Section 17.5. Limits of Compression with Loss
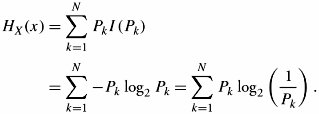
| Example. | A source with bandwidth 8 KHz is sampled at the Nyquist rate. If the result is modeled using any value from {-2,-1,0,1,2} and corresponding probabilities {0.05, 0.05, 0.08, 0.30, 0.52}, find the entropy. |
| Solution. | |
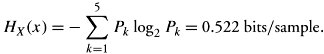
The information rate in samples/sec = 8,000 x 2 = 16,000, and the rate of information produced by the source = 16,000 x 0.522 = 8,352 bits.
Joint Entropy
The joint entropy of two discrete random variables X and Y is defined by
Equation 17.18
![]()
where P X,Y ( x , y ) = Prob[ X = x and the same time Y = y ] and is called the joint probability mass function of two random variables. In general, for a random process X n = ( X 1 ,..., X n ) with n random variables:
Equation 17.19
where P X1, ..., Xn ( x 1 , ...., x n ) is the joint probability mass function (J-PMF) of the random process X n . For more information on J-PMF, see Appendix C.
17.5.3. Shannon's Coding Theorem
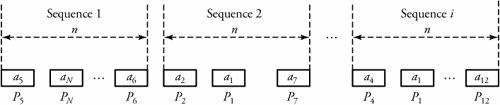
This theorem limits the rate of data compression. Consider again Figure 17.10, which shows a discrete source modeled by a random process that generates sequences of length n using values in set { a 1 , ..., a N } with probabilities { P 1 , ..., P N }, respectively. If n is large enough, the number of times a value a i is repeated in a given sequence = nP i , and the number of values in a typical sequence is therefore n(P 1 +... + P N ) .
We define the typical sequence as one in which any value a i is repeated nP i times. Accordingly, the probability that a i is repeated nP i times is obviously ![]() , resulting in a more general statement: The probability of a typical sequence is the probability [( a 1 is repeated np 1 )] x the probability [( a 2 is repeated np 2 ] x .... This can be shown by
, resulting in a more general statement: The probability of a typical sequence is the probability [( a 1 is repeated np 1 )] x the probability [( a 2 is repeated np 2 ] x .... This can be shown by ![]() , or
, or
Equation 17.20
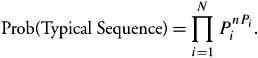
Knowing ![]() , we can obtain the probability of a typical sequence P t as follow:
, we can obtain the probability of a typical sequence P t as follow:
Equation 17.21
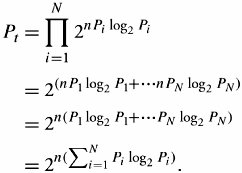
This last expression results in the well-known Shannon's theorem, which expresses the probability that a typical sequence of length n with entropy H X (x) is equal to
Equation 17.22
![]()
| Example. | Assume that a sequence size of 200 of an information source chooses values from the set { a 1 , ..., a 5 } with corresponding probabilities {0.05, 0.05, 0.08, 0.30, 0.52}. Find the probability of a typical sequence. |
| Solution. | In the previous example, we calculated the entropy to be H X (x) = 0.522 for the same situation. With n = 200, N = 5, the probability of a typical sequence is the probability of a sequence in which a 1 , a 2 , a 3 , a 4 , and a 5 are repeated, respectively, 200 x 0.05 = 10 times, 10 times, 16 times, 60 times, and 104 times. Thus, the probability of a typical sequence is P t = 2 -nH X (x) = 2 -200(0.52) . |
The fundamental Shannon's theorem leads to an important conclusion. As the probability of a typical sequence is 2 - nH X (x) and the sum of probabilities of all typical sequences is 1, the number of typical sequences is obtained by ![]() .
.
Knowing that the total number of all sequences, including typical and nontypical ones, is N n , it is sufficient, in all practical cases when n is large enough, to transmit only the set of typical sequences rather than the set of all sequences. This is the essence of data compression: The total number of bits required to represent 2 nH X(x) sequences is nH X (x) bits, and the average number of bits for each source = H X (x) .
| Example. | Following the previous example, in which the sequence size for an information source is 200, find the ratio of the number of typical sequences to the number of all types of sequences. |
| Solution. | We had n = 200 and N = 5; thus, the number of typical sequences is 2 nH (x) =2 200 x0.522, and the total number of all sequences is 5 200 . This ratio is almost zero, which may cause a significant loss of data if it is compressed, based on Shannon's theorem. It is worth mentioning that the number of bits required to represent 2 nH X (x) sequences is nH X (x) = 104 bits. |
17.5.4. Compression Ratio and Code Efficiency
Let ![]() be the average length of codes,
be the average length of codes, 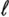 i be the length of code word i , and P i be the probability of code word i :
i be the length of code word i , and P i be the probability of code word i :
Equation 17.23
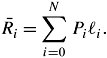
A compression ratio is defined as
Equation 17.24
![]()
where ![]() x is the length of a source output before coding. It can also be shown that
x is the length of a source output before coding. It can also be shown that
Equation 17.25
![]()
Code efficiency is a measure for understanding how close code lengths are to the corresponding decoded data and is defined by
Equation 17.26
![]()
When data is compressed, part of the data may need to be removed in the process.
EAN: 2147483647
Pages: 211