, you're better off providing the column list to explicitly name the columns. Your INSERT statement will still work even if you add a column via ALTER TABLE.
- If one of the INSERT statements in this example had failed, the others would have continued and succeeded. Even if we wrapped multiple INSERT statements in a BEGIN TRAN/COMMIT TRAN block (and did nothing more than that), a failure of one INSERT (because of an error such as a constraint violation or duplicate value) wouldn't cause the others to fail. This behavior is expected and proper. If you want all the statements to fail when one statement fails, you must add error handling. (Chapter 13 covers error handling in more detail.)
- The special form of the INSERT statement that uses DEFAULT VALUES and no column list is a shorthand method that enables you to avoid supplying the keyword DEFAULT for each column.
- You can't specify the column name for a column that has the Identity property, and you can't use the DEFAULT placeholder for a column with the Identity property. (This would be nice, but SQL Server doesn't currently work this way.) You must completely omit a reference to the identity column. To explicitly provide a value for the column, you must use SET IDENTITY_INSERT ON. You can use the DEFAULT VALUES clause, however.
Behavior of DEFAULT and NULL
You should understand the general behavior of INSERT in relationship to NULL and DEFAULT precedence. If you omit a column from the column list and the values list, the column takes on the default value, if one exists. If a default value doesn't exist, SQL Server tries a NULL value. An error results if the column has been declared NOT NULL. If NULL is explicitly specified in the values list, a column is set to NULL (assuming it allows NULL), even if a default exists. When you use the DEFAULT placeholder on a column allowing NULL and no default has been declared, NULL is inserted for that column. An error results in a column declared NOT NULL without a default if you specify NULL or DEFAULT, or if you omit the value entirely.
Table 8-1 summarizes the results of an INSERT statement that omits columns, specifies NULL, or specifies DEFAULT, depending on whether the column is declared NULL or NOT NULL and whether it has a default declared.
Expressions in the VALUES Clause
So far, the INSERT examples have demonstrated only constant values in the VALUES clause of INSERT. In fact, you can use a scalar expression such as a function or a local variable in the VALUES clause. (We'll see functions and variables in Chapter 9. Hopefully, the basics are clear. If not, you can take a quick look ahead and then return to this chapter.) You can't use an entire SELECT statement as a scalar value even if you're certain that it returns only one row and one column. However, you can take the result of that SELECT statement and assign it to a variable, and then you can use that variable in the VALUES clause. In the next section, we'll see how a SELECT statement can completely replace the VALUES clause.
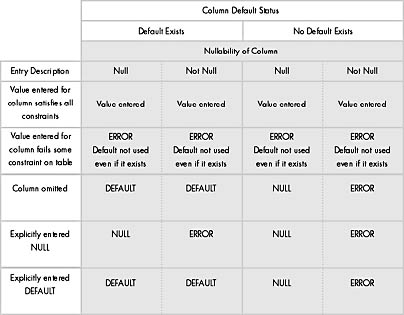
Table 8-1. The effects of an INSERT statement that omits columns, specifies NULL, or specifies DEFAULT.
Here's a contrived example that demonstrates how functions, expressions, arithmetic operations, string concatenation, and local variables are used within the VALUES clause of an INSERT statement:
CREATE TABLE mytable ( int_val int, smallint_val smallint, numeric_val numeric(8,2), tiny_const tinyint, float_val float, date_val datetime, char_strng char(10) ) GO DECLARE @myvar1 numeric(8, 2) SELECT @myvar1=65.45 INSERT mytable (int_val, smallint_val, numeric_val, tiny_const, float_val, date_val, char_strng) VALUES (OBJECT_ID('mytable'), @@spid, @myvar1 / 10.0, 5, SQRT(144), GETDATE(), REPLICATE('A', 3) + REPLICATE('B', 3)) GO SELECT * FROM mytable GO |
Your results should look something like this:
int_val smallint_val Numeric_val tiny_const float_val ---------- ------------ ----------- ---------- --------- 162099618 12 6.55 5 12.0 date_val char_string ---------- ------------ 1999-08-19 AAABBB 13:09:38.790 |
If you run this query, your values will be slightly different because your table will have a different object_id value, your process ID ( spid ) might be different, and you'll certainly be executing this query at a different date and time.
Multiple-Row INSERT Statements
The most typical use of INSERT is to add one row to a table. However, two special forms of INSERT (INSERT/SELECT and INSERT/ EXEC ) and a special SELECT statement (SELECT INTO) allow you to add multiple rows of data at once. Note that you can use the system function @@ROWCOUNT after all these statements to find out the number of rows affected.
INSERT/SELECT As mentioned earlier, you can use a SELECT statement instead of a VALUES clause with INSERT. You get the full power of SELECT, including joins, subqueries, UNION, and all the other goodies . The table you're inserting into must already exist; the table can be a permanent table or a temporary table. The operation is atomic, so a failure of one row, such as from a constraint violation, causes all rows chosen by the SELECT statement to be thrown away. An exception to this occurs if a duplicate key is found on a unique index created with the IGNORE_DUP_KEY option. In this case, the duplicate row is thrown out but the entire statement continues and isn't aborted. You can, of course, also use expressions in the SELECT statement, and using the CONVERT function is common if the target table has a datatype that's different from that of the source table.
Here's an example: Suppose we want to copy the authors table (in the pubs sample database) to a temporary table. But rather than show the author ID as a char field in Social Security_number format with hyphens, we want to strip those hyphens out and store the ID as an int . We want to use a single name field with the concatenation of the last and first name. We also want to record the current date but strip off the time so that the internal time is considered midnight. (If you're working only with dates, this is a good idea because it avoids issues that occur when the time portions of columns aren't equal.) We'll also record each author's area code ”the first three digits of her phone number. We need the author's state, but if it's NULL, we'll use WA instead.
CREATE TABLE #authors ( au_id int PRIMARY KEY, au_fullname varchar(60) NOT NULL, date_entered smalldatetime NOT NULL, area_code char(3) NOT NULL, state char(2) NOT NULL ) GO INSERT INTO #authors SELECT CONVERT(int, SUBSTRING(au_id, 1, 3) + SUBSTRING(au_id, 5, 2) + SUBSTRING(au_id, 8, 4)), au_lname + ', ' + au_fname, CONVERT(varchar, GETDATE(), 102), CONVERT(char(3), phone), ISNULL(state, 'WA') FROM authors SELECT * FROM #authors |
Here's the result:
au_id au_fullname date_entered area_code state --------- ----------------- ------------------- --------- 172321176 White, Johnson 1998-08-19 00:00:00 408 CA 213468915 Green, Marjorie 1998-08-19 00:00:00 415 CA 238957766 Carson, Cheryl 1998-08-19 00:00:00 415 CA 267412394 O'Leary, Michael 1998-08-19 00:00:00 408 CA 274809391 Straight, Dean 1998-08-19 00:00:00 415 CA 341221782 Smith, Meander 1998-08-19 00:00:00 913 KS 409567008 Bennet, Abraham 1998-08-19 00:00:00 415 CA 427172319 Dull, Ann 1998-08-19 00:00:00 415 CA 472272349 Gringlesby, Burt 1998-08-19 00:00:00 707 CA 486291786 Locksley, Charlene 1998-08-19 00:00:00 415 CA 527723246 Greene, Morningstar 1998-08-19 00:00:00 615 TN 648921872 Blotchet-Halls, 1998-08-19 00:00:00 503 OR Reginald 672713249 Yokomoto, Akiko 1998-08-19 00:00:00 415 CA 712451867 del Castillo, Innes 1998-08-19 00:00:00 615 MI 722515454 DeFrance, Michel 1998-08-19 00:00:00 219 IN 724089931 Stringer, Dirk 1998-08-19 00:00:00 415 CA 724809391 MacFeather, Stearns 1998-08-19 00:00:00 415 CA 756307391 Karsen, Livia 1998-08-19 00:00:00 415 CA 807916654 Panteley, Sylvia 1998-08-19 00:00:00 301 MD 846927186 Hunter, Sheryl 1998-08-19 00:00:00 415 CA 893721158 McBadden, Heather 1998-08-19 00:00:00 707 CA 899462035 Ringer, Anne 1998-08-19 00:00:00 801 UT 998723567 Ringer, Albert 1998-08-19 00:00:00 801 UT |
INSERT/EXEC You can use INSERT with the results of a stored procedure or a dynamic EXECUTE statement taking the place of the VALUES clause. This procedure is similar to the INSERT/SELECT form, except that EXEC is used instead. The EXEC should return exactly one result set with types that match the table you've set up for it. You can pass parameters if executing a stored procedure, use EXEC(' string '), or even call out to extended procedures (your own custom DLLs) or to remote procedures on other servers. By calling to a remote procedure on another server, putting the data into a temporary table, and then joining on it, you get the capabilities of a distributed join.
An example explains this better: Suppose that we want to store the results of executing the sp_configure stored procedure in a temporary table. (You can also do this with a permanent table.)
CREATE TABLE #config_out ( name_col varchar(50), minval int, maxval int, configval int, runval int ) INSERT #config_out EXEC sp_configure SELECT * FROM #config_out |
Here's the result:
name_col minval maxval configval runval -------------------- ------ ---------- --------- -------- allow updates 0 1 0 0 default language 0 9999 0 0 fill factor (%) 0 100 0 0 language in cache 3 100 3 3 max async IO 1 255 32 32 max text repl size (B) 0 2147483647 65536 65536 max worker threads 10 1024 255 255 nested triggers 0 1 1 1 network packet size(B) 512 65535 4096 4096 recovery interval(min) 0 32767 0 0 remote access 0 1 1 1 remote proc trans 0 1 0 0 show advanced options 0 1 0 0 user options 0 4095 0 0 |
If we want to execute the procedure against the remote server named dogfood , that's almost as easy. Assuming the same table #config_out exists:
INSERT #config_out EXEC dogfood.master.dbo.sp_configure |
NOTE
Before executing a procedure on another server, you must perform several administrative steps to enable the servers to communicate with each other. Refer to the SQL Server documentation for the details. Once you carry out these few simple steps, procedures can be executed on the remote server by just including the name of the server as part of the procedure name, as shown in the previous example.
SELECT INTO SELECT INTO is in many ways similar to INSERT/SELECT, but it directly builds the table rather than requiring that the table already exist. In addition, SELECT INTO operates with a special nonlogged mode, which makes it faster. To use SELECT INTO to populate a permanent table, the database must have the select into/bulkcopy option enabled (for example, EXEC sp_dboption pubs, 'select into/bulkcopy', true ). Note that if you use SELECT INTO with a permanent table, your next backup must be a full database backup because the transaction log won't have the records for these operations. In fact, you'll get an error message if you try to back up the transaction log after running an unlogged operation.
NOTE
Always use nonlogged operations with care. Think about their effects on your backup and restore plans before you launch such an operation.
You can also use SELECT INTO with temporary tables (# and ## prefixed) without enabling the select into/bulkcopy option. Because temporary tables don't have to be recovered, not logging the data inserted into them isn't a problem. (A user executing SELECT INTO must have permission to select from the target table and also have CREATE TABLE permission, because this statement does both actions.)
SELECT INTO is handy. It's commonly used to easily copy a table or perhaps to drop a column that's no longer needed. In the latter case, you'd simply omit the unnecessary column from the select list. Or you can change the datatypes of columns by using CONVERT in the select list.
To illustrate the SELECT INTO statement, here's an equivalent operation to the earlier INSERT/SELECT example. The results, including the column names of the new temporary table, appear identical to those produced using INSERT/SELECT.
SELECT CONVERT(int, SUBSTRING(au_id, 1, 3) + substring(au_id, 5, 2) + substring(au_id, 8, 4)) AS au_id, au_lname + ', ' + au_fname AS au_fullname, convert(varchar, getdate(), 102) AS date_entered, convert(char(3), phone) AS area_code, isnull(state, 'WA') AS state INTO #authors FROM authors |
There's one important difference between the two procedures: the datatypes of the table created automatically are slightly different from the datatypes declared explicitly using INSERT/SELECT. If the exact datatypes were important, you could use CONVERT to cast them to the types you want in all cases, or you could create the table separately and then use INSERT/SELECT.
BULK INSERT
SQL Server 7 provides a command to load a flat file of data into a SQL Server table. However, no corresponding command exists to copy data out to a file. The file to be copied in must be either a local file or one available via a UNC name. Here's the general syntax for the command, called BULK INSERT:
BULK INSERT [[' database_name '.][' owner '].]{' table_name ' FROM data_file } [WITH ( [ BATCHSIZE [ = batch_size ]] [[,] CODEPAGE [ = ACP OEM RAW code_page ]] [[,] DATAFILETYPE [ = {'char' 'native' 'widechar' 'widenative'}]] [[,] FIELDTERMINATOR [ = 'field_terminator ']] [[,] FIRSTROW [ = first_row ]] [[,] FORMATFILE [ = ' format_file_path ']] [[,] KEEPIDENTITY] [[,] KEEPNULLS [[,] LASTROW [ = last_row ]] [[,] MAXERRORS [ = max_errors ]] [[,] CHECK_CONSTRAINTS] [[,] ORDER ({ column [ASC DESC]} [, ... n ])] [[,] ROWTERMINATOR [ = ' row_terminator ']] [[,] TABLOCK] ) |
To use the BULK INSERT command, the table must already exist. The number and datatypes of the columns must be compatible with the data in the file that you plan to copy in.Here's a simple example to give you a feel for what this command can do:
- Create a simple table in the pubs database, using the following batch:
USE pubs CREATE TABLE mybcp (col1 char(3), col2 INT)
- Use your favorite editor (for example, notepad ). Save a text file named mydata.txt to the root directory of drive C. Include the following text:
abc,1;def,2;ghi,3;
- Finally, load the file into the table with the following Transact -SQL statement:
BULK INSERT pubs.dbo.mybcp FROM 'c:\mydata.txt' WITH (DATAFILETYPE = 'char', FIELDTERMINATOR = ',', ROWTERMINATOR = ';')
NOTE
The BULK INSERT command will work only if SQL Server is running on the machine local to the specified logical disk, in this case, C.
As the syntax specification shows, the BULK INSERT command has quite a few possible arguments. These arguments appear in the online documentation, but some of the arguments might be unclear, so it's worth mentioning the highlights. (See Table 8-2.)
Table 8-2. BULK INSERT command arguments.
| Argument | Description |
|---|---|
| BATCHSIZE | Each batch is copied to the server as a single transaction. If an entire batch is successfully loaded, the data is immediately written to disk. If a server failure occurs in the middle of a batch, all rows in that batch will be lost, but all rows up to the end of the previous batch will still be available. By default, all data in the specified data file is one batch. |
| ORDER ( column_list ) where column_list = { column [ASC column_list as the destination DESC] [,... n ]} | The data file is already sorted by the same columns in table. A clustered index on the same columns, in the same order as the columns in column_list , must already exist in the table. Using a sorted data file can improve the performance of the BULK INSERT command. By default, BULK INSERT assumes the data file is unordered. |
| TABLOCK | A table-level lock is acquired for the duration of the bulk copy. It improves performance because of reduced lock contention on the table. This special kind of BulkUpdate lock is primarily compatible only with other BulkUpdate locks, so a table can be loaded quickly using multiple clients running BULK INSERT in parallel. By default, no table-level lock is acquired . You can still run parallel BULK INSERTS , but their performance will be much slower, similar to running individual INSERT statements. (Chapter 13 covers locking in detail.) |
| CHECK_CONSTRAINTS | Any constraints on the table are applied during the bulk copy. By default, constraints aren't enforced. Applying constraints can have several benefits and is the recommended approach. By checking the constraints on the data, you know that the data you load will be valid. In addition, SQL Server might be able to better optimize the entire operation, because it has advance knowledge of the kind of data that will be loaded. |
Unlike for previous versions of SQL Server, we don't always recommend that you drop all your indexes before running the BULK INSERT operation (or the BCP command, described in the next section). In many cases, the copy operation doesn't perform noticeably better if a table has no indexes, so you should usually leave your indexes on a table while copying data into it. The only exception is when you want to have multiple clients load data into the same table simultaneously ; then you should drop indexes before loading the data.
When SQL Server executes a BULK INSERT operation, the rows of data go straight into the server as an OLE DB row set. The functionality of a BULK INSERT operation is quite similar to that of the command-line utility BCP, which is discussed in the next section. In contrast to the BULK INSERT operation, BCP data is sent to SQL Server as a Tabular Data Stream (TDS) result set and flows through network protocols and ODS. This can generate a lot of additional overhead, and you might find that BULK INSERT is up to twice as fast as BCP for copying data into a table from a local file.
Tools and Utilities Related to Multiple-Row Insert
INSERT and BULK INSERT aren't the only ways to get data into SQL Server tables. SQL Server also provides some tools and utilities for loading tables from external sources. Because the focus of this book isn't on the utilities and tools, we won't discuss the details; however, you should at least be aware of the options available.
Bulk copy libraries, SQL-DMO objects, and BCP.EXE The ODBC standard doesn't directly support SQL Server bulk copy operations. When running against SQL Server version 7, however, the SQL Server 7 ODBC driver supports a set of older DB-Library functions that perform SQL Server bulk copy operations. The specialized bulk copy support requires that the following files be available: odbcss.h , odbcbcp.lib , and odbcbcp.dll .
The BCP.EXE command-line utility for SQL Server 7 is written using the ODBC bulk copy interface. This utility has little code other than that accepting various command-line parameters and then invoking the functions of the bcp library. We won't go into all the details of BCP.EXE here, except to say that it was built for function, not form. It's totally command-line driven. If you're a fan of UNIX utilities, you'll love it! The possible arguments are similar to those for the BULK INSERT command, and you can find a complete description in the online documentation.
The SQL-DMO BulkCopy object ultimately invokes these same bcp functions, but it provides some higher-level methods and ease of use within the world of COM (Component Object Model) objects. The BulkCopy object represents the parameters of a single bulk-copy command issued against SQL Server.
The BulkCopy object doesn't have a place in the SQL-DMO object tree. Instead, BulkCopy is used as a parameter to the ImportData method of the Table object and the ExportData method of the Table and View objects.
Data Transformation Services One of the most exciting tools available with SQL Server 7 is Data Transformation Services ( DTS ). Using this tool, you can import and export data to and from any OLE DB or ODBC data source. You can do a straight copy of the data, or you can transform the data using simple SQL statements or procedures. Alternatively, you can execute a Microsoft ActiveX script that modifies (transforms) the data when copied from the source to the destination, or you can perform any operation supported by the Microsoft JScript, PerlScript, or Microsoft Visual Basic Script (VBScript) languages.
Unlike the BCP and BULK INSERT operations just described, DTS creates the destination table for you as part of the copying operation and allows you to specify the exact column names and datatypes (depending on what the destination data store allows). DTS is installed by default with a standard SQL Server setup, and complete documentation is available in Books Online.
Transfer SQL Server Objects SQL Server Enterprise Manager puts an easy-to-use graphical interface on top of the SQL-DMO BulkCopy object to make it easy to transfer data between two SQL Server installations. This provides the same functionality as the SQL Transfer Manager utility or the transfer management interface in earlier versions of SQL Server. The tool allows you to transfer all objects ”not just data, but stored procedures, rules, constraints, and so on ”but only when moving from one SQL Server database to another SQL Server database. The Transfer Objects tool is accessible from the DTS Package Designer by specifying the task Transfer SQL Server Objects .
Whether you use the bcp libraries through the BCP.EXE utility, SQLDMO, BULK INSERT, or the transfer functions of SQL Enterprise Manager, be aware of a few bulk copy specifics:
- When used to copy data into a SQL Server table, bulk copy has two main forms: logged and nonlogged. (Previous versions of SQL Server called the two forms fast bulk copy and slow bulk copy. In SQL Server 7, both forms are very fast, so these terms are no longer used.) Nonlogged bulk copy is faster than logged bulk copy for several reasons. For one, the nonlogged copy moves data in units of extents at a time, instead of as single-row operations.
- Because nonlogged bulk copy doesn't allow any indexes on a table, there's no overhead of maintaining those indexes.
- Nonlogged bulk copy doesn't log the individual data rows inserted. (It does log page and extent allocations , however, so your transaction log will grow during a large copy operation.) As is true with any nonlogged operation, you must deal with any failures manually while the load is in progress. If that's not possible, use logged bulk copy, in which all activity is logged and therefore recoverable. If you can start everything over, including the table creation, use nonlogged bulk copy. With nonlogged bulk copy, the table must not have any indexes (which also means that it can't have a PRIMARY KEY or UNIQUE constraint). And the database must have the select into/bulk copy option enabled.
- If the table is marked for replication, the copy will be done using logged bulk copy. The flowchart in Figure 8-1 on the following page summarizes the conditions that determine whether a logged or nonlogged bulk copy operation will be performed.
If you can't use nonlogged bulk copy, you should use logged bulk copy. (Logged bulk copy is still faster than a standard INSERT statement because it comes in at a lower level within SQL Server.)
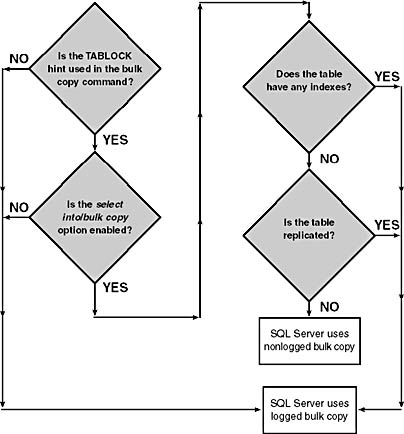
Figure 8-1. How SQL Server determines whether to execute a bulk copy operation in logged or nonlogged mode.
UPDATE
UPDATE, the next data modification statement, is used to change existing rows. Usually, UPDATE contains a WHERE clause that limits the update to only a subset of rows in the table. (The subset could be a single row, which would generally be accomplished by testing for equality to the primary key values in the WHERE clause.) If no WHERE clause is provided, every row in the table is changed by UPDATE. You can use the @@ROWCOUNT system function to determine the number of rows that were updated.
Here's the basic UPDATE syntax:
UPDATE {table_nameview_name} SET column_name1 = {expression1NULLDEFAULT(SELECT)} [, column_name2 = {expression2NULLDEFAULT(SELECT)} WHERE {search_conditions} |
Columns are set to an expression. The expression can be almost anything that returns a scalar value ”a constant, another column, an arithmetic expression, a bunch of nested functions that end up returning one value, a local variable, or a system function. You can set a column to a value conditionally determined using the CASE expression or to a value returned from a subquery. You can also set columns to NULL (if the column allows it) or to DEFAULT (if a default is declared or if the column allows NULL), much like with the INSERT statement.
You can set multiple columns in a single UPDATE statement. Like a multiple-row INSERT, an UPDATE that affects multiple rows is an atomic operation ”if a single UPDATE statement affects multiple rows and one row fails a constraint, all the changes made by that statement are rolled back.
The following simple UPDATE statements should be self-explanatory. Later in this chapter, we'll show you some that aren't this simple and intuitive.
-- Change a specific employee's last name after his marriage UPDATE employee SET lname='Thomas-Kemper' WHERE emp_id='GHT50241M' -- Raise the price of every title by 12% -- No WHERE clause so it affects every row in the table UPDATE titles SET price=price * 1.12 -- Publisher 1389 was sold, changing its name and location. -- All the data in other tables relating to pub_id 1389 is -- still valid; only the name of the publisher and its -- location have changed. UPDATE publishers SET pub_name='O Canada Publications', city='Victoria', state='BC', country='Canada' WHERE pub_id='1389' -- Change the phone number of authors living in Gary, IN, -- back to the DEFAULT value UPDATE authors SET phone=DEFAULT WHERE city='Gary' AND state='IN' |
Forcing the Use of DefaultsNotice the use of the keyword DEFAULT in the last example. Sometimes you'll want to stamp a table with the name of the user who last modified the row or with the time it was last modified. You could use system functions, such as SUSER_NAME() or GETDATE(), as the DEFAULT value, and then restrict all data modification to be done via stored procedures that explicitly update such columns to the DEFAULT keyword. Or you could make it policy that such columns must always be set to the DEFAULT keyword in the UPDATE statement, and then you could monitor this by also having a CHECK constraint on the same column that insists that the value be equal to that which the function returns. (If you use GETDATE(), you'll probably want to use it in conjunction with other string and date functions to strip off the milliseconds and avoid the possibility that the value from the DEFAULT might be slightly different than that in the CHECK.) Here's a sample using SUSER_NAME():
More Advanced UPDATE Examples
You can go well beyond these UPDATE examples, however, and use subqueries, the CASE statement, and even joins in specifying search criteria. (Chapter 9 covers CASE in depth.) For example, the following UPDATE statement is like a correlated subquery. It sets the ytd_sales field of the titles table to the sum of all qty fields for matching titles:
UPDATE titles SET titles.ytd_sales=(SELECT SUM(sales.qty) FROM sales WHERE titles.title_id=sales.title_id) |
In the next example, you can use the CASE expression with UPDATE to selectively give pay raises based on an employee's review rating. Assume that reviews have been turned in and big salary adjustments are due. A review rating of 4 doubles the employee's salary. A rating of 3 increases the salary by 60 percent. A rating of 2 increases the salary by 20 percent, and a rating lower than 2 doesn't change the salary.
UPDATE employee_salaries SET salary = CASE review WHEN 4 THEN salary * 2.0 WHEN 3 THEN salary * 1.6 WHEN 2 THEN salary * 1.2 ELSE salary END |
DELETE
DELETE, the last data manipulation statement, removes rows from a table. Once the action is committed, no undelete action is available. (If it's not wrapped in a BEGIN TRAN/COMMIT TRAN block, the COMMIT, of course, occurs by default as soon as the statement completes.) Because you delete only rows, not columns, you never specify column names in a DELETE statement as you do with INSERT or UPDATE. But in many other ways, DELETE acts much like UPDATE ”you specify a WHERE clause to limit the delete to certain rows. If you omit the WHERE clause, every row in the table will be deleted. The system function @@ROWCOUNT keeps track of the number of rows deleted. You can delete through a view but only if the view is based on a single table (because there's no way to specify to delete only certain rows in a multiple-table view). If you delete through a view, all the underlying FOREIGN KEY constraints on the table must still be satisfied for the delete to succeed.
Here's the general form of DELETE:
DELETE [FROM] {table_name view_name} [WHERE clause] |
The FROM preposition is ANSI standard, but its inclusion is always optional in SQL Server (similar to INTO with INSERT). The preposition must be specified per ANSI SQL. If the preposition is always needed, it is logically redundant, which is why SQL Server doesn't require it.
Here are some simple examples:
DELETE discounts -- Deletes every row from the discounts table but does not -- delete the table itself. An empty table remains. DELETE FROM sales WHERE qty > 5 -- Deletes those rows from the sales table that have a value for -- qty of 6 or more DELETE FROM WA_stores -- Attempts to delete all rows qualified by the WA_stores view, -- which would delete those rows from the stores table that have -- state of WA. This delete is correctly stated but would fail -- because of a foreign key reference. |
TRUNCATE TABLE
In the first example, DELETE discounts deletes every row of that table. Every row is fully logged. SQL Server provides a much faster way to purge all the rows from the table: using TRUNCATE TABLE empties the whole table by deallocating all the table's data pages and index pages. TRUNCATE TABLE is orders-of-magnitude faster than an unqualified DELETE against the whole table. Delete triggers on the table won't fire (because the rows deleted aren't individually logged), and TRUNCATE TABLE will still work. If a foreign key references the table to be truncated, however, TRUNCATE TABLE won't work. And if the table is publishing data for replication, which requires the log records, TRUNCATE TABLE won't work.
Despite contrary information, TRUNCATE TABLE isn't really an unlogged operation. The deletions of rows aren't logged because they don't really occur. Rather, entire pages are deallocated. But the page deallocations are logged. If TRUNCATE TABLE weren't logged, it couldn't be used inside transactions, which must have the capacity to be rolled back. A simple example demonstrates that the action can indeed be rolled back:
BEGIN TRAN -- Get the initial count of rows SELECT COUNT(*) FROM titleauthor 25 TRUNCATE TABLE titleauthor -- Verify that all rows are now gone SELECT COUNT(*) FROM titleauthor 0 -- Undo the truncate operation ROLLBACK TRAN -- Verify that rows are still there after the undo SELECT COUNT(*) FROM titleauthor 25 |
Modifying Data Through Views
You can specify INSERT, UPDATE, and DELETE statements on views as well as on tables, although you should be aware of some restrictions and other issues. Modifications through a view end up modifying the data in an underlying base table (and only one such table) because views don't store data. All three types of data modifications work easily for single-table views, especially in the simplest case in which the view exposes all the columns of the base table. But a single-table view doesn't necessarily have to expose every column of the base table ”it could restrict the view to a subset of columns only.
For any modification, all the underlying constraints of the base table must still be satisfied. For example, if a column in the base table is defined as NOT NULL and doesn't have a DEFAULT declared for it, the column must be visible to the view, and the insert must supply a value for it. If the column weren't part of the view, an insert through that view could never work because the NOT NULL constraint could never be satisfied. And, of course, you can't modify or insert a value for a column that's derived by the view, such as an arithmetic calculation or concatenation of two strings of the base table. (You can still modify the nonderived columns in the view, however.)
Basing a view on multiple tables is far less straightforward. You can issue an UPDATE statement against a view that is a join of multiple tables, but only if all columns being modified (that is, the columns in the SET clause) are part of the same base table. An INSERT statement can also be performed against a view that does a join only if columns from a single table are specified in the INSERT statement's column list. Only the table whose columns are specified will have a row inserted: any other tables in the view will be unaffected. A DELETE statement can't be executed against a view that's a join, because entire rows are deleted and modifications through a view can affect only one base table. (Because no columns are specified in a delete, from which table would the rows be deleted?)
In the real world, you would probably have little use for an INSERT statement against a view with a join because all but one table in the underlying query would be totally ignored. But the insert is possible. The following simple example illustrates this:
CREATE TABLE one ( col11 int NOT NULL, col12 int NOT NULL ) CREATE TABLE two ( col21 int NOT NULL, col22 int NOT NULL ) GO CREATE VIEW one_two AS (SELECT col11, col12, col21, col22 FROM one LEFT JOIN two ON (col11=col21)) GO INSERT one_two (col11, col12) VALUES (1, 2) SELECT * FROM one_two |
Here's the result set:
col11 col12 col21 col22 ----- ----- ----- ----- 1 2 NULL NULL |
Notice that this insert specifies values only for columns from table one , and only table one gets a new row. Selecting from the view produces the row only because LEFT OUTER JOIN is specified in the view. Because table two contains no actual rows, a simple equijoin would have found no matches. Although the row would still have been inserted into table one, it would have seemingly vanished from the view. You could specify the view as an equijoin and use WITH CHECK OPTION to prevent an insert that wouldn't find a match. But the insert must still affect only one of the tables, so matching rows would already need to exist in the other table. We'll come back to WITH CHECK OPTION in the next section; for now, we'll simply see how this would be specified:
CREATE VIEW one_two_equijoin AS (SELECT col11, col12, col21, col22 FROM one JOIN two ON (col11=col21)) WITH CHECK OPTION GO |
If we try to specify all columns with either view formulation, even if we simply try to insert NULL values into the columns of table two, an error results because the single INSERT operation can't be performed on both tables. (Admittedly, the error message is slightly misleading.)
INSERT one_two (col11, col12, col21, col22) VALUES (1, 2, NULL, NULL) Msg 4405, Level 16, State 2 View 'one_two' is not updatable because the FROM clause names multiple tables. |
Similarly, a DELETE against this view with a join will be disallowed and results in the same message:
DELETE one_two Msg 4405, Level 16, State 2 View 'one_two' is not updatable because the FROM clause names multiple tables. |
The UPDATE case isn't common, but it's somewhat more realistic. You'll probably want to avoid allowing updates through views that do joins, and the next example shows why. Given the following view,
CREATE VIEW titles_and_authors AS ( SELECT A.au_id, A.au_lname, T.title_id, T.title FROM authors AS A FULL OUTER JOIN titleauthor AS TA ON (A.au_id=TA.au_id) FULL OUTER JOIN titles AS T ON (TA.title_id=T.title_id) ) |
selecting from the view
SELECT * FROM titles_and_authors |
yields this:
au_id au_lname title_id title ----------- ------------- -------- --------------------------------- 172-32-1176 White PS3333 Prolonged Data Deprivation: Four Case Studies 213-46-8915 Green BU1032 The Busy Executive's Database Guide 213-46-8915 Green BU2075 You Can Combat Computer Stress! 238-95-7766 Carson PC1035 But Is It User Friendly? 267-41-2394 O'Leary BU1111 Cooking with Computers: Surreptitious Balance Sheets 267-41-2394 O'Leary TC7777 Sushi, Anyone? 274-80-9391 Straight BU7832 Straight Talk About Computers 409-56-7008 Bennet BU1032 The Busy Executive's Database Guide 427-17-2319 Dull PC8888 Secrets of Silicon Valley 472-27-2349 Gringlesby TC7777 Sushi, Anyone? 486-29-1786 Locksley PC9999 Net Etiquette 486-29-1786 Locksley PS7777 Emotional Security: A New Algorithm 648-92-1872 Blotchet-Halls TC4203 Fifty Years in Buckingham Palace Kitchens 672-71-3249 Yokomoto TC7777 Sushi, Anyone? 712-45-1867 del Castillo MC2222 Silicon Valley Gastronomic Treats 722-51-5454 DeFrance MC3021 The Gourmet Microwave 724-80-9391 MacFeather BU1111 Cooking with Computers: Surreptitious Balance Sheets 724-80-9391 MacFeather PS1372 Computer Phobic AND Non-Phobic Individuals: Behavior Variations 756-30-7391 Karsen PS1372 Computer Phobic AND Non-Phobic Individuals: Behavior Variations 807-91-6654 Panteley TC3218 Onions, Leeks, and Garlic: Cooking Secrets of the Mediterranean 846-92-7186 Hunter PC8888 Secrets of Silicon Valley 899-46-2035 Ringer MC3021 The Gourmet Microwave 899-46-2035 Ringer PS2091 Is Anger the Enemy? 998-72-3567 Ringer PS2091 Is Anger the Enemy? 998-72-3567 Ringer PS2106 Life Without Fear 341-22-1782 Smith NULL NULL 527-72-3246 Greene NULL NULL 724-08-9931 Stringer NULL NULL 893-72-1158 McBadden NULL NULL NULL NULL MC3026 The Psychology of Computer Cooking (30 rows affected) |
The following UPDATE statement works fine because only one underlying table, authors, is affected. This example changes the author's name from DeFrance to DeFrance-Macy .
UPDATE TITLES_AND_AUTHORS SET au_lname='DeFrance-Macy' WHERE au_id='722-51-5454' (1 row(s) affected) |
This UPDATE statement yields an error, however, because two tables from a view can't be updated in the same statement:
UPDATE TITLES_AND_AUTHORS SET au_lname='DeFrance-Macy', title='The Gourmet Microwave Cookbook' WHERE au_id='722-51-5454' and title_id='MC3021' Msg 4405, Level 16, State 2 View 'TITLES_AND_AUTHORS' is not updatable because the FROM clause names multiple tables. |
If you created the view, it might seem obvious that the UPDATE statement above won't be allowed. But if the person doing the update isn't aware of the underlying tables, which a view does a great job of hiding, it will not be obvious why one UPDATE statement works and the other one doesn't.
In general, it's a good idea to avoid allowing updates (and inserts) through views that do joins. Such views are extremely useful for querying and are wonderful constructs that make querying simpler and less prone to bugs from misstating joins. But modifications against them are problematic . If you do allow an update through a view that's a join, be sure that the relationships are properly protected via FOREIGN KEY constraints or triggers, or you'll run into bigger problems.
Suppose, for example, that we wanted to change only the au_id column in the example view above. If the existing value in the underlying authors table is referenced by a row in titleauthor, such an update won't be allowed because it would orphan the row in titleauthor . The FOREIGN KEY constraint protects against the modification. But here, we'll temporarily disable the FOREIGN KEY constraint between titleauthor and titles :
ALTER TABLE titleauthor -- This disables the constraint NOCHECK CONSTRAINT ALL |
Notice that although we'll be updating the authors table, the constraint we're disabling (the constraint that would otherwise be violated) is on the titleauthor table. New users often forget that a FOREIGN KEY constraint on one table is essentially a constraint on both the referencing table (here, titleauthors ) and on the referenced table (here, titles ). With the constraint now disabled, we change the value of au_id through the view for the author Anne Ringer:
-- With constraint now disabled, the following update succeeds: UPDATE titles_and_authors SET au_id='111-22-3333' WHERE au_id='899-46-2035' |
But look at the effect on the same SELECT of all rows in the view:
au_id au_lname title_id title ----------- ------------- -------- --------------------------------- 172-32-1176 White PS3333 Prolonged Data Deprivation: Four Case Studies 213-46-8915 Green BU1032 The Busy Executive's Database Guide 213-46-8915 Green BU2075 You Can Combat Computer Stress! 238-95-7766 Carson PC1035 But Is It User Friendly? 267-41-2394 O'Leary BU1111 Cooking with Computers: Surreptitious Balance Sheets 267-41-2394 O'Leary TC7777 Sushi, Anyone? 274-80-9391 Straight BU7832 Straight Talk About Computers 409-56-7008 Bennet BU1032 The Busy Executive's Database Guide 427-17-2319 Dull PC8888 Secrets of Silicon Valley 472-27-2349 Gringlesby TC7777 Sushi, Anyone? 486-29-1786 Locksley PC9999 Net Etiquette 486-29-1786 Locksley PS7777 Emotional Security: A New Algorithm 648-92-1872 Blotchet-Halls TC4203 Fifty Years in Buckingham Palace Kitchens 672-71-3249 Yokomoto TC7777 Sushi, Anyone? 712-45-1867 del Castillo MC2222 Silicon Valley Gastronomic Treats 722-51-5454 DeFrance-Macy MC3021 The Gourmet Microwave 724-80-9391 MacFeather BU1111 Cooking with Computers: Surreptitious Balance Sheets 724-80-9391 MacFeather PS1372 Computer Phobic AND Non-Phobic Individuals: Behavior Variations 756-30-7391 Karsen PS1372 Computer Phobic AND Non-Phobic Individuals: Behavior Variations 807-91-6654 Panteley TC3218 Onions, Leeks, and Garlic: Cooking Secrets of the Mediterranean 846-92-7186 Hunter PC8888 Secrets of Silicon Valley NULL NULL MC3021 The Gourmet Microwave NULL NULL PS2091 Is Anger the Enemy? 998-72-3567 Ringer PS2091 Is Anger the Enemy? 998-72-3567 Ringer PS2106 Life Without Fear 111-22-3333 Ringer NULL NULL 341-22-1782 Smith NULL NULL 527-72-3246 Greene NULL NULL 724-08-9931 Stringer NULL NULL 893-72-1158 McBadden NULL NULL NULL NULL MC3026 The Psychology of Computer Cooking (31 rows affected) |
Although we haven't added or deleted any rows, instead of producing 30 rows total from the view, as was the case earlier, the view now produces 31 rows. This is because the outer join fabricates a row for the new au_id that has no match in the titles table. (It appears with NULL title fields.) Also notice that the two titles that matched the old au_id now have NULLs in their author fields. This might be comprehensible to someone who has a detailed understanding of the tables, but if the view is the only window that exists for updating the table, it will be extremely confusing.
If in future releases, referential actions are added that allow updates to cascade, you might reconsider whether to use updates against views based on joins; you'd still have the problem of affecting columns from more than one table without being able to know which is which. (Chapter 10 covers the implementation of referential actions via triggers.) Theoretically, it's possible to update many more views ”such as joins ”than SQL Server currently allows. But until these additional algorithms for updatability of views make their way into a future release, it's simply best to avoid the problem.
WITH CHECK OPTION
Earlier, we saw that modifying data with views based on one table is pretty straightforward ”but there's one "gotcha" to think about: disappearing rows. By default, a view can allow an UPDATE or an INSERT, even if the result is that the row no longer qualifies for the view. Consider the view on the following page that qualifies only stores in the state of Washington.
CREATE VIEW WA_stores AS SELECT * FROM stores WHERE state='WA' GO SELECT stor_id, stor_name, state FROM WA_stores |
Here's the result:
stor_id stor_name state ------- ------------------------------------ ----- 6380 Eric the Read Books WA 7131 Doc-U-Mat: Quality Laundry and Books WA (2 rows affected) |
The following UPDATE statement changes both qualifying rows so that they no longer qualify from the view and have seemingly disappeared.
UPDATE WA_stores SET state='CA' SELECT stor_id, stor_name, state FROM WA_stores |
And the result:
stor_id stor_name state ------- --------- ----- (0 rows affected) |
Modifications you make against a view without WITH CHECK OPTION can result in rows being added or modified in the base table, but the rows can't be selected from the view because they don't meet the view's criteria. The rows seem to disappear, as the example above illustrates.
If you allow data to be modified through a view that uses a WHERE clause, consider using WITH CHECK OPTION when defining the view. In fact, it would be better if WITH CHECK OPTION were the default behavior. But the behavior described above is in accordance with the ANSI and ISO SQL standards, and the expected result is that the disappearing row phenomenon can occur unless WITH CHECK OPTION is specified. Of course, any modifications you make through the view must also satisfy the constraints of the underlying table, or the statement will be aborted. This is true whether WITH CHECK OPTION is declared or not.
The following example shows how WITH CHECK OPTION protects against the disappearing rows phenomenon:
CREATE VIEW WA_stores AS SELECT * FROM stores WHERE state='WA' WITH CHECK OPTION GO UPDATE WA_stores SET state='CA' |
Here's the result:
Msg 550, Level 16, State 2 The attempted insert or update failed because the target view either specifies WITH CHECK OPTION or spans a view which specifies WITH CHECK OPTION and one or more rows resulting from the operation did not qualify under the CHECK OPTION constraint. Command has been aborted. SELECT stor_id, stor_name, state FROM WA_stores |
And the final result:
stor_id stor_name state ------- ------------------------------------ ----- 6380 Eric the Read Books WA 7131 Doc-U-Mat: Quality Laundry and Books WA (2 rows affected) |
Reenabling Integrity Constraints
To demonstrate a point in the preceding section, we disabled foreign key checks on the titleauthor table. When you're reenabling constraints, make sure that no rows violate the constraints. By default, when you add a new constraint, SQL Server automatically checks for violations, and the constraint won't be added until the data is cleaned up and such violations are eliminated. You can suppress this check by using the NOCHECK option. With this option, when you reenable an existing constraint that has just been disabled, SQL Server doesn't recheck the constraint's relationships.
After reenabling a disabled constraint, adding a new constraint with the NOCHECK option, or performing a bulk load operation without specifying the CHECK CONSTRAINTS option, you should check to see that constraints have been satisfied. Otherwise, the next time a row is updated, you might get an error suggesting that the constraint has been violated, even if the update at that time seems to have nothing to do with that specific constraint.
You can query for constraint violations using subqueries of the type discussed in Chapter 7. You must formulate a separate query to check for every constraint, which can be tedious if you have many constraints. It's sometimes easier to issue a dummy update, setting the columns equal to themselves , to be sure that all constraints are valid. If the table has many constraints and you think that none are likely to have been violated, doing the dummy update can be a convenient way to confirm, in one fell swoop, that all constraints are satisfied. If no errors result, you know that all constraints are satisfied.
Note that if FOREIGN KEY constraints exist, the dummy update actually resets the values. This update is performed as a delete/insert operation (which we'll see a bit later in this chapter). Although a dummy update can be a convenient way to test all constraints, it might be inappropriate for your environment because a lengthy operation could fill up the transaction log. If a violation occurs, you'll still need to do queries to pinpoint the violation. The dummy update doesn't isolate the offending rows ”it only tells you that a constraint was violated.
In an earlier example, we disabled the constraints on the titleauthor table and updated one row in such a way that the FOREIGN KEY constraint was violated. Here's an example in which we reenable the constraints on titleauthor and then do a dummy update, which reveals the constraint failure:
-- Reenable constraints. Note this does not check the validity -- of the constraints. ALTER TABLE titleauthor CHECK CONSTRAINT ALL GO -- Do a dummy update to check the constraints UPDATE titleauthor SET au_id=au_id, title_id=title_id Msg 547, Level 16, State 2 UPDATE statement conflicted with COLUMN FOREIGN KEY constraint 'FK__titleauth__au_id__1312E04B'. The conflict occurred in database 'pubs', table 'authors', column 'au_id' Command has been aborted. |
The constraint failure occurred because of the foreign key reference to the authors table. We know that it must be a case of an au_id value in the titleauthor table that has no match in authors, but we don't know which are the offending rows. Chapter 7 shows you a few approaches for finding such nonmatching rows. One of the most useful approaches is to use an outer join and then restrict the results to show only the rows that had to be fabricated for preservation on the outer-join side. These rows are the nonmatching rows ”exactly the ones we're interested in:
SELECT A.au_id, TA.au_id FROM authors AS A RIGHT OUTER JOIN titleauthor AS TA ON (A.au_id=TA.au_id) WHERE A.au_id IS NULL au_id au_id ----- ----- NULL 899-46-2035 NULL 899-46-2035 |
EAN: 2147483647
Pages: 144