Cluster Administration
The primary administrative tasks on a cluster are:
- Adding a server
- Removing a server
- Restarting a server
- Changing the cluster controller
- Disbanding a cluster
Because of their scope and complexity, certain tasks that can be viewed as administrative—such as forcing cluster synchronization or modifying a member's load balancing configuration—are covered later in this chapter.
Adding a Server
When you want to add a server to a cluster, you can use the Add Cluster Member wizard; it uses a dialog that is similar to the New Cluster Wizard but with fewer steps. The wizard steps are used to identify the new member, provide credentials if required, analyze the server's configuration, and add the server to a cluster.
NOTE
Before you add a server to the cluster, you need to assess its hardware configuration. You should do this for two reasons: first, to verify that it meets the minimum configuration requirements to be a cluster member; and second, to determine whether its processing capabilities are adequate. Don't forget, there is the potential for any member to be pressed into service as a cluster controller. Use the existing controller's configuration as a guideline for evaluating this server.
Processing Activities and Their Sequence
As trivial as a welcoming page may seem—users do tend to ignore them and hit the Next button—let's start with this page because it presents important information.
NOTE
You can add a server to a cluster by invoking the wizard from either the server that you want to add, from the cluster controller, or remotely from a computer outside the cluster. In any case, you must supply the appropriate administrative credentials to connect to the server that you're not logged on to—either for the cluster controller or the potential new member.
Welcome to the Add Cluster Member Wizard
In addition to telling you what the wizard does, the opening page provides these set up warnings:
- Two network adapters are required for NLB.
- Web content may be overwritten when the server is added to the cluster.
Server Name and Credentials
With this page, you specify the server to add, either by browsing the network or by entering the server's name or IP address. You have to provide explicit credentials for an account that has administrative privileges to continue.
Controller
Virtually identical to the Server Name and Credentials page, this is where you provide the name of the cluster controller for the target cluster. Unless you're working on the controller, you will have to provide administrative credentials.
Analyzing Server Configuration
During this analysis phase, the wizard checks the configuration of the server you want to add as well as the target cluster controller. The following information is gathered:
- The number of network adapters installed on the server you want to add. A server with one network adapter can be added only if the target cluster is not using NLB.
- The IP address configuration(s) on the front-end network adapter are checked to see if:
- NLB is already bound to the adapter, which triggers an upgrade case.
- The adapter has a DHCP assigned IP, which causes the IP assignment to be set to static, and the cluster IP address is assigned.
- There is a single static IP, which becomes the dedicated IP and the cluster IP is bound as the second IP address for the adapter.
- Whether Application Center is installed on the server that you want to add. (This really applies only if you launch the program from a server other than the one you want to add.)
- The cluster membership is checked to determine whether the new server is already part of the cluster you want to join. If it is, an error message is displayed that indicates that the server you're working with is already a cluster member.
Load Balancing Options
If the cluster that you're joining already has NLB installed, the network adapter selection list appears dimmed. If not, you'll have to specify the network adapter that you want to use for load balancing. The load balancing cases described for the cluster creation process also apply in this case. The screen capture in Figure 4.4 illustrates the load balancing options that are available.
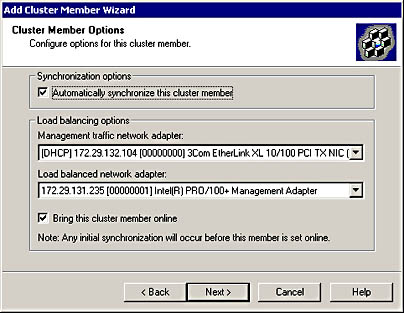
Figure 4.4 Available load balancing options when adding a cluster member
Two items should be noted on the Cluster Member Options page shown in Figure 4.4. They are the settings for Automatically synchronize this cluster member and Bring this cluster member online, which are enabled by default. There are cases where you will not want the member to be synchronized to the controller and/or brought online for load balancing immediately. This may be after a staged deployment or if you want to test new content by using live users.
Finish
During this phase, the wizard generates setup XML for the new member, updates the cluster membership list on the controller and new member, generates member and cluster configuration settings, and returns a success or failure notification. The final step is synchronization, in which cluster controller content and settings are replicated to the new member. The new member is brought online for load balancing by default, but you can defer this step until later if you prefer.
Figure 4.5 illustrates the network-level configurations that occur when a server is added to an NLB cluster.
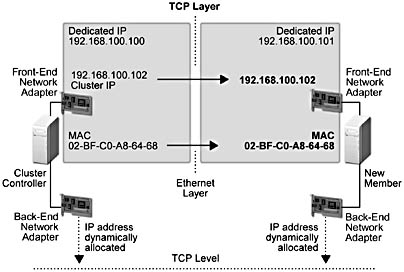
Figure 4.5 Network-level configurations as a result of adding a cluster member
Two items are of particular interest in the illustration shown in Figure 4.5. First, the static IP address on the controller's front-end network adapter, which is used for load balancing, is bound to the front-end network adapter on the new member. This cluster IP address is used for servicing all incoming TCP/UDP requests according to the NLB port-rule settings for a given port. Which is to say, HTTP for port 80. On a COM+ routing cluster, NLB uses this address to service incoming RPC activation requests. Second, if NLB is used for load balancing, the media access control address of the controller's front-end network adapter is assigned as the media access control address for the front-end network adapter on the new member. This is why, at the Ethernet level; all cluster members can "hear" inbound TCP/UDP level requests that are sent to the cluster IP address.
NLB and network adapter media access control addresses
In Unicast mode, NLB overwrites the network adapter's media access control address with its own virtual media access control address by using the registry. Some network adapter drivers do not allow their media access control address to be overwritten in the registry.The work-around is to use multicast mode, which adds a virtual media access control address to the existing network adapter's media access control address, or use a different network adapter that allows overwriting the media access control address in the registry. Because the Application Center user interface doesn't enable you to create a multicast cluster, you have to do this manually. The following steps are required:
- Manually configure NLB on the controller before creating a cluster.
- Choose Keep existing settings when running the cluster creation wizard.
When you add a member to the cluster, the multicast settings are replicated to the new member.
The IP addresses on the back end are dynamically allocated by DHCP and are used for transmitting cluster heartbeats as well as for content replication.
NOTE
DHCP-assigned addresses are not mandatory on the back-end adapter; you can choose to use static IP addresses on the back-end.
Application Center cluster heartbeats
The cluster controller sends an Internet Control Message Protocol (ICMP) ping to every member at 2-second intervals. The cluster controller makes a call to the name resolution service to determine the appropriate IP address to ping. If this fails or the service is turned off, the controller calls the Windows Socket API (Winsock) function GetHostByName() for each member to determine the IP address to ping. Each member has 1 second in which to respond to the ping. If a member doesn't respond to more than 2 consecutive pings, it is assumed to be "Dead" from a networking perspective. Its status will switch back to Alive if it starts responding again and does so for 3 consecutive pings. This heartbeat, transmitted over the back-end network adapters, doesn't do any health or performance checking on the application level; it simply verifies that a server can communicate at the TCP level.For more information about ICMP and/or GetHostByName(), see the Platform Software Development Kit.
Removing a Server
You can launch the Remove Cluster Member dialog box from the individual member's node in the MMC. If the member is still online, you'll be cued with a warning to that effect. In the case of a Web-based cluster, the online members are actively servicing HTTP requests, so they should be set offline before removing them from the cluster. You can, however, simply force a member's removal without any draining period.
WARNING
If you choose to remove a member without first setting it offline, there is a strong potential for terminating client connections in mid-session. Any work that these users are doing may be lost.
If you're initiating a member's removal from a different cluster member, you will have to connect to the target member by using an account that has administrative privileges on that member.
Processing Activities and Their Sequence
After the preliminary identification and validation is completed, a component is called that carries out the following tasks:
- Checks to see if the member to be removed is the local server. If it is, and the member is the cluster controller, the entire cluster is disbanded as part of the removal process.
NOTE
If there is more than one cluster member, Remove Cluster Member is unavailable for the cluster controller node in the member tree. - If you didn't set the member offline before initiating its removal, the component notifies the other cluster members that new requests should not be directed at the member that is being removed.
- Updates the cluster configuration store on the controller.
The final step in the removal process is the execution of a component that cleans up the member that was removed. This component:
- Unbinds NLB if it was configured on the member, regardless of whether or not it was an NLB upgrade case when it was added to the cluster.
- Removes the load balancing IP address from the front-end network adapter.
- Deletes cluster-related configuration settings.
- Stops the Cluster Service and Synchronization Service.
- Deletes the member's cluster-wide account.
- Sends out a completion notification via a WMI event.
TIP
If you do end up in a situation where a server becomes unstable or inoperable, you should remove it from the cluster and use the command-line tool CLUSTER /CLEAN against the server to clean up all the cluster configuration settings. After you have a clean server, you can re-install Application Center and add the server back into the cluster.
Restarting a Member
You can force a restart of any cluster member whose node has focus in the console tree by using Restart Cluster Member (All Tasks). This action forces a warm restart of the specified member.
Whenever various Application Center services have to be restarted because of a Service Control Manager net start or a member restart, the following sequence of events occurs:
- The Cluster Service uses the CDP to determine which member is the cluster controller.
- The Synchronization Service is started and initialized.
- The Cluster Service is reported as started.
If the member being restarted isn't the controller but the controller was found, the next set of activities are added to the restart sequence:
- The cluster configuration information for the member is synchronized from the controller to the member.
- The cluster membership list is checked to verify that the server is still part of the cluster. If it isn't, all the cluster-related settings are deleted, and the server is not brought into the cluster.
- Cluster configuration that may have changed, such as the load-balancing configuration, is checked.
- If the member is flagged for a full synchronization before coming online, a full synchronization is requested from the controller and the restart sequence is held until the synchronization finishes.
If NLB is configured on the cluster, an additional set of start-up actions is triggered. These actions are:
- The front-end network adapter is checked to verify that NLB is bound to the network adapter—this binding may not exist if the network adapter was replaced. If NLB isn't bound to the network adapter, an event is fired that generates the appropriate notification.
- The member starts listening for NLB events such as "NLB started" and "NLB converged" so that online/offline actions are taken directly from the wlbs command rather than the Application Center user interface.
At this point the restart sequence executes some final tasks before finishing the server restart:
- The Web Service (W3SVC) is started.
- Any monitors that are flagged for checking are checked before the member is set online.
- Load balancing is started.
- If a full synchronization wasn't required before adding the member to the load-balancing loop, a work item is queued that will request a full synchronization of the member.
Changing the Cluster Controller
Changing the designated controller for a cluster is a fairly simple process from the user's perspective—it consists of selecting a member node in the console tree (assuming that the user is connected to the controller) and launching the Designate as Controller command. Alternatively, if the cluster controller is down, you can connect directly to the member that you want to designate as the controller and invoke the preceding command.
TIP
Prior to promoting a member to controller status, you should do a full synchronization of the member to the current controller.
Processing Activities and Their Sequence
There are two situations that can exist when you decide to explicitly change the designated cluster controller:
- The controller is up and running.
- The controller is not available or is in an unstable condition.
The Controller Is Up and Running
In this scenario you've decided to promote a member to controller status even though the current controller is up and running. (Reasons for making this change may be to add more memory or replace one of the network adapters.)
You should not change the controller if one of the following operations is in progress:
- Synchronization.
- A cluster administrative activity, such as setting a server offline/online.
WARNING
If you launch the Designate as Controller command while one of the previously described operations is in progress, the controller change will fail.
If the preceding conditions do not exist, the following sequence of events occurs involving the current controller (S1) and the member that will become the controller (S2).
In the first step, the administration program verifies that S2 can be contacted. If not, the operation is stopped. The next step involves a call to S1 to see if the cluster is in a controller-less state. If it is, the processing described in the following section, "The Controller Is Not Available," occurs.
If the current controller (S1) can be contacted and appears to be functioning normally, S1:
- Notifies the user that he or she should perform a full synchronization on S2.
- Disallows all new requests for administrative changes and turns off automatic synchronization. If any of these activities are currently in progress, they are allowed to finish.
- Notifies cluster members that a controller change is about to occur. This gives the members a chance to stop any operations that reference S1, such as request forwarding. The members also cancel currently executing requests and set a flag indicating that the cluster controller is changing. When this notification is received, each member starts a local timer.
If S1 fails before completing the preceding step, an error is returned to the administration program and no timers are started. If an S1 failure occurs after notifying some of the members, these members will have started their timers. As soon as these members are notified of the S1 failure, they expire their timers and wait to be notified of a controller recovery or controller change.
Assuming there isn't a failure, S1:
- Fires a "Controller is changing" event.
- Makes a synchronous COM call to S2, telling it to take over as controller. If S2 fails during the time-out associated with this call, an error is returned to the administrator and the administrator may retry the command.
If control is successfully transferred to the new controller, S2:
- Re-enables changes that require synchronization to the rest of the cluster.
- Informs all members that it has taken over as the new controller and that they can re-enable operations that reference the controller. In response, the members stop their timers and set their local pointers to reference S2 as the controller.
- Sets its own pointer in the local cluster members list to point to itself and fires a "new controller is S2" event.
If S2 fails between responding to the COM call from S1 and the firing of the new controller event, the members expire their timers and revert to regarding S1 as the controller. If S2 fails after telling only a subset of the members that it's taking over as the controller, the timer expires on the members that haven't been told about the controller change—they switch back to regarding S1 as the controller. Members on which the timer expires fire an event/alert that tells the administrator what has happened.
If controller transfer is successful to this point, the call from S1 to S2 returns and S1 changes its local pointer to reference S2 as the cluster controller. When the S1 cluster reference change is saved, the controller change is finished. (If S2 fails before this reference is changed, the administrator is notified and the controller change has to be redone.)
There are additional special cases that can happen during the course of a controller change:
- S1 fails at any time before S1 changes its local pointer to reference S2. The cluster will enter the controller-less state and administrative action may be needed to recover from this state.
- A server other than S1 or S2 fails. No special processing is required; the new controller is picked up automatically when the failed member recovers.
The Controller Is Not Available
When the controller (S) is not available and the cluster is in a controller-less state, in your role of administrator you have to designate another cluster member as the controller.
- The user interface calls a method on S that checks the configuration on the member that you want to promote to confirm that the cluster is, in fact, in a controller-less state. If it isn't, an error is generated indicating that there is currently a cluster controller. At this point you can decide whether or not you still want to promote a member to controller status.
- If the cluster is controller-less, S sets the local pointers on all the cluster members to point to S as the controller.
- S fires a "new controller is S" event and controller re-assignment is finished.
Disbanding a Cluster
In order to disband a cluster, you have to remove each cluster member, leaving the cluster controller as the last member to remove. As noted earlier, the option to remove the cluster controller is not available unless it's the only cluster member.
Although this approach may seem tedious when faced with the task of disbanding a large cluster, it's actually an excellent feature from a production perspective. If a cluster, regardless of its size, could be disabled with a single command, the potential for wreaking havoc in a production cluster is frightening. (For a script example that illustrates how you can remove a group of members from a cluster by using a single batch file, see Chapter 11, "Working with the Command-Line Tool and Scripts.")
When you initiate the removal of the cluster controller from the cluster, the following activities occur:
- The user interface goes through the same steps that were described in "Removing a Server" earlier in this chapter.
- All cluster-related configuration settings are deleted on the controller.
- An event notification of the success or failure of the cluster disbanding is sent.
- The MMC is refreshed to show the current state of the Application Center environment; there is no cluster node and no member node.
EAN: N/A
Pages: 183