Lesson 2: Introduction to SQL Server Replication
This lesson describes the publisher-subscriber metaphor, which is the SQL Server model for defining the source and destination of replicated data and the sets of data that will be replicated. It also discusses different types of data filtering.
Before you continue with the lesson, run the Rep.htm video demonstration located in the Media folder on the Supplemental Course Materials CD-ROM that accompanies this book. This demonstration provides an overview of the SQL Server replication process.
After this lesson, you will be able to
- Explain the publisher-subscriber metaphor, including articles, publications, and subscriptions
- Explain the process of filtering data for replication
Estimated lesson time: 30 minutes
The Publisher-Subscriber Metaphor
Replication uses a publisher-subscriber metaphor for distributing data. In a replication environment, a Publisher sends data and a Subscriber receives data.
A single SQL Server can act as a Publisher, a Distributor, a Subscriber, or any combination of the three for one or more databases at the same time. Figure 15.3 illustrates the Publisher-Distributor-Subscriber relationship.
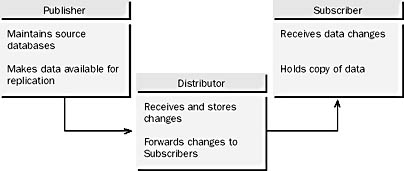
Figure 15.3 The Publisher-Distributor-Subscriber relationship
Publisher
A Publisher is a SQL Server that maintains a source database, makes published data from that database available for replication, and sends changes to the published data to the Distributor.
Subscriber
A Subscriber is a SQL Server that holds a copy of the replicated data and receives updates to this data. It is possible to allow the data on a Subscriber to be changed, and a Subscriber can, in turn, be a Publisher to other Subscribers.
Distributor
The Distributor receives a copy of all changes to the published data, stores the changes, and then makes them available to the appropriate Subscribers. A special system database called the distribution database and a folder called the distribution working folder are created on the Distributor for storing this data and replication configuration information. By default, the distribution folder is C:\Mssql7 \Repldata, but this can be changed and other folders can be created. Storing the replicated data in this way makes it possible to forward data to Subscribers at short or long intervals and allows for Subscribers that are not always connected. The Distributor can send changes to Subscribers, or Subscribers can fetch changes from the Distributor.
Although the Publisher and the Distributor can be on the same computer, it is more typical in larger or more active sites to locate the Distributor on its own server. If the Distributor is located on another computer, a complete, separately licensed SQL Server installation is required on that computer. It is also possible for one distribution server to support multiple publication servers.
NOTE
The most important concept in replication is that every replicated data element has only one Publisher. None of the SQL Server replication options uses a so-called "multiple master" model. This does not mean that data can be modified only on a single server. You will learn how to allow subscribed data to be changed, and even published, but in doing so no data element will have more than one Publisher.
Publications and Articles
In keeping with the publisher-subscriber metaphor, the terms publication and article are used to refer to data that is published.
Publications
A publication is a collection of articles. The following facts apply to a publication:
- A publication is the basis of a subscription. A subscription to a publication includes all articles in the publication, and Subscribers subscribe to publications, not to articles. A publication will typically include all of the data necessary to support a particular application or operation, so that a Subscriber will not have to subscribe to many publications in order to support the application or operation.
- One or more publications can be created in a database.
- A publication cannot span databases. All of the data in a publication must come from the same database.
Articles
An article is the basic unit of replication and represents a single data element that is replicated. Subscribers subscribe to publications, not articles. An article can be
- An entire table. When using snapshot replication, the table schema, including triggers, as well as the data can be replicated.
- Certain columns from a table, by using a vertical filter.
- Certain rows from a table, by using a horizontal filter.
- Certain rows and columns from a table, by using a vertical and a horizontal filter.
- A stored procedure definition. When using snapshot replication, the entire stored procedure is replicated.
- The execution of a stored procedure. When using transactional replication, a record of the execution of a stored procedure, rather than the data changes that resulted from the execution of the stored procedure can be replicated. This can dramatically reduce the amount of data that must be sent to the Subscriber(s).
IMPORTANT
In previous versions of SQL Server, you could subscribe to an article as well as to a publication. For backward compatibility, SQL Server 7 supports subscriptions to articles, but you cannot create them in Enterprise Manager, and it is recommended that you replace them with subscriptions to publications.
Filtering Data
It is possible to publish a subset of a table as an article. This is known as filtering data. Filtering data helps to avoid replication conflicts when multiple sites are allowed to update data. You can filter tables vertically, horizontally, or both vertically and horizontally. Each instance of a filtered table is a separate article. Figure 15.4 shows examples of vertical and horizontal filtering.
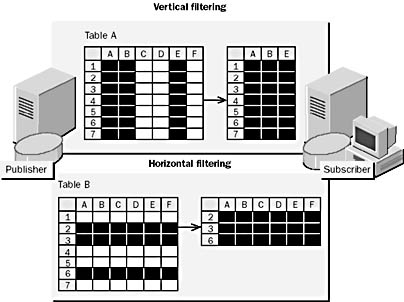
Figure 15.4 Vertical and horizontal filtering
Vertical Filtering
As shown in the upper half of Figure 15.4, a vertical filter contains a subset of the columns in a table. The Subscriber receives only the replicated columns. For example, you might use a vertical filter to publish all but the Salary column from the Employee table. Vertical filtering is similar to specifying only certain columns from a table in a SELECT statement.
Merge replication (described in Lesson 3) does not support vertical filtering.
Horizontal Filtering
As shown in the lower half of Figure 15.4, a horizontal filter contains a subset of the rows in a table. The Subscriber receives only the subset of rows. For example, you can publish order records by region to each region. Horizontal filtering is similar to specifying a WHERE clause in a SELECT statement.
Additional Ways to Create Data Subsets
An alternative to filtering is to create separate tables. This can be more efficient than filtering, preventing conflicts and simplifying the logical view of the data. For example, instead of storing the sales data from multiple branches in a single table at a head office, you could create a separate table for each branch. The disadvantages to creating separate tables are that applications must deal with the separate tables and that administration can be more complex because, if the table structure changes, tables on different servers may have to be altered.
Creating separate tables that use the same schema but contain different rows is usually called partitioning. Creating separate tables containing different columns is less common.
Partitioning Rows
Partitioning rows (horizontal partitioning) involves physically defining a horizontal subset of data as a separate table. For example, you can partition a customer table into separate tables for each region.
Partitioning Columns
Partitioning columns (vertical partitioning) involves physically defining a vertical subset of data as a separate table. For example, you can vertically partition an employee table by placing the name, title, and office number columns in one table and other confidential information, such as birth date and salary information, in another table.
Subscriptions
The configuration that defines how a database on a Subscriber will receive a publication from a Publisher is referred to as a subscription.
Two kinds of subscriptions are possible. The type of subscription determines how subscriptions are created and administered and how data is replicated. There can be many subscriptions of both types to a single publication, as shown in Figure 15.5.
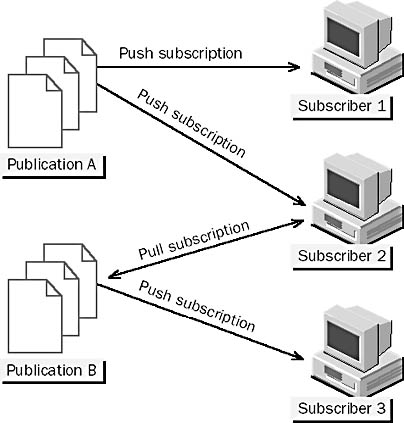
Figure 15.5 Push vs. pull subscriptions
NOTE
In previous versions of SQL Server, the subscription types affected only how subscriptions were administered.
Push Subscriptions
You can set up subscriptions while creating or administering publications on the Publisher. This is known as a push subscription. Push subscriptions centralize subscription administration in the following ways:
- A push subscription is defined at the Publisher.
- Many Subscribers can be set up at once for each publication.
With a push subscription, the Distributor propagates the changes to a Subscriber without a request from the Subscriber to do so. Typically, push subscriptions are used in applications that must send changes to Subscribers as soon as they occur. Push subscriptions are best for applications that require higher security and near-real-time updates, and where the higher processor overhead at the Distributor does not affect performance.
For push subscriptions, the replication agents that replicate data to the Subscriber run at the Distributor or the Publisher.
Pull Subscriptions
You can also set up a subscription while administering a Subscriber. This is known as a pull subscription. The following are distinguishing characteristics of a pull subscription:
- The Subscriber initiates a pull subscription.
- The publication must be enabled to allow pull subscriptions.
- Only SQL Server Subscribers fully support pull subscriptions.
- The system administrator or database owner of the Subscriber decides which publications are received and when to receive them.
Pull subscriptions are best for applications that need lower security, need more Subscriber autonomy (such as mobile users), and need to support a high number of Subscribers (such as Subscribers that use the Internet).
Two kinds of pull subscriptions are available. Standard pull subscriptions are registered on the Publisher. Anonymous pull subscriptions are set up entirely on the Subscriber; no information about the subscription is stored on the Publisher. Anonymous subscriptions are ideal for Subscribers that connect via the Internet. Internet-based Subscribers can connect using the FTP protocol.
For pull subscriptions, the replication agents that replicate data to the Subscriber run at the Subscriber.
TIP
This discussion of subscriptions states that creation and administration of subscriptions is performed on the Publisher for push subscriptions and on the Subscriber for pull subscriptions. This does not mean that these tasks must be performed physically at these servers. You can register a Publisher and a Subscriber in SQL Server Enterprise Manager running on a client computer, and then manage both push and pull subscriptions simply by selecting the relevant server.
Lesson Summary
SQL Server replication uses a publisher-subscriber metaphor. Data identified for replication is distributed from a Publisher server through a distribution server to a Subscriber server. Data marked for replication, called a publication, can be filtered horizontally and vertically. A subscription configures a Subscriber to receive data from a Publisher. Subscriptions can be configured from the Publisher (a push subscription) or from the Subscriber (a pull subscription).
EAN: 2147483647
Pages: 100