Constraints
Constraints provide a powerful yet easy way for you to enforce relationships between tables ( referential integrity ) by declaring primary, foreign, and alternate keys. CHECK constraints enforce domain integrity. Domain integrity enforces valid entries for a given column by restricting the type (through datatypes), the format (through CHECK constraints and rules), or the range of possible values (through REFERENCES to foreign keys, CHECK constraints, and rules). The declaration of a column as either NULL or NOT NULL can be thought of as a type of constraint. And you can declare default values for use when a value isn't known at insert or update time.
PRIMARY KEY and UNIQUE Constraints
A central tenet of the relational model is that every tuple (row) in a relation (table) is in some way unique and can be distinguished in some way from every other row in the table. The combination of all columns in a table could be used as this unique identifier, but in practice, the identifier is usually at most the combination of a handful of columns , and often it's just one column: the primary key. Although some tables might have multiple unique identifiers, each table can have only one primary key. For example, perhaps the employee table maintains both an Emp_ID column and an SSN (Social Security number) column, both of which can be considered unique. Such column pairs are often referred to as alternate keys or candidate keys, although both terms are design terms and aren't used by the ANSI SQL standard or by SQL Server. In practice, one of the two columns is logically promoted to primary key with the PRIMARY KEY constraint, and the other will usually be declared by a UNIQUE constraint. Although neither the ANSI SQL standard nor SQL Server require it, it's good practice to always declare a PRIMARY KEY constraint on every table. Furthermore, you must designate a primary key for a table that will be published for transaction-based replication.
Internally, PRIMARY KEY and UNIQUE constraints are handled almost identically, so we'll discuss them together here. Declaring a PRIMARY KEY or UNIQUE constraint simply results in a unique index being created on the specified column or columns, and this index enforces the column's uniqueness, in the same way that a unique index created manually on a column would. The query optimizer makes decisions based on the presence of the unique index rather than on the fact that a column was declared as a primary key. How the index got there in the first place is irrelevant to the optimizer.
Nullability
All columns that are part of a primary key must be declared (either explicitly or implicitly) as NOT NULL. Columns that are part of a UNIQUE constraint can be declared to allow NULL. However, for the purposes of unique indexes, all NULLs are considered equal. So if the unique index is on a single column, only one NULL value can be stored (another good reason to try to avoid NULL whenever possible). If the unique index is on a composite key, one of the columns can have many NULLs, as long as the value in the other column is unique.
Index Attributes
The index attributes of CLUSTERED or NONCLUSTERED can be explicitly specified when declaring the constraint. If not specified, the index for a UNIQUE constraint will be nonclustered, and the index for a PRIMARY KEY constraint will be clustered (unless CLUSTERED has already been explicitly stated for a unique index, because only one clustered index can exist per table). The index FILLFACTOR attribute can be specified if a PRIMARY KEY or UNIQUE constraint is added to an existing table using the ALTER TABLE command. FILLFACTOR doesn't make sense in a CREATE TABLE statement because the table has no existing data, and FILLFACTOR on an index affects how full pages are only when the index is initially created. FILLFACTOR isn't maintained when data is added.
Choosing Keys
Try to keep the key lengths as compact as possible. Columns that are the primary key or that are unique are most likely to be joined and frequently queried. Compact key lengths allow more index entries to fit on a given 8-KB page, reducing I/O, increasing cache hits, and speeding character matching. When no naturally efficient compact key exists, it's often useful to manufacture a surrogate key using the Identity property on an int column. (If int doesn't provide enough range, a good second choice is a numeric column with the required precision and with scale 0.) You might use this surrogate as the primary key, use it for most join and retrieval operations, and declare a UNIQUE constraint on the natural but inefficient columns that provide the logical unique identifier in your data. (Or you might dispense with creating the UNIQUE constraint altogether if you don't need to have SQL Server enforce the uniqueness. Indexes slow performance of data modification statements because the index, as well as the data, must be maintained.)
Another reason for keeping your primary key short is relevant when the primary key has a clustered index on it (the default). Because clustered index keys are used as the locators for all nonclustered indexes, the clustered key will occur over and over again. A large key for your clustered index will mean your nonclustered indexes will end up large.
Although it's permissible to do so, don't create a PRIMARY KEY constraint on a column of type float or real . Because these are approximate datatypes, the uniqueness of such columns is also approximate, and the results can sometimes be unexpected.
Removing Constraints
You can't directly drop a unique index created as a result of a PRIMARY KEY or UNIQUE constraint by using the DROP INDEX statement. Instead, you must drop the constraint by using ALTER TABLE DROP CONSTRAINT (or you have to drop the table itself). This feature was designed so that a constraint can't be compromised accidentally by someone who doesn't realize that the index is being used to enforce the constraint. There is no way to temporarily disable a PRIMARY KEY or UNIQUE constraint. If disabling is required, use ALTER TABLE DROP CONSTRAINT, and then later restore the constraint by using ALTER TABLE ADD CONSTRAINT. If the index you use to enforce uniqueness is clustered, when you add the constraint to an existing table, the entire table and all nonclustered indexes are internally rebuilt to establish the cluster order. This can be a time-consuming task, and it requires about 1.2 times the existing table space as a temporary work area in the database would require (2.2 times in total, counting the permanent space needed) so that the operation can be rolled back if necessary.
Creating Constraints
Typically, you declare PRIMARY KEY and UNIQUE constraints when you create the table (CREATE TABLE). However, you can add or drop both by subsequently using the ALTER TABLE command. To simplify matters, you can declare a PRIMARY KEY or UNIQUE constraint that includes only a single column on the same line where you define that column in the CREATE TABLE statement. Such a constraint is known as a column-level constraint . Or you can declare the constraint after all columns have been defined; this constraint is known as a table-level constraint . Which approach you use is largely a matter of personal preference. We find the column-level syntax more readable and clear. You can use abbreviated syntax with a column-level constraint, in which case SQL Server will generate the name for the constraint, or you can use a slightly more verbose syntax that uses the clause CONSTRAINT name . A table-level constraint must always be named by its creator. If you'll be creating the same database structure across multiple servers, it's probably wise to explicitly name column-level constraints so that the same name will be used on all servers.
Following are examples of three different ways to declare a PRIMARY KEY constraint on a single column. All methods cause a unique, clustered index to be created. Note the (abridged) output of the sp_helpconstraint procedure for each ” especially the constraint name.
EXAMPLE 1
CREATE TABLE customer (cust_id int IDENTITY NOT NULL PRIMARY KEY, cust_name varchar(30) NOT NULL) GO EXEC sp_helpconstraint customer GO >>>> Object Name ----------- customer constraint_type constraint_name ----------------------- ------------------------------ PRIMARY KEY (clustered) PK__customer__68E79C55 |
EXAMPLE 2
CREATE TABLE customer (cust_id int IDENTITY NOT NULL CONSTRAINT cust_pk PRIMARY KEY, cust_name varchar(30) NOT NULL) GO EXEC sp_helpconstraint customer GO >>>> Object Name ----------- customer constraint_type constraint_name ----------------------- --------------- PRIMARY KEY (clustered) cust_pk No foreign keys reference this table. |
EXAMPLE 3
CREATE TABLE customer (cust_id int IDENTITY NOT NULL, cust_name varchar(30) NOT NULL, CONSTRAINT customer_PK PRIMARY KEY (cust_id)) GO EXEC sp_helpconstraint customer GO >>>> Object Name ----------- customer constraint_type constraint_name --------------- --------------- PRIMARY KEY (clustered) customer_PK No foreign keys reference this table. |
In Example 1, the constraint name bears the seemingly cryptic name of PK __ customer __ 68E79C55 . There is some method to this apparent madness ”all types of column-level constraints use this naming scheme (which we'll discuss later in this chapter). Whether you choose a more intuitive name of your own, such as customer_PK in Example 3, or the less intuitive (but information-packed), system-generated name produced with the abbreviated column-level syntax is up to you. However, when a constraint involves multiple columns, as is often the case for PRIMARY KEY, UNIQUE, and FOREIGN KEY constraints, the only way to syntactically declare them is with a table-level declaration. The syntax for creating constraints is quite broad and has many variations. A given column could have the Identity property, be part of a primary key, be a foreign key, and be declared NOT NULL. The order of these specifications isn't mandated and can be interchanged. Here's an example of creating a table-level, UNIQUE constraint on the combination of multiple columns. (The primary key case is essentially identical.)
CREATE TABLE customer_location (cust_id int NOT NULL, cust_location_number int NOT NULL, CONSTRAINT customer_location_unique UNIQUE (cust_id, cust_location_number)) GO EXEC sp_helpconstraint customer_location GO >>> Object Name ----------------- customer_location constraint_type constraint_name constraint_keys --------------- ------------------------ --------------- UNIQUE customer_location_unique cust_id, (non-clustered) cust_location_number No foreign keys reference this table. |
As noted earlier, a unique index is created to enforce either a PRIMARY KEY or a UNIQUE constraint. The name of the index is based on the constraint name, whether it was explicitly named or system generated. The index used to enforce the CUSTOMER_LOCATION_UNIQUE constraint in the above example is also named customer_location_unique . The index used to enforce the column-level, PRIMARY KEY constraint of the customer table in Example 1 is named PK __ customer __ 68E79C55 , which is the system-generated name of the constraint. You can use the sp_helpindex stored procedure to see information for all indexes of a given table. For example:
EXEC sp_helpindex customer >>> index_name index_description index_keys ------------------------------ ------------------ ---------- PK__customer__68E79C55 clustered, unique, cust_id primary key located on default |
You can't directly drop an index created to enforce a PRIMARY KEY or UNIQUE constraint. However, you can rebuild the index by using DBCC DBREINDEX, which is useful when you want to reestablish a given FILLFACTOR for the index or to reorganize the table, in the case of a clustered index.
FOREIGN KEY Constraints
As the term implies, logical relationships between tables is a fundamental concept of the relational model. In most databases, certain relationships must exist (that is, the data must have referential integrity), or the data will be logically corrupt.
SQL Server automatically enforces referential integrity through the use of FOREIGN KEY constraints. (This feature is sometimes referred to as declarative referential integrity, or DRI, to distinguish it from other features, such as triggers, that you can also use to enforce the existence of the relationships.)
A foreign key is one or more columns of a table whose values must be equal to a value in another column having a PRIMARY KEY or UNIQUE constraint in another table (or the same table when it references itself). After the foreign key is declared in a CREATE TABLE or ALTER TABLE statement, SQL Server restricts a row from being inserted or updated in a table that references another table if the relationship wouldn't be established. SQL Server also restricts the rows in the table being referenced from being deleted or changed in a way that would destroy the relationship.
Here's a simple way to declare a primary key/foreign key relationship:
CREATE TABLE customer (cust_id int NOT NULL IDENTITY PRIMARY KEY, cust_name varchar(50) NOT NULL) CREATE TABLE orders (order_id int NOT NULL IDENTITY PRIMARY KEY, cust_id int NOT NULL REFERENCES customer(cust_id)) |
The orders table contains the column cust_id , which references the primary key of the customer table. An order ( order_id ) must not exist unless it relates to an existing customer ( cust_id ) . You can't delete a row from the customer table if a row that references it currently exists in the orders table, and you can't modify the cust_id column in a way that would destroy the relationship.
The previous example shows the syntax for a column-level constraint, which you can declare only if the foreign key is a single column. This syntax uses the keyword REFERENCES, and the term "foreign key" is implied but not explicitly stated. The name of the FOREIGN KEY constraint is generated internally, following the same general form described earlier for PRIMARY KEY and UNIQUE constraints. Here's a portion of the output of sp_helpconstraint for both the customer and orders tables. (The tables were created in the pubs sample database.)
EXEC sp_helpconstraint customer >>> Object Name ------------ customer constraint_type constraint_name constraint_keys ---------------- ---------------------- --------------- PRIMARY KEY PK__customer__07F6335A cust_id (clustered) Table is referenced by ---------------------------------------------- pubs.dbo.orders: FK__orders__cust_id__0AD2A005 EXEC sp_helpconstraint orders >>> Object Name ----------- orders constraint_type constraint_name constraint_keys ----------------- ----------------------------- --------------- FOREIGN KEY FK__orders__cust_id__0AD2A005 cust_id REFERENCES pubs.dbo. customer(cust_id) PRIMARY KEY PK__orders__09DE7BCC order_id (clustered) No foreign keys reference this table. |
As with PRIMARY KEY and UNIQUE constraints, you can declare FOREIGN KEY constraints at the column and table levels. If the foreign key is a combination of multiple columns, you must declare FOREIGN KEY constraints at the table level. The following example shows a table-level, multiple-column FOREIGN KEY constraint:
CREATE TABLE customer (cust_id int NOT NULL, location_num smallint NULL, cust_name varchar(50) NOT NULL, CONSTRAINT CUSTOMER_UNQ UNIQUE CLUSTERED (location_num, cust_id)) CREATE TABLE orders (order_id int NOT NULL IDENTITY CONSTRAINT ORDER_PK PRIMARY KEY NONCLUSTERED, cust_num int NOT NULL, cust_loc smallint NULL, CONSTRAINT FK_ORDER_CUSTOMER FOREIGN KEY (cust_loc, cust_num) REFERENCES customer (location_num, cust_id)) GO EXEC sp_helpconstraint customer EXEC sp_helpconstraint orders GO >>> Object Name ----------- customer constraint_type constraint_name constraint_keys ------------------ ---------------- -------------------- UNIQUE (clustered) CUSTOMER_UNQ location_num, cust_id Table is referenced by --------------------------- pubs.dbo.orders: FK_ORDER_CUSTOMER Object Name ------------ orders constraint_type constraint_name constraint_keys ---------------- ---------------- ------------------ FOREIGN KEY FK_ORDER_CUSTOMER cust_loc, cust_num REFERENCES pubs.dbo.customer (location_num, cust_id) PRIMARY KEY ORDER_PK order_id (non-clustered) No foreign keys reference this table. |
The previous example also shows the following variations of how you can create constraints:
FOREIGN KEY constraints You can use a FOREIGN KEY constraint to reference a UNIQUE constraint (an alternate key) instead of a PRIMARY KEY constraint. (Note, however, that referencing a PRIMARY KEY is much more typical and is generally better practice.)
Matching column names and datatypes You don't have to use identical column names in tables involved in a foreign key reference, but it's often good practice. The cust_id and location_num column names are defined in the customer table. The orders table, which references the customer table, uses the names cust_num and cust_loc . Although the column names of related columns can differ , the datatypes of the related columns must be identical, except for nullability and variable-length attributes. (For example, a column of char(10) NOT NULL can reference one of varchar(10) NULL , but it can't reference a column of char(12) NOT NULL . A column of type smallint can't reference a column of type int .) Notice in the preceding example that cust_id and cust_num are both int NOT NULL and that location_num and cust_loc are both smallint NULL .
UNIQUE columns and NULL values You can declare a UNIQUE constraint on a column that allows NULL, but only one entirely NULL UNIQUE column is allowed when multiple columns make up the constraint. More precisely, the UNIQUE constraint would allow one entry for each combination of values that includes a NULL, as though NULL were a value in itself. For example, if the constraint contained two int columns, exactly one row of each of these combinations (and so on) would be allowed:
| NULL | NULL |
| NULL | |
| NULL | |
| 1 | NULL |
| NULL | 1 |
This case is questionable: NULL represents an unknown, yet using it this way clearly implies that NULL is equal to NULL. (As you'll recall, we recommend that you avoid using NULLs, especially in key columns.)
Index attributes You can specify the CLUSTERED and NONCLUSTERED index attributes for a PRIMARY KEY or UNIQUE constraint. (You can also specify FILLFACTOR when using ALTER TABLE to add a constraint.) The index keys will be created in the order in which you declare columns. In the preceding example, we specified location_num as the first column of the UNIQUE constraint, even though it follows cust_id in the table declaration, because we want the clustered index to be created with location_num as the lead column of the B-tree and, consequently, to keep the data clustered around the location values.
CONSTRAINT syntax You can explicitly name a column-level constraint by declaring it with the more verbose CONSTRAINT syntax on the same line or section as a column definition. You can see this syntax for the PRIMARY KEY constraint in the orders table. There's no difference in the semantics or run-time performance of a column-level or table-level constraint, and it doesn't matter to the system whether the constraint name is user specified or system generated. (A slight added efficiency occurs when you initially create a column-level constraint rather than a table-level constraint on only one column, but typically, only run-time performance matters.) However, the real advantage of explicitly naming your constraint rather than using the system-generated name is improved understandability. The constraint name is used in the error message for any constraint violation, so creating a name such as CUSTOMER_PK will probably make more sense to users than a name such as PK__customer__cust_i__0677FF3C . You should choose your own constraint names if such error messages are visible to your users.
Unlike a PRIMARY KEY or UNIQUE constraint, an index isn't automatically built for the column or columns declared as FOREIGN KEY. However, in many cases, you'll want to build indexes on these columns because they're often used for joining to other tables. To enforce foreign key relationships, SQL Server must add additional steps to the execution plan of every insert, delete, and update (if the update affects columns that are part of the relationship) that affects either the table referencing another table or the table being referenced itself. The execution plan, determined by the SQL Server optimizer, is simply the collection of steps that carries out the operation. (In Chapter 14, you'll see the actual execution plan by using the SET SHOWPLAN ON statement.)
If no FOREIGN KEY constraints exist, a statement specifying the update of a single row of the orders table might have an execution plan like the following:
- Find a qualifying order record using a clustered index.
- Update the order record.
When a FOREIGN KEY constraint exists on the orders table, the same operation would have additional steps in the execution plan:
- Check for the existence of a related record in the customer table (based on the updated order record) using a clustered index.
- If no related record is found, raise an exception and terminate the operation.
- Find a qualifying order record using a clustered index.
- Update the order record.
The execution plan is more complex if the orders table has many FOREIGN KEY constraints declared. Internally, a simple update or insert operation might no longer be possible. Any such operation requires checking many other tables for matching entries. Because a seemingly simple operation could require checking as many as 253 other tables (see the next paragraph) and possibly creating multiple worktables, the operation might be much more complicated than it looks and much slower than expected.
A table can have a maximum of 253 FOREIGN KEY references. This limit is derived from the internal limit of 256 tables in a single query. In practice, an operation on a table with 253 or fewer FOREIGN KEY constraints might still fail with an error because of the 256-table query limit if worktables are required for the operation.
A database designed for excellent performance doesn't reach anything close to this limit of 253 FOREIGN KEY references. For best performance results, use FOREIGN KEY constraints judiciously. Some sites use many FOREIGN KEY constraints because the constraints they declare are logically redundant. Take the case in the following example. The orders table declares a FOREIGN KEY constraint to both the master_customer and customer_location tables:
CREATE TABLE master_customer (cust_id int NOT NULL IDENTITY PRIMARY KEY, cust_name varchar(50) NOT NULL) CREATE TABLE customer_location (cust_id int NOT NULL, cust_loc smallint NOT NULL, CONSTRAINT PK_CUSTOMER_LOCATION PRIMARY KEY (cust_id,cust_loc), CONSTRAINT FK_CUSTOMER_LOCATION FOREIGN KEY (cust_id) REFERENCES master_customer (cust_id)) CREATE TABLE orders (order_id int NOT NULL IDENTITY PRIMARY KEY, cust_id int NOT NULL, cust_loc smallint NOT NULL, CONSTRAINT FK_ORDER_MASTER_CUST FOREIGN KEY (cust_id) REFERENCES master_customer (cust_id), CONSTRAINT FK_ORDER_CUST_LOC FOREIGN KEY (cust_id, cust_loc) REFERENCES customer_location (cust_id, cust_loc)) |
Although logically, the relationship between the orders and master_customer tables exists, the relationship is redundant to and subsumed by the fact that orders is related to customer_location , which has its own FOREIGN KEY constraint to master_customer . Declaring a foreign key for master_customer adds unnecessary overhead without adding any further integrity protection.
NOTE
In the case just described, perhaps declaring a foreign key adds readability to the table definition, but you can achieve this readability by simply adding comments to the CREATE TABLE command. It's perfectly legal to add a comment practically anywhere ”even in the middle of a CREATE TABLE statement. A more subtle way to achieve this readability is to declare the constraint so that it appears in sp_helpconstraint and in the system catalogs, but to then disable the constraint by using the ALTER TABLE NOCHECK option. Because the constraint would then be unenforced, an additional table wouldn't be added to the execution plan.
The CREATE TABLE statement that is shown in the following example for the orders table omits the redundant foreign key and, for illustrative purposes, includes a comment. Despite the lack of a FOREIGN KEY constraint in the master _ customer table, you still couldn't insert a cust_id that didn't existin the master_customer table, because the reference to the customer_location table would prevent it.
CREATE TABLE orders (order_id int NOT NULL IDENTITY PRIMARY KEY, cust_id int NOT NULL, cust_loc smallint NOT NULL, - Implied Foreign Key Reference of: - (cust_id) REFERENCES master_customer (cust_id) CONSTRAINT FK_ORDER_CUST_LOC FOREIGN KEY (cust_id, cust_loc) REFERENCES customer_location (cust_id, cust_loc)) |
Note that the table on which the foreign key is declared (the referencing table, which in this example is orders ) isn't the only table that requires additional execution steps. When being updated, the table being referenced (in this case customer_location ) also must have additional steps in its execution plan to ensure that an update of the columns being referenced won't break a relationship and create an orphan entry in the orders table. Without making any changes directly to the customer_location table, you can see a significant decrease in update or delete performance because of foreign key references added to other tables.
Practical Considerations for FOREIGN KEY Constraints
When using constraints, you should consider triggers, performance, and indexing. Let's take a look at the ramifications of each.
Constraints and triggers Triggers won't be discussed in detail until Chapter 10, but for now, you should simply note that constraints are enforced before a triggered action is performed. If the constraint is violated, the statement will abort before the trigger fires.
NOTE
The owner of a table isn't allowed to declare a foreign key reference to another table unless the owner of the other table has granted REFERENCES permission to the first table owner. Even if the owner of the first table is allowed to select from the table to be referenced, that owner must have REFERENCES permission. This prevents another user from changing the performance of operations on your table without your knowledge or consent . You can grant any user REFERENCES permission even if you don't also grant SELECT permission, and vice versa. The only exception is that the DBO, or any user who is a member of the db_owner role, has full default permissions on all objects in the database.
Performance considerations In deciding on the use of foreign key relationships, you must balance the protection provided with the corresponding performance overhead. Be careful not to add constraints that form logically redundant relationships. Excessive use of FOREIGN KEY constraints can severelydegrade the performance of seemingly simple operations.
Constraints and indexing The columns specified in FOREIGN KEY constraints are often strong candidates for index creation. You should build the index with the same key order used in the PRIMARY KEY or UNIQUE constraint of the table it references so that joins can be performed efficiently . Also be aware that a foreign key is often a subset of the table's primary key. In the customer_location table used in the preceding two examples, cust_id is part of the primary key as well as a foreign key in its own right. Given that cust_id is part of a primary key, it's already part of an index. In this example, cust_id is the lead column of the index, and building a separate index on it alone probably isn't warranted. However, if cust_id were not the lead column of the index B-tree, it might make sense to build an index on it.
Constraint Checking Solutions
Sometimes two tables reference one another, which creates a bootstrap problem. Suppose Table1 has a foreign key reference to Table2 , but Table2 has a foreign key reference to Table1 . Even before either table contains any data, you'll be prevented from inserting a row into Table1 because the reference to Table2 will fail. Similarly, you can't insert a row into Table2 because the reference to Table1 will fail.
ANSI SQL has a solution: deferred constraints, in which you can instruct the system to postpone constraint checking until the entire transaction is committed. Using this elegant remedy puts both INSERT statements into a single transaction that results in the two tables having correct references by the time COMMIT occurs. Unfortunately, no mainstream product currently provides the deferred option for constraints. The deferred option is part of the complete SQL-92 specification, which no product has yet fully implemented. It's not required for NIST certification as ANSI SQL-92 compliant, a certification that Microsoft SQL Server has achieved.
SQL Server 7 provides immediate constraint checking; it has no deferred option. SQL Server offers three options for dealing with constraint checking: it allows you to add constraints after adding data, it lets you temporarily disable checking of foreign key references, and it allows you to use the bcp (bulk copy) program or BULK INSERT command to initially load data and avoid checking FOREIGN KEY constraints. (You can override this default option with bcp or the BULK INSERT command and force FOREIGN KEY constraints to be validated .) To add constraints after adding data, don't create constraints via the CREATE TABLE command. After adding the initial data, you can add constraints by using the ALTER TABLE command.
With the second option, the table owner can temporarily disable checking of foreign key references by using the ALTER TABLE table NOCHECK CONSTRAINT statement. Once data exists, you can reestablish the FOREIGN KEY constraint by using ALTER TABLE table CHECK CONSTRAINT. Note that when an existing constraint is reenabled using this method, SQL Server doesn't automatically check to see that all rows still satisfy the constraint. To do this, you can simply issue a dummy update by setting a column to itself for all rows, determining whether any constraint violations are raised, and then fixing them. (For example, you could issue UPDATE ORDERS SET cust_id = cust_id .)
Finally you can use the bcp program or the BULK INSERT command to initially load data. The BULK INSERT command and the bcp program don't check any FOREIGN KEY constraints, by default. You can use the CHECK_CONSTRAINTS option to override this behavior. BULK INSERT and bcp are faster than regular INSERT commands because they usually bypass normal integrity checks and most logging.
When using ALTER TABLE to add (instead of reenable ) a new FOREIGN KEY constraint for a table in which data already exists, the existing data is checked by default. If constraint violations occur, the constraint won't be added. With large tables, such a check can be quite time-consuming. You do have an alternative ”you can add a FOREIGN KEY constraint and omit the check. To do this, specify the WITH NOCHECK option with ALTER TABLE. All subsequent operations will be checked, but existing data won't be checked. As in the case for reenabling a constraint, you could then perform a dummy update to flag any violations in the existing data. If you use this option, you should do the dummy update as soon as possible to ensure that all the data is clean. Otherwise, your users might see constraint error messages when they perform update operations on the preexisting data, even if they haven't changed any values.
Restrictions on Dropping Tables
If you're dropping tables, you must drop all the referencing tables, or drop the referencing FOREIGN KEY constraints before dropping the referenced table. For example, in the preceding example's orders , customer_location , and master_customer tables, the following sequence of DROP statements fails because a table being dropped is referenced by a table that still exists ”that is, customer_location can't be dropped because the orders table references it, and orders isn't dropped until later:
DROP TABLE customer_location DROP TABLE master_customer DROP TABLE orders |
Changing the sequence to the following works fine because orders is dropped first:
DROP TABLE orders DROP TABLE customer_location DROP TABLE master_customer |
When two tables reference each other, you must first drop the constraints or set them to NOCHECK (both operations use ALTER TABLE) before the tables can be dropped. Similarly, a table that's being referenced can't be part of a TRUNCATE TABLE command. You must drop or disable the constraint, or you must simply drop and rebuild the table.
Self-Referencing Tables
A table can be self-referencing ”that is, the foreign key can reference one or more columns in the same table. The following example shows an employee table, in which a column for manager references another employee entry:
CREATE TABLE employee (emp_id int NOT NULL PRIMARY KEY, emp_name varchar(30) NOT NULL, mgr_id int NOT NULL REFERENCES employee(emp_id)) |
The employee table is a perfectly reasonable table. It illustrates most of the issues we've discussed. However, in this case, a single INSERT command that satisfies the reference is legal. For example, if the CEO of the company has an emp_id of 1 and is also his own manager, the following INSERT will be allowed and can be a useful way to insert the first row in a self-referencing table:
INSERT employee VALUES (1,'Chris Smith',1) |
Although SQL Server doesn't currently provide a deferred option for constraints, self-referencing tables add a twist that sometimes makes SQL Server use deferred operations internally. Consider the case of a nonqualified DELETE statement that deletes many rows in the table. After all rows are ultimately deleted, you can assume that no constraint violation would occur. However, while some rows are deleted internally and others remain during the delete operation, violations would occur because some of the referencing rows would be orphaned before they were actually deleted. SQL Server handles such interim violations automatically and without any user intervention. As long as the self-referencing constraints are valid at the end of the data modification statement, no errors are raised during processing.
To gracefully handle these interim violations, however, additional processing and worktables are required to hold the work-in-progress. This adds substantial overhead and can also limit the actual number of foreign keys that can be used. An UPDATE statement can also cause an interim violation. For example, if all employee numbers are to be changed by multiplying each by 1000, the following UPDATE statement would require worktables to avoid the possibility of raising an error on an interim violation:
UPDATE employee SET emp_id=emp_id * 1000, mgr_id=mgr_id * 1000 |
The additional worktables and the processing needed to handle the worktables are made part of the execution plan. Therefore, if the optimizer sees that a data modification statement could cause an interim violation, the additional temporary worktables will be created, even if no such interim violations ever actually occur. These extra steps are needed only in the following situations:
- A table is self-referencing (it has a FOREIGN KEY constraint that refers back to itself).
- A single data modification statement (UPDATE, DELETE, or INSERT based on a SELECT) is performed and can affect more than one row. (The optimizer can't determine a priori , based on the WHERE clause and unique indexes, whether more than one row could be affected.) Multiple data modification statements within the transaction don't apply ”this condition must be a single statement that affects multiple rows.
- Both the referencing and referenced columns are affected (which is always the case for DELETE and INSERT operations, but might or might not be the case for UPDATE).
If a data modification statement in your application meets the above criteria, you can be sure that SQL Server is automatically using a limited and special-purpose form of deferred constraints to protect against interim violations.
Referential Actions
The full ANSI SQL-92 standard contains the notion of the referential action, sometimes (incompletely) referred to as a cascading delete. SQL Server 7 doesn't provide this feature as part of FOREIGN KEY constraints, but this notion warrants some discussion here because the capability exists via triggers.
The idea behind referential actions is this: sometimes, instead of just preventing an update of data that would violate a foreign key reference, you might be able to perform an additional, compensating action that would still enable the constraint to be honored. For example, if you were to delete a customer table, which had references to orders , it would be possible to have SQL Server automatically delete all those related order records (that is, cascade the delete to orders ), in which case the constraint wouldn't be violated and the customer table could be deleted. This feature is intended for both UPDATE and DELETE statements, and four possible actions are defined: NO ACTION, CASCADE, SET DEFAULT, and SET NULL.
- NO ACTION The delete is prevented. This default mode, per the ANSI standard, occurs if no other action is specified. SQL Server constraints provide this action (without the NO ACTION syntax). NO ACTION is often referred to as RESTRICT, but this usage is slightly incorrect in terms of how ANSI defines RESTRICT and NO ACTION. ANSI uses RESTRICT in DDL statements such as DROP TABLE, and it uses NO ACTION for FOREIGN KEY constraints. (The difference is subtle and unimportant. It's common to refer to the FOREIGN KEY constraint as having an action of RESTRICT.)
- CASCADE A delete of all matching rows in the referenced table occurs.
- SET DEFAULT The delete is performed, and all foreign key values in the referencing table are set to a default value.
- SET NULL The delete is performed, and all foreign key values in the referencing table are set to NULL.
Implementation of referential actions isn't required for NIST certification as ANSI SQL-92 conformant. SQL Server will provide referential actions in a future release. Until then, the program performs these actions via triggers, as discussed in Chapter 10. Creating triggers for such actions or for constraint enforcement is easy. Practically speaking, performance is usually equivalent to that of a FOREIGN KEY constraint, because both need to do the same type of operations to check the constraint.
NOTE
Because a constraint is checked before a trigger fires, you can't have both a constraint to enforce the relationship when a new key is inserted into the referencing table and a trigger that performs an operation such as a cascade delete from the referenced table. Triggers need to perform both the enforcement (an INSERT trigger on the referencing table) and the referential action (a DELETE trigger on the referenced table). If you do have both a constraint and a trigger, the constraint will fail and the statement will be aborted before the trigger to cascade the delete fires.You might still want to declare the foreign key relationship largely for readability so that the relationship between the tables is clear. Simply use the NOCHECK option of ALTER TABLE to ensure that the constraint won't be enforced, and then the trigger will fire. (The trigger must also take on the enforcement of the constraint.)
SQL Server users often request support for referential actions, and it will surely be implemented in a future version. However, using application logic for such actions and SQL Server constraints (without referential actions other than NO ACTION) to safeguard the relationship is more often applicable . Although referential actions are intuitive, how many applications could really avail themselves of this feature? How many real-world examples exist in which the application is so simplistic that you would go ahead and unconditionally delete (or set to the default or to NULL) all matching rows in a related table? Probably not many. Most applications would perform some additional processing, such as asking a user if she really intends to delete a customer who has open orders. The declarative nature of referential actions doesn't provide a way to hook in application logic to handle cases like these. Probably the most useful course, then, is to use SQL Server's constraints to restrict breaking relationships and have the application deal with updates that would produce constraint violations. This method will probably continue to be the most useful even after referential actions are added.
CHECK Constraints
Enforcing domain integrity (that is, ensuring that only entries of expected types, values, or ranges can exist for a given column) is also important. SQL Server provides two ways to enforce domain integrity: CHECK constraints and rules. CHECK constraints allow you to define an expression for a table that must not evaluate to FALSE for a data modification statement to succeed. (Note that we didn't say that the constraint must evaluate to TRUE. The constraint will allow the row if it evaluates to TRUE or to unknown. The constraint evaluates to unknown when NULL values are present, and this introduces three-value logic. The issues of NULLs and three-value logic are discussed in depth in Chapter 7.) Rules perform almost the same function as CHECK constraints, but they use different syntax and have fewer capabilities. Rules have existed in SQL Server since its initial release in 1989, well before CHECK constraints, which are part of the ANSI SQL-92 standard and were added in version 6 in 1995.
CHECK constraints make a table's definition more readable by including the domain checks in the DDL. Rules have a potential advantage in that they can be defined once and then bound to multiple columns and tables (using sp_bindrule each time), while you must respecify a CHECK constraint for each column and table. But the extra binding step can also be a hassle, so this capability for rules is beneficial only if a rule will be used in many places. Although performance between the two approaches is identical, CHECK constraints are generally preferred over rules because they're a direct part of the table's DDL, they're ANSI-standard SQL, they provide a few more capabilities than rules (such as the ability to reference other columns in the same row or to call a system function), and perhaps most importantly, they're more likely than rules to be further enhanced in future releases of SQL Server. For these reasons, we're going to concentrate on CHECK constraints.
CHECK constraints (and rules) add additional steps to the execution plan to ensure that the expression doesn't evaluate to FALSE (which would result in the operation being aborted). Although steps are added to the execution plan for data modifications, these are typically much less expensive than the extra steps discussed earlier for FOREIGN KEY constraints. For foreign key checking, another table must be searched, requiring additional I/O. CHECK constraints deal only with some logical expression for the specific row already being operated on, so no additional I/O is required. Because additional processing cycles are used to evaluate the expressions, the system requires more CPU use. But if there's plenty of CPU power to spare, the effect might well be negligible. (You can watch this by using Performance Monitor.)
Like other constraint types, you can declare CHECK constraints at the column or table level. For a constraint on one column, the run-time performance is the same for the two methods. You must declare a CHECK constraint that refers to more than one column as a table-level constraint. Only a single column-level CHECK constraint is allowed for a specific column, although the constraint can have multiple logical expressions that can be AND'ed or OR'ed together. And a specific column can have or be part of many table-level expressions.
Some CHECK constraint features have often been underutilized by SQL Server database designers, including the ability to reference other columns in the same row, use system and niladic functions (which are evaluated at runtime), and use AND/OR expressions. The following example shows a table with multiple CHECK constraints (as well as a PRIMARY KEY constraint and a FOREIGN KEY constraint) and showcases some of these features:
CREATE TABLE employee (emp_id int NOT NULL PRIMARY KEY CHECK (emp_id BETWEEN 0 AND 1000), emp_name varchar(30) NOT NULL CONSTRAINT no_nums CHECK (emp_name NOT LIKE '%[0-9]%'), mgr_id int NOT NULL REFERENCES employee(emp_id), entered_date datetime NULL CHECK (entered_date >= CURRENT_TIMESTAMP), entered_by int CHECK (entered_by IS NOT NULL), CONSTRAINT valid_entered_by CHECK (entered_by = SUSER_ID(NULL) AND entered_by <> emp_id), CONSTRAINT valid_mgr CHECK (mgr_id <> emp_id OR emp_id=1), CONSTRAINT end_of_month CHECK (DATEPART(DAY, GETDATE()) < 28)) GO EXEC sp_helpconstraint employee GO >>>> Object Name --------------- employee constraint_type constraint_name constraint_keys --------------- -------------------------------- ------------------ CHECK on column CK__employee__emp_id__2C3393D0 ([emp_id] >= 0 emp_id [emp_id] <= 1000) CHECK on column CK__employee__entered_by__300424B4 (((not([entered_by] entered_by is null)))) CHECK on column CK__employee__entered_date__2F10007B ([entered_date] >= entered_date getdate()) CHECK Table Level end_of_month (datepart(day, getdate()) < 28) FOREIGN KEY FK__employee__mgr_id__2E1BDC42 mgr_id CHECK on column no_nums ([emp_name] not emp_name like '%[0-9]%') PRIMARY KEY PK__employee__2B3F6F97 emp_id (clustered) CHECK Table Level valid_entered_by ([entered_by] = suser_id(null) and [entered_by] <> [emp_id]) CHECK Table Level valid_mgr ([mgr_id] <> [emp_id] or [emp_id] = 1) Table is referenced by -------------------------------- pubs.dbo.employee: FK__employee__mgr_id__2E1BDC42 |
This example illustrates the following points:
Constraint syntax CHECK constraints can be expressed at the column level with abbreviated syntax (leaving naming to SQL Server), such as the check on entered_date ; at the column level with an explicit name, such as the NO_NUMS constraint on emp_name ; or as a table-level constraint, such as the VALID_MGR constraint.
Regular expressions CHECK constraints can use regular expressions ”for example, NO_NUMS ensures that a digit can never be entered as a character in a person's name.
AND/OR Expressions can be AND'ed and OR'ed together to represent more complex situations ”for example, VALID_MGR. However, SQL Server won't check for logical correctness at the time a constraint is added to the table. Suppose you wanted to restrict the values in a department_id column to either negative numbers or values greater than 100. (Perhaps numbers between 0 and 100 are reserved.) You could add this column and constraint to the table using ALTER TABLE.
ALTER TABLE employee add department_no int CHECK(department_no < 100 AND department_no > 100) |
However, once the above command has been executed successfully and the new column and constraint have been added to the table, we'll never be able to put another row into the table. We accidentally typed AND in the ALTER TABLE statement instead of OR , but that isn't considered an illegal CHECK constraint. Each time we tried to insert a row, SQL Server tried to validate that the value in the department_no column was both less than 0 and more than 100! Any value for department_no that doesn't meet that requirement will cause the insert to fail. It could take a long time to come up with a value to satisfy this constraint. In this case, we'd have to drop the constraint and add a new one with the correct definition before we could insert any rows.
Constraint reference Table-level CHECK constraints can refer to more than one column in the same row. For example, VALID_MGR insists that no employee can be his own boss, except employee number 1, who is assumed to be the CEO. SQL Server currently has no provision that allows you to check a value from another row or from a different table.
NULL prevention You can make a CHECK constraint prevent NULL values ”for example, CHECK ( entered_by IS NOT NULL). Generally, you would simply declare the column NOT NULL.
Unknown expressions A NULL column might make the expression logically unknown. For example, a NULL value for entered_date gives CHECK entered_date >= CURRENT_TIMESTAMP an unknown value. This doesn't reject the row, however. The constraint rejects the row only when the expression is clearly false, even if it isn't necessarily true.
System functions System functions, such as GETDATE(), APP_NAME(), DATALENGTH(), and SUSER_ID(), as well as niladic functions, such as SYSTEM_USER, CURRENT_TIMESTAMP, and USER, can be used in CHECK constraints. This subtle feature is powerful and can be useful, for example, for assuring that a user can change only records that she has entered by comparing entered_by to the user's system ID, as generated by SUSER_ID() (or by comparing emp_name to SYSTEM_USER). Note that niladic functions such as CURRENT_TIMESTAMP are provided for ANSI SQL conformance and simply map to an underlying SQL Server function, in this case GETDATE(). So while the DDL to create the constraint on entered_date uses CURRENT_TIMESTAMP, sp_helpconstraint shows it as GETDATE(), which is the underlying function. Either expression is valid and equivalent in the CHECK constraint. The VALID_ENTERED_BY constraint ensures that the entered_by column can be set only to the currently connected user's ID, and it ensures that users can't update their own records.
System functions and column references A table-level constraint can call a system function without referencing a column in the table. In the example preceding this list, the END_OF_MONTH CHECK constraint calls two date functions, DATEPART() and GETDATE(), to ensure that updates can't be made after day 28 of the month (when the business's payroll is assumed to be processed ). The constraint never references a column in the table. Similarly, a CHECK constraint might call the APP_NAME() function to ensure that updates can be made only from an application of a certain name, instead of from an ad hoc tool such as the Query Analyzer.
As with FOREIGN KEY constraints, you can add or drop CHECK constraints by using ALTER TABLE. When adding a constraint, by default the existing data is checked for compliance; you can override this default by using the NOCHECK syntax. You can later do a dummy update to check for any violations. The table or database owner can also temporarily disable CHECK constraints by using WITH NOCHECK in the ALTER TABLE statement.
Default Constraints
A default allows you to specify a constant value, NULL, or the run-time value of a system function if no known value exists or if the column is missing in an INSERT statement. Although you could argue that a default isn't truly a constraint (because a default doesn't enforce anything), you can create defaults in a CREATE TABLE statement using the CONSTRAINT keyword; therefore, defaults will be referred to as constraints. Defaults add little overhead, and you can use them liberally without too much concern about performance degradation.
SQL Server provides two ways of creating defaults. Since the original SQL Server release in 1989, you can create a default (CREATE DEFAULT) and then bind the default to a column ( sp_bindefault ). Default constraints were introduced in 1995 with SQL Server 6.0 as part of the CREATE TABLE and ALTER TABLE statements, and they're based on the ANSI SQL standard (which includes such niceties as being able to use system functions). Using defaults is pretty intuitive. The type of default you use is a matter of preference; both perform the same function internally. Future enhancements are likely to be made to the ANSI-style implementation. Having the default within the table DDL seems a cleaner approach. We recommend that you use defaults within CREATE TABLE and ALTER TABLE rather than within CREATE DEFAULT, so we'll focus on that style here.
Here's the example from the previous CHECK constraint discussion, now modified to include several defaults:
CREATE TABLE employee (emp_id int NOT NULL PRIMARY KEY DEFAULT 1000 CHECK (emp_id BETWEEN 0 AND 1000), emp_name varchar(30) NULL DEFAULT NULL CONSTRAINT no_nums CHECK (emp_name NOT LIKE '%[0-9]%'), mgr_id int NOT NULL DEFAULT (1) REFERENCES employee(emp_id), entered_date datetime NOT NULL CHECK (entered_date >= CONVERT(char(10), CURRENT_TIMESTAMP, 102)) CONSTRAINT def_today DEFAULT (CONVERT(char(10), GETDATE(), 102)), entered_by int NOT NULL DEFAULT SUSER_ID() CHECK (entered_by IS NOT NULL), CONSTRAINT valid_entered_by CHECK (entered_by=SUSER_ID() AND entered_by <> emp_id), CONSTRAINT valid_mgr CHECK (mgr_id <> emp_id OR emp_id=1), CONSTRAINT end_of_month CHECK (DATEPART(DAY, GETDATE()) < 28)) GO EXEC sp_helpconstraint employee GO >>> Object Name --------------- employee constraint_type constraint_name constraint_keys --------------- -------------------------------- ------------------ CHECK on column CK__employee__emp_id__2C3393D0 ([emp_id] >= 0 emp_id [emp_id] <= 1000) CHECK on column CK__employee__entered_by__300424B4 (((not([entered_by] entered_by is null)))) DEFAULT on column def_today convert(char(10), entered_date getdate(),102)) DEFAULT on column DF__employee__emp_id__35BCFE0A (1000) emp_id DEFAULT on column DF__employee__emp_name__37A5467C (null) emp_name DEFAULT on column DF__employee__entered_by__3D5E1FD2 (suser_id()) entered_by DEFAULT on column DF__employee__mgr_id__398D8EEE (1) mgr_id CHECK on column CK__employee__entered_date__2F10007B ([entered_date] >= entered_date getdate()) CHECK Table Level end_of_month (datepart(day, getdate()) < 28) FOREIGN KEY FK__employee__mgr_id__2E1BDC42 mgr_id CHECK on column no_nums ([emp_name] not emp_name like '%[0-9]%') PRIMARY KEY PK__employee__2B3F6F97 emp_id (clustered) CHECK Table Level valid_entered_by ([entered_by] = suser_id(null) and [entered_by] <> [emp_id]) CHECK Table Level valid_mgr ([mgr_id] <> [emp_id] or [emp_id] = 1) Table is referenced by -------------------------------- pubs.dbo.employee: FK__employee__mgr_id__2E1BDC42 |
The preceding code demonstrates the following about defaults:
Column-level constraint A default constraint is always a column-level constraint because it pertains to only one column. You can use the abbreviated syntax that omits the keyword CONSTRAINT and the specified name, letting SQL Server generate the name, or you can specify the name by using the more verbose CONSTRAINT name DEFAULT syntax.
Clashes with CHECK constraint A default value can clash with a CHECK constraint. This problem appears only at runtime, not when you create the table or when you add the default via ALTER TABLE. For example, a column with a default of 0 and a CHECK constraint that states that the value must be greater than 0 would never be able to insert or update the default value.
PRIMARY KEY or UNIQUE constraint You can assign a default to a column having a PRIMARY KEY or a UNIQUE constraint. Such columns must have unique values, so only one row could exist with the default value in that column. The preceding example sets a DEFAULT on a primary key column for illustration, but in general, this practice is unwise.
Parentheses and quotation marks You can write a constant value within parentheses, as in DEFAULT (1), or without them, as in DEFAULT 1. A character or date constant must be enclosed in either single or double quotation marks.
NULL vs. default value A tricky concept is knowing when a NULL is inserted into a column vs. when a default value is entered. A column declared NOT NULL with a default defined uses the default only under one of the following conditions:
- The INSERT statement specifies its column list and omits the column with the default.
- The INSERT statement specifies the keyword DEFAULT in the values list (whether the column is explicitly specified as part of the column list or implicitly specified in the values list and the column list is omitted, meaning "All columns in the order in which they were created"). If the values list explicitly specifies NULL, an error is raised and the statement fails; the default value isn't used. If the INSERT statement omits the column entirely, the default is used and no error occurs. (This behavior is in accordance with ANSI SQL.) The keyword DEFAULT can be used in the values list, and this is the only way the default value will be used if a NOT NULL column is specified in the column list of an INSERT statement (either, as in the following example, by omitting the column list ”which means all columns ”or by explicitly including the NOT NULL column in the columns list).
-
INSERT EMPLOYEE VALUES (1, 'The Big Guy', 1, DEFAULT, DEFAULT)
Table 6-5 summarizes the behavior of INSERT statements based on whether a column is declared NULL or NOT NULL and whether it has a default specified. It shows the result for the column for three cases:
- Omitting the column entirely (no entry).
- Having the INSERT statement use NULL in the values list.
- Specifying the column and using DEFAULT in the values list.
Table 6-5. INSERT behavior with defaults.
| No Entry | Enter NULL | Enter DEFAULT | ||||
|---|---|---|---|---|---|---|
| No Default | Default | No Default | Default | No Default | Default | |
| NULL | NULL | default | NULL | NULL | NULL | default |
| NOT NULL | error | default | error | error | error | default |
NOTE
Although you can declare DEFAULT NULL on a column allowing NULL, SQL Server does this without declaring a default at all, even when using the DEFAULT keyword in an INSERT or UPDATE statement.
Declaring a default on a column that has the Identity property wouldn't make sense, and SQL Server will raise an error if you try it. The Identity property acts as a default for the column. But the DEFAULT keyword cannot be used as a placeholder for an identity column in the values list of an INSERT statement. You can use a special form of INSERT statement if a table has a default value for every column (an identity column does meet this criteria) or allows NULL. The following statement uses the DEFAULT VALUES clause instead of a column list and values list:
INSERT EMPLOYEE DEFAULT VALUES |
TIP
You can generate some test data by putting the Identity property on a primary key column and declaring default values for all other columns and then repeatedly issuing an INSERT statement of this form within a Transact -SQL loop.
More About Constraints
This section covers some tips and considerations that you should know about when working with constraints. We'll look at constraint names and system catalog entries, the status field, constraint failures, multiple-row data modifications, and integrity checks.
Constraint Names and System Catalog Entries
Earlier in this chapter, you learned about the cryptic-looking constraint names that SQL Server generates. Now we'll explain the naming. Consider again the following simple CREATE TABLE statement:
CREATE TABLE customer (cust_id int IDENTITY NOT NULL PRIMARY KEY, cust_name varchar(30) NOT NULL) |
The constraint produced from this simple statement bears the nonintuitive name PK__customer__59FA5E80 . All types of column-level constraints use this naming scheme. (Note that although the NULL/NOT NULL designation is often thought of as a constraint, it's not quite the same. Instead, this designation is treated as a column attribute and has no name or representation in the sysobjects system table.)
The first two characters (PK) show the constraint type ”PK for PRIMARY KEY, UN for UNIQUE, FK for FOREIGN KEY, and DF for DEFAULT. Next are two underscore characters (__) used as a separator. (You might be tempted to use one underscore as a separator, to conserve characters and to avoid having to truncate as much. However, it's common to use an underscore in a table name or a column name, both of which appear in the constraint name. Using two underscore characters distinguishes which kind of a name this is and where the separation occurs.)
Next comes the table name ( customer ), which is limited to 116 characters for a PRIMARY KEY constraint and slightly fewer characters for all other constraint names. For all constraints other than PRIMARY KEY, there are then two more underscore characters for separation followed by the next sequence of characters, which is the column name. The column name is truncated to five characters, if necessary. If the column name has fewer than five characters in it, the length of the table name portion can be slightly longer.
And finally, the hexadecimal representation of the object ID for the constraint ( 59FA5E80 ) comes after another separator. (This value is used as the id column of the sysobjects system table and the constid column of the sysconstraints system table.) Object names are limited to 128 characters in SQL Server 7, so the total length of all portions of the constraint name must also be less than or equal to 128.
Note the queries and output using this value that are shown in Figure 6-11.
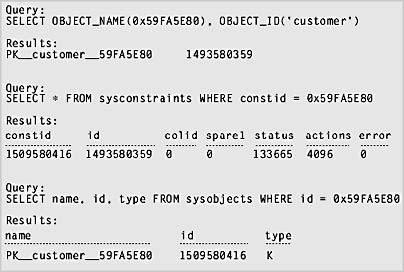
Figure 6-11. Querying the system tables using the hexadecimal ID value.
TIP
The hexadecimal value 0x59FA5E80 is equal to the decimal value 1509580416, which is the value of constid in sysconstraints and of id in sysobjects .
These sample queries of system tables show the following:
- A constraint is an object A constraint has an entry in the sysobjects table in the xtype column of C, D, F, PK, or UQ for CHECK, DEFAULT, FOREIGN KEY, PRIMARY KEY, and UNIQUE, respectively.
- Sysconstraints relates to sysobjects The sysconstraints table is really just a view of the sysobjects system table. The constid column in the view is the object ID of the constraint, and the id column of sysconstraints is the object ID of the base table on which the constraint is declared.
- Colid values If the constraint is a column-level CHECK, FOREIGN KEY, or DEFAULT, the colid has the colid of the column. This colid is related to the colid of syscolumns for the base table represented by id . A table-level constraint, or any PRIMARY KEY/UNIQUE constraint (even if column level), always has 0 in this column.
TIP
To see the names and order of the columns in a PRIMARY KEY or UNIQUE constraint, you can query the sysindexes and syscolumns tables for the index being used to enforce the constraint. The name of the constraint and that of the index enforcing the constraint are the same, whether the name was user specified or system generated. The columns in the index key are somewhat cryptically encoded in the keys1 and keys2 fields of sysindexes . The easiest way to decode these values is to simply use the sp_helpindex system stored procedure, or you can use the code of that procedure as a template if you need to decode them in your own procedure.
Decoding the status Field
The status field of the sysconstraints view is a pseudo_bit-mask field packed with information. If you know how to crack this column, you can essentially write your own sp_helpconstraint -like procedure. Note that the documentation is incomplete regarding the values of this column. One way to start decoding this column is to look at the definition of the sysconstraints view using the sp_helptext system procedure.
The lowest four bits, obtained by AND'ing status with 0xF ( status & 0xF ), contain the constraint type. A value of 1 is PRIMARY KEY, 2 is UNIQUE, 3 is FOREIGN KEY, 4 is CHECK, and 5 is Default. The fifth bit is on ( status & 0x10 <> 0 ) when the constraint was created at the column level. The sixth bit is on ( status & 0x20 <> 0 ) when the constraint was created at the table level.
Some of the higher bits are used for internal status purposes, such as noting whether a nonclustered index is being rebuilt and for other internal states. Table 6-6 shows some of the other bit-mask values you might be interested in:
Table 6-6. Bit-mask values.
| Bit-Mask Value | Description |
|---|---|
| 512 | The constraint creates a clustered index. |
| 1024 | The constraint creates a nonclustered index. |
| 16384 | The constraint has been disabled. |
| 32767 | The constraint has been enabled. |
| 131072 | SQL Server generates a name for the constraint. |
Using this information, and not worrying about the higher bits used for internal status, you could use the following query to show constraint information for the employee table:
SELECT OBJECT_NAME(constid) 'Constraint Name', constid 'Constraint ID', CASE (status & 0xF) WHEN 1 THEN 'Primary Key' WHEN 2 THEN 'Unique' WHEN 3 THEN 'Foreign Key' WHEN 4 THEN 'Check' WHEN 5 THEN 'Default' ELSE 'Undefined' END 'Constraint Type', CASE (status & 0x30) WHEN 0x10 THEN 'Column' WHEN 0x20 THEN 'Table' ELSE 'NA' END 'Level' FROM sysconstraints WHERE id=OBJECT_ID('employee') >>> Constraint Name Constraint Constraint Level ID Type -------------------------------------- ----------- ------------ ------ PK__employee__49C3F6B7 1237579447 Primary Key Table DF__employee__emp_id__4AB81AF0 1253579504 Default Column CK__employee__emp_id__4BAC3F29 1269579561 Check Column DF__employee__emp_name__4CA06362 1285579618 Default Column no_nums 1301579675 Check Column DF__employee__mgr_id__4E88ABD4 1317579732 Default Column FK__employee__mgr_id__4F7CD00D 1333579789 Foreign Key Column CK__employee__entered_date__5070F446 1349579846 Check Column def_today 1365579903 Default Column DF__employee__entered_by__52593CB8 1381579960 Default Column CK__employee__entered_by__534D60F1 1397580017 Check Column valid_entered_by 1413580074 Check Table valid_mgr 1429580131 Check Table end_of_month 1445580188 Check Table |
Constraint Failures in Transactions and Multiple-Row Data Modifications
Many bugs occur in application code because the developers don't understand how failure of a constraint affects a multiple-statement transaction declared by the user. The biggest misconception is that any error, such as a constraint failure, automatically aborts and rolls back the entire transaction. Rather, after an error is raised, it's up to the transaction to either proceed and ultimately commit, or to roll back. This feature provides the developer with the flexibility to decide how to handle errors. (The semantics are also in accordance with the ANSI SQL-92 standard for COMMIT behavior.)
Following is an example of a simple transaction that tries to insert three rows of data. The second row contains a duplicate key and violates the PRIMARY KEY constraint. Some developers believe that this example wouldn't insert any rows because of the error that occurred in one of the statements; they think that this error causes the entire transaction to be aborted. However, this isn't what happens ”instead, the statement inserts two rows and then commits that change. Although the second INSERT fails, the third INSERT is processed because no error checking occurred between the statements, and then the transaction does a COMMIT. Because no instructions were provided to take some other action after the error other than to proceed, proceed is exactly what SQL Server does. It adds the first and third INSERT statements to the table and ignores the second statement.
IF EXISTS (SELECT * FROM sysobjects WHERE name='show_error' AND type='U') DROP TABLE show_error GO CREATE TABLE show_error (col1 smallint NOT NULL PRIMARY KEY, col2 smallint NOT NULL) GO BEGIN TRANSACTION INSERT show_error VALUES (1, 1) INSERT show_error VALUES (1, 2) INSERT show_error VALUES (2, 2) COMMIT TRANSACTION GO SELECT * FROM show_error GO Server: Msg 2627, Level 14, State 1 [Microsoft][ODBC SQL Server Driver][SQL Server]Violation of PRIMARY KEY constraint 'PK__show_error__6754599E'. Cannot insert duplicate key in object 'show_error'. The statement has been aborted. col1 col2 ---- ---- 1 1 2 2 |
Here's a modified version of the transaction. This example does some simple error checking using the system function @@ERROR and rolls back the transaction if any statement results in an error. In this example, no rows are inserted because the transaction is rolled back:
IF EXISTS (SELECT * FROM sysobjects WHERE name='show_error' AND type='U') DROP TABLE show_error GO CREATE TABLE show_error (col1 smallint NOT NULL PRIMARY KEY, col2 smallint NOT NULL) GO BEGIN TRANSACTION INSERT show_error VALUES (1, 1) IF @@ERROR <> 0 GOTO TRAN_ABORT INSERT show_error VALUES (1, 2) if @@ERROR <> 0 GOTO TRAN_ABORT INSERT show_error VALUES (2, 2) if @@ERROR <> 0 GOTO TRAN_ABORT COMMIT TRANSACTION GOTO FINISH TRAN_ABORT: ROLLBACK TRANSACTION FINISH: GO SELECT * FROM show_error GO Server: Msg 2627, Level 14, State 1 [Microsoft][ODBC SQL Server Driver][SQL Server]Violation of PRIMARY KEY constraint 'PK__show_error__6B24EA82'. Cannot insert duplicate key in object 'show_error'. The statement has been aborted. col1 col2 ---- ---- |
Because many developers have handled transaction errors incorrectly, and because it can be tedious to add an error check after every command, SQL Server includes a SET statement that aborts a transaction if it encounters any error during the transaction. (Transact-SQL has no WHENEVER statement, although such a feature would be useful for situations like this.) Using SET XACT_ABORT ON causes the entire transaction to be aborted and rolled back if any error is encountered . The default setting is OFF, which is consistent with semantics prior to version 6.5 (when this SET option was introduced) as well as with ANSI-standard behavior. By setting the option XACT_ABORT ON, we can now rerun the example that does no error checking, and no rows will be inserted:
IF EXISTS (SELECT * FROM sysobjects WHERE name='show_error' AND type='U') DROP TABLE show_error GO CREATE TABLE show_error (col1 smallint NOT NULL PRIMARY KEY, col2 smallint NOT NULL) GO SET XACT_ABORT ON BEGIN TRANSACTION INSERT show_error VALUES (1, 1) INSERT show_error VALUES (1, 2) INSERT show_error VALUES (2, 2) COMMIT TRANSACTION GO SELECT * FROM show_error GO Server: Msg 2627, Level 14, State 1 [Microsoft][ODBC SQL Server Driver][SQL Server]Violation of PRIMARY KEY constraint 'PK__show_error__6D0D32F4'. Cannot insert duplicate key in object 'show_error'. col1 col2 ---- ---- |
A final comment about constraint errors and transactions: A single data modification statement (such as an UPDATE statement) that affects multiple rows is automatically an atomic operation, even if it's not part of an explicit transaction. If such an UPDATE statement finds 100 rows that meet the criteria of the WHERE clause but one row fails because of a constraint violation, no rows will be updated.
The Order of Integrity Checks
The modification of a given row will fail if any constraint is violated or if a trigger aborts the operation. As soon as a failure in a constraint occurs, the operation is aborted, subsequent checks for that row aren't performed, and no trigger fires for the row. Hence, the order of these checks can be important, as the following list shows.
- Defaults are applied as appropriate.
- NOT NULL violations are raised.
- CHECK constraints are evaluated.
- FOREIGN KEY checks of referencing tables are applied.
- FOREIGN KEY checks of referenced tables are applied.
- UNIQUE/PRIMARY KEY is checked for correctness.
- Triggers fire.
EAN: 2147483647
Pages: 144