The SQL Server Kernel and Interaction with the Operating System
The SQL Server kernel is responsible for interacting with the operating system. It's a bit of a simplification to suggest that SQL Server has one module for all operating system calls, but for ease of understanding, you can think of it in this way. All requests to operating system services are made via the Win32 API and C run-time libraries. When SQL Server runs under Windows NT, it runs entirely in the Win32 protected subsystem. Absolutely no calls are made in Windows NT Privileged Mode; they are made in User Mode. This means that SQL Server cannot crash the entire system, it cannot crash another process running in User Mode, and other such processes cannot crash SQL Server. SQL Server has no device driver_level calls, nor does it use any undocumented calls to Windows NT. If the entire system crashes (giving you the so-called "Blue Screen of Death") and SQL Server happens to have been running there, one thing is certain: SQL Server did not crash the system. Such a crash must be the result of faulty or incompatible hardware, a buggy device driver operating in Privileged Mode, or a critical bug in the Windows NT operating system code (which is doubtful).
NOTE
The Blue Screen of Death ” a blue "bug check" screen with some diagnostic information ” appears if a crash of Windows NT occurs. It looks similar to the screen that appears when Windows NT initially boots up.
A key design goal of both SQL Server and Windows NT is scalability. The same binary executable files that run on notebook computer systems run on symmetric multiprocessor super servers with loads of processors. SQL Server includes versions for Intel and RISC hardware architectures on the same CD. Windows NT is an ideal platform for a database server because it provides a fully protected, secure 32-bit environment. The foundations of a great database server platform are preemptive scheduling, virtual paged memory management, symmetric multiprocessing, and asynchronous I/O. Windows NT provides these, and SQL Server uses them fully. The SQL Server engine runs as a single process on Windows NT. Within that process are multiple threads of execution. Windows NT schedules each thread to the next processor available to run one.
Exploiting the Windows NT PlatformCompetitors have occasionally, and falsely, claimed that SQL Server must have special, secret hooks into the operating system. Such claims are likely the result of SQL Server's astonishing level of performance. Yes, it is tightly integrated with the Windows NT, Windows 95, and Windows 98 operating systems. But this integration is accomplished via completely public interfaces ” there are no secret "hooks" into the operating system. Yes, the product is optimized for Windows NT. That's SQL Server's primary platform. But other products could also achieve this level of optimization and integration if they made it a chief design goal. Instead, they tend to abstract away the differences between operating systems. Of course, there's nothing wrong with that. If Microsoft had to make SQL Server run on 44 different operating sys-tems, it might also take a lowest -common-denominator approach to engineering ” to do anything else would be almost impossible . So although such an approach is quite rational, it is in direct conflict with the goal of fully exploiting all services of a given operating system. Since SQL Server runs exclusively on Microsoft operating systems, it intentionally uses every service in the smartest way possible.
Threading and Symmetric Multiprocessing
SQL Server approaches multiprocessor scalability differently than most other symmetric multiprocessing (SMP) database systems. Two characteristics separate this approach from other implementations :
- Single-process architecture SQL Server maintains a single-process, multithreaded architecture that reduces system overhead and memory use. This is called the Symmetric Server Architecture.
- Native thread-level multiprocessing SQL Server supports multiprocessing at the thread level rather than at the process level, which allows for preemptive operation and dynamic load balancing across multiple CPUs. Using multiple threads is significantly more efficient than using multiple processes.
To understand how SQL Server works, it is useful to compare its strategies to strategies generally used by other products. On a nonthreaded operating system such as some UNIX variants, a typical SMP database server has multiple DBMS processes, each bound to a specific CPU. Some implementations even have one process per user, which results in a high memory cost. These processes communicate using Shared Memory, which maintains the cache, locks, task queues, and user context information. The DBMS must include complex logic that takes on the role of an operating system: it schedules user tasks , simulates threads, coordinates multiple processes, and so on. Because processes are bound to specific CPUs, dynamic load balancing can be difficult or impossible. For the sake of portability, products often take this approach even when they run on an operating system that offers native threading services, such as Windows NT.
SQL Server, on the other hand, uses a clean design of a single process and multiple operating system threads. The threads are scheduled onto a CPU by a User Mode Scheduler, as discussed in Chapter 2. Figure 3-7 shows the difference between SQL Server's threading architecture and that of other typical SMP database systems.
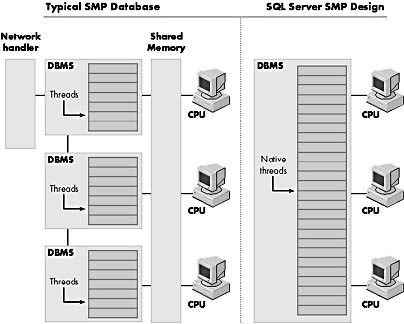
Figure 3-7. SQL Server's single-process, multiple-thread design.
SQL Server always uses multiple threads, even on a single-processor system. Threads are created and destroyed depending on system activity, so thread count is not constant. Typically, the number of active threads in SQL Server range from 16 to 100, depending on system activity and configuration. A pool of threads handles each of the networks that SQL Server simultaneously supports, another thread handles database checkpoints, another handles the lazywriter process, and another handles the log writer. A separate thread is also available for general database cleanup tasks, such as periodically shrinking a database that is in autoshrink mode. Finally, a pool of threads handles all user commands.
The Worker Thread Pool
Although SQL Server might seem to offer each user a separate operating system thread, the system is actually a bit more sophisticated than that. Because it is inefficient to use hundreds of separate operating system threads to support hundreds of users, SQL Server establishes a pool of worker threads.
When a client issues a command, the SQL Server network handler places the command in a "queue" and the next available thread from the worker thread pool takes the request. Technically, this queue is a Windows NT facility called an IOCompletion port. The SQL Server worker thread waits in the completion queue for incoming network requests to be posted to the IOCompletion port. If no idle worker thread is available to wait for the next incoming request, SQL Server dynamically creates a new thread until the maximum configured worker thread limit has been reached. The client's command must wait for a worker thread to be freed.
Even in a system with thousands of connected users, most are typically idle at any given time. As the workload decreases, SQL Server gradually eliminates idle threads to improve resource and memory use.
The worker thread pool design is efficient for handling thousands of active connections without the need for a transaction monitor. Most competing products, including those on the largest mainframe systems, need to use a transaction monitor to achieve the level of active users that SQL Server can handle without such an extra component. If you support a large number of connections, this is an important capability.
NOTE
In many cases, you should allow users to stay connected ” even if they will be idle for periods of, say, an hour ” rather than have them continually connect and disconnect. Repeatedly incurring the overhead of the logon process is more expensive than simply allowing the connection to remain live but idle.
Active vs. IdleIn the previous context, a user is considered idle from the database perspective. The human end user might be quite active, filling in the data entry screen, getting information from customers, and so forth. But those activities don't require any server interaction until a command is actually sent. So from the SQL Server engine perspective, the connection is idle.
When you think of an active user vs. an idle user, be sure to consider the user in the context of the back-end database server. In practically all types of applications that have many end users, at any given time the number of users who have an active request with the database is relatively small. A system with 1000 active connections might reasonably be configured with 150 or so worker threads. But this doesn't mean that all 150 worker threads are created at the start ” they're created only as needed, and 150 is only a high-water mark. In fact, fewer than 100 worker threads might be active at a time, even if end users all think they are actively using the system all the time.
A thread from the worker thread pool services each command to allow multiple processors to be fully utilized as long as multiple user commands are outstanding. In addition, with SQL Server 7, a single user command with no other activity on the system can benefit from multiple processors if the query is complex. SQL Server can break complex queries into component parts that can be executed in parallel on multiple CPUs. Note that this intraquery parallelism occurs only if there are processors to spare ” that is, if the number of processors is greater than the number of connections. In addition, intraquery parallelism is not considered if the query is not expensive to run, and the threshold for what constitutes "expensive" can be controlled with a configuration option called cost threshold for parallelism .
Under the normal pooling scheme, a worker thread runs each user request to completion. Because each thread has its own stack, stack switching is unnecessary. If a given thread performs an operation that causes a page fault, only that thread, and hence only that one client, is blocked. (A page fault occurs if the thread makes a request for memory and the virtual memory manager of the operating system must swap that page in from disk since it had been paged out. Such a request for memory must wait a long time relative to the normal memory access time because a physical I/O is thousands of times more expensive than reading real memory.)
Now consider something more serious than a page fault. Suppose that while a user request is being carried out, a bug is exposed in SQL Server that results in an illegal operation that causes an access violation (for example, the thread tries to read some memory outside the SQL Server address space). Windows NT immediately terminates the offending thread ” an important feature of a truly protected operating system. Because SQL Server makes use of structured exception handling in Windows NT, only the specific SQL Server user who made the request is affected. All other users of SQL Server or other applications on the system are unaffected and the system at large will not crash. Of course, such a bug should never occur and in reality is indeed rare. But this is software, and software is never perfect. Having this important reliability feature is like wearing a seat belt ” you hope you never need it, but you're glad it's there in case a crash occurs.
NOTE
Since Windows 95 and Windows 98 do not support SMP systems or thread pooling, the previous discussion is relevant only to SQL Server running on Windows NT. The following discussion of disk I/O is also only relevant to SQL Server on Windows NT.
Disk I/O on Windows NT
SQL Server 7 uses two Windows NT features to improve its disk I/O performance: scatter-gather I/O and asynchronous I/O. The descriptions below were adapted from SQL Server's Books Online:
Scatter-gather I/O As just mentioned, scatter-gather I/O was introduced in Windows NT 4, Service Pack 2. Previously, all the data for a disk read or write on Windows NT had to be in a contiguous area of memory. If a read transferred in 64 KB of data, the read request had to specify the address of a contiguous area of 64 KB of memory. Scatter-gather I/O allows a read or write to transfer data into or out of discontiguous areas of memory.
If SQL Server 7 reads in a 64 KB extent, it does not have to allocate a single 64 KB area and then copy the individual pages to buffer cache pages. It can locate eight buffer pages and then do a single scatter-gather I/O that specifies the address of the eight buffer pages. Windows NT places the eight pages directly into the buffer pages, eliminating the need for SQL Server to do a separate memory copy.
Asynchronous I/O In an asynchronous I/O, after an application requests a read or write operation, Windows NT immediately returns control to the application. The application can then perform additional work, and it can later test to see if the read or write has completed. By contrast, in a synchronous I/O, the operating system does not return control to the application until the read or write completes. SQL Server supports multiple concurrent asynchronous I/O operations against each file in a database. The maximum number of I/O operations for any file is controlled by the max async io configuration option. If max async io is left at its default of 32, a maximum of 32 asynchronous I/O operations can be outstanding for each file at any time.
EAN: 2147483647
Pages: 144