Designing a Database Logically to Leverage the Relational Engine
| | ||
| | ||
| | ||
After the conceptual model is approved and obtains the consent of users and customers, database modelers create a logical design. A logical design is a database model that evolves from the conceptual model, for it takes the previously captured requirements and creates a vision of the software solution. A logical database diagram is created to answer questions such as the fol-lowing: What datatypes should be used? How do you identify an entity? What rules should be enforced to validate the data?
Modeling terminology changes when it reaches the logical model. Table 5-1 may help you to distinguish the language used in each model.
| Conceptual Model | Logical Model |
|---|---|
| Entity | Table |
| Attribute | Column |
| Relationship | Foreign Key |
To create a logical model, complete the following steps:
-
Find the appropriate type for each column.
-
Find the primary key of each table.
-
Normalize the database.
-
Add additional validation rules.
| More Info | Normalization is the process in a relational database that both reduces redundancy and reduces the potential for anomalies, thus improving data integrity and consistency. |
Creating Columns to Capture Object Attributes
Each time you define a column to capture an object attribute, you must define a datatype. The datatype is an attribute of each column that specifies what kind of data the column will store. For example, you may want the Name column to store string ( alphanumeric ) values, the Price column to store monetary data, and the OrderDate column to store only date and time data.
SQL Server 2005 supports twenty-eight system datatypes and also allows programmers to create their own. The datatypes provided by the system are shown in Table 5-2.
| bigint | binary | bit | char | cursor |
| datetime | decimal | float | image | int |
| money | nchar | ntext | numeric | nvarchar |
| real | smalldatetime | smallint | smallmoney | sql_variant |
| table | text | timestamp | tinyint | varbinary |
| varchar | uniqueidentifier | xml |
Defining the appropriate datatype is critical in maintaining the integrity of the database. For example, if you use the char datatype to define the Price column, users may store names and addresses in this column, and no one will know the true value of the attribute. Good database designers invest a considerable amount of time analyzing what datatype should be applied to a column so as to create models that offer database integrity and good performance.
Declaring a Datatype Graphically
To define a datatype graphically, you may use your modeling tool or a T-SQL statement. To define a datatype using Microsoft Visio 2003, perform the following steps.
Defining a Datatype Using Microsoft Visio 2003
-
Select the table you want to model.
-
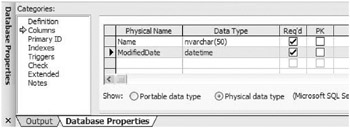
If the Database Properties window is not displayed, right-click the table and choose Database Properties from the shortcut menu.
-
Select Columns from the Categories list in the Database Properties window.
-
Make sure that the Physical DataType (Microsoft SQL Server) option is selected.
-
Select the column you want to model from the Column list.
-
Enter the datatype in the Data Type column, or select the datatype from the Combo box.
Using T-SQL Code to Define a Datatype
To define a datatype using T-SQL language, use the CREATE TABLE statement. This statement defines the table and its columns with the chosen datatypes. The simplified version of the CREATE TABLE statement is:
CREATE TABLE <NameofTable> (<ColumnName> <DataType> , <ColumnName> <DataType) , ...)
For example, the following statement creates a department table.
CREATE TABLE Departments(DepartmentName NVARCHAR(50) , DivisionName NVARCHAR(50) , ModifiedDate DATETIME)
Numeric Attributes
SQL Server 2005 offers wide support for numeric attributes, which include integer datatypes, precise decimal numbers, and approximate numbers . Each datatype category is useful in different situations.
Integers and quantities Integer columns store whole numeric data containing no decimal components , meaning that integer attributes do not support fractions. Integers include natural positive numbers (1, 2, 3), natural negative numbers (1,2,3), and 0. Integers are frequently used to model quantities. Examples of integer attributes include Age (in years ), Quantity in C05622078.fm Page 100 Monday, August 7, 2006 12:03 PM Stock, Shipped Quantity, Number of Employees , and Apartment Number. SQL Server 2005 provides five integer datatypes: bit, tinyint, smallint, int, and bigint. The difference between each datatype is the range of numbers they support and the storage space that each column of that datatype occupies. Table 5-3 provides specific information about integer datatype parameters that may help you make decisions about your choice of datatype.
| Datatype | Storage Space | Min Value to Max Value |
|---|---|---|
| bit | 1/8 of byte | 0 to 1 |
| tinyint | 1 byte | 0 to 255 |
| smallint | 2 bytes | 32,768 to 32,767 |
| int | 4 bytes | 2,147,483,648 to 2,147,483,647 |
| bigint | 8 bytes | 9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
Refer to the following guidelines to help you determine which integer datatype to use in different scenarios.
-
Use the bit datatype for True/False, Flag, or Status attributes. Examples include Sex (Male/Female), Reorder (True/False), Enable (True/False), and InProcess (0/1). Keep in mind that the bit datatype also permits the unknown value (NULL); therefore, it actually has three different statuses: 0, 1, and NULL.
-
Use the tinyint datatype for very small numbers. Examples include Number of Children, Line Number, Floor, and Age. The tinyint datatype stores only positive numbers (or zero) and does not allow negative numbers.
-
Use the smallint datatype for small numbers. Examples include Room Number, Years, and Seat Number.
-
Use the int datatype for almost every number you find in business applications. Examples include Quantity Ordered, Parts in Stock, Number of Shares, and Number of Passengers.
-
Use the bigint datatype only when very large numbers are required. These numbers are rarely required in business applications, but you may encounter them in scientific situations.
Precise numbers and accounting data Precise numbers in T-SQL language allow the storage of numbers with decimal parts. This means that a number may contain fractions as long as it is expressed as a division of a power of ten. Financial and accounting information, including prices and amounts, are expressed with this datatype.
SQL Server 2005 provides four precise datatypes: decimal, money, numeric, and smallmoney. The difference between each datatype is the range of numbers they support and the storage space that each column of that datatype occupies. Other important factors include the datatypes precision and scale.
Precision is the maximum number of digits you want a datatype to store. For example, the number 12,345.12 contains seven digits. Precision includes all of the digits before and after the decimal point. The scale of the datatype is the number of decimal digits; therefore, the scale of 12,345.12 is two.
Table 5-4 provides specific information about precision datatypes that may help you make decisions when choosing these datatypes.
| Datatype | Space | Precision | Scale | Min Value to Max Value |
|---|---|---|---|---|
| decimal | 5 bytes | 9 | 05 | 999,999,999 to 999,999,999 |
| numeric | 9 bytes | 19 | 09 | 10 19 +1 to 10 19 1 |
| dec | 13 bytes | 28 | 013 | 10 28 +1 to 10 28 1 |
| 17 bytes | 38 | 017 | 10 38 +1 to 10 38 1 | |
| money | 8 bytes | Approx. 18 | 4 | 922,337,203,685,477.5808 to 922,337,203,685,477.5807 |
| smallmoney | 4 bytes | Approx. 9 | 4 | 214,748.3648 to 214,748.3647 |
| Note | The dec datatype is not included as a system datatype, but can be used to define columns in a table. The dec datatype is part of the SQL-92 ANSI standard. |
The numeric and decimal datatypes are equivalent and can be used with different precisions and scales to accommodate most information. The smallmoney datatype can be used for prices, and the money datatype can be used for financial amounts.
Table 5-5 displays the minimum datatype required to store each number.
| Datatype | Example | Precision | Scale |
|---|---|---|---|
| decimal | 54,143.9481 | 9 | 4 |
| numeric | 98,145,875,298.12 | 13 | 2 |
| dec | 0.12679 | 5 | 5 |
| money | 103,785,675.9573 | Fixed | Fixed |
| smallmoney | 45,985.4503 | Fixed | Fixed |
Scientific and engineering data Scientific and engineering applications frequently use very large or very small numbers. For example, astronomy applications may store the mass and size of planets, stars, or galaxies. The mass of the sun is 1.9181 x 10 30 Kg, which is a unit called solar mass. The mass of the Milky Way galaxy is about one trillion solar masses. To store the mass of a galaxy using a precise decimal number would not be appropriate.
For these purposes, SQL Server 2005 offers approximate number datatypes. These datatypes do not store an exact number, but instead use approximate floating-point data. SQL Server 2005 provides three approximate datatypes: float, real, and double. The real and double datatypes are float datatypes with predefined mantissa bits. Table 5-6 provides specific information about approximate datatypes that may help you make decisions about your choice of datatype.
| Datatype | Storage Space | Mantissa Bits |
|---|---|---|
| float | 4 | 124 |
| 8 | 2553 | |
| real | 4 | 24 |
| double | 8 | 53 |
| Important | Do not use approximate number datatypes (float, real, double) to store financial information because aggregations will result in round-off errors. |
Because approximate number datatypes use natural logarithms to store values, the critical factor is the precision of the datatype. The real datatype uses twenty-four bits to store the mantissa, and the double datatype uses fifty-three bits, thereby controlling the precision and size of the datatype.
| Note | A mantissa is the positive fractional part of the representation of a logarithm. For example, in reference to the number 12345.12, the log value is 9.42101612226667 and the mantissa is .42101612226667. |
String Attributes
Users also need to store string attributes in the database. These attributes save information such as Name, Address, Title, and E-mail. These datatypes are composed of letters , numbers, and symbols. To store such attributes, SQL Server 2005 provides four different datatypes: char, nchar, varchar, and nvarchar. To better understand the terminology used in string types, refer to Table 5-7 below.
| Stringc Types | Character | Unicode |
|---|---|---|
| Fixed | char | nchar |
| Variable | varchar | nvarchar |
Variable datatypes use the var prefix, and unicode datatypes use the n prefix.
Unicode and character datatypes Unicode and character datatypes use different methods to store (encode) strings. Unicode datatypes (nchar, nvarchar) use the unicode standard to convert characters into bit sequences (encode). Character datatypes use sets of rules called collations to perform the same task.
Unicode datatypes are an industry standard designed to allow text and symbols from all languages to be consistently represented and manipulated by computers. Therefore, information stored in unicode datatypes can be consistently communicated between computers, thereby always resulting in the decoding of the original character. In contrast, character datatypes use collations to control the physical storage of character strings by using a specific code page. If the code page differs between computers, the incorrect character may be decoded.
The main advantage of character datatypes is efficiency. In general, character datatypes are more efficient than unicode datatypes because most collations use one byte per character, while their unicode counterpart uses two bytes per character. For example, a char(20) column will require twenty bytes, whereas the same column defined as nchar(20) will use forty bytes. Some collations use two bytes per character.
Fixed and variable-length datatypes Another option to consider when using string datatypes is whether to use fixed or variable-length datatypes. Fixed datatypes (char, nchar) use a permanent amount of space regardless of the value of the column or variable. For example, if you declare a column as type char(10) and it has the value of Test, it will employ ten bytes, even though Test has only four letters. This occurs because SQL Server 2005 will add six spaces after the word Test , thus always filling in the ten characters. The same column defined as nchar(10) will employ twenty bytes. This behavior is known as right padding .
In contrast, variable-length datatypes adjust their storage to accommodate the value of the column, but require two additional bytes to control the length of the value. Therefore, if you declare a column as type varchar(10) and a row has the value of Test, it will employ six bytes to store the value, two bytes for length control, and four bytes to store the actual value. The same column using nvarchar(10) will use ten bytes (two for length, eight for the actual value), and SQL Server 2005 will not add additional spaces.
String syntax To define string attributes in T-SQL, use the following syntax.
CREATE TABLE <NameofTable> (<ColumnName> CHAR(<Size>) , <ColumnName> VARCHAR(<MaxSize>) <ColumnName> NCHAR(<Size>) , <ColumnName> NVARCHAR(<MaxSize>) , ...)
For example, the following code will create a Department table to store the attributes Code, Name, and AlternateName.
CREATE TABLE Departments(DepartmentCode CHAR(6) , DepartmentName VARCHAR(50) , AlternateName NVARCHAR(50))
Character datatypes (char, varchar) support up to 8,000 characters per column, and unicode datatypes (nchar, nvarchar) can hold up to 4,000 characters.
Long text datatypes When the attribute you are capturing exceeds the maximum capacity of string datatypes, you may use the varchar(max) or nvarchar(max) datatype. Use these datatypes when the size of column values varies significantly and when the size might exceed 8,000 bytes. These datatypes support up to 2,147,483,647 characters (two gigabytes). The varchar(max) datatype uses collation to code characters, and nvarchar(max) uses unicode. Remember that unicode datatypes occupy two bytes per character; therefore, nvarchar(max) holds only 1,073,741,823 characters.
| Note | SQL Server 2005 also supports the text and ntext datatypes. Avoid using these datatypes because they are marked as obsolete, and future versions will remove them. |
Choosing the appropriate datatype Refer to the following guidelines to help you determine which datatype to use in each situation.
-
Appropriately size the column to collect the values of the attribute, but do not add additional unnecessary space. Using an adequate length will aid in data validation and provide better performance.
-
Use fixed-length datatypes (char, nchar) when the values of the attribute do not vary considerably in length. For example, to store a Social Security number, use a char datatype instead of varchar. This will result in better storage usage and performance.
-
Use variable-length datatypes (varchar, nvarchar) when the values of the attribute vary considerably in length. For example, to store an address attribute, use a varchar datatype instead of char. This will result in better storage usage and performance.
-
Use character datatypes when all users of the database utilize the same language or when you can set a general collation to represent all characters in their languages. Using character datatypes will result in more efficient databases.
-
Use unicode datatypes when users will store strings from different writing systems (e.g., Latin, Kanji, Arabic, Greek) and you cannot set a general collation to represent all characters in their languages. Unicode will support a wider range of characters and avoid those errors produced when using different code pages.
Date and Time Attributes
In business applications, the need to store date and time attributes occurs frequently. For example, you may want to store the date and time that an order is received or shipped, the date an employee is hired , or the date of someones birthday. SQL Server 2005 does not have separate datatypes for date and time attributes. It instead has two datatypes that combine date and time into a single attribute with different features (Size, Accuracy and Range). Table 5-8 provides specific information about datetime attributes that will help you better understand their characteristics.
| Type | Size | Accuracy | Min to Max Value |
|---|---|---|---|
| datetime | 8 bytes | 3.33 milliseconds | January 1, 1753, to December 31, 9999 |
| smalldatetime | 4 bytes | 1 minute | January 1, 1900, to June 6, 2079 |
| Best Practices | Do not use string datatypes (char, nchar, varchar, nvarchar) to store dates. Storing dates as strings makes data validation more difficult, exposes the application to internalization errors, and is frequently detrimental to performance. |
Binary Data
Some applications need to store images (such as JPG, GIF, and BMP files) or documents (such as Microsoft Excel workbooks or Microsoft Word documents). To support those needs, SQL Server 2005 supports binary datatypes. Binary datatypes are raw sequences of bytes that SQL Server 2005 does not try to encode or decode as it does with string datatypes. Binary information can be stored in three datatypes: binary(n), varbinary(n), and varbinary(max), as detailed below in Table 5-9.
| Datatype | Description | Max Width |
|---|---|---|
| binary(n) | Fixed-length binary data | 8000 bytes |
| varbinary(n) | Variable-length binary data | 8000 bytes |
| varbinary(max) | Long binary data | 2,147,483,647 bytes |
| Best Practices | SQL Server 2005 also supports the image datatype. Avoid using the image datatype because it is marked as obsolete, and future versions will remove it. |
The following is an example of how to declare binary datatypes in SQL server 2005.
CREATE TABLE Applicants(, ApplicantID INT , Name VARCHAR(25) , LastName VARCHAR(25) , Curriculum VARBINARY(MAX) , PictureVARBINARY(300000))
Complex Attributes
SQL Server 2005 also offers additional datatypes, which are listed below.
-
Rowversion A binary(8) datatype that is automatically updated when a row is inserted or updated. Because rowversion numbers are controlled per database, they are not sequential in the table; however, they are sequential per database. For example, if you define two tables, Orders and OrderDetails, and define a rowversion column in each table, the value 0 — 87D2 may be assigned to the Order table, and the value 0 — 87D3 may be assigned to the OrderDetail table. Rowversion columns are useful to control changes in rows.
-
Uniqueidentifier A datatype used to stored globally unique identifiers (GUIDs). A GUID is a numbering mechanism that guarantees that the same number will not be generated in any table, database, or networked server in the world. A uniqueidentifier is a sixteen-byte number, like the following: 50295F55-4666-4358-B6C6-B9B709755BAC . Uniqueidentifiers are not automatically updated, as are rowversion numbers. You must use the NEWID() function to generate the GUID. Uniqueidentifiers are useful to identify, copy, and control rows in distributed databases.
-
XML The xml datatype is one of the most interesting and complex datatypes offered by SQL Server 2005. This datatype is used to store XML documents and fragments as single values. For example, you may store documents that were generated by other applications or platforms, such as Purchase Orders or Shipment Confirmations. The xml datatype can also be used to store information that can be modeled in a relational manner, or it can be used when the schema of the information is unknown.
T-SQL user -defined datatypes If you want to create your own datatype to maintain consistency among tables that store the same attribute, you may use a T-SQL user-defined type (UDT). A UDT will help you create columns that contain the same datatype and length. For example, you may create a PhoneNumber attribute to ensure that all tables define phone numbers in the same manner. The following example creates a PhoneNumber attribute using T-SQL.
CREATE TYPE PhoneNumber FROM VARCHAR(14);
Common language runtime-based UDTs If you want to create your own datatypes without being limited by system datatypes, you may create your own common language runtime (CLR) UDTs using .NET languages such as Visual Basic.NET, C#.NET, and C++.NET. To create a CLR UDT, you must create a structure and use the Microsoft.SqlServer.Server.SqlUserDefinedTypeAttribute . After the structure is created, it must be compiled as an assembly and deployed in the database. Finally, the server must be enabled to execute CLR code.
Validating the Data
Determining how your database will implement integrity is an important part of the database designing process. To do so, you must identify which values are valid for each column in your database. After the values have been identified, you then create constraints that help keep bad data from entering your database. SQL Server 2005 provides the following constraints: NOT NULL, DEFAULT, PRIMARY KEY, UNIQUE, CHECK, and FOREIGN KEY.
NOT NULL Constraints
The NOT NULL constraint is equivalent to declaring an attribute as being required instead of optional. As a result, it will not allow rows that do not have a value in that column. For example, in the following table, the Number, Name, Social Security Number, and Hire Date columns are required and the Termination Date is optional.
CREATE TABLE Employee (EmployeeNumber INT NOT NULL , EmployeeName VARCHAR(50) NOT NULL , EmployeeSSN VARCHAR(15) NOT NULL , HireDate SMALLDATETIME NOT NULL , TerminationDate SMALLDATETIME NULL)
Try to design all columns with the NOT NULL constraint, and allow NULL values only in rare cases.
DEFAULT Constraints
Another useful constraint is DEFAULT , which allows you to declare a column value if one is not specified when the row is inserted. For example, if you have an E-mail column in the Employee table, recently hired employees may not have an e-mail account. If you do not want the column to support NULL values, you may create a DEFAULT constraint. The following code creates the table.
CREATE TABLE Employee (EmployeeNumberINTNOT NULL , EmployeeNameVARCHAR(50)NOT NULL , EmployeeSSNVARCHAR(15)NOT NULL , EmailAccountVARCHAR(50)NOT NULL DEFAULT('unknown@mycompany.com') , HireDateSMALLDATETIMENOT NULL , TerminationDateSMALLDATETIMENULL) PRIMARY KEY Constraints
Because a table is a set of rows, a row cannot be identified unless you define a primary key. The primary key is a column or combination of columns that identifies each row in the table. For example, the EmployeeNumber column identifies each row in the Employee table because it is a value that is both required (NOT NULL) and distinct in each row (employees do not share employee numbers). The following code creates the PRIMARY KEY constraint of the employee table.
CREATE TABLE Employee (EmployeeNumber INT NOT NULL PRIMARY KEY , EmployeeName VARCHAR(50) NOT NULL , EmployeeSSN VARCHAR(15) NOT NULL , EmailAccount VARCHAR(50) NOT NULL DEFAULT('unknown@mycompany.com') , HireDate SMALLDATETIME NOT NULL , TerminationDate SMALLDATETIME NULL) When the primary key involves multiple columns, the PRIMARY KEY constraint is defined at the table level with the following syntax.
CREATE TABLE StateProvince (CountryCode CHAR(3) NOT NULL , StateCode CHAR(3) NOT NULL , StateProvinceName VARCHAR(50) NOT NULL PRIMARY KEY (CountryCode, StateCode))
UNIQUE Constraints
When you want to enforce the stipulation that a value cannot be repeated in a table, you may define a UNIQUE constraint . For example, if you want the database to control that no employees use the same Social Security number, use a UNIQUE constraint. The following code will check that a Social Security number is used in only one row and that two rows do not have the same value.
CREATE TABLE Employee (EmployeeNumber INT NOT NULL PRIMARY KEY , EmployeeName VARCHAR(50) NOT NULL , EmployeeSSN VARCHAR(15) NOT NULL UNIQUE)
UNIQUE constraints may also limit a combination of multiple columns. For example, if you want to limit repeated products in a purchase order, the following UNIQUE constraint may help you.
CREATE TABLE OrderDetails (OrderId CHAR(6) NOT NULL , OrderLine INT NOT NULL , ProductNumber CHAR(10) NOT NULL , Quantity DECIMAL(10,2) NOT NULL , Price DECIMAL(10,2) NOT NULL , PRIMARY KEY(OrderId, OrderLine) , UNIQUE(OrderId, ProductNumber))
CHECK Constraints
Certain columns should be limited to a range of values, a pattern, or a certain condition. For example, the Sex column should be limited to Male or Female, the Amount column to positive values, and Social Security Numbers to a string pattern such as ###-##-####. To define such constraints, use CHECK expressions, such as those shown in the code below.
CREATE TABLE Employee (EmployeeNumberINT NOT NULL CHECK(EmployeeNumber>0) , EmployeeSSN VARCHAR(15) NOT NULL CHECK(EmployeeSSN LIKE '[0-9][0-9][0-9][0-9]-[0-9][0-9]- [0-9][0-9]-[0-9][0-9][0-9][0-9]') , HireDate SMALLDATETIME NOT NULL CHECK(HireDate>'19950101') , TerminationDateSMALLDATETIMENULL CHECK(TerminationDate IS NULL OR TerminationDate>HireDate))
FOREIGN KEY Constraints
The FOREIGN KEY constraint limits the values of a column to those that can be found in another table. For example, if you create a DepartmentCode column in the Employee table, you want the database to guarantee that this department exists in the Department table. The FOREIGN KEY constraint links the values of the column with the PRIMARY KEY or UNIQUE constraint in the referenced table, as shown in the following example.
CREATE TABLE StatesProvinces (CountryCode CHAR(3) NOT NULL FOREIGN KEY REFERENCES Countries(CountryCode) , StateCode CHAR(3) NOT NULL , StateProvinceName VARCHAR(50) NOT NULL , PRIMARY KEY (CountryCode, StateCode) , UNIQUE (CountryCode, StateProvinceName))
| | ||
| | ||
| | ||
EAN: N/A
Pages: 130