Character Sets and Sort Orders
During installation, you must decide which character set and sort order to use. A SQL Server installation defines a single character set in addition to supporting Unicode (2-byte character) data. It also defines two sort orders, one for non-Unicode data and one for Unicode data. If you decide later that you want a different character set or sort order, you must rebuild all databases, including SQL Server's master database. Most of the discussion below concerns non-Unicode data. Unicode data is discussed later in a separate section.
Character Sets
A single (non-Unicode) character is stored in SQL Server as 1 byte (8 bits), which means that 256 (2 8 ) different characters can be represented. But all the world's languages in aggregate have many more than 256 characters. Hence, if you don't want to store all your data as Unicode, which takes twice as much storage space, you must choose a character set that contains all the characters (referred to as the repertoire ) you need to work with. For installations in the Western Hemisphere and Western Europe, the ISO character set (also often referred to as Windows Characters, ISO 8859-1, Latin-1, or ANSI) is the default and is compatible with the character set used by all versions of Windows in those regions . (Technically, there is a slight difference between the Windows character set and ISO 8859-1.) If you choose ISO, you might want to skip the rest of this section on character sets, but you should still familiarize yourself with sort order issues.
You should also ensure that all your client workstations use a character set that is consistent with the characters used by your installation of SQL Server. SQL Server stores a byte value for a character. If, for example, the character , the symbol for the Japanese yen, is entered by a client application using the standard Windows character set, its byte value (known as the code point ) of 165 (0xA5) is stored in SQL Server. If an MS-DOS_based application using code page 437 retrieves that value, that application displays the character ‘ . (MS-DOS uses the term code pages to mean character sets. You can think of them as interchangeable terms.) In both cases, the byte value of 165 is stored, but the Windows character set and the MS-DOS code page 437 render it differently. You must consider whether the ordering of characters is what is semantically expected (discussed later in the "Sort Orders" section) and whether the character is rendered on the application monitor (or other output device) as expected. SQL Server provides services in the OLE DB provider, the ODBC driver, and DB-Library that use Windows services to perform character set conversions. Conversions cannot always be exact, however, because by definition each character set has a somewhat different repertoire of characters. For example, there is no exact match in code page 437 for the Windows character • , so the conversion must give a close, but different, character.
The ASCII Character SetIt is worth pointing out that the first 128 characters are the same for the character sets ISO, code page 437, and code page 850. These 128 characters make up the ASCII character set. (Standard ASCII is only a 7-bit character set. ASCII was simple and efficient to use in telecommunications because the character and a "stop bit" for synchronization could all be expressed in a single byte.) If your application uses ASCII characters but not the so-called extended characters (typically characters with diacritical marks, such as , …,) that differentiate the upper 128 characters between these three character sets, it probably doesn't matter which character set you choose. In this situation (only), whether you choose any of these three character sets or use different character sets on your client and server machines doesn't matter because the rendering and sorting of every important character uses the same byte value in all cases.
Windows NT and SQL Server 7 also support 2-byte characters that allow representation of virtually every character used in any language. This is known as Unicode, and it provides many benefits with some costs. The principal cost is that 2 bytes instead of 1 are needed to store a character. SQL Server allows storage of Unicode data by using three new datatypes: nchar , nvarchar , and ntext . We'll discuss these when we talk about datatypes in Chapter 6. The use of Unicode characters for certain data does not affect the character set chosen to store the non-Unicode data.
Earlier versions of SQL Server did not support Unicode, but they did support double-byte character sets (DBCS). DBCS is a hybrid approach and is the most common way for applications to support Asian languages such as Japanese and Chinese. With DBCS encoding, some characters are 1 byte and others are 2 bytes. The first bit in the character indicates whether the character is a 1-byte or a 2-byte character. (In Unicode, every character is 2 bytes.) However, for non-Unicode datatypes, each character is considered 1 byte for storage. To store two DBCS characters, a field would need to be declared as char(4) instead of char(2) . But SQL Server correctly parses and understands DBCS characters in its string functions.
Table 4-4 lists the character sets available in SQL Server and notes DBCSs. The DBCSs are still available for backward compatibility, but for new applications that need more flexibility in character representation than the default ISO code page provides, you should consider using the Unicode datatypes exclusively. As mentioned earlier, most sites in countries of the Western Hemisphere and in Western Europe are best served by the default ISO character set. The choices for code page 437 and code page 850 might be of interest if you are supporting many older MS-DOS_based applications that use those code pages or for other backward compatibility reasons. The other character sets are mostly locale specific.
Table 4-4. SQL Server character sets.
| Code Page | Character Set |
|---|---|
| 1252 (ISO) | Default, multilingual |
| 850 | Multilingual |
| 437 | U.S. English |
| 874 | Thai (DBCS) |
| 932 | Japanese (DBCS) |
| 936 | Chinese simplified (DBCS) |
| 949 | Korean (DBCS) |
| 950 | Chinese traditional (DBCS) |
| 1250 | Central European |
| 1251 | Cyrillic |
| 1253 | Greek |
| 1254 | Turkish |
| 1255 | Hebrew |
| 1256 | Arabic |
| 1257 | Baltic |
Sort Orders
Character sets are not important in many sites, but in nearly every site, whether you realize it or not, the basics of sort order (more properly called collating sequence ) is important. Sort order determines how characters compare and assign their values. It determines whether your SQL Server installation is case sensitive. (For example, is an uppercase A considered identical to a lowercase a ?) If you use only ASCII characters and no extended characters, you should simply decide your case-sensitivity preference and choose accordingly . By default, SQL Server installs a case-insensitive sort order. (That is, A and a are considered equivalent.) To change the default, you simply choose an option during installation that provides case sensitivity, such as Binary Order or Dictionary Order, Case-Sensitive.
Sort order affects not only the ordering of a result set but also which rows of data qualify for that result set. If a query's criterion is
WHERE name='SMITH', |
the case sensitivity installed determines whether a row with the name Smith qualifies.
Character matching, string functions, and aggregate functions (MIN(), MAX(), COUNT (DISTINCT), GROUP BY, UNION, CUBE, LIKE, and ORDER BY) all behave differently with character data depending on the sort order specified.
Sort Order Semantics
The sort order also determines more subtle semantic differences. The following lengthy discussion principally applies to use of extended characters. If you plan to work with only 7-bit ASCII characters, you can skip this section.
A given sort order option is specific to a character set. Not every sorting option is available in every character set. For example, you will find the option for Croatian Dictionary Order, Case-Sensitive, only with the 1250, Central European character set. The DBCS character sets (Japanese, Chinese, and Korean) each provide two sort options. The first is Binary, which means that characters are sorted on the basis of their internal byte values, without regard to cultural correctness. The other choice makes use of Windows NT National Language Support (NLS) capabilities and provides a Case-Insensitive, Dictionary option consistent with the Windows NT character sorting in the respective localized version of the operating system. Hence, the English version of SQL Server can be used on the Chinese version of Windows NT, and it can work properly with double-byte Chinese characters and can sort them in a culturally correct manner.
For non-DBCS character sets, SQL Server provides more sorting options (which we'll explain in a moment). In addition, Unicode data has its own sort order, referred to as the Unicode collation sequence.Figure 4-3 shows the sort-order definition for the default sort order and character set. You can obtain similar information for whatever sort order you are using by running the procedure sp_helpsort . For example, the output shows that the letter A is defined for the current sort order definition file as having this collating sequence:
A=a = = = = = = = |
This definition states that A should be treated identically to a , as should all uppercase characters and their lowercase equivalents in this sort order. Both A and a have a value before and ( a -grave) followed by and ( a -acute) and then ‚ and ( a -circumflex). Next is ƒ and followed by and , … and , and finally and .
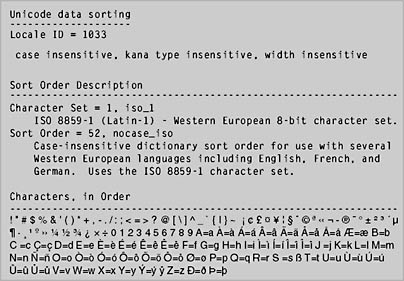
Figure 4-3. The definition for the default character set and sort order.
The default sort order is case insensitive, for both comparison and sorting purposes. You must use a variation of this sort order, which is called case insensitivity with preference , when you work with multilingual characters. In a sort order "with preference," even though A is defined as equal to a for the purposes of string comparison ( affecting character searches, including the constructs DISTINCT, UNION, LIKE, and so on), the preference option causes all collating (order by) to present the A before the a . In general terms, the semantics are "For the search process, treat A and a as identical, but show it to me with the A results preceding a ." You might prefer this behavior, for example, when you want to print a list of both uppercase and lowercase entries, without regard to case but with names in uppercase printing before those in lowercase rather than their being randomly intermixed.
You can actually think of characters as having primary, secondary, and tertiary sort values, which are different for different sort order choices. To be more precise, the above sort order defines all A -like values as having the same primary sort value. A and a not only have the same primary sort value, they also have the same secondary sort value because they are defined as equal. The character has the same primary value as A and a but is not declared equal to them, so has a different secondary value. And although A and a have the same primary and secondary sort values, with an uppercase preference sort order each has a different tertiary sort value, which allows it to compare identically but sort differently. If your sort order does not have uppercase preference, A and a have the same primary, secondary, and tertiary sort values.
A character's primary sort value is used to distinguish it from other characters, without regard to case and diacritical marks. It is essentially an optimization: if two characters do not have the same primary sort value, they cannot be considered identical for either comparison or sorting and there is no reason to look further. The secondary sort value distinguishes two characters that share the same primary value. If the characters share the same primary and secondary values (for example A = a ), they are treated as identical for comparisons. The tertiary value allows the characters to compare identically but sort differently. Hence, based on A = a , apple and Apple are considered equal. However, Apple sorts before apple when a sort order with uppercase preference is used. If there is no uppercase preference, whether Apple or apple sorts first is simply a random event based on the order in which the data is encountered when retrieved.
Some sort order choices allow for accent insensitivity. This means that extended characters with diacritics are defined with primary and secondary values equivalent to those without. If you want a search of name = 'Jose' to find both Jose and Jos , you should choose accent insensitivity. Such a sort order defines all E -like characters as equal and has the following in the sp_helpsort output:
E=e===== |
All the accent-insensitive sort orders provided by SQL Server also have uppercase preference enabled, which means that in an ORDER BY, the E -like characters above, although considered equivalent for character matching, sort as E , e , , ‰ , , , « , with each uppercase letter paired with its lowercase equivalent and distinguished from the other E -like characters. Technically, there is no reason that you can't have a sort order of Accent Insensitive Without Preference. But because the large number of existing sort orders are confusing to most people, not every conceivable variation is offered .
NOTE
When deciding on the case sensitivity for your SQL Server installation, you should be aware that the case sensitivity applies to object names as well as your user data because object names (the metadata) are stored in tables just like user data. So if you have a case-insensitive sort order, the table CustomerList is seen as identical to a table called CUSTOMERLIST and to one called customerlist . If your server is case sensitive and you have a table called CustomerList , SQL Server will not find the table if you refer to it as customerlist.
Binary Sorting
Each character set offers a binary sorting option. With binary sorting, you do not have to specify each character's sort position. Characters are sorted based on their internal byte representation. If you look at a chart for the character set, you see the characters ordered by this numeric value. In a binary sort, the characters sort according to their position by value, just as they are in the chart. Hence, by definition, a binary sort is always case sensitive and accent sensitive and every character has a unique byte value.
Binary sorting is the fastest sorting option because all that is required internally is a simple byte-by-byte comparison of the values. But if you use extended characters, binary sorting is not semantically desirable. Characters that are A -like, such as , , … , and , all sort after Z because the extended character A 's are in the top 128 characters and Z is a standard ASCII character in the lower 128. If you deal with only ASCII characters (or otherwise don't care about the sort order of extended characters), you want case sensitivity, and you don't care about "dictionary" sorting, binary sorting is an ideal choice. (In case- sensitive dictionary sorting, the letters ABCXYZabcxyz sort as AaBbCcXxYyZz . In binary sorting, all uppercase letters appear before any lowercase letters: for example, ABCXYZabcxyz .)
Performance Considerations
Binary sorting uses significantly fewer CPU instructions than sort orders with defined sort values. So binary sorting is ideal if it fulfills your semantic needs. However, you won't pay a noticeable penalty for using either a simple case-insensitive sort order (for example, Dictionary Order, Case-Insensitive) or a case-sensitive choice that offers better support than binary sorting for extended characters. Most large sorts in SQL Server tend to be I/O bound, not CPU bound, so the fact that there are fewer CPU instructions used by binary sorting doesn't typically translate to a significant performance difference. When you sort a small amount of data that is not I/O bound, even though binary sorting is faster, the difference is minimal; the sort will be fast in both cases.
A more significant performance difference results if you choose a sort order that is Case-Insensitive, Uppercase Preference. Recall that this choice considers all values as equal from the comparison standpoint, which also includes indexing. Characters retain a unique tertiary sort order, so they might be treated differently by an ORDER BY clause. Uppercase Preference can often require an additional sort operation in queries, more than with simple case insensitivity.
Consider a query that specifies WHERE LAST_NAME >= 'Jackson' ORDER BY LAST_NAME. If an index exists on the last_name field, the query optimizer will likely use it to find rows whose last_name value is greater than or equal to Jackson . If there is no need to use Uppercase Preference, the optimizer knows that because it is retrieving records based on the order of last_name , there is also no need to physically sort the rows because they were extracted in that order already. Jackson , jackson , and JACKSON are all qualifying rows. All are indexed and treated identically, and they simply appear in the results set in the order in which they were encountered. If Uppercase Preference is required for sorting, a subsequent sort of the qualifying rows is required to differentiate the rows, even though the index can still be used for selecting qualifying rows. If many qualifying rows are present, the performance difference between the two cases (one needs an additional sort operation) can be dramatic. This doesn't mean that you shouldn't choose Uppercase Preference. If you require those semantics, the performance aspect might well be a secondary concern. But you should be aware of the trade-off and decide which is most important to you. Determine whether your application can simply be made to input character data in all lowercase or uppercase consistently.
EAN: 2147483647
Pages: 144